翻訳は、Habrに関する他のデータサイエンスチュートリアルのストリームに突然成功しました。 :)
これはDataquest.ioの創設者であるVic Paruchuriによって書かれました。彼らはこの種のデータサイエンスのインタラクティブなトレーニングと、この分野での実際の作業の準備に従事しています。 ここには排他的なノウハウはありませんが、データの収集からそれらに関する最初の結論までのプロセスは非常に詳細に説明されています。しかし、どこから始めればいいのかわかりません。
データサイエンス企業は、採用を決定する際にポートフォリオをますます検討しています。 これは、特に、実践的なスキルを判断する最良の方法はポートフォリオを使用することだからです。 良いニュースは、完全に自由に使えることです。試してみると、多くの企業を感動させる優れたポートフォリオをまとめることができます。
高品質のポートフォリオの最初のステップは、その中で実証する必要があるスキルを理解することです。
企業がデータサイエンティストで見たいと考えている主要なスキルは、次のとおりです。
- コミュニケーション能力
- 他の人と協力する能力
- 技術的能力
- データに基づいて結論を出す能力
- 主導権を握る動機と能力。
すべての優れたポートフォリオには複数のプロジェクトが含まれており、各プロジェクトには1〜2個のデータポイントを表示できます。 これは、調和の取れたデータサイエンスポートフォリオの取得を検討するシリーズの最初の投稿です。 ポートフォリオの最初のプロジェクトを作成する方法と、データを通じて良いストーリーを伝える方法を見ていきます。 最後に、あなたのコミュニケーション能力とデータに基づいて結論を出す能力を明らかにするプロジェクトがあります。
サイクル全体を翻訳することは絶対にありませんが、そこから機械学習に関する興味深いチュートリアルに触れる予定です。
データによる履歴
基本的に、データサイエンスはコミュニケーションに関するものです。 データにあるパターンを見た後、このパターンを他の人に説明するための効果的な方法を探し、必要だと思う行動をとるように説得します。 データサイエンスで最も重要なスキルの1つは、データを通じてストーリーを視覚化することです。 良いストーリーはあなたの洞察をより良く伝え、他の人があなたのアイデアを理解するのを助けます。
データサイエンスの文脈でのストーリーは、あなたが見つけたすべての概要とその意味です。 例として、過去1年間で会社の利益が20%減少したという発見があります。 この事実を指摘するだけでは十分ではありません。なぜ利益が落ちたのか、それについてどうするのかを説明する必要があります。
データのストーリーの主なコンポーネントは次のとおりです。
- コンテキストの理解と形成
- さまざまな角度からの研究
- 適切な視覚化の使用
- さまざまなデータソースの使用
- 一貫したプレゼンテーション。
データを通じてストーリーを明確に伝える最良の方法はJupyterノートブックです。 あなたが彼に慣れていないなら、 これは良いチュートリアルです。 Jupyterノートブックを使用すると、データをインタラクティブに探索し、githubを含むさまざまなサイトに公開できます。 結果の公開はコラボレーションに役立ちます-他の人が分析を拡張できます。
この投稿では、PandasやmatplotlibなどのPythonライブラリとともにJupyterノートブックを使用します。
データサイエンスプロジェクトのトピックを選択する
プロジェクトを作成する最初のステップは、テーマを決定することです。 あなたが興味を持ち、探求したいという何かを選ぶ価値があります。 人々は、いつそれを実現するためだけにプロジェクトを作成したか、いつデータを掘り下げることが本当に面白かったのかを常に確認できます。 このステップでは、魅力的な何かを正確に見つけるために時間を費やすことが理にかなっています。
トピックを見つける良い方法は、異なるデータセットに登って、何が面白いかを見ることです。 開始するのに適した場所を次に示します。
- Data.gov-政府のデータが含まれています
- / r / datasets-数百の興味深いデータセットを持つsubreddit
- 素晴らしいデータセット -GitHubでホストされるデータセットのリスト
- データセットを見つけるための17の場所 -17のデータソースとそれぞれからのサンプルデータセット
実際のデータサイエンスでは、研究用に完全に準備されたデータセットが見つからないことがよくあります。 さまざまなデータソースを集約するか、真剣にクリーンアップする必要がある場合があります。 トピックがあなたにとって非常に興味深い場合、ここで同じことをするのは理にかなっています:最後に自分自身を見せた方が良いです。
ここから投稿にニューヨークの総合学校のデータを使用します 。
念のため、私たちに近い類似のデータセット(ロシア語)の例を示します。
- 政府のデータセット 。
- モスクワのデータセット
- オープンデータのハブアグリゲーター 。 上記のデータはありますが、すべてではありませんが、他にもたくさんあります。
トピック選択
プロジェクト全体を最初から最後まで作成することが重要です。 これを行うには、学習範囲を制限して、終了する内容を正確に把握しておくと便利です。 既に終了したプロジェクトに既に何かを追加する方が、既に終わりに持っていくのに飽き飽きしているものを完成させるよりも簡単です。
私たちのケースでは、高校生向けの統一国家試験の成績を、さまざまな人口統計およびその他の情報とともに調査します。 試験または統一状態試験は、高校生が大学に入る前に受けるテストです。 大学は、入学を決定するときに成績を考慮します。したがって、合格することが非常に重要です。 試験は3つのパートで構成され、各パートの評価は800ポイントです。 最後の合計スコアは2400です(ただし、前後に変動することもあります-データセットではすべて2400です)。 高校は、多くの場合、平均試験スコアでランク付けされ、通常、高い平均点は学区がどれだけ良いかを示す指標です。
米国の一部の少数民族の評価の不公正について不満がいくつかありました。そのため、ニューヨークでの分析は、試験の公平性を明らかにするのに役立ちます。
USE評価のデータセットはこちら 、各学校の情報を含むデータセットはこちらです。 これがプロジェクトの基礎になりますが、完全な分析を行うにはさらに情報が必要です。
元の試験は、SAT-Scholastic Aptitude Testと呼ばれます。 しかし、それは私たちのUSEと実質的に同じ意味なので、そのように翻訳することにしました。
データ収集
良いトピックが見つかったら、トピックを展開したり、調査を深めたりするのに役立つ他のデータセットを調べると便利です。 プロジェクトが作成されるのと同じくらい多くのデータがスタディに存在するように、最初にこれを行うことをお勧めします。 データが少ない場合、すぐに降伏する可能性があります。
私たちの場合、同じサイトのこのトピックには、人口統計情報と試験結果をカバーするデータセットがいくつかあります。
使用するすべてのデータセットへのリンクは次のとおりです。
- 学校のUSEグレード -ニューヨークの各学校のUSEグレード。
- 学校の出席 -ニューヨークの各学校の出席情報。
- 数学試験結果 -ニューヨークの各学校の数学試験結果。
- Grade Size —ニューヨークの各学校のクラスサイズ情報を表示します。
- UE試験結果 -上級試験結果。 このプログラムに合格すると、入学にメリットがあります。
- 卒業生に関する情報-卒業生の割合およびその他の関連情報。
- 人口統計 -各学校の人口統計情報。
- 学校調査 -各学校の保護者、教師、生徒の調査。
- 学区のマップ - 学区の形式に関する情報が含まれているため、学区をマップできます。
これらのデータはすべて相互接続されており、分析を開始する前にそれらを組み合わせることができます。
背景情報の収集
データ分析に入る前に、主題に関する一般的な情報を見つけることは有用です。 私たちの場合、役に立つかもしれない何かを知っています:
- ニューヨークは5つの地区に分割されており、それらはほぼ別々のエリアです。
- ニューヨークの学校はいくつかの学区に分かれており、各学区には何十もの学校を含めることができます。
- データセット内のすべての学校が高校ではないため、データを事前にクリーンアップする必要がある場合があります。
- ニューヨークの各学校には、固有のDBNまたは地区コードがあります。
- 地区ごとにデータを集計することで、地図作成情報を使用して、それらの違いをマッピングできます。
「Neighborhoods」と翻訳したものは、実際にはNYC「自治区」と呼ばれ、列はそれぞれ自治区と呼ばれます。
データを理解しています
データのコンテキストを本当に理解するには、時間をかけてこのデータについて読む必要があります。 この場合、上記の各リンクには各列のデータの説明が含まれています。 人口統計やその他の情報を含む他のデータセットとともに、高校生の試験の推定値に関するデータがあるようです。
コードを実行してデータを読み取りましょう。 研究にはJupyterノートブックを使用します。 以下のコード:
- ダウンロードした各ファイルを実行する
- Pandasデータフレームのそれぞれを読み取ります
- すべてのデータフレームをpython辞書に入れます。
import pandas import numpy as np files = ["ap_2010.csv", "class_size.csv", "demographics.csv", "graduation.csv", "hs_directory.csv", "math_test_results.csv", "sat_results.csv"] data = {} for f in files: d = pandas.read_csv("schools/{0}".format(f)) data[f.replace(".csv", "")] = d
すべてを読んだら、データフレームでheadメソッドを使用して、それぞれの最初の5行を表示できます。
for k,v in data.items(): print("\n" + k + "\n") print(v.head())
データセット内の特定の機能を既に確認できます。
math_test_results
| Dbn | グレード | 年 | カテゴリー | テスト済みの数 | 平均スケールスコア | レベル1# | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | 3 | 2006 | すべての学生 | 39 | 667 | 2 | |
