
みなさんこんにちは! 私の名前はアレクサンダー、私はBadooのデータチームを率いています。 今日は、分散イベント処理システムで変位値を計算するための最適なアルゴリズムの選択方法について説明します。
前に、UDS(Unified Data Stream) イベント処理システムの仕組みについて説明しました。 つまり、スライディングウィンドウのさまざまなセクションにデータを集約する必要がある、異種イベントのストリームがあります。 イベントの各タイプは、独自の集合関数と測定値のセットによって特徴付けられます。
システムの開発中に、分位の集計関数のサポートを実装する必要がありました。 BadooでのPinbaの使用に関する投稿から、パーセンタイルとは何か、そしてそれらがなぜmin / avg / maxよりもメトリックの振る舞いを表すのかについて詳しく知ることができます。 おそらくPinbaで使用されているのと同じ実装を使用できますが、UDSの次の機能を考慮する必要があります。
- 計算はHadoopクラスター全体に「広がり」ます。
- システムの設計には、任意の属性セットによるグループ化が含まれます。 これは、パーセンタイルメトリックの数が数百万であることを意味します。
- 計算はMap / Reduceを使用して実行されるため、集計関数のすべての中間計算には加算性プロパティが必要です(計算を個別に実行する異なるノードから「マージ」できる必要があります)。
- ピンバとUDSには、それぞれCとJavaの異なる実装言語があります。
評価基準
これらのアーキテクチャ上の機能に基づいて、分位数計算アルゴリズムを評価するためのいくつかのパラメーターを提案します。
計算精度
最大1.5%の計算精度に満足していると判断しました。
リードタイム
イベントの発生からグラフ上での変位値の視覚化までの時間を最小限に抑えることが重要です。 この要素は、次の3つの要素で構成されます。
- 「数学」時間(マップステージ)-データ構造を初期化してデータを追加するためのオーバーヘッド。
- シリアル化時間-2つのデータ構造をマージするには、それらをシリアル化してネットワーク経由で送信する必要があります。
- マージ時間(縮小段階)-独立して計算された2つのデータ構造をマージするオーバーヘッド。
記憶容量
私たちのシステムでは数百万のメトリックが処理されており、コンピューティングリソースの賢明な使用を監視することが重要です。 メモリとは、次のことを意味します。
- RAMは、変位値のデータ構造が占めるボリュームです。
- シャッフル-計算はMap / Reduceを使用して実行されるため、ノード間の中間結果の交換は避けられません。 これを可能にするには、データ構造をシリアル化し、ディスク/ネットワークに書き込む必要があります。
また、次の条件を提示します。
データ型
アルゴリズムは、double型で表される負でない値の計算をサポートする必要があります。
プログラミング言語
JNIを使用しないJava実装が必要です。
研究参加者

ナイーブ
比較のための参照を得るために、すべての入力値をdouble[]
格納する「額」の実装を作成しました。 変位値を計算する必要がある場合、配列がソートされ、変位値に対応するセルが計算され、その値が取得されます。 2つの中間結果のマージは、2つの配列を連結することにより発生します。
Twitter Algebird
このソリューションは、Spark(UDSのベースで使用)向けに強化されたアルゴリズムの検討中に発見されました。 AlgebirdのTwitterライブラリは 、Scalaで利用可能な代数演算を拡張するように設計されています。 これには、 ApproximateDistinct
、 CountMinSketch
とCountMinSketch
広く使用されている多くの関数が含まれており、特にQ-Digestアルゴリズムに基づくパーセンタイルの実装が含まれています。 ここで、アルゴリズムの数学的正当化を見つけることができます。 要するに、構造は、各ノードがいくつかの追加属性を格納するバイナリツリーです。
テッド・ダニングT-ダイジェスト
このライブラリは、前述のQ-Digestアルゴリズムを改良したものであり、メモリ消費量の削減、パフォーマンスの向上、精度の向上を実現しています。
空輸分位ダイジェスト
Facebook Prestoの分散SQLエンジンをリバースエンジニアリングしているときに、 この製品に出会いました。 RESTフレームワークでの変位値の実装を見るのは少々驚くべきことでしたが、Prestoの高速でアーキテクチャー(Map / Reduceと同様)により、このソリューションをテストするよう促されました。 繰り返しますが、Q-Digestは数学的装置として使用されます。
高ダイナミックレンジ(HDR)ヒストグラム
この決定は、ピンバにパーセンタイルを導入するためのイデオロギーのインスピレーションでした。 その特徴的な機能は、構造を初期化するときに、上位のデータ範囲を知る必要があることです。 値の範囲全体をN番目のセルに分割し、追加するときに、いずれかのセルの値を増やします。
試験方法

