
一連の記事「保険会社の機械学習」
1. 現実的なアイデア 。
2. アルゴリズムを研究します 。
3. アルゴリズムの最適化によるモデルの改善 。
データの前処理のためにAzureにPythonスクリプトを埋め込む機能を使用する
最初の記事では、AzureがPythonスクリプトの使用をどのようにサポートするかについて説明しました。 これに必要なモジュールは、2つのデータセットと、追加のマテリアル(たとえば、他のスクリプト、ライブラリなど)を含むzipアーカイブを受け入れることができます。
簡単な例:最終評価の最初の記事では、クラスによって不均衡なテストサンプルについて発言がありました。 選択全体から余分な行を除外するスキームに簡単なスクリプトを導入することで、状況を修正できます。 デモンストレーションとして、次の方法でこれを行います(他の方法も可能です)。

このモジュールは、変更されたデータ配列を返します。これには、後で説明するように、両方のクラスの同数のレコードが含まれます。
使用されたデータの分析。 MS Analysis Serviceを使用する
ほとんどすべての機械学習タスクでは、生データでは満足のいく結果が得られません。 モデルの最も有益な機能を選択するには、データマイニングが必要です。
前の記事で説明したプロトタイプでは、2種類のデータが使用されました。過去3か月間の患者の訪問回数と、この訪問に費やされた最後の金額です。 まず、追加します:
- 年齢
- idを診断します。
- 過去3か月間のコストのピーク数。
ただし、この方法では、処理せずに記号の数を増やすだけです。 これを行うには、MS Analysis Servicesを使用します。MSAnalysis Servicesは、機械学習を使用して、機能、特に簡易ベイズアルゴリズムを抽出します。

結果に基づいて、入力データのバイナリ表現の境界を選択できます。 たとえば、「19歳未満」および「医師への訪問回数が5未満」は、ピークがない可能性が高いことを示します。 一方、「64歳以上」と「14歳以上の通話数」には来月のコストがかかります。
他の人よりも多くの費用がかかる診断のリストを取得できます。