| 1 | 01M015 | 3 | 2007年 | すべての学生 | 31 | 672 | 2 | |
| 2 | 01M015 | 3 | 2008年 | すべての学生 | 37 | 668 | 0 | |
| 3 | 01M015 | 3 | 2009 | すべての学生 | 33 | 668 | 0 | |
| 4 | 01M015 | 3 | 2010 | すべての学生 | 26 | 677 | 6 |
| レベル1% | レベル2# | レベル2% | レベル3# | レベル3% | レベル4# | レベル4% | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | 5.1% | 11 | 28.2% | 20 | 51.3% | 6 | 15.4% | |
| 1 | 6.5% | 3 | 9.7% | 22 | 71% | 4 | 12.9% | |
| 2 | 0% | 6 | 16.2% | 29日 | 78.4% | 2 | 5.4% | |
| 3 | 0% | 4 | 12.1% | 28 | 84.8% | 1 | 3% | |
| 4 | 23.1% | 12 | 46.2% | 6 | 23.1% | 2 | 7.7% |
| レベル3 + 4# | レベル3 + 4% | |
|---|---|---|
| 0 | 26 | 66.7% |
| 1 | 26 | 83.9% |
| 2 | 31 | 83.8% |
| 3 | 29日 | 87.9% |
| 4 | 8 | 30.8% |
ap_2010
| Dbn | 学校名 | AP受験者 | 合計試験数 | スコア3 4または5の試験の数 | |
|---|---|---|---|---|---|
| 0 | 01M448 | 大学ネイバーフッドHS | 39 | 49 | 10 |
| 1 | 01M450 | イーストサイドコミュニティHS | 19 | 21 | s |
| 2 | 01M515 | イーストサイドの下ごしらえ | 24 | 26 | 24 |
| 3 | 01M539 | 新しい探査SCI、TECH、MATH | 255 | 377 | 191 |
| 4 | 02M296 | ホスピタリティマネジメントの高校 | s | s | s |
sat_results
| Dbn | 学校名 | SAT受験者数 | SAT Critical Reading Avg。 得点 | SAT Math平均 得点 | SATライティング平均 得点 | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | 国際研究のためのヘンリーストリートスクール | 29日 | 355 | 404 | 363 |
| 1 | 01M448 | 大学近隣高等学校 | 91 | 383 | 423 | 366 |
| 2 | 01M450 | イーストサイドコミュニティスクール | 70 | 377 | 402 | 370 |
| 3 | 01M458 | フォーサイスサテライトアカデミー | 7 | 414 | 401 | 359 |
| 4 | 01M509 | マルタバレーハイスクール | 44 | 390 | 433 | 384 |
class_size
| CSD | 自治区 | 学校コード | 学校名 | グレード | プログラムの種類 | CORE SUBJECT(MS COREおよび9-12のみ) | コアコース(MSコアおよび9-12のみ) | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | GEN ED | - | - | |
| 1 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | CTT | - | - | |
| 2 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | GEN ED | - | - | |
| 3 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | CTT | - | - | |
| 4 | 1 | M | M015 | PS 015ロベルトクレメンテ | 02 | GEN E | - | - |
| サービスカテゴリ(K-9 *のみ) | 受講者数/席数 | セクションの数 | 平均クラスサイズ | 最小クラスのサイズ | \ | |
|---|---|---|---|---|---|---|
| 0 | - | 19.0 | 1.0 | 19.0 | 19.0 | |
| 1 | - | 21.0 | 1.0 | 21.0 | 21.0 | |
| 2 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 3 | - | 17.0 | 1.0 | 17.0 | 17.0 | |
| 4 | - | 15.0 | 1.0 | 15.0 | 15.0 |
| 最大クラスのサイズ | データソース | 学校の生徒と教師の比率 | |
|---|---|---|---|
| 0 | 19.0 | ATS | ナン |
| 1 | 21.0 | ATS | ナン |
| 2 | 17.0 | ATS | ナン |
| 3 | 17.0 | ATS | ナン |
| 4 | 15.0 | ATS | ナン |
人口統計
| Dbn | お名前 | 学年 | fl_percent | frl_percent | \ | |
|---|---|---|---|---|---|---|
| 0 | 01M015 | PS 015ロベルトクレメンテ | 20052006 | 89.4 | ナン | |
| 1 | 01M015 | PS 015ロベルトクレメンテ | 20062007 | 89.4 | ナン | |
| 2 | 01M015 | PS 015ロベルトクレメンテ | 20072008 | 89.4 | ナン | |
| 3 | 01M015 | PS 015ロベルトクレメンテ | 20082009 | 89.4 | ナン | |
| 4 | 01M015 | PS 015ロベルトクレメンテ | 20092010 | 96.5 |
| total_enrollment | プレック | k | グレード1 | グレード2 | ... | black_num | black_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 281 | 15 | 36 | 40 | 33 | ... | 74 | 26.3 | |
| 1 | 243 | 15 | 29日 | 39 | 38 | ... | 68 | 28.0 | |
| 2 | 261 | 18 | 43 | 39 | 36 | ... | 77 | 29.5 | |
| 3 | 252 | 17 | 37 | 44 | 32 | ... | 75 | 29.8 | |
| 4 | 208 | 16 | 40 | 28 | 32 | ... | 67 | 32.2 |
| hispanic_num | hispanic_per | white_num | white_per | male_num | male_per | female_num | female_per | \ | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 189 | 67.3 | 5 | 1.8 | 158.0 | 56.2 | 123.0 | 43.8 | |
| 1 | 153 | 63.0 | 4 | 1.6 | 140.0 | 57.6 | 103.0 | 42.4 | |
| 2 | 157 | 60.2 | 7 | 2.7 | 143.0 | 54.8 | 118.0 | 45.2 | |
| 3 | 149 | 59.1 | 7 | 2.8 | 149.0 | 59.1 | 103.0 | 40.9 | |
| 4 | 118 | 56.7 | 6 | 2.9 | 124.0 | 59.6 | 84.0 | 40.4 |
卒業
| 人口統計 | Dbn | 学校名 | コホート | \ | |
|---|---|---|---|---|---|
| 0 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2003 | |
| 1 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2004 | |
| 2 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2005年 | |
| 3 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2006 | |
| 4 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2006年8月 |
| 総コホート | 総卒業-n | 総卒業生-コホートの割合 | 合計リージェント-n | \ | |
|---|---|---|---|---|---|
| 0 | 5 | s | s | s | |
| 1 | 55 | 37 | 67.3% | 17 | |
| 2 | 64 | 43 | 67.2% | 27 | |
| 3 | 78 | 43 | 55.1% | 36 | |
| 4 | 78 | 44 | 56.4% | 37 |
| 総リージェント-コホートの% | 総リージェント-卒業生の割合 | ... | 高度なしのリージェント-n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | ... | s | |
| 1 | 30.9% | 45.9% | ... | 17 | |
| 2 | 42.2% | 62.8% | ... | 27 | |
| 3 | 46.2% | 83.7% | ... | 36 | |
| 4 | 47.4% | 84.1% | ... | 37 |
| 高度なしのリージェント-コホートの% | 高度なしのリージェント-卒業生の% | \ | |
|---|---|---|---|
| 0 | s | s | |
| 1 | 30.9% | 45.9% | |
| 2 | 42.2% | 62.8% | |
| 3 | 46.2% | 83.7% | |
| 4 | 47.4% | 84.1% |
