私たちは2010年に趣味としてそれを始め、主な仕事の後に長い夜に働き、短い夜にスムーズに変わり、週末に働きました。 この作業の5年間で、最小限の遅延とデータ処理ロジックのシンプルなプログラミングモデルを備えたソリューションを求めて3つのプロトタイプを作成しました。
2015年に、2〜3マイクロ秒の保証された遅延でデータストリームを処理できるまともな作成があることに気付きました。 そして、私たちは始めたものを商用製品に変える機会を探し始めました。おそらく、「おじさん」のために働くのをやめて、私たちの製品だけを扱い、すべての時間を捧げます。 2015年の終わりに、私たちは最初のクライアントを見つけ、「おじさん」を出て「フリースイミング」に向かいました。
今日、私たちは確実にデバイスで成功したと言うことができます。 私たちはまだすべての計画を実現しておらず、新しい機能を追加するために、時にはエラーを修正するために一生懸命働く必要があります。 しかし、私たちのデバイスは現在1年間商用運用されています。
「おじ」のために働いて、私たちは取引所での金融商品の取引の技術的側面とニーズをよく研究し、主にそれらによって導かれました。 これは、自動取引(HFT、Algo Trading)、リスク管理(事前取引)、取引への「直接」アクセスの組織(直接市場アクセス)などです。
しかし、私たちはCEPapplianceを非常に汎用性の高いデバイスにすることができました。大量のデータをポンピングする必要がある分野に適用でき、迅速に行うだけでなく、低遅延を保証します。 標準のネットワークプロトコルの組み込みサポートと最小限の遅延の導入のおかげで、このデバイスは、ネットワークのセキュリティ違反を検出し、ネットワーク負荷を制御するための通信に適用できます。 このデバイスは、数マイクロ秒で決定を下し、センサーからの信号の受信に応答する必要がある場合に、テレマティクスで使用できます。 この場合、デバイスによるデータ処理のロジックは複雑になる可能性があります。 それを記述するために(プログラミング)、Complex Event Processing( CEP )テクノロジーのいくつかのテクニックを使用します。
CEPアプライアンスは、単純化された形式で次のように定式化できる問題を解決するために考案および作成されました。合計遅延は3マイクロ秒未満
- イーサネット、TCP / IP、UDP、 FIX 、 FAST 、 TWIME (FIX SBE) プロトコルなどの形式のネットワークインターフェイスを介して入力データ(信号)を受信します。
- ユーザーデータの解析と抽出。
- ユーザーデータを分析します。
- 出力データ(反応)を生成し、ネットワークインターフェイス経由で送信します。
CEPapplianceは、デバイスアーキテクチャのコアがユーザープログラマブルゲートアレイ( FPGA )であるという点で、CPUアーキテクチャで実行されるソフトウェアソリューションとは異なります。FPGAは、説明した問題を例外なく解決するすべての段階を実装します。
CPUアーキテクチャは進化しています。 ハイブリッドオプションが表示されます( 図1 、 図2 、および図3を参照) 。ネットワークインターフェースからプロセッサへの(およびその逆の)データ配信の時間は、ネットワークおよびアプリケーション層プロトコルの処理を中央プロセッサからネットワークカードに転送することにより短縮されます。 ただし、データ配信時間は1〜3マイクロ秒(一方向)であり、遅延に大きく寄与し、信号1の瞬間から反応時間を遠ざけます。
FPGAでは、入力データの解析、抽出、分析、および出力データの生成のためのコンポーネントを1つのチップに配置しました。比chip的に言うと「中間体なし」( 図4を参照)。

図 1.中央処理装置を備えた従来のソリューションのロジック
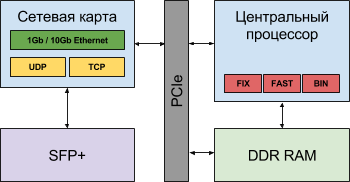
図 2.中央処理装置とネットワークカード上のTCPオフロードエンジンを備えたハイブリッドソリューションの論理図

