多くの場合、人々はビッグデータが自分の生活にどのように影響するかを知らない。 しかし、すべての人がビッグデータのソースです。 ビッグデータのスペシャリストは、いいね、コメント、Youtubeでの動画の視聴、スマートフォンからのGPSデータ、金融取引、ウェブサイトの動作など、デジタルトラックを収集して分析します。 彼らはすべての人に興味があるわけではなく、パターンに興味があります。

これらのパターンを理解することは、広告キャンペーンを最適化し、製品またはサービスに対する顧客のニーズを予測し、ユーザーの気分を評価するのに役立ちます。
調査と調査によると、ビッグデータはマーケティングとITの分野で最も頻繁に実装され、その後、研究、直接販売、ロジスティクス、金融などが行われます。

ビッグデータを処理するための特別なツールが開発されました。 今日最も人気のあるのはApache Sparkです。
Apache Sparkとは
Apache Sparkは、RAM内の不十分な構造のデータの並列処理および分析のためのオープンソースフレームワークです。
Sparkの主な利点は、パフォーマンス、暗黙的な並列化とフォールトトレランスを備えた使いやすいソフトウェアインターフェイスです。 Sparkは、Scala、Java、 Python、 Rの4つの言語をサポートしています。
このフレームワークは、カーネルと4つのライブラリの5つのコンポーネントで構成され、それぞれが特定の問題を解決します。
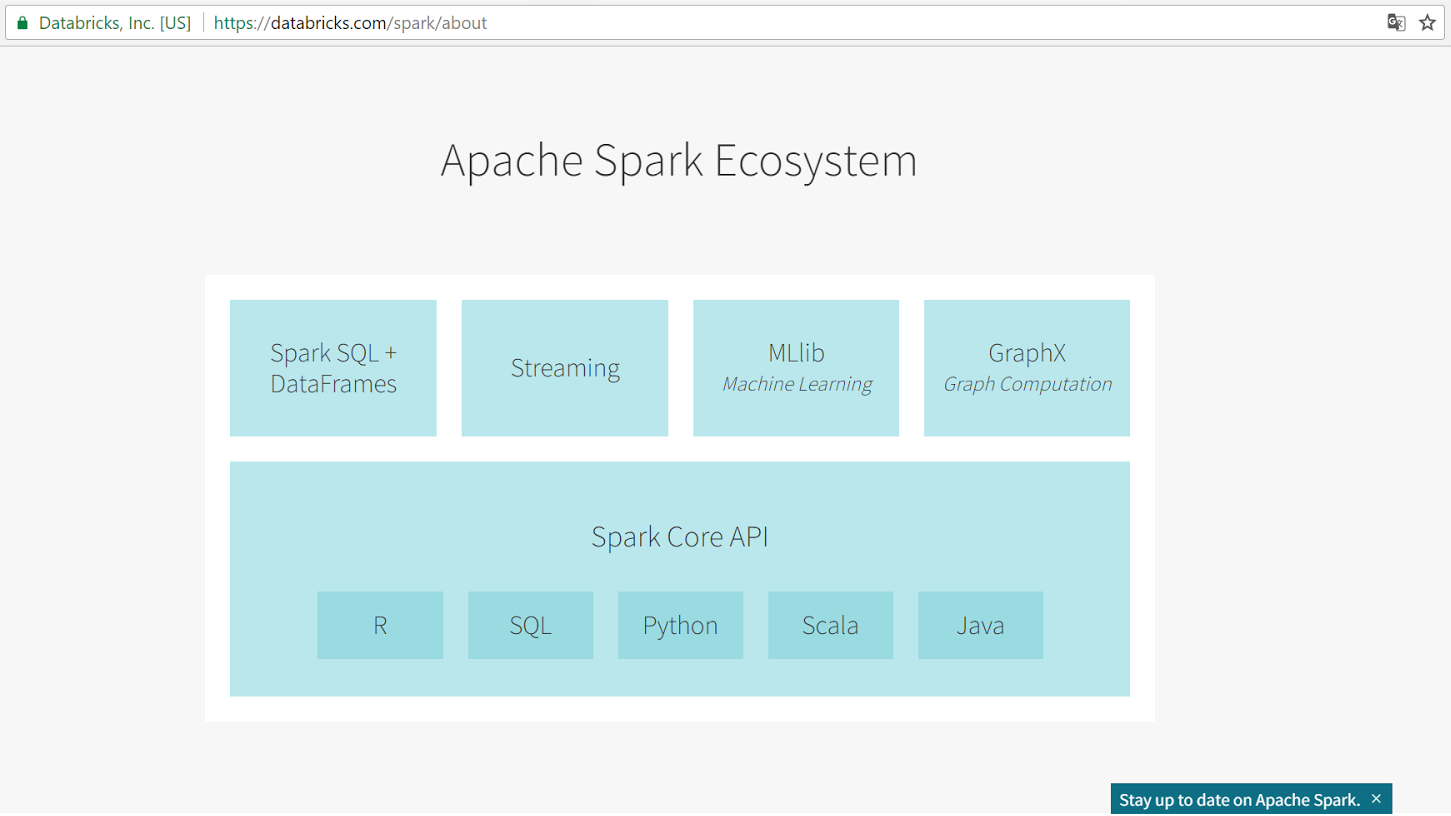
Spark Coreはフレームワークの中核です。 分散スケジューリング、スケジューリング、および基本的なI / Oを提供します。
Spark SQLは、構造化データ処理用の4つのフレームワークライブラリの1つです。 DataFramesと呼ばれるデータ構造を使用し、分散SQLクエリエンジンとして機能できます。 これにより、Hadoop Hiveリクエストを最大100倍高速で実行できます。
Spark Streamingは、ストリーミングデータを処理するための使いやすいツールです。 その名前にもかかわらず、Spark Streamingはリアルタイムでデータを処理しませんが、マイクロバッチモードで処理します。 Sparkの作成者は、各マイクロバッチの最小処理時間は0.5秒であるため、パフォーマンスはそれほど影響を受けないと主張しています。
このライブラリにより、ストリーム分析にバッチ分析アプリケーションコードを使用できるため、λアーキテクチャの実装が容易になります。
Spark Streamingは、HDFS、Flume、Kafka、ZeroMQ、Kinesis、Twitterなどの幅広い一般的なデータソースとシームレスに統合されます。
MLlibは、高速の分散型機械学習システムです。 彼女は、競合する最小二乗(ALS)アルゴリズムのベンチマークでテストしたとき、Apache Mahoutライブラリよりも9速いです。
MLlibには一般的なアルゴリズムが含まれています。
- 分類
- 退行
- 決定木
- 推薦
- クラスタリング
- テーマ別モデリング。
GraphXは、グラフデータのスケーラブルな処理のためのライブラリです。 GraphXは、トランザクション方式(データベースなど)によって変更されるグラフには適していません。
Sparkの動作:
- YARNのHadoopクラスター環境で、
- Mesosの実行、
- AWSのクラウドまたはその他のクラウドサービスで、
- 完全に自律的。
また、いくつかの分散ストレージシステムもサポートしています。
- HDFS
- OpenStack Swift、
- NoSQL DBMS
- カサンドラ