品質評価
考慮された各ソフトウェアソリューションは、特定のレイヤー(モデル)でラップされました(テストのためにフレームワークに適合させるため)。 各モデルのパフォーマンステストを実施する前に、ユニットテストを作成してその有効性を検証しました。 これらのテストでは、モデル(基礎となるソフトウェアソリューション)が所定の精度で変位値を生成できることを検証します(精度1%および0.5%がチェックされました)。
性能試験
各モデルについて、テストはJMHを使用して作成されました。 それらはカテゴリに分けられ、それぞれについて詳細に説明します。 JMHの生の結論で投稿を「詰まらせる」ことはしません-すぐにグラフの形で視覚化する方が良いでしょう。
生テスト
このテストでは、挿入ごとにデータ構造のパフォーマンスを測定します。つまり、構造を初期化し、データを入力するのに必要な時間を測定します。 また、要素の精度と数に応じてこの時間がどのように変化するかを検討します。 測定は、0.5、1%の計算誤差で、10、100、1000、10000、10000、1,000,000の範囲で単調に増加する数のシーケンスに対して行われました。 挿入は、バンドルで(構造がサポートしている場合)または要素ごとに実行されました。
その結果、次の図が得られました(縦軸のスケールは対数であり、値が小さいほど優れています)。
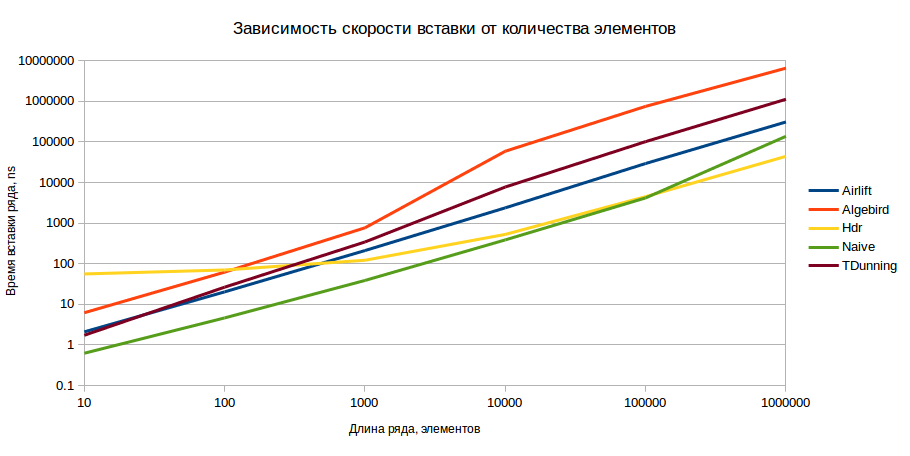
結果は1%の精度で示されていますが、0.5%の精度では画像は根本的に変わりません。 肉眼では、挿入の観点から、モデルに1000を超える要素がある場合、HDRが最適なオプションであることがわかります。
ボリュームテスト
このテストでは、メモリ内およびシリアル化された形式でモデルが占めるボリュームを測定します。 モデルにデータシーケンスが入力され、そのサイズが推定されます。 最適なモデルはメモリが少ないことが期待されます。 測定は、SparkのSizeEstimatorを使用して実行されます。