| ローカル-n | ローカル-コホートの% | ローカル-卒業生の% | sまだ登録済み-n | \ | |
|---|---|---|---|---|---|
| 0 | s | s | s | s | |
| 1 | 20 | 36.4% | 54.1% | 15 | |
| 2 | 16 | 25% | 37.200000000000003% | 9 | |
| 3 | 7 | 9% | 16.3% | 16 | |
| 4 | 7 | 9% | 15.9% | 15 |
| まだ登録済み-コホートの% | ドロップアウト-n | ドロップアウト-コホートの% | |
|---|---|---|---|
| 0 | s | s | s |
| 1 | 27.3% | 3 | 5.5% |
| 2 | 14.1% | 9 | 14.1% |
| 3 | 20.5% | 11 | 14.1% |
| 4 | 19.2% | 11 | 14.1% |
hs_directory
| dbn | school_name | ボロ | \ | |
|---|---|---|---|---|
| 0 | 17K548 | ブルックリン音楽学校 | ブルックリン | |
| 1 | 09X543 | バイオリンとダンスの高校 | ブロンクス | |
| 2 | 09X327 | 包括的なモデルスクールプロジェクトMS 327 | ブロンクス | |
| 3 | 02M280 | マンハッタン広告大学 | マンハッタン | |
| 4 | 28Q680 | クイーンズヘルスゲートウェイセカンダリサイエンスコース... | クイーンズ |
| building_code | 電話番号 | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | ナン | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority02 | \ | |
|---|---|---|---|---|---|
| 0 | ナン | ナン | ... | それからニューヨーク市の住民へ | |
| 1 | ナン | ナン | ... | その後、ニューヨーク市の住民に出席し... | |
| 2 | ナン | ナン | ... | 次に、出席するブロンクスの学生または居住者に... | |
| 3 | 9 | 14.0 | ... | その後、ニューヨーク市の住民に出席し... | |
| 4 | ナン | ナン | ... | 次に、28区および29区の学生または居住者へ |
| priority03 | priority04 | priority05 | \ | |
|---|---|---|---|---|
| 0 | ナン | ナン | ナン | |
| 1 | その後、ブロンクスの学生または居住者に | それからニューヨーク市の住民へ | ナン | |
| 2 | その後、ニューヨーク市の住民に出席し... | その後、ブロンクスの学生または居住者に | それからニューヨーク市の住民へ | |
| 3 | その後、マンハッタンの学生または居住者に | それからニューヨーク市の住民へ | ナン | |
| 4 | その後、クイーンズの学生または居住者へ | それからニューヨーク市の住民へ | ナン |
| priority06 | priority07 | priority08 | priority09 | 優先度10 | 場所1 | |
|---|---|---|---|---|---|---|
| 0 | ナン | ナン | ナン | ナン | ナン | 883 Classon Avenue \ nブルックリン、ニューヨーク11225 \ n(40.67 ... |
| 1 | ナン | ナン | ナン | ナン | ナン | 1110 Boston Road \ nBronx、NY 10456 \ n(40.8276026 ... |
| 2 | ナン | ナン | ナン | ナン | ナン | 1501ジェロームアベニュー\ nブロンクス、ニューヨーク10452 \ n(40.84241 ... |
| 3 | ナン | ナン | ナン | ナン | ナン | 411 Pearl Street \ nニューヨーク、NY 10038 \ n(40.7106 ... |
| 4 | ナン | ナン | ナン | ナン | ナン | 160-20 Goethals Avenue \ nジャマイカ、NY 11432 \ n(40 ... |
- ほとんどにはDBN列が含まれます
- 一部のフィールドは、マッピングに興味深いように見えます。特に、位置1には、行の座標が含まれています。
- 一部のデータセットには、学校ごとに複数の行があり(DBN値が重複しています)、前処理の必要性を示唆しています。
共通分母にデータをもたらす
データの操作を簡単にするには、すべてのデータセットを1つに結合する必要があります。これにより、データセットの列をすばやく比較できます。 このためには、まず、組合の共通の列を見つける必要があります。 以前に推測した内容を見ると、 DBNは複数のデータセットで繰り返されているため、 DBNがそのような列であると想定できます。
「DBN New York City Schools」をGoogleで検索すると、 ここに来ます 。これは、DBNが各学校に固有のコードであることを説明しています。 データセット、特に政府のデータセットの調査では、各列が何を意味するのかを理解するために、しばしば各データセットでさえ、探偵の仕事をしなければなりません。
現在の問題は、 class_sizeとhs_directoryの 2つのデータセットにDBNが含まれていないことです。 hs_directoryでは、dbnと呼ばれるため、名前を変更するか、 DBNにコピーするだけです。 Class_sizeには別のアプローチが必要です。
DBN列は次のようになります。
In [5]: data["demographics"]["DBN"].head() Out[5]: 0 01M015 1 01M015 2 01M015 3 01M015 4 01M015 Name: DBN, dtype: object
class_sizeを見ると、これが最初の5行に表示されます。
In [4]: data["class_size"].head() Out[4]:
| CSD | 自治区 | 学校コード | 学校名 | グレード | プログラムの種類 | CORE SUBJECT(MS COREおよび9-12のみ) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | CTT | - | |
| 2 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | CTT | - | |
| 4 | 1 | M | M015 | PS 015ロベルトクレメンテ | 02 | GEN ED | - |
| コアコース(MSコアおよび9-12のみ) | サービスカテゴリ(K-9 *のみ) | 受講者数/席数 | / | |
|---|---|---|---|---|
| 0 | - | - | 19.0 | |
| 1 | - | - | 21.0 | |
| 2 | - | - | 17.0 | |
| 3 | - | - | 17.0 | |
| 4 | - | - | 15.0 |
| セクションの数 | 平均クラスサイズ | 最小クラスのサイズ | 最大クラスのサイズ | データソース | 学校の生徒と教師の比率 | |
|---|---|---|---|---|---|---|
| 0 | 1.0 | 19.0 | 19.0 | 19.0 | ATS | ナン |
| 1 | 1.0 | 21.0 | 21.0 | 21.0 | ATS | ナン |
| 2 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | ナン |
| 3 | 1.0 | 17.0 | 17.0 | 17.0 | ATS | ナン |
| 4 | 1.0 | 15.0 | 15.0 | 15.0 | ATS | ナン |
ご覧のとおり、DBNはCSD 、 BOROUGH 、およびSCHOOL_ CODEの単なる組み合わせです。 ニューヨークに不慣れな人のために:それは5つの地区で構成されています。 各エリアは、十分に大きい米国の都市とほぼ同じサイズの組織単位です。 DBNは、地区地区番号の略です。 CSDは郡のようで、 BOROUGHは地区であり、 SCHOOL_CODEと組み合わせるとDBNが取得されます。
DBNの作成方法がわかったので、それをclass_sizeとhs_directoryに追加できます。
In [ ]: data["class_size"]["DBN"] = data["class_size"].apply(lambda x: "{0:02d}{1}".format(x["CSD"], x["SCHOOL CODE"]), axis=1) data["hs_directory"]["DBN"] = data["hs_directory"]["dbn"]
アンケートを追加
最も興味深い可能性のあるデータセットの1つは、学校の質に関する学生、保護者、教師の調査のデータセットです。 これらの調査には、各学校の安全性、教育基準などの主観的な認識に関する情報が含まれています。 データセットを結合する前に、調査データを追加しましょう。 実際のデータサイエンスプロジェクトでは、分析中に興味深いデータに出くわすことが多く、そのデータも接続したい場合があります。 Jupyterノートブックなどの柔軟なツールを使用すると、コードをすばやく追加して分析をやり直すことができます。
この例では、追加のポーリングデータをデータディクショナリに追加し、すべてのデータセットを結合します。 調査データは、すべての学校用と学区75用の2つのファイルで構成されています。これらを結合するには、いくつかのコードを記述する必要があります。 その中でそれを行います:
- Windows-1252エンコーディングを使用して、すべての学校のアンケートを読みます
- windows-1252を使用して郡75の投票を読む
- 各データセットがどの地区に属しているかを示すフラグを追加します。
- データフレームでconcatメソッドを使用して、すべてのデータセットを1つに結合します。
