私の実践では、さまざまな目的のためにクラウドインフラストラクチャの設計と管理に多くの時間を費やしています。 これは主にApache CloudStackです。 このシステムには優れた機能がありますが、監視の観点では、特に個々の監視オブジェクト(サーバー、仮想マシン)を監視するよりも広範囲に監視する場合、機能は明らかに不十分です(読み取り-利用不可)。
一般に、視覚情報分析システムのより広範な要件とデータソースとの統合の要件に関連して、Kibana、Grafanaなどの特別なアドホックデータ分析ソリューションが広がり始めました。 これらのシステムは、 InfluxDBの 1つである時系列データの専用リポジトリと統合できます。 この記事では、LibVirt API、Grafana、およびInfluxDBを使用して、KVMハイパーバイザーの実行VMのパラメーターを収集および分析するように設計されたDockerイメージとして配布される既製のソリューションについて説明します。
ソリューションの概要
このソリューションは、Apache License v2ライセンスの下で配布されるDockerコンテナの形式で提供されるため、特定のタスクのニーズを反映して、あらゆる組織で制限なく変更して使用できます。 コンテナは専用サーバーでホストされ、pythonデータ収集ユーティリティはTCPを介してLibVirtにリモート接続し、InfluxDBにデータを送信します。そこからGrafanaを使用して視覚化と分析を要求できます。
コンテナは、 GitHubのソースコードとして、およびDockerHubのインストール可能なイメージとして入手できます。 実装言語はpythonです。
なぜDocker Container
このソリューションは最終的な実装に便利であり、ネットワーク経由でLibVirt APIへのアクセスを許可する場合を除き、仮想化サーバーに追加設定や追加ソフトウェアをインストールする必要もありません。 外部からLibVirt APIにアクセスできない場合は、仮想化ホストにDockerをインストールして、コンテナーをローカルで実行できます。
私が実際に使用するソリューションの一部として、常に安全なネットワークがあり、アクセスは許可されていないユーザーに対して制限されています。したがって、パスワードを使用してLibVirtへのアクセスを制限せず、提示されたコンテナーは認証をサポートしません。 そのような機能が必要な場合は、単純に追加できます。
収集されるデータ
センサーは、LibVirtを介して利用可能な以下の仮想マシンデータを収集します。
CPU:
{ "fields": { "cpuTime": 1070.75, "cpus": 4 }, "measurement": "cpuTime", "tags": { "vmHost": "qemu+tcp://root@10.252.1.33:16509/system", "vmId": "i-376-1733-VM", "vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679" } }
RAM:
{ "fields": { "maxmem": 4194304, "mem": 4194304, "rss": 1443428 }, "measurement": "rss", "tags": { "vmHost": "qemu+tcp://root@10.252.1.33:16509/system", "vmId": "i-376-1733-VM", "vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679" } }
MACアドレスにバインドされている各ネットワークアダプターの統計:
{ "fields": { "readBytes": 111991494, "readDrops": 0, "readErrors": 0, "readPackets": 1453303, "writeBytes": 3067403974, "writeDrops": 0, "writeErrors": 0, "writePackets": 588124 }, "measurement": "networkInterface", "tags": { "mac": "06:f2:64:00:01:54", "vmHost": "qemu+tcp://root@10.252.1.33:16509/system", "vmId": "i-376-1733-VM", "vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679" } }
各ドライブの統計:
{ "fields": { "allocatedSpace": 890, "ioErrors": -1, "onDiskSpace": 890, "readBytes": 264512607744, "readIOPS": 16538654, "totalSpace": 1000, "writeBytes": 930057794560, "writeIOPS": 30476842 }, "measurement": "disk", "tags": { "image": "cc8121ef-2029-4f4f-826e-7c4f2c8a5563", "pool": "b13cb3c0-c84d-334c-9fc3-4826ae58d984", "vmHost": "qemu+tcp://root@10.252.1.33:16509/system", "vmId": "i-376-1733-VM", "vmUuid": "12805898-0fda-4fa6-9f18-fac64f673679" } }