- Amazon S3、
- クドゥ、
- MapR-FS。
どうでしたか
ビッグデータを使用するための最初のフレームワークは、MapReduceテクノロジーに基づいて実装されたApache Hadoopでした。
2009年、カリフォルニア大学バークレー校の大学院生グループが、オープンソースのクラスター管理システムMesosを開発しました。 製品のすべての機能とMesosに基づくフレームワークの管理がいかに簡単かを示すために、同じ大学院生のグループがSparkの作業を開始しました。
クリエイターが考えたように、SparkはHadoopに代わるものであるだけでなく、Hadoopを上回るものでした。
2つのフレームワークの主な違いは、データへのアクセス方法です。 HadoopはMapReduceアルゴリズムのすべてのステップでデータをハードドライブに保存し、Sparkはすべての操作をRAMで実行します。 これにより、Sparkは最大100倍のパフォーマンスを獲得し、ストリーム内のデータを処理できます。
2010年には、このプロジェクトはBSDライセンスの下で公開され、2013年には、有望なプロジェクトを後援および開発するApache Software Foundationによってライセンスされました。 MesosもApacheの注目を集めてライセンスを受けましたが、Sparkほど人気はありませんでした。
使用方法
2016年にApache Foundationが実施した調査によると、 1,000社以上がSparkを使用しています。 マーケティングだけでなく使用されます。 以下は、企業がSparkで解決するタスクの一部です。
- 保険会社は、賠償請求プロセスを合理化します。
- 検索エンジンは、ソーシャルネットワーク上の偽のアカウントを識別し、ターゲティングを改善します。
- 銀行は、顧客からの特定の銀行サービスの需要を予測します。
- タクシーサービスは、時間と位置情報を分析して需要と価格を予測します。
- Twitterは大量のツイートを分析して、ユーザーの気分や製品や会社に対する態度を判断します。
- 航空会社は、フライト遅延を予測するモデルを構築しています。
- 科学者は気象災害を分析し、将来の外観を予測します。
代替案
ビッグデータの収集、分析、処理の必要性が高まるにつれて、新しいフレームワークが登場します。 一部の大企業は、内部のタスクとニーズを考慮して独自の製品を開発しています。 たとえば、GoogleのBeamとAmazonのKinesisが登場しました。 幅広いユーザーに人気のあるフレームワークについて話す場合、すでに述べたHadoopに加えて、Apache Flink、Apache Storm、Apache Samzaを呼び出すことができます。
重要な指標について、Apacheライセンスの下で4つのフレームワークを比較しました。

各フレームワークには、独自の長所と短所があります。 これまでのところ、それらのどれも普遍的ではなく、残りを置き換えることはできません。 そのため、ビッグデータを扱う場合、企業は特定の問題を解決するのに最適なフレームワークを選択します。 トリップアドバイザーやグルーポンなど、いくつかの企業は同時に複数のフレームワークを使用しています。
まとめると
Apache Sparkは、 Big Dataを操作するための最も人気のある急成長しているフレームワークです。 優れた技術パラメーターと4つの追加ライブラリにより、Sparkを使用してさまざまな問題を解決できます。
このフレームワークの明白な利点は、多数のSparkコミュニティとパブリックドメイン内のそれに関する大量の情報です。 明らかな欠点のうち、データ処理の遅延は、ストリームモデルを使用したフレームワークの遅延よりも長くなります。