In [66]: survey1 = pandas.read_csv("schools/survey_all.txt", delimiter="\t", encoding='windows-1252') survey2 = pandas.read_csv("schools/survey_d75.txt", delimiter="\t", encoding='windows-1252') survey1["d75"] = False survey2["d75"] = True survey = pandas.concat([survey1, survey2], axis=0)
すべての投票を結合するとすぐに、さらなる困難が生じます。 結合されたデータセットの列の数を最小限に抑えて、列を簡単に比較して依存関係を識別できるようにします。 残念ながら、調査データには不必要な列が多く含まれています。
In [16]: survey.head() Out[16]:
| N_p | N_s | N_t | aca_p_11 | aca_s_11 | aca_t_11 | aca_tot_11 | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 90.0 | ナン | 22.0 | 7.8 | ナン | 7.9 | 7.9 | |
| 1 | 161.0 | ナン | 34.0 | 7.8 | ナン | 9.1 | 8.4 | |
| 2 | 367.0 | ナン | 42.0 | 8.6 | ナン | 7.5 | 8.0 | |
| 3 | 151.0 | 145.0 | 29.0 | 8.5 | 7.4 | 7.8 | 7.9 | |
| 4 | 90.0 | ナン | 23.0 | 7.9 | ナン | 8.1 | 8.0 |
| 十億 | com_p_11 | com_s_11 | ... | t_q8c_1 | t_q8c_2 | t_q8c_3 | t_q8c_4 | / | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | M015 | 7.6 | ナン | ... | 29.0 | 67.0 | 5.0 | 0.0 | |
| 1 | M019 | 7.6 | ナン | ... | 74.0 | 21.0 | 6.0 | 0.0 | |
| 2 | M020 | 8.3 | ナン | ... | 33.0 | 35.0 | 20.0 | 13.0 | |
| 3 | M034 | 8.2 | 5.9 | ... | 21.0 | 45.0 | 28.0 | 7.0 | |
| 4 | M063 | 7.9 | ナン | ... | 59.0 | 36.0 | 5.0 | 0.0 |
| t_q9 | t_q9_1 | t_q9_2 | t_q9_3 | t_q9_4 | t_q9_5 | |
|---|---|---|---|---|---|---|
| 0 | ナン | 5.0 | 14.0 | 52.0 | 24.0 | 5.0 |
| 1 | ナン | 3.0 | 6.0 | 3.0 | 78.0 | 9.0 |
| 2 | ナン | 3.0 | 5.0 | 16.0 | 70.0 | 5.0 |
| 3 | ナン | 0.0 | 18.0 | 32.0 | 39.0 | 11.0 |
| 4 | ナン | 10.0 | 5.0 | 10.0 | 60.0 | 15.0 |
これは、調査データとともにダウンロードしたデータ辞書ファイルを調べることで処理できます。 彼は重要な分野について教えてくれます。
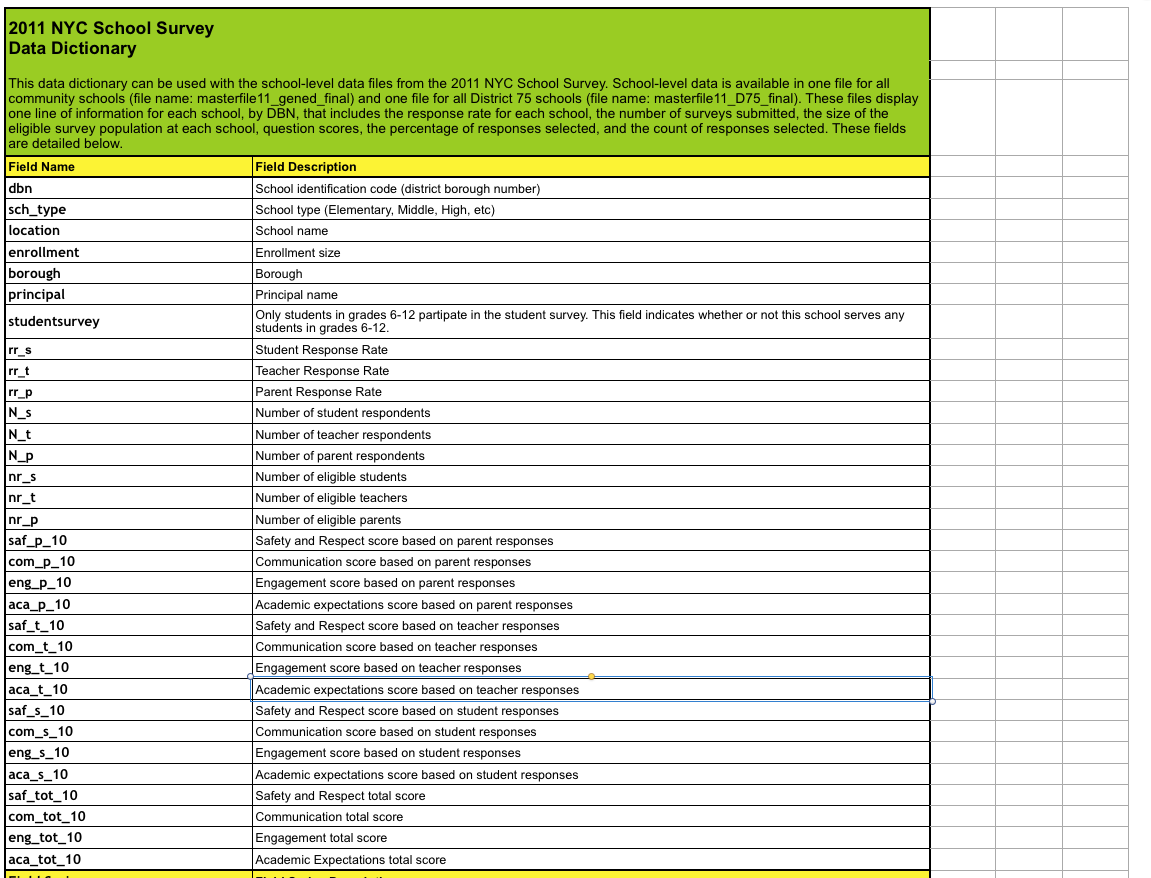
そして、調査で私たちに関係のないすべての列を削除します。
In [17]: survey["DBN"] = survey["dbn"] survey_fields = ["DBN", "rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_p_11", "com_p_11", "eng_p_11", "aca_p_11", "saf_t_11", "com_t_11", "eng_t_10", "aca_t_11", "saf_s_11", "com_s_11", "eng_s_11", "aca_s_11", "saf_tot_11", "com_tot_11", "eng_tot_11", "aca_tot_11",] survey = survey.loc[:,survey_fields] data["survey"] = survey survey.shape Out[17]: (1702, 23)
各データセットが正確に何を含むのか、そしてそれからどの列が重要であるのかを理解することで、将来の時間と労力を大幅に節約できます。
データセットを圧縮します
class_sizeを含むいくつかのデータセットを見ると、すぐに問題がわかります。
In [18]: data["class_size"].head() Out[18]:
| CSD | 自治区 | 学校コード | 学校名 | グレード | プログラムの種類 | CORE SUBJECT(MS COREおよび9-12のみ) | / | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | GEN ED | - | |
| 1 | 1 | M | M015 | PS 015ロベルトクレメンテ | 0K | CTT | - | |
| 2 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | GEN ED | - | |
| 3 | 1 | M | M015 | PS 015ロベルトクレメンテ | 01 | CTT | - | |
| 4 | 1 | M | M015 | PS 015ロベルトクレメンテ | 02 | GEN ED | - |
| コアコース(MSコアおよび9-12のみ) | サービスカテゴリ(K-9 *のみ) | 受講者数/席数 | セクションの数 | 平均クラスサイズ | / | |
|---|---|---|---|---|---|---|
| 0 | - | - | 19.0 | 1.0 | 19.0 | |
| 1 | - | - | 21.0 | 1.0 | 21.0 | |
| 2 | - | - | 17.0 | 1.0 | 17.0 | |
| 3 | - | - | 17.0 | 1.0 | 17.0 | |
| 4 | - | - | 15.0 | 1.0 | 15.0 |
| 最小クラスのサイズ | 最大クラスのサイズ | データソース | 学校の生徒と教師の比率 | Dbn | |
|---|---|---|---|---|---|
| 0 | 19.0 | 19.0 | ATS | ナン | 01M015 |
| 1 | 21.0 | 21.0 | ATS | ナン | 01M015 |
| 2 | 17.0 | 17.0 | ATS | ナン | 01M015 |
| 3 | 17.0 | 17.0 | ATS | ナン | 01M015 |
| 4 | 15.0 | 15.0 | ATS | ナン | 01M015 |
各学校には複数の行があります(重複するフィールドDBNとSCHOOL NAMEから理解できます)。 ただし、 sat_resultsを見ると、学校ごとに1行しかありません。
In [21]: data["sat_results"].head() Out[21]:
| Dbn | 学校名 | SAT受験者数 | SAT Critical Reading Avg。 得点 | SAT Math平均 得点 | SATライティング平均 得点 | |
|---|---|---|---|---|---|---|
| 0 | 01M292 | 国際研究のためのヘンリーストリートスクール | 29日 | 355 | 404 | 363 |
| 1 | 01M448 | 大学近隣高等学校 | 91 | 383 | 423 | 366 |
| 2 | 01M450 | イーストサイドコミュニティスクール | 70 | 377 | 402 | 370 |
| 3 | 01M458 | フォーサイスサテライトアカデミー | 7 | 414 | 401 | 359 |
| 4 | 01M509 | マルタバレーハイスクール | 44 | 390 | 433 | 384 |
これらのデータセットを結合するには、 class_sizeなどのデータセットを圧縮して、高校ごとに1つの行があるようにする方法が必要です。 うまくいかない場合は、うまくいかず、USEグレードをクラスサイズと比較します。 これを実現するには、データをよりよく理解してから、いくつかの集計を実行します。
class_size データセット別-GRADEとPROGRAM TYPEには学校ごとに異なる成績が含まれているようです。 各フィールドを単一の値に制限することにより、重複する行をすべて破棄できます。 以下のコードでは:
- class_sizeからこれらの値のみを選択します。GRADEフィールドは09-12です。
- PROGRAM TYPEフィールドがGEN EDであるclass_sizeからの値のみを選択します。
- class_sizeをDBNでグループ化し、各列の平均を取ります。 本質的に、各学校の平均class_sizeを見つけます。
- DBNが列として再び追加されるように、インデックスをリセットします。
In [68]: class_size = data["class_size"] class_size = class_size[class_size["GRADE "] == "09-12"] class_size = class_size[class_size["PROGRAM TYPE"] == "GEN ED"] class_size = class_size.groupby("DBN").agg(np.mean) class_size.reset_index(inplace=True) data["class_size"] = class_size
残りのデータセットを厚くする
次に、 人口統計データセットを圧縮する必要があります。 同じ学校について数年にわたって収集されたデータ。 schoolyearフィールドがすべての中で最も新しい行のみを選択します。
In [69]: demographics = data["demographics"] demographics = demographics[demographics["schoolyear"] == 20112012] data["demographics"] = demographics
次に、math_test_results データセットを圧縮する必要があります。 GradeとYearの値で除算されます。 1年間で1つのクラスを選択できます。