LibVirtが「見る」仮想化ホストの一般的な統計:
{ "fields": { "freeMem": 80558, "idle": 120492574, "iowait": 39380, "kernel": 1198652, "totalMem": 128850, "user": 6416940 }, "measurement": "nodeInfo", "tags": { "vmHost": "qemu+tcp://root@10.252.1.33:16509/system" } }
LibVirtを構成する
構成ファイル/etc/libvirt/libvirtd.conf
インストールする必要があります。
listen_tls = 0 listen_tcp = 1 tcp_port = "16509" auth_tcp = "none" mdns_adv = 0
注意 ! 上記の設定により、TCP経由でLibVirt APIに接続し、アクセスを制限するためにファイアウォールを正しく構成できます。
これらの設定が完了したら、LibVirtを再起動する必要があります。
sudo service libvirt-bin restart
Influxdb
インストール(Ubuntu用)
InfluxDBのインストールは、たとえばUbuntuのドキュメントに従って行われます 。
curl -sL https://repos.influxdata.com/influxdb.key | sudo apt-key add - source /etc/lsb-release echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list sudo apt-get update && sudo apt-get install influxdb sudo service influxdb start
認証設定
influxコマンドを実行して、DBMSへのセッションを開きます。
$ influx
管理者を作成します(認証をアクティブにするときに必要になります)。
CREATE USER admin WITH PASSWORD '<password>' WITH ALL PRIVILEGES
pulsedbデータベースと、このデータベースにアクセスできる通常のpulseユーザーを作成しましょう:
CREATE DATABASE pulsedb CREATE USER pulse WITH PASSWORD '<password>' GRANT ALL ON pulsedb TO pulse
設定ファイル/etc/influxdb/influxdb.confで認証を有効にします。
auth-enabled = true
InfluxDBを再起動します。
service influxdb restart
すべてが正しく行われたら、セッションを開いたときに、ユーザー名とパスワードを指定する必要があります。
influx -username pulse -password secret
コンテナを起動してデータの収集を開始する
docker pull bwsw/cs-pulse-sensor docker run --restart=always -d --name 10.252.1.11 \ -e PAUSE=10 \ -e INFLUX_HOST=influx \ -e INFLUX_PORT=8086 \ -e INFLUX_DB=pulsedb \ -e INFLUX_USER=pulse \ -e INFLUX_PASSWORD=secret \ -e GATHER_HOST_STATS=true -e DEBUG=true \ -e KVM_HOST=qemu+tcp://root@10.252.1.11:16509/system \ bwsw/cs-pulse-sensor
ほとんどのパラメーターは自明です。2つだけ説明します。
- PAUSE-値を要求する間隔(秒単位)。
- GATHER_HOST_STATS-ホストで追加の統計を収集するかどうかを決定します。
その後、アクティビティはdocker logsコマンドを使用してコンテナログに反映され、エラーは反映されません。
InfluxDBへのセッションを開いた場合、コンソールでコマンドを実行し、測定データが利用可能であることを確認できます。
influx -database pulsedb -username admin -password secret
> select * from cpuTime limit 1 name: cpuTime time cpuTime cpus vmHost vmId vmUuid ---- ------- ---- ------ ---- ------ 1498262401173035067 1614.06 4 qemu+tcp://root@10.252.1.30:16509/system i-332-2954-VM 9c002f94-8d24-437e-8af3-a041523b916a
これで記事の主要部分は終わりです。その後、Grafanaを使用して永続的な時系列を処理する方法を説明します。
Grafana(Ubuntu)をインストールして構成する
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.4.1_amd64.deb sudo apt-get install -y adduser libfontconfig sudo dpkg -i grafana_4.4.1_amd64.deb sudo service grafana-server start sudo update-rc.d grafana-server defaults