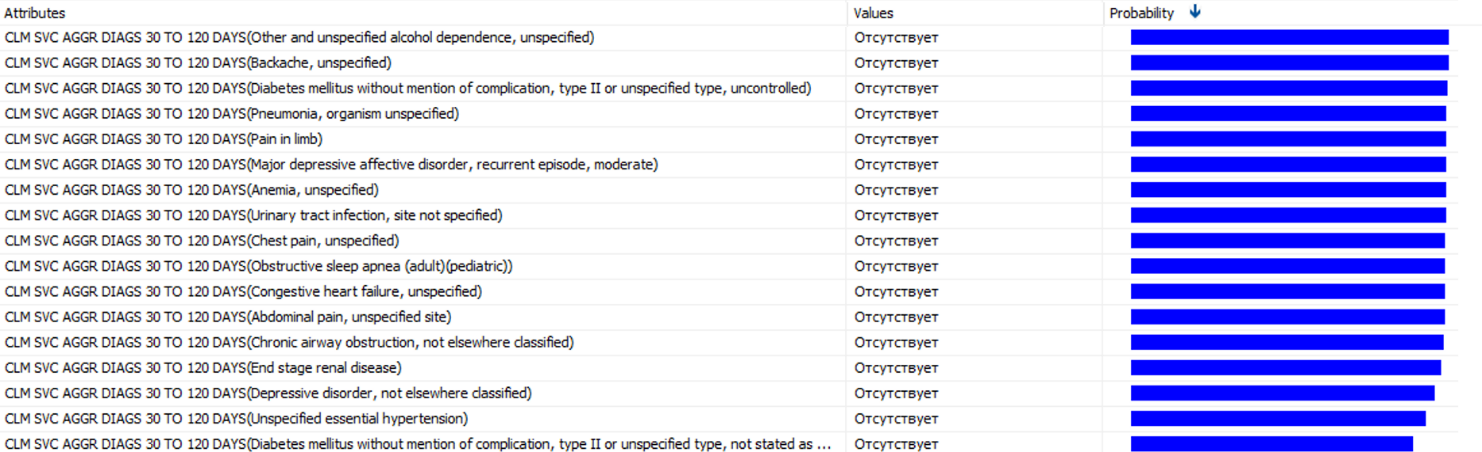
これは、選択した診断の一部にすぎません。 85%から100%の確率で、各診断でコストのピークが続きます。 それらの存在は、別個の兆候として取り上げられるべきです。 会社に多大な費用がかからないという通常の診断の存在をお見逃しなく。 したがって、見つかった確率を正規化し、過去90日間の診断数の加重合計となる新しい兆候を導入する必要があります。
その結果、入力特徴ベクトルで7つのパラメーターが取得されました。 異なるアルゴリズムを使用して前回取得したものと比較します。
さまざまなアルゴリズムのテストとパラメーターの設定
トレーニングに使用するパラメーターを決定しました。 ロジスティック回帰、サポートベクターマシン、決定ジャングル/ランダムフォレスト、ベイジアンネットワークなど、いくつかの異なる分類アルゴリズムを検討してください。 ニューラルネットワークも明らかなオプションですが、これは別の複雑なトピックであり、この場合、このアルゴリズムは冗長になります。
バランスの取れたサンプルを取得するためにデータがフィルター処理されたため、現時点ではクラス割り当ての境界値を変更しません。 次の記事でこの問題に戻ります。
ロジスティック回帰
これは、分類問題に適応した線形リグレッサーの特殊なケースです。 このアルゴリズムは、最初の記事で既に言及されており、プロトタイプとして最も単純なモデルを構築するために使用されました。
初期段階では、マイナスからプラスの無限大の範囲で初期値を取得できます。 次に、形式1 /(1 + e ^(-スコア))のシグモイド関数を使用して変換を実行します。スコアは以前に取得した値であるため、変換を実行します。 結果は、-1〜+1の数値になります。 クラスメンバーシップの決定は、選択したしきい値に基づいて行われます。
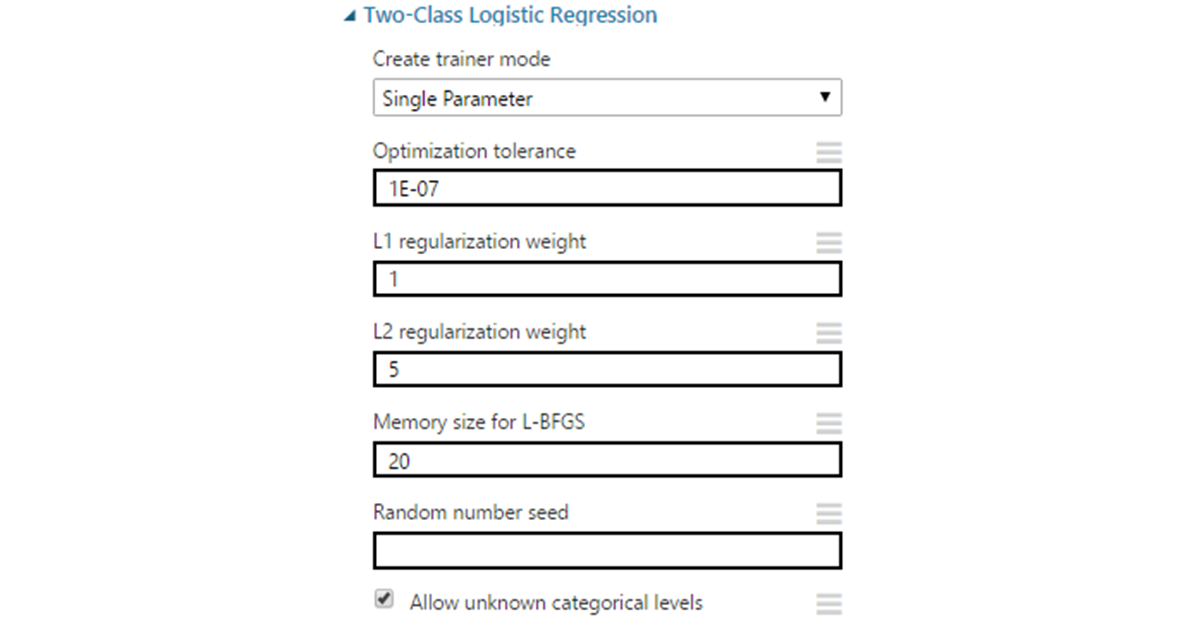
パラメータ:
- 最適化公差 -精度の最小変化の境界。 反復間の差が指定値より小さくなると、学習は停止します。 ほとんどの場合、デフォルト値の1E-7のままでかまいません。