In [70]: data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Year"] == 2011] data["math_test_results"] = data["math_test_results"][data["math_test_results"]["Grade"] ==
最後に、 卒業も凝縮する必要があります。
In [71]: data["graduation"] = data["graduation"][data["graduation"]["Cohort"] == "2006"] data["graduation"] = data["graduation"][data["graduation"]["Demographic"] == "Total Cohort"]
プロジェクトの本質に取り組む前に、データをクリーンアップして調査することが重要です。 いいね 合う 包括的なデータセットは、分析を高速化するのに役立ちます。
集約変数の計算
変数の計算は、比較をより高速に行う機能により分析を高速化し、原則として、変数なしでは不可能ないくつかの比較を可能にします。 最初にできることは、個々のSAT Math Avg列から合計試験スコアを計算することです。 スコア 、 SATクリティカルリーディング平均 スコア 、およびSAT Writing Avg。 スコア 。 以下のコードでは:
- 各試験のスコアを行から数値に変換します
- すべての列を追加し、合計試験スコアであるsat_score列を取得します。
In [72]: cols = ['SAT Math Avg. Score', 'SAT Critical Reading Avg. Score', 'SAT Writing Avg. Score'] for c in cols: data["sat_results"][c] = data["sat_results"][c].convert_objects(convert_numeric=True) data['sat_results']['sat_score'] = data['sat_results'][cols[0]] + data['sat_results'][cols[1]]
次に、各学校の座標を解析してマップを作成する必要があります。 彼らは私たちが各学校の状況を記録できるようにします。 コードでは:
- 緯度と経度の列に解析する場所1の列
- latとlonを数値に変換します。
データセットを表示し、何が起こったかを確認します。
In [74]: for k,v in data.items(): print(k) print(v.head())
math_test_results
| Dbn | グレード | 年 | カテゴリー | テスト済みの数 | 平均スケールスコア | \ | |
|---|---|---|---|---|---|---|---|
| 111 | 01M034 | 8 | 2011 | すべての学生 | 48 | 646 | |
| 280 | 01M140 | 8 | 2011 | すべての学生 | 61 | 665 | |
| 346 | 01M184 | 8 | 2011 | すべての学生 | 49 | 727 | |
| 388 | 01M188 | 8 | 2011 | すべての学生 | 49 | 658 | |
| 411 | 01M292 | 8 | 2011 | すべての学生 | 49 | 650 |
| レベル1# | レベル1% | レベル2# | レベル2% | レベル3# | レベル3% | レベル4# | \ | |
|---|---|---|---|---|---|---|---|---|
| 111 | 15 | 31.3% | 22 | 45.8% | 11 | 22.9% | 0 | |
| 280 | 1 | 1.6% | 43 | 70.5% | 17 | 27.9% | 0 | |
| 346 | 0 | 0% | 0 | 0% | 5 | 10.2% | 44 | |
| 388 | 10 | 20.4% | 26 | 53.1% | 10 | 20.4% | 3 | |
| 411 | 15 | 30.6% | 25 | 51% | 7 | 14.3% | 2 |
| レベル4% | レベル3 + 4# | レベル3 + 4% | |
|---|---|---|---|
| 111 | 0% | 11 | 22.9% |
| 280 | 0% | 17 | 27.9% |
| 346 | 89.8% | 49 | 100% |
| 388 | 6.1% | 13 | 26.5% |
| 411 | 4.1% | 9 | 18.4% |
調査
| Dbn | rr_s | rr_t | rr_p | N_s | N_t | N_p | saf_p_11 | com_p_11 | eng_p_11 | \ | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 01M015 | ナン | 88 | 60 | ナン | 22.0 | 90.0 | 8.5 | 7.6 | 7.5 | |
| 1 | 01M019 | ナン | 100 | 60 | ナン | 34.0 | 161.0 | 8.4 | 7.6 | 7.6 | |
| 2 | 01M020 | ナン | 88 | 73 | ナン | 42.0 | 367.0 | 8.9 | 8.3 | 8.3 | |
| 3 | 01M034 | 89.0 | 73 | 50 | 145.0 | 29.0 | 151.0 | 8.8 | 8.2 | 8.0 | |
| 4 | 01M063 | ナン | 100 | 60 | ナン | 23.0 | 90.0 | 8.7 | 7.9 | 8.1 |
| ... | eng_t_10 | aca_t_11 | saf_s_11 | com_s_11 | eng_s_11 | aca_s_11 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | ... | ナン | 7.9 | ナン | ナン | ナン | ナン | |
| 1 | ... | ナン | 9.1 | ナン | ナン | ナン | ナン | |
| 2 | ... | ナン | 7.5 | ナン | ナン | ナン | ナン | |
| 3 | ... | ナン | 7.8 | 6.2 | 5.9 | 6.5 | 7.4 | |
| 4 | ... | ナン | 8.1 | ナン | ナン | ナン | ナン |
| saf_tot_11 | com_tot_11 | eng_tot_11 | aca_tot_11 | |
|---|---|---|---|---|
| 0 | 8.0 | 7.7 | 7.5 | 7.9 |
| 1 | 8.5 | 8.1 | 8.2 | 8.4 |
| 2 | 8.2 | 7.3 | 7.5 | 8.0 |
| 3 | 7.3 | 6.7 | 7.1 | 7.9 |
| 4 | 8.5 | 7.6 | 7.9 | 8.0 |
ap_2010
| Dbn | 学校名 | AP受験者 | 合計試験数 | スコア3 4または5の試験の数 | |
|---|---|---|---|---|---|
| 0 | 01M448 | 大学ネイバーフッドHS | 39 | 49 | 10 |
| 1 | 01M450 | イーストサイドコミュニティHS | 19 | 21 | s |
| 2 | 01M515 | イーストサイドの下ごしらえ | 24 | 26 | 24 |
| 3 | 01M539 | 新しい探査SCI、TECH、MATH | 255 | 377 | 191 |
| 4 | 02M296 | ホスピタリティマネジメントの高校 | s | s | s |
sat_results
| Dbn | 学校名 | SAT受験者数 | SAT Critical Reading Avg。 得点 | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | 国際研究のためのヘンリーストリートスクール | 29日 | 355.0 | |
| 1 | 01M448 | 大学近隣高等学校 | 91 | 383.0 | |
| 2 | 01M450 | イーストサイドコミュニティスクール | 70 | 377.0 | |
| 3 | 01M458 | フォーサイスサテライトアカデミー | 7 | 414.0 | |
| 4 | 01M509 | マルタバレーハイスクール | 44 | 390.0 |
| SAT Math平均 得点 | SATライティング平均 得点 | sat_score | |
|---|---|---|---|
| 0 | 404.0 | 363.0 | 1122.0 |
| 1 | 423.0 | 366.0 | 1172.0 |
| 2 | 402.0 | 370.0 | 1149.0 |
| 3 | 401.0 | 359.0 | 1174.0 |
| 4 | 433.0 | 384.0 | 1207.0 |
class_size
| Dbn | CSD | 受講者数/席数 | セクションの数 | \ | |
|---|---|---|---|---|---|
| 0 | 01M292 | 1 | 88.0000 | 4.000000 | |
| 1 | 01M332 | 1 | 46.0000 | 2.000000 | |
| 2 | 01M378 | 1 | 33.0000 | 1.000000 | |
| 3 | 01M448 | 1 | 105.6875 | 4.750000 | |
| 4 | 01M450 | 1 | 57.6000 | 2.733333 |
| 平均クラスサイズ | 最小クラスのサイズ | 最大クラスのサイズ | 学校の生徒と教師の比率 | |
|---|---|---|---|---|
| 0 | 22.564286 | 18.50 | 26.571429 | ナン |
| 1 | 22.000000 | 午後9時 | 23.500000 | ナン |
| 2 | 33.000000 | 33.00 | 33.000000 | ナン |
| 3 | 22.231250 | 18.25 | 06/27/2500 | ナン |
| 4 | 21.200000 | 19.40 | 22.866667 | ナン |
人口統計
| Dbn | お名前 | 学年 | \ | |
|---|---|---|---|---|
| 6 | 01M015 | PS 015ロベルトクレメンテ | 20112012 | |
