
次の出口の一部として実装されたプロジェクトに関する学校の参加者を代表する別の記事:
「私はDmitry Pasechnyukです。E-ContentaのテクニカルディレクターasashであるAlexander Petrovのリーダーシップの下、 GoTo Schoolの春のシフトの一環として休暇中に行った研究を共有したいと思います。
私たちが知っているように、オンライン映画館は非常に一般的であり、良い収入を生み出すことができます。 しかし、他のビジネスと同様に、これは単独では発生しません。 オンライン映画の成功のための重要な条件の1つは、視聴のための提案の有能な準備です。
すべての映画館には、オンラインであろうと本物の映画館であろうと、レパートリー企画の従業員がいます。 どの映画がスクリーンに表示されるかを決めるのは彼です。 フィルムロールプロセスには落とし穴があります。 成功する映画を選択するには、購入権のコストだけでなく、他の千のニュアンスも考慮する必要があります。 映画自体を選択するシステムは存在せず、多くの場合、映画は独自の「本能」、期待の評価、専門家の意見に基づいて選択されます。
責任ある決定を下すことは、人にとって大きな道徳的負担です。一方で、個人的および状況的要因が決定に過度に影響するリスクが常にあります。
現代の技術は人々の仕事を促進するように設計されており、この場合、期待は正当化されます。
私の研究では、オンライン映画館のターゲット視聴者の期待に応じて、映画を人から機械にランク付けするタスクをシフトしようとしました。 もちろん、一般的な声明では、このタスクはより複雑であり、このソリューションは最初のステップにすぎません。 将来的には、この方向で研究を続ける予定です。
カットの下ですべてが順番に。
問題解決へのアプローチ
機械学習モデルのトレーニングとテスト用のフィルムのリストを取得するために、GroupLens Webサイト(MovieLens 20Mデータセットml-20m.zip)のデータセットを使用しました。
アルゴリズムのテスト用に2018年に発表された映画のリストを取得するには、TMDb API(Movie Database API developers.themoviedb.org/3/getting-started )を使用しました 。
俳優、監督のリストなど、映画に関する情報については、IMDb IDの簡単な説明がSimAPIで使用されました 。
ソリューションは、基本的な機械学習アルゴリズムの実装を含むScikit-learnライブラリを使用してPythonで実装されました。
この問題を解決するために、フィルムから次の機能が特定されました。ワンホットエンコード機能のジャンル。 撮影年; 有名な俳優、監督、映画の製作国; 映画の説明によると、テキスト内の50個の最も重要な単語のtf-idf。説明内のすべての単語(ストップワードを除く)word2vecの平均。
ターゲット変数として、映画の評価に関してアクティブなMovieLens視聴者の割合が使用され、特定の映画を評価しました。 以下は、ランダムフォレストアルゴリズムによって決定される、映画の人気とその重みを予測する上で最も重要な15の機能です。

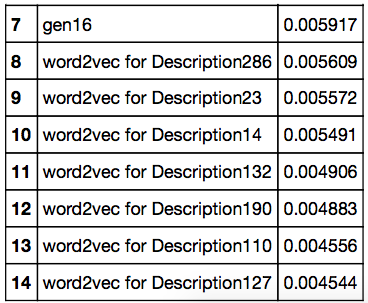
トレーニングと検証のために、MovieLensフィルムの初期サンプルを99:1の比率で分割しました。トレーニングサンプルのフィルムは検証サンプルのフィルムから先に出ており、アルゴリズムがその瞬間後に人気のあるフィルムを知るなどの問題を回避しましたまだ公開されていない映画の人気を予測する必要が生じたとき(その時点で、どの映画が将来関連するかを正確に言うことはできません)。
アルゴリズムの品質を判断するために、アルゴリズムで10、50、200の映画のうち少なくとも1つを視聴した、合計視聴者数の中で最も人気のあるユニークなMovieLensユーザーの数の割合を使用しました。
線形回帰、ランダムフォレスト、K最近傍、決定木、決定木に対する勾配ブースティングなどのアルゴリズムが検証サンプルでテストされました。 テスト結果を次の表に示します。

(番号0の行は、ターゲット変数がわかっている場合の特定のメトリックの値を表します)。
ステージ1の結果
特定の品質メトリックに関してアルゴリズムによってテストされたものの中で最高のものは、ランダムフォレストでした。 ターゲット変数の実際の値とこのアルゴリズムで予測された値の間のピアソン相関係数は0.826です。 以下は、これらの量の散布図です。
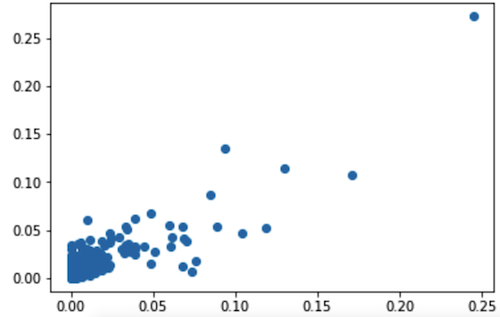
次に、選択したアルゴリズムの結果が実際の結果と一致するかどうかを確認することにしました。 アルゴリズムによって予測された映画に関心のある対象視聴者の割合に従って映画をランク付けし、結果を表示すると、MovieLensの視聴者のサイズと他の映画のサイズに比べて、上位5位の映画の視聴回数が実際にかなり多くなっていることがわかりますTOP 20〜30、しかし同時に低い場所で(映画は2001年から2002年までの期間に150個の量でランク付けされました)