- L1とL2の正則化 -1次と2次の規範による正則化。 L1は、結果への影響が最も少ないフィーチャを削除することにより、入力データの次元を削減するために使用されます。 L2は大きな係数を持つフィーチャを「微調整」し、これらの係数を無限大でゼロに減らします。 示されている値は標準の係数であり、初期設定ではデフォルトで1のままにすることができます。
- L-BFGSは、メモリを制限せずに、非線形汎関数の極大(最小)を見つけるための最適化手法です。 これは、モデルパラメータの重み付けに使用される準ニュートン法(勾配の変更による目的関数の曲率に関する情報の蓄積に基づく)です。 ここで、選択は設定に依存します。設定値は、関数ヘッセ行列の反転に使用されるデータ量に影響します。 実際、指定された数の最近のベクトルが取得されます。 この値を大きくすると、精度が向上します。 特定の制限を改善します(再トレーニングも忘れないでください)。 同時に、実行時間が大幅に増加する可能性があるため、多くの場合10近くに設定されます。
- アルゴリズムの異なる実行で同じ結果を得るために、必要に応じてランダムシードを設定できます。

このアルゴリズムはプロトタイプモデルで使用されたため、比較が最も顕著になります。 クラス定義の境界を設定せず、入力特徴ベクトルに少し追加しただけでも、正しく予測されたピークの割合は5%増加し、不在ピークは15%増加しました。 このグラフの曲線下面積などの重要な指標も大幅に成長しています。 このパラメーターは、異なる境界値でのクラス値の相互関係を反映しています。 曲線が対角線から遠ければ遠いほど良い。
サポートベクターマシン
サポートベクトルメソッドは線形分類器のグループに含まれていますが、アルゴリズムの主要部分に対するいくつかの変更により、非線形分類器の構築も可能になります。 一番下の行は、ソースデータをより高い次元に変換し、分離する超平面を構築することです。 元のベクトルは多くの場合線形に分離できないため、次元を増やす必要があります。 変換後、クラス境界を示す超平面への最大クリアランスの条件で超平面が検索されます。

パラメータ:
- 反復回数 -学習アルゴリズムの反復回数。 これは、アルゴリズムの精度と速度を変更するためのパラメーターです。 まず、1〜10の範囲の値を設定できます。