| 13 | 01M019 | PS 019アシャーレヴィー | 20112012 | |
| 20 | 01M020 | PS 020アンナシルバー | 20112012 | |
| 27 | 01M034 | PS 034フランクリンDルーズヴェルト | 20112012 | |
| 35 | 01M063 | PS 063ウィリアム・マッキンレー | 20112012 |
| fl_percent | frl_percent | total_enrollment | プレック | k | グレード1 | グレード2 | \ | |
|---|---|---|---|---|---|---|---|---|
| 6 | ナン | 89.4 | 189 | 13 | 31 | 35 | 28 | |
| 13 | ナン | 61.5 | 328 | 32 | 46 | 52 | 54 | |
| 20 | ナン | 92.5 | 626 | 52 | 102 | 121 | 87 | |
| 27 | ナン | 99.7 | 401 | 14 | 34 | 38 | 36 | |
| 35 | ナン | 78.9 | 176 | 18 | 20 | 30 | 21 |
| ... | black_num | black_per | hispanic_num | hispanic_per | white_num | \ | |
|---|---|---|---|---|---|---|---|
| 6 | ... | 63 | 33.3 | 109 | 57.7 | 4 | |
| 13 | ... | 81 | 24.7 | 158 | 48.2 | 28 | |
| 20 | ... | 55 | 8.8 | 357 | 57.0 | 16 | |
| 27 | ... | 90 | 22.4 | 275 | 68.6 | 8 | |
| 35 | ... | 41 | 23.3 | 110 | 62.5 | 15 |
| white_per | male_num | male_per | female_num | female_per | |
|---|---|---|---|---|---|
| 6 | 2.1 | 97.0 | 51.3 | 92.0 | 48.7 |
| 13 | 8.5 | 147.0 | 44.8 | 181.0 | 55.2 |
| 20 | 2.6 | 330.0 | 52.7 | 296.0 | 47.3 |
| 27 | 2.0 | 204.0 | 50.9 | 197.0 | 49.1 |
| 35 | 8.5 | 97.0 | 55.1 | 79.0 | 44.9 |
卒業
| 人口統計 | Dbn | 学校名 | コホート | \ | |
|---|---|---|---|---|---|
| 3 | 総コホート | 01M292 | ヘンリーストリートスクールフォーインターナショナル | 2006 | |
| 10 | 総コホート | 01M448 | 大学近隣高等学校 | 2006 | |
| 17 | 総コホート | 01M450 | イーストサイドコミュニティスクール | 2006 | |
| 24 | 総コホート | 01M509 | マルタバレーハイスクール | 2006 | |
| 31 | 総コホート | 01M515 | 下部東側準備高等学校 | 2006 |
| 総コホート | 総卒業-n | 総卒業生-コホートの割合 | 合計リージェント-n | \ | |
|---|---|---|---|---|---|
| 3 | 78 | 43 | 55.1% | 36 | |
| 10 | 124 | 53 | 42.7% | 42 | |
| 17 | 90 | 70 | 77.8% | 67 | |
| 24 | 84 | 47 | 56% | 40 | |
| 31 | 193 | 105 | 54.4% | 91 |
| 総リージェント-コホートの% | 総リージェント-卒業生の割合 | ... | 高度なしのリージェント-n | \ | |
|---|---|---|---|---|---|
| 3 | 46.2% | 83.7% | ... | 36 | |
| 10 | 33.9% | 79.2% | ... | 34 | |
| 17 | 74.400000000000006% | 95.7% | ... | 67 | |
| 24 | 47.6% | 85.1% | ... | 23 | |
| 31 | 47.2% | 86.7% | ... | 22 |
| Regents w/o Advanced — % of cohort | Regents w/o Advanced — % of grads | \ | |
|---|---|---|---|
| 3 | 46.2% | 83.7% | |
| 10 | 27.4% | 64.2% | |
| 17 | 74.400000000000006% | 95.7% | |
| 24 | 27.4% | 48.9% | |
| 31 | 11.4% | 21% |
| Local — n | Local — % of cohort | Local — % of grads | Still Enrolled — n | \ | |
|---|---|---|---|---|---|
| 3 | 7 | 9% | 16.3% | 16 | |
| 10 | 11 | 8.9% | 20.8% | 46 | |
| 17 | 3 | 3.3% | 4.3% | 15 | |
| 24 | 7 | 8.300000000000001% | 14.9% | 25 | |
| 31 | 14 | 7.3% | 13.3% | 53 |
| Still Enrolled — % of cohort | Dropped Out — n | Dropped Out — % of cohort | |
|---|---|---|---|
| 3 | 20.5% | 11 | 14.1% |
| 10 | 37.1% | 20 | 16.100000000000001% |
| 17 | 16.7% | 5 | 5.6% |
| 24 | 29.8% | 5 | 6% |
| 31 | 27.5% | 35 | 18.100000000000001% |
hs_directory
| dbn | school_name | boro | \ | |
|---|---|---|---|---|
| 0 | 17K548 | Brooklyn School for Music & Theatre | Brooklyn | |
| 1 | 09X543 | High School for Violin and Dance | Bronx | |
| 2 | 09X327 | Comprehensive Model School Project MS 327 | Bronx | |
| 3 | 02M280 | Manhattan Early College School for Advertising | マンハッタン | |
| 4 | 28Q680 | Queens Gateway to Health Sciences Secondary Sc... | Queens |
| building_code | phone_number | fax_number | grade_span_min | grade_span_max | \ | |
|---|---|---|---|---|---|---|
| 0 | K440 | 718-230-6250 | 718-230-6262 | 9 | 12 | |
| 1 | X400 | 718-842-0687 | 718-589-9849 | 9 | 12 | |
| 2 | X240 | 718-294-8111 | 718-294-8109 | 6 | 12 | |
| 3 | M520 | 718-935-3477 | ナン | 9 | 10 | |
| 4 | Q695 | 718-969-3155 | 718-969-3552 | 6 | 12 |
| expgrade_span_min | expgrade_span_max | ... | priority05 | priority06 | priority07 | priority08 | \ | |
|---|---|---|---|---|---|---|---|---|
| 0 | ナン | ナン | ... | ナン | ナン | ナン | ナン | |
| 1 | ナン | ナン | ... | ナン | ナン | ナン | ナン | |
| 2 | ナン | ナン | ... | Then to New York City residents | ナン | ナン | ナン | |
| 3 | 9 | 14.0 | ... | ナン | ナン | ナン | ナン | |
| 4 | ナン | ナン | ... | ナン | ナン | ナン | ナン |
| priority09 | priority10 | Location 1 | \ | |
|---|---|---|---|---|
| 0 | ナン | ナン | 883 Classon Avenue\nBrooklyn, NY 11225\n(40.67... | |
| 1 | ナン | ナン | 1110 Boston Road\nBronx, NY 10456\n(40.8276026... | |
| 2 | ナン | ナン | 1501 Jerome Avenue\nBronx, NY 10452\n(40.84241... | |
| 3 | ナン | ナン | 411 Pearl Street\nNew York, NY 10038\n(40.7106... | |
| 4 | ナン | ナン | 160-20 Goethals Avenue\nJamaica, NY 11432\n(40... |
| DBN | lat | lon | |
|---|---|---|---|
| 0 | 17K548 | 40.670299 | -73.961648 |
| 1 | 09X543 | 40.827603 | -73.904475 |
| 2 | 09X327 | 40.842414 | -73.916162 |
| 3 | 02M280 | 40.710679 | -74.000807 |
| 4 | 28Q680 | 40.718810 | -73.806500 |
, DBN. , . , , sat_results . , outer join, . — . — .