図 3.中央処理装置、TCPオフロードエンジン、およびネットワークカードでのアプリケーション層プロトコルの実装を備えたハイブリッドソリューションの論理スキーム

図 4. CEPアプライアンスロジック
CEPapplianceでは、入力データの解析、抽出、分析、および出力データの生成のためのコンポーネントがFPGAチップに配置され、相互に直接やり取りします。
これを行うには、「車輪を再発明する」必要がありました。 趣味モードでCEPapplianceの作業(2010年に遡ります)を開始したことを思い出させてください。 彼らはすべて「自分がすべきであり、正しく」自分たちでやった。 その結果、とりわけ、イーサネット、TCP / IP、UDP、FIX、FAST、TWIMEをゼロから実装しました。
これらのコンポーネントを作成して、入力データが到着速度 ( ワイヤ速度 )で解析されるようにしました。 コンポーネントは関連する標準を実装します。これは「刻まれた」ものであり、ほとんど変更されません。 標準プロトコルの場合、構成メカニズムが提供されています。 たとえば、FIX、FAST、TWIME、およびその他のプロトコルモジュールは、ユーザー定義のパラメーターと、メッセージの構造を記述するテンプレートまたは図を使用して構成されます。
同時に、(ユーザー)データ処理アルゴリズムが変更される可能性があるという事実から進めました。 たとえば、リスクを最小限に抑えるためにブローカーによって実行される取引戦略またはチェック(取引前リスクチェック)、変化する市場状況、取引所のマイクロアーキテクチャの近代化、または規制当局の要件の順守。
ハードウェア言語(VHDL、Verilogなど)でFPGAのアルゴリズムを直接開発するには、高レベル言語での開発よりもコーディング、デバッグ、テストにかなり長い時間が必要です[2] 。 これには、原則として、高水準言語でプログラムを作成するプログラマーが持たない特別なスキルも必要です。 また、FPGAを使用してアルゴリズムの実行を高速化する場合は、アルゴリズムの詳細な説明を実装するFPGA開発者に渡す必要があります。 アルゴリズムの説明を転送すると、所有者が競争上の優位性を失うリスクが生じるため、これは非常に望ましくない場合があります。
このデバイスは、データ処理アルゴリズムを説明する機会をユーザーに提供します。 このために開発しました
- 高レベルのアルゴリズム言語、
- 元のアーキテクチャのプロセッサと
- プログラムを高水準言語からプロセッサコードに変換し、同時に実行されている複数のプロセッサにプログラムの実行を自動的に並列化できる最適化コンパイラ。
独自のプログラミング言語、プロセッサ、コンパイラにより、ユーザーが利用できる機能をFPGA(ハードウェア)に実装できます。 これらの機能は、アルゴリズムの一部またはアルゴリズム全体になります。これは、そのような実装の適切性、ユーザーの希望と能力に依存します。 このアプローチにより、CEPアプライアンスでのプログラムの実行を大幅に高速化できます。
ユーザーにCEPアプライアンスを自分でプログラムする機会を提供するために、これらのプログラムをデバッグするためのツールを提供する必要があったことは明らかです。 このようなツールがなければ、CEPアプライアンスを最大限に活用することは困難です。 そのため、デバイス自体と100%互換性のあるデバイスエミュレーターを開発しました。 エミュレータでプログラムをデバッグしたら、構成を変更し(ほとんどの場合、IPアドレスの変更です)、デバイスでプログラムをすぐに実行できます。
デバッグツールに加えて、デバイスエミュレータを使用すると、デバイス自体によるプログラム実行遅延を評価できます。 このようにして得られた遅延測定を使用して、プログラムを最適化できます。
また、CEPappliance用に作成されたユーザープログラムの自動テスト用に、テストスクリプトを表形式で読み取り、実行するテストベンチという特別なツールがあります。 デバイスとそのエミュレーターの両方で、同じテストセットを実行できます。
さて、いくつかの結果をまとめると...私たちの取締役会はモスクワ取引所のデータセンターにあり、取引に成功しています。 入札の結果について話すことはできません-これは私たちのトピックではありませんが、クライアントは非常に満足しています(このテキストは彼に同意します)。
今後は、デバイスの開発、株式取引以外の地域の顧客の検索、および多くの新しいアイデアに関する多くの作業が行われます。
1 TCP / IPを介したデータ交換の場合にこの遅延がどのように形成されるかについては、 [1]で読むことができます。 ここでは 、FPGAを使用してハイブリッドアーキテクチャを実装することにより、この遅延をどのように削減できるかについて説明します。
参照資料
1. S. LarsenおよびP. Sarangam、「TCP / IPネットワークにおけるエンドツーエンド遅延のアーキテクチャの内訳」、International Journal of Parallel Programming、Springer、2009年。
2.デビッドF.ベーコン、ロドリックラバ、スニルシュクラ。 大衆向けFPGAプログラミング 。 ACMキュー、Vol 11(2)、2013年2月。