- ラムダ -ロジスティック回帰におけるL1の重みアナログ
- 機能の正規化 -トレーニング前のデータの正規化。 メソッドの仕様により、ほとんどの場合、デフォルトでパラメーターを有効のままにしておく必要があります。
- 単位球への投影 -係数の正規化。 このパラメーターはオプションであり、ほとんどの場合必要ありません。
- 不明なカテゴリを許可 -デフォルトでは含まれているパラメータで、不明なモデルパラメータの処理を許可します。 分類器に既知のデータを使用してモデルの作業を低下させ、未知のものの精度を向上させます。
- ランダムシード -ロジスティック回帰に似ています。

グラフは、これがこのタスクで最も成功したアルゴリズムではないことを示しています。 精度と曲線下面積が低い。 さらに、曲線自体は不安定であり、プロトタイプでは受け入れられますが、処理されたデータを含むモデルでは受け入れられません。
ベイジアンネットワーク
ベイジアンネットワークは、非周期的な有向グラフの形で提示される確率的データモデルです。 グラフの頂点は特定の判断の真実を反映する変数であり、エッジはそれらの間の依存度です。 モデルを設定するには、これらの変数とそれらの間の関係を選択する必要があります。 私たちの場合、グラフが収束する最終的な価値提案は、コストのピークの存在です。

パラメータ:
- トレーニングの反復回数 -SVMのパラメーターに似ています。
- バイアスを含める -モデルの入力パラメーターに定数値を導入します。 これは、元のベクターにない場合に必要です。
- 不明な値を許可 -SVMのパラメーターに似ています。
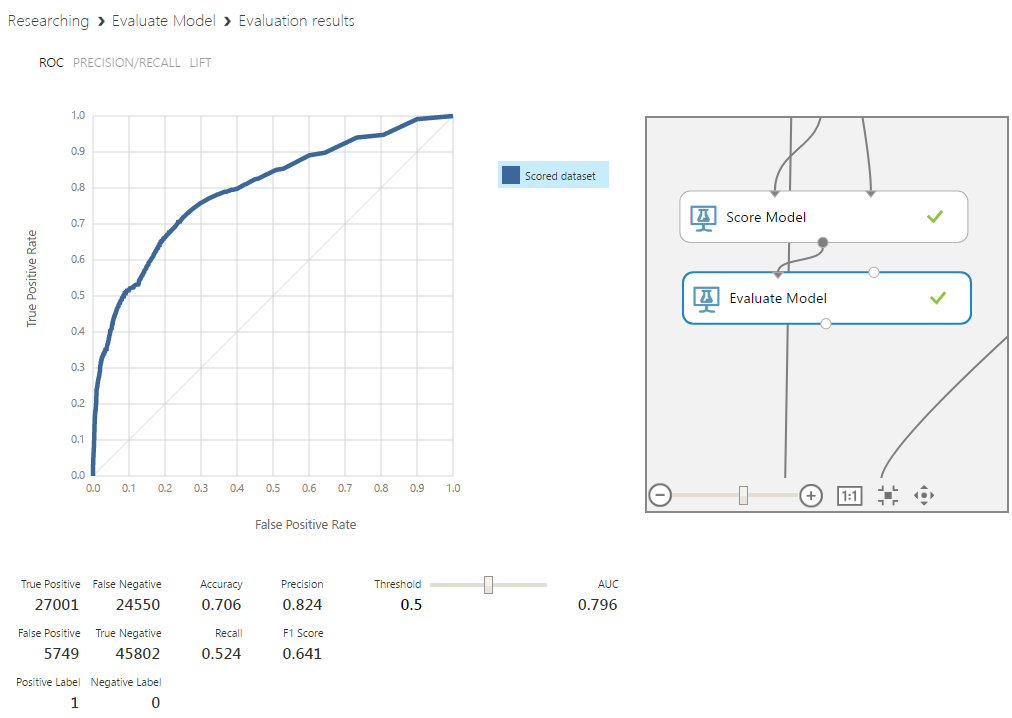
ベイジアン分類器は、ロジスティック回帰の結果と非常に類似した結果を示しました。 回帰は簡単なので、それらの間で詳しく説明します。
ランダムフォレスト
この方法は、古典的な決定木の委員会です。 このアルゴリズムでは、ツリーは枝刈りされません(枝刈りは、モデルが完全に構築された後にツリーブランチをトリミングすることにより、モデルの複雑さを軽減する方法です)。 ただし、早期停止条件は残ります。 多様性は、ソースデータのランダムなサブセットを選択することで実現されます。 サイズは同じままですが、これらのサブセットでは同じデータを再利用できます。