:
- data
- DBN
- , — .
- full DBN .
In [75]: flat_data_names = [k for k,v in data.items()] flat_data = [data[k] for k in flat_data_names] full = flat_data[0] for i, f in enumerate(flat_data[1:]): name = flat_data_names[i+1] print(name) print(len(f["DBN"]) - len(f["DBN"].unique())) join_type = "inner" if name in ["sat_results", "ap_2010", "graduation"]: join_type = "outer" if name not in ["math_test_results"]: full = full.merge(f, on="DBN", how=join_type) full.shape survey 0 ap_2010 1 sat_results 0 class_size 0 demographics 0 graduation 0 hs_directory 0 Out[75]: (374, 174)
, full , . . , , :
In [76]: cols = ['AP Test Takers ', 'Total Exams Taken', 'Number of Exams with scores 3 4 or 5'] for col in cols: full[col] = full[col].convert_objects(convert_numeric=True) full[cols] = full[cols].fillna(value=0)
, school_dist , . , :
In [77]: full["school_dist"] = full["DBN"].apply(lambda x: x[:2])
, full ,
In [79]: full = full.fillna(full.mean())
, , — . , . corr Pandas. 0 — . 1 — . -1 — :
In [80]: full.corr()['sat_score'] Out[80]: Year NaN Number Tested 8.127817e-02 rr_s 8.484298e-02 rr_t -6.604290e-02 rr_p 3.432778e-02 N_s 1.399443e-01 N_t 9.654314e-03 N_p 1.397405e-01 saf_p_11 1.050653e-01 com_p_11 2.107343e-02 eng_p_11 5.094925e-02 aca_p_11 5.822715e-02 saf_t_11 1.206710e-01 com_t_11 3.875666e-02 eng_t_10 NaN aca_t_11 5.250357e-02 saf_s_11 1.054050e-01 com_s_11 4.576521e-02 eng_s_11 6.303699e-02 aca_s_11 8.015700e-02 saf_tot_11 1.266955e-01 com_tot_11 4.340710e-02 eng_tot_11 5.028588e-02 aca_tot_11 7.229584e-02 AP Test Takers 5.687940e-01 Total Exams Taken 5.585421e-01 Number of Exams with scores 3 4 or 5 5.619043e-01 SAT Critical Reading Avg. Score 9.868201e-01 SAT Math Avg. Score 9.726430e-01 SAT Writing Avg. Score 9.877708e-01 ... SIZE OF SMALLEST CLASS 2.440690e-01 SIZE OF LARGEST CLASS 3.052551e-01 SCHOOLWIDE PUPIL-TEACHER RATIO NaN schoolyear NaN frl_percent -7.018217e-01 total_enrollment 3.668201e-01 ell_num -1.535745e-01 ell_percent -3.981643e-01 sped_num 3.486852e-02 sped_percent -4.413665e-01 asian_num 4.748801e-01 asian_per 5.686267e-01 black_num 2.788331e-02 black_per -2.827907e-01 hispanic_num 2.568811e-02 hispanic_per -3.926373e-01 white_num 4.490835e-01 white_per 6.100860e-01 male_num 3.245320e-01 male_per -1.101484e-01 female_num 3.876979e-01 female_per 1.101928e-01 Total Cohort 3.244785e-01 grade_span_max -2.495359e-17 expgrade_span_max NaN zip -6.312962e-02 total_students 4.066081e-01 number_programs 1.166234e-01 lat -1.198662e-01 lon -1.315241e-01 Name: sat_score, dtype: float64
, :
- ( total_enrollment ) ( sat_score ), , , , , , .
- ( female_per ) , ( male_per ) — .
- .
- ( white_per , asian_per , black_per , hispanic_per ).
- ell_percent .
— .
, ( ) . , , , — .
, , . , . .
, , , , , . — . , , .
:
- -
In [82]: import folium from folium import plugins schools_map = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10) marker_cluster = folium.MarkerCluster().add_to(schools_map) for name, row in full.iterrows(): folium.Marker([row["lat"], row["lon"]], popup="{0}: {1}".format(row["DBN"], row["school_name"])).add_to(marker_cluster) schools_map.create_map('schools.html') schools_map Out[82]:
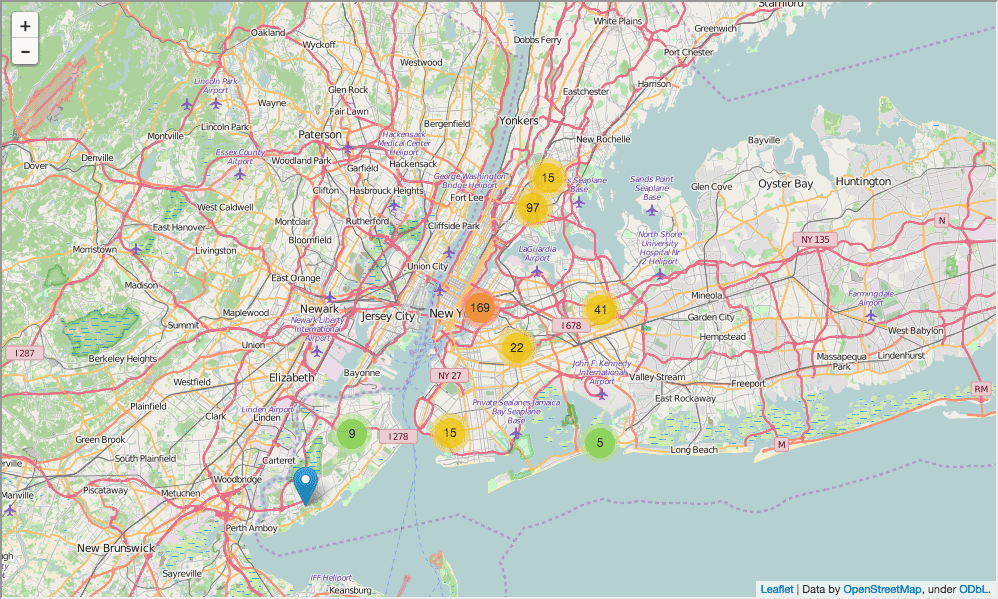
, , - . :
In [84]: schools_heatmap = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10) schools_heatmap.add_children(plugins.HeatMap([[row["lat"], row["lon"]] for name, row in full.iterrows()])) schools_heatmap.save("heatmap.html") schools_heatmap Out[84]:
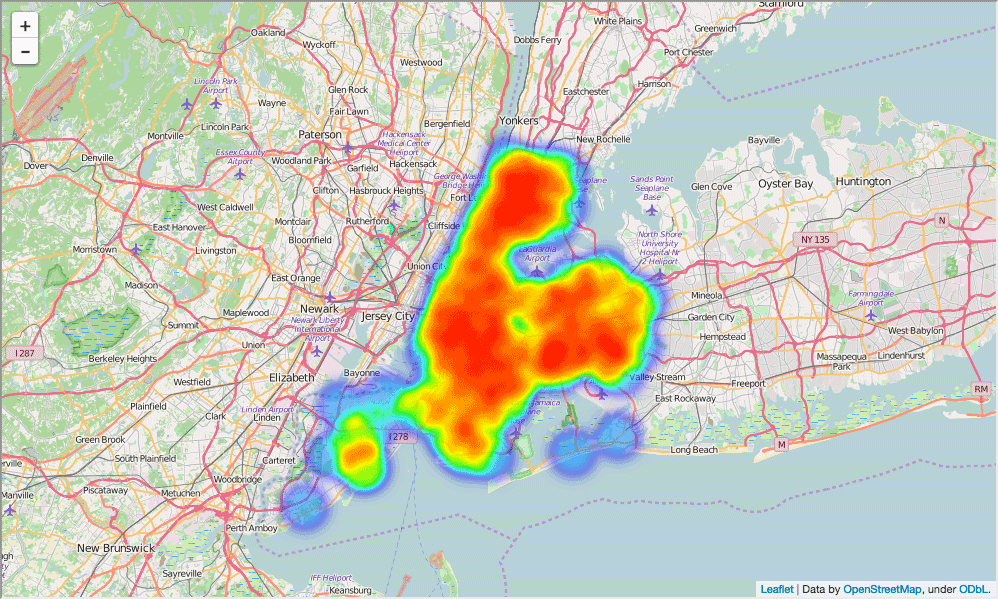
, - , . , .. . - , .