Webブラウザーを起動し、Grafana管理インターフェイスhttp://influx.host.com//000/を開きます。
Grafanaへのデータソースの追加
プロジェクトWebサイトにデータソースを追加するための詳細な手順 。 この場合、追加されたデータソースは次のようになります。
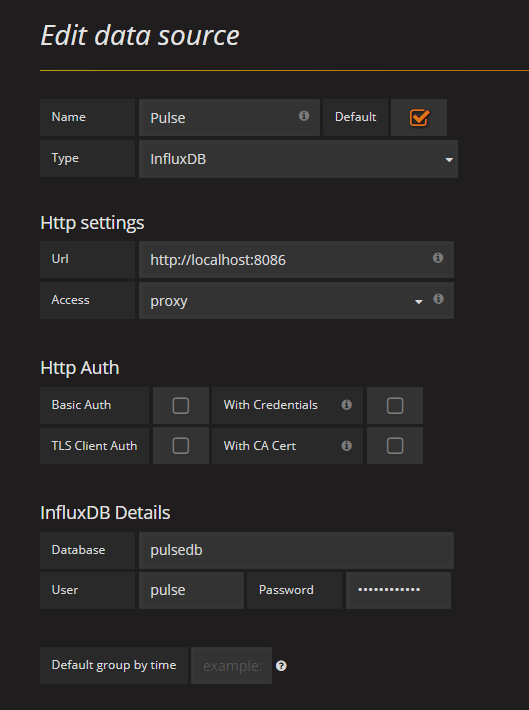
データソースを保存したら、「ダッシュボード」を作成し、グラフのクエリを作成できます(この手順はGrafanaの使用方法ではないため、クエリの式のみを指定します)。
CPU負荷(分):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 1m) / LAST("cpus") / 60 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(1m)
CPU負荷(5分):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"), 5m) / LAST("cpus") / 300 * 100 from "cpuTime" where "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter group by time(5m)
CPU負荷(すべてのVM):
select NON_NEGATIVE_DERIVATIVE(MAX("cpuTime"),1m) / LAST("cpus") / 60 * 100 as CPU from "cpuTime" WHERE $timeFilter group by time(1m), vmUuid

VMメモリ(5分間の集約):
SELECT MAX("rss") FROM "rss" WHERE "vmUuid" = '6da0cdc9-d8ff-4b43-802c-0be01c6e0099' and $timeFilter GROUP BY time(5m) fill(null)
ディスクのReadBytes、WriteBytes統計(5分集約):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m) select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"),5m) / 300 from "disk" where "image" = '999a1942-3e14-4d04-8123-391494a28198' and $timeFilter group by time(5m)
NICのReadBits、WriteBits統計(5分集約):
select NON_NEGATIVE_DERIVATIVE(MAX("readBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" = '06:07:70:00:01:10' and $timeFilter group by time(5m) select NON_NEGATIVE_DERIVATIVE(MAX("writeBytes"), 5m) / 300 * 8 from "networkInterface" where "mac" ='06:07:70:00:01:10' and $timeFilter group by time(5m)
InfluxDBクエリ言語の全機能はサービスにあり、ニーズに合わせてデータの視覚的分析を可能にするようなダッシュボードを構築できます。 たとえば、私にとって最も便利なケースの1つは、インシデントの分析です。クライアントが「あなたのコードは**** o」©と文句を言い、彼のVMは素晴らしく機能したと言って、それがすべてです。 式を作成し、写真を見て、そのVMのCPUがピーク時に1時間でどのように消え去ったかを確認します。 スクリーンショットは、競合を解決する上で大きな議論です。
さまざまなVMリソースを使用して最も集中的に分析し、それらを個々のホストに移行することもできます。 はい、何でも。 この意味で、Grafana、Kibana、および類似のシステムは、オンデマンド分析を実行して複雑な分析セットを構築できるという点で、従来の監視システム(Zabbixなど)と比較して有利です。一方、InfluxDBは、大きなデータセットでも高い分析パフォーマンスを保証します。
おわりに
LibVirtからデータを受信するコードは、QCOW2形式のボリュームを使用するVMでテストされました。 LVM2とRBDのオプションを考慮に入れようとしましたが、テストしませんでした。 誰かがVMボリュームの他のバリアントでコードをテストし、コードの修正を送信できる場合、感謝します。
PS:VMネットワークトラフィックを監視すると、PPSデータが、ルーターのSflow / NetflowまたはVMのtcpdumpを介して取得するデータよりも大幅に少ないことがあります。 これはKVMのよく知られたプロパティであり、そのネットワークサブシステムは1500バイトの標準MTUに準拠していません。
PPS:pythonのLibVirt APIドキュメントはひどく、データが返される形式とその意味を把握するために、さまざまなバージョンを調べなければなりませんでした。
PPS2:Gazorpazorpeで言われているように、「もし必要ならお話しします」©