各ツリーは、サイズmの属性のランダムなサブセットを使用します(mはカスタムパラメーターですが、多くの場合、元の属性ベクトルのサイズのルートに近い値を使用することをお勧めします)。 分類は投票を通過します。 最も投票数の多いクラスが勝ちます。
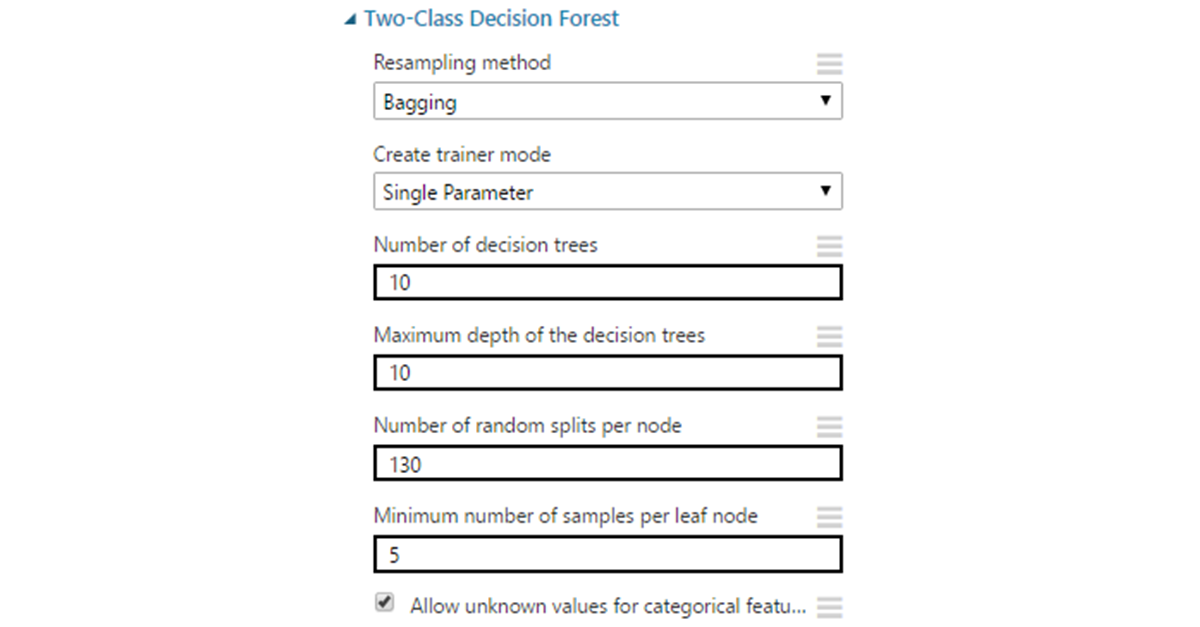
パラメータ:
- リサンプリング方法はデフォルトでバギングに設定されており、上記のように各ツリーに一意のデータ選択が与えられます。 同じデータですべてのツリーをトレーニングする必要がある場合は、レプリケートを設定することもできます。
- 決定木の数 。 ツリーの数を増やすと、サンプルのカバレッジが向上しますが、常にではありませんが、トレーニング時間が長くなります。
- 最大深度 -ツリーの最大深度。 デフォルト値の32は十分な大きさであり、多くの場合、再トレーニングにつながります。 ほとんどの場合、深さを10より大きくする必要はありません。
- ノードごとのランダム分割の数-頂点を構築するときのサインのランダム分割の数を決定します 。 多すぎると再トレーニングにつながる可能性があるため、最初に10〜30の範囲の値に制限する必要があります。
- リーフノードあたりの最小サンプル数 -「リーフ」(ブランチへの分割の対象ではなくなった頂点)を形成するためのレコードの最小数。 この場所に1を残すことはほとんど意味がありません。そのような葉は冗長であり、多くの場合、モデルを再トレーニングに導くからです。
- 不明な値を許可 -SVMに似ています。
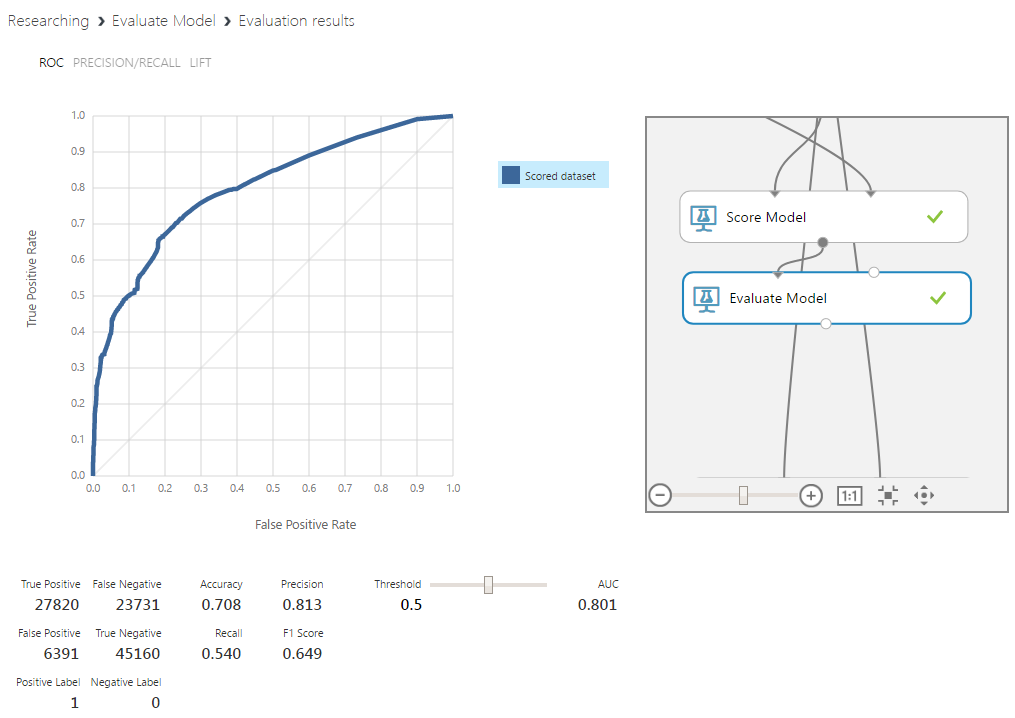
ランダムフォレストが最も効果的なアルゴリズムであることが判明し、ピークの決定が8%増加し、ピークの不在が13%増加しました。 問題のコンテキストで同様に重要なのは、クラスのデータを定義する理由のより良い解釈可能性です。 もちろん、このアルゴリズムは全体としてブラックボックスですが、必要な情報を抽出する比較的簡単な方法があります。