. :
- full
- school_dist , ,
In [ ]: district_data = full.groupby("school_dist").agg(np.mean) district_data.reset_index(inplace=True) district_data["school_dist"] = district_data["school_dist"].apply(lambda x: str(int(x))
. GeoJSON , , school_dist , , , .
In [85]: def show_district_map(col): geo_path = 'schools/districts.geojson' districts = folium.Map(location=[full['lat'].mean(), full['lon'].mean()], zoom_start=10) districts.geo_json( geo_path=geo_path, data=district_data, columns=['school_dist', col], key_on='feature.properties.school_dist', fill_color='YlGn', fill_opacity=0.7, line_opacity=0.2, ) districts.save("districts.html") return districts show_district_map("sat_score") Out[85]:

, ; , . , , . — , , .
, :
In [87]: %matplotlib inline full.plot.scatter(x='total_enrollment', y='sat_score') Out[87]: <matplotlib.axes._subplots.AxesSubplot at 0x10fe79978>
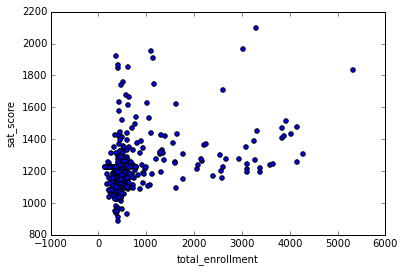
, . , . .
, :
In [88]: full[(full["total_enrollment"] < 1000) & (full["sat_score"] < 1000)]["School Name"] Out[88]: 34 INTERNATIONAL SCHOOL FOR LIBERAL ARTS 143 NaN 148 KINGSBRIDGE INTERNATIONAL HIGH SCHOOL 203 MULTICULTURAL HIGH SCHOOL 294 INTERNATIONAL COMMUNITY HIGH SCHOOL 304 BRONX INTERNATIONAL HIGH SCHOOL 314 NaN 317 HIGH SCHOOL OF WORLD CULTURES 320 BROOKLYN INTERNATIONAL HIGH SCHOOL 329 INTERNATIONAL HIGH SCHOOL AT PROSPECT 331 IT TAKES A VILLAGE ACADEMY 351 PAN AMERICAN INTERNATIONAL HIGH SCHOO Name: School Name, dtype: object
, , , , , . , — , , .
, , . ell_percent - . :
In [89]: full.plot.scatter(x='ell_percent', y='sat_score') Out[89]: <matplotlib.axes._subplots.AxesSubplot at 0x10fe824e0>
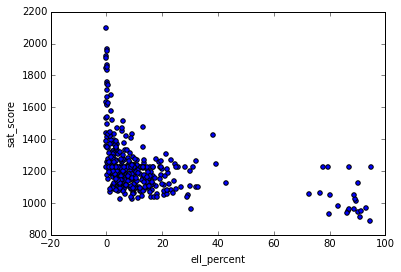
, ell_percentage . , , :
In [90]: show_district_map("ell_percent") Out[90]:
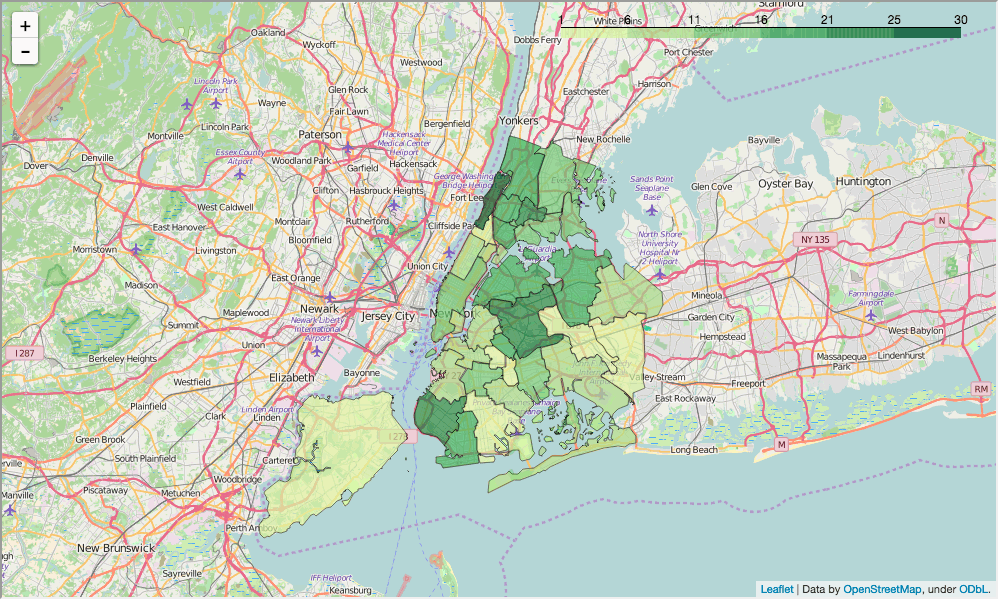
, , .
, , . , . :
In [91]: full.corr()["sat_score"][["rr_s", "rr_t", "rr_p", "N_s", "N_t", "N_p", "saf_tot_11", "com_tot_11", "aca_tot_11", "eng_tot_11"]].plot.bar() Out[91]: <matplotlib.axes._subplots.AxesSubplot at 0x114652400>
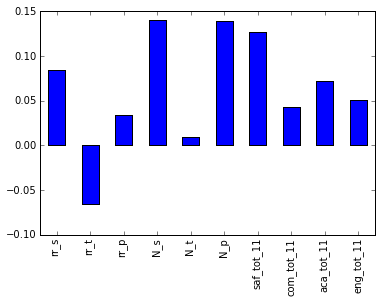
, N_p N_s , . , ell_learners . — saf_t_11 . , , . , , — . , , , , . , - , ( — , ).
. , , :
In [92]: full.corr()["sat_score"][["white_per", "asian_per", "black_per", "hispanic_per"]].plot.bar() Out[92]: <matplotlib.axes._subplots.AxesSubplot at 0x108166ba8>

, , . , , . , :
In [93]: show_district_map("hispanic_per") Out[93]:

, - , .
— . , . :
In [94]: full.corr()["sat_score"][["male_per", "female_per"]].plot.bar() Out[94]: <matplotlib.axes._subplots.AxesSubplot at 0x10774d0f0>

, female_per sat_score :
In [95]: full.plot.scatter(x='female_per', y='sat_score') Out[95]: <matplotlib.axes._subplots.AxesSubplot at 0x104715160>
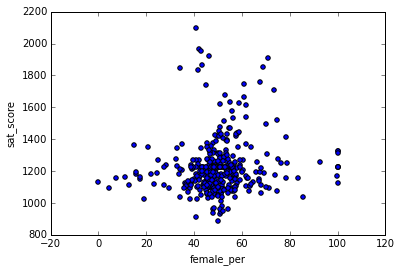
, ( ). :
In [96]: full[(full["female_per"] > 65) & (full["sat_score"] > 1400)]["School Name"] Out[96]: 3 PROFESSIONAL PERFORMING ARTS HIGH SCH 92 ELEANOR ROOSEVELT HIGH SCHOOL 100 TALENT UNLIMITED HIGH SCHOOL 111 FIORELLO H. LAGUARDIA HIGH SCHOOL OF 229 TOWNSEND HARRIS HIGH SCHOOL 250 FRANK SINATRA SCHOOL OF THE ARTS HIGH SCHOOL 265 BARD HIGH SCHOOL EARLY COLLEGE Name: School Name, dtype: object
, , . . , , , , , .
, 100 ( ).
. , — , , . , , .
In [98]: full["ap_avg"] = full["AP Test Takers "] / full["total_enrollment"] full.plot.scatter(x='ap_avg', y='sat_score') Out[98]: <matplotlib.axes._subplots.AxesSubplot at 0x11463a908>

, . , :
In [99]: full[(full["ap_avg"] > .3) & (full["sat_score"] > 1700)]["School Name"] Out[99]: 92 ELEANOR ROOSEVELT HIGH SCHOOL 98 STUYVESANT HIGH SCHOOL 157 BRONX HIGH SCHOOL OF SCIENCE 161 HIGH SCHOOL OF AMERICAN STUDIES AT LE 176 BROOKLYN TECHNICAL HIGH SCHOOL 229 TOWNSEND HARRIS HIGH SCHOOL 243 QUEENS HIGH SCHOOL FOR THE SCIENCES A 260 STATEN ISLAND TECHNICAL HIGH SCHOOL Name: School Name, dtype: object
, , , . , .
data science - . , . , , , .
— . — - . — , .
, , . :)
次は何ですか
— , .
Dataquest , , . — .