アルゴリズムの改善
人気順にランク付けされた映画のリストを受け取った後、どのジャンルがリストのトップの位置を支配しているかに興味を持つようになりました。 最上位の映画のほとんどがドラマであることが判明しました。 このため、リストの一番上からN本のフィルムを取り出して、これらのフィルムだけを映画館で上映した場合、一部の人々はドラマだけでなく、ドキュメンタリーやホラー。
映画のセットを作成するための次のスキームが最善の方法であることを提案しました:各映画について、映画のアルゴリズムが映画のジャンルの「人気」に返す結果の積として、その「人気」を考慮します。
まず、各ジャンルのヒストグラムを作成し、横軸にこのジャンルのXフィルムの数をプロットし、1993年から2003年の期間にMovieLensの合計視聴者からこのジャンルのXフィルムを視聴した人の割合を延期しました。 結果は以下のとおりです。

次に、ジャンルの人気の指標を選択する必要がありました。 テスト対象の中で最適なオプションは、MovieLens視聴者からの各人によるこのジャンルの映画の視聴回数の正規化された合計でした。 その結果、各ジャンルは次の「人気」ポイントを獲得しました。

第二段階の結果
アルゴリズムの改善されたバージョンによって示された結果をアルゴリズムの初期バージョンと比較することにし、次の結果を得ました。 横軸にフィルム配布用に選択する必要があるフィルムの数、および縦座標<元のアルゴリズムの品質>-<新しいアルゴリズムの品質>を示すグラフを作成すると、次の結果が得られます。

グラフからわかるように、操作のプロセスで改善したアルゴリズムは、セグメントX∈[60、225]でより高い品質を示し、同時にXの大きな値に対して同じ結果を示します。
一般に、このアルゴリズムは、購入する映画の長期的なリストを作成するために使用できます。
実際の条件でアルゴリズムをテストする
2018年に発表され、128個のMovie DB APIを使用して受け取った映画のリストでテストが行われました。 所定の数から60枚未満のフィルムを選択するのは理にかなっていない可能性があり、実際の状況では新しいアルゴリズムの「収益性の限界」が右にシフトする可能性があるという事実に関連して、元のアルゴリズムをテストすることにしました。 映画とその「人気」のポイントのランク付けされたリストを出力すると、次の結果が得られます。
リストの最初の24作品

最近の24作品のリスト
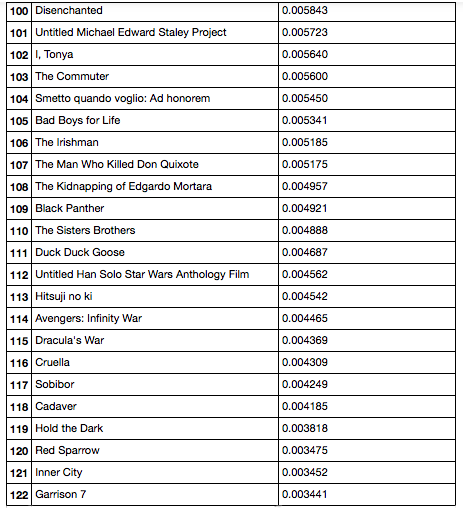
このリストを見ると、最初の部分では、たとえば4、8、9、10、12、17、18の位置で非常に有望な映画を見ることができます。リストの最新の映画を見ると、これらの映画は一般に明らかに魅力的であるが、それらのコンテンツは、おそらく114位の映画を除いて、あまり印象的ではない。なぜそうなったのか? -この映画の機能のリストを見ると、この映画の監督がすべての監督のリストに含まれていないことがわかります(トレーニングセットにこのシリーズの映画はなかったと言うことができます)。また、ジャンルに関する情報もありません(多分TMDb APIおよび/またはSimAPI、この映画に関する情報が見つかりませんでした)。
見込み
最初に、人気によって新しい映画をランク付けするという私たちのタスクは解決されました。 このアルゴリズムは、本番ソリューションの一部になります。 同時に、これは作業の終わりにはほど遠い。
将来的には、GoogleとYandexでの映画の検索履歴、映画レビューのデータ(最も人気のあるサービスのレビューの平均調性)、コンテンツの観点で考慮されたものに近い映画の成功に関するデータなど、標識の数を増やす予定です説明。 映画に興味のある観客の割合を予測し、各ユーザーが特定の映画を視聴する確率を(すべてまたは一部から)ユーザーが平均することもできます。
ご清聴ありがとうございました。そして記事についてはDmitryです。 新しい学校について、プロジェクトのアイデアをお寄せください。school@ goto.msk.ruまでお問い合わせください。