ベイジアンネットワークを除く上記のすべてのアルゴリズムには、「トレーナーモードの作成」パラメーターがあります。 パラメータ範囲に設定することにより、指定された範囲内のパラメータの組み合わせのさまざまなオプションについてアルゴリズムが学習し、最適なオプションを提供するモードをオンにできます。 この機能は後で強調します。
交差検定を使用して分散をテストする
相互検証評価は、さまざまな問題を解決するために使用できます。 たとえば、少量のデータの条件で再トレーニングと戦い、別の検証サンプルを強調するために使用されます。 現在、現在のモデルが一般化する能力をテストするツールとして必要になります。 これを行うには、データを10の部分に分割し、それぞれをテストと見なします。 次に、分離の各バリアントでモデルをトレーニングする必要があります。
残りの中で最高の結果を示したアルゴリズム-ランダムフォレストを使用します。

すべてのサンプルで、結果は安定しており、非常に高くなっています。 モデルには一般化能力があり、トレーニングに十分な量のデータが提供されます。
まとめ
このパートでは、機械学習に関する一連の記事から、次のことを調べました。
- クラスバランスの取れたデータサンプリングを取得する例を使用して、プロジェクトの一般的なスキームにPythonスクリプトを埋め込みます。
- MS Analysis Servicesを使用して、生データから新しい特性を抽出します。
- 結果の安定性とトレーニングセット内のデータの完全性を評価するためのモデルの相互検証。
得られた結果は、モデルの精度と安定性の明らかな改善を示しています。 最後の記事では、再訓練、統計的排出、委員会の問題に対処します。
著者について
WaveAccessチームは、さまざまな国の企業向けに、技術的に洗練され、負荷が高く、フォールトトレラントなソフトウェアを作成しています。 WaveAccessの機械学習責任者であるAlexander Azarovのコメント:
機械学習により、専門家の意見が現在支配している分野を自動化できます。 これにより、人的要因の影響を軽減し、ビジネスのスケーラビリティを高めることができます。