ご覧のとおり、要素の数が少ないため、HDRは他の実装に負けていますが、将来的には成長率が向上します。
シリアル化されたサイズは、シリアル化の事実上の標準であるKryoを介してモデルをシリアル化することで推定されました。 各シリアライザーは各モデル用に作成されており、可能な限り迅速かつコンパクトに変換します。

ここでも絶対的なチャンピオンはHDRです。
マップ/削減テスト
このテストは、戦闘状況でのシステムの動作を最も完全に反映しています。 テスト手順は次のとおりです。
- n番目の値を含む10個のモデルが事前に作成されています。
- それらはマージされます(エミュレーションマップ側の結合)。
- 結果の値は10回シリアル化および非シリアル化されます(異なるワーカーからのネットワーク送信エミュレーション)。
- デシリアライズされたモデルがマージされます(最終的な削減段階をエミュレートします)。
テスト結果(値が小さいほど良い):
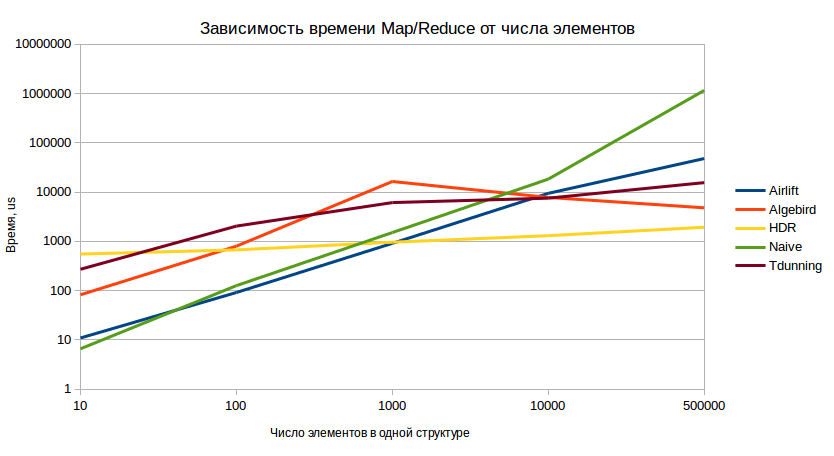
また、このテストでは、長期的に見た場合に、HDRの優位性が確信できることが再びわかりました。
結果分析
結果を分析した結果、HDRは多数の要素に対する最適な実装であり、少量のデータを含むモデルではより収益性の高い実装であるという結論に達しました。 多くのディメンションでの集計の特異性により、単一の物理イベントが複数の集計キーに影響を与えます。 1つのEPaymentイベントをユーザーの国と性別でグループ化することを想像してください。 この場合、4つの集約キーを取得します。

明らかに、イベントストリームを処理するとき、ディメンションが少ないキーのパーセンタイルの値は大きくなります。 システムの使用に関する統計は、次の図を示しています。

これらの統計により、多数のディメンションを持つメトリックの動作を調べる必要性を判断できました。 その結果、メトリックあたりのイベント数(つまり、テストモデル)の90パーセンタイルは2000年以内であることがわかりました。前に見たように、同様の要素数で、HDRより優れた動作をするモデルがあります。 そこで、新しいモデル-Combinedがあります。これは、2つの世界のベストを組み合わせたものです。
- モデルに含まれる要素がn未満の場合、Naiveモデルアルゴリズムが使用されます。
- しきい値nを超えると、HDRモデルが初期化されます。
この新しいメンバーの結果をご覧ください!



グラフからわかるように、結合モデルは小さなサンプルでHDRよりも実際に動作し、要素数が増加した場合と比較されます。
検討されているアルゴリズムの研究コードとAPIの例に興味がある場合は、GitHubでこれらすべてを見つけることができます。 また、比較に追加できる実装を知っている場合は、コメントに書いてください!