時間があり、顧客がもう少し欲しい場合は、最も人気のあるアルゴリズム(「レーベンシュタイン距離」)の実装をグーグルで検索して入力します。
この記事では、高度に修正されたアルゴリズムについて説明しますが、レーベンシュタイン距離に基づいて、名前によるファジー検索のC#コードの例を示します。たとえば、カフェ、レストラン、特定のサービスなどです。構成のいくつかの単語:
Yandex、Mail、ProjectArmata、戦車の世界、軍艦の世界、軍用機の世界など
アルゴリズムに慣れていない人のために、最初に「 Implementing Fuzzy Search 」、「 Fuzzy Search in Text and Dictionary 」、またはスライダーの下のプレゼンテーションの説明を読むことをお勧めします。
レーベンシュタイン距離アルゴリズム
レーベンシュタイン距離は、2つの単語の違いの程度を見つけるためのネットワークで最も一般的なアルゴリズムです。 つまり、1行目から2行目を取得するために実行する必要があるアクションの最小数は何ですか。
そのようなアクションは3つしかありません。
•取り外し
•挿入
•交換
たとえば、2つの行「CONNECT」と「CONEHEAD」の場合、次の変換テーブルを作成できます。
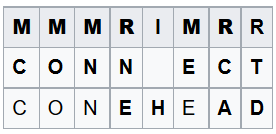
理論的には、取引価格は操作の種類(挿入、削除、交換)および/または関連するシンボルに依存する場合があります。 しかし、一般的な場合:
w(a、ε)-シンボル「a」を削除する価格は1
w(ε、b)-記号「b」を挿入する価格は1
w(a、b)-文字「a」を文字「b」で置き換える価格は1
どこでもユニットを置きます。
そして、数学の観点からは、計算は次のようになります。
S1とS2をアルファベット上の2本の線(それぞれ長さMとN)とし、編集距離(レーベンシュタイン距離)d(S1、S2)は次の繰り返し式を使用して計算できます。
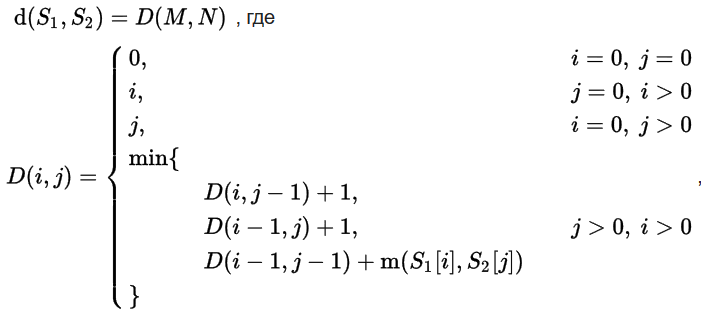
レーベンシュタインアルゴリズムの「デフォルトの実装」は、2人の数学者WangerとFisherによって行われました[チェスプレーヤーと混同しないでください]。
そして、C#では次のようになります。
ここから撮影 。
そして、視覚的に「Arestant」および「Dagestan」という単語に対するアルゴリズムの動作は次のように表されます。
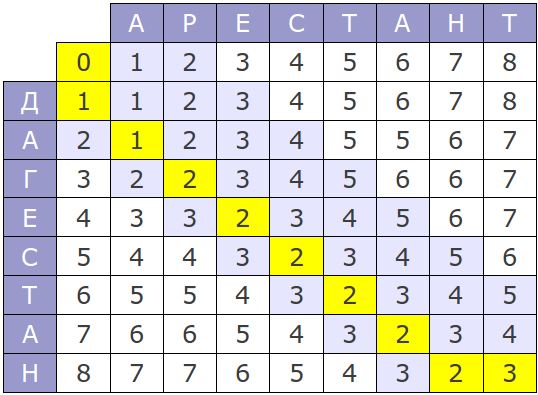
マトリックスの右下隅は、単語の違いを示しています。 マトリックスから、この特定のケースでは、単語間の違いは3つの条件付きオウムです。
明確でない場合は、これらの単語を別のビューで見てください。
_ A R E S T A N T
D A G E S T A N _
したがって、単語「Arestant」と「Dagestan」を有効にするには、1つの文字「D」を追加し、1つの文字「P」を「G」に置き換え、文字「T」を削除する必要があります。 なぜなら すべてのアクションの重みは1で、言葉の違いは3オウムです。
単語が完全に一致する場合、距離は0になります。これが理論全体であり、独創的なものはすべて単純です。
そのようなアクションは3つしかありません。
•取り外し
•挿入
•交換
たとえば、2つの行「CONNECT」と「CONEHEAD」の場合、次の変換テーブルを作成できます。
理論的には、取引価格は操作の種類(挿入、削除、交換)および/または関連するシンボルに依存する場合があります。 しかし、一般的な場合:
w(a、ε)-シンボル「a」を削除する価格は1
w(ε、b)-記号「b」を挿入する価格は1
w(a、b)-文字「a」を文字「b」で置き換える価格は1
どこでもユニットを置きます。
そして、数学の観点からは、計算は次のようになります。
S1とS2をアルファベット上の2本の線(それぞれ長さMとN)とし、編集距離(レーベンシュタイン距離)d(S1、S2)は次の繰り返し式を使用して計算できます。
レーベンシュタインアルゴリズムの「デフォルトの実装」は、2人の数学者WangerとFisherによって行われました[チェスプレーヤーと混同しないでください]。
そして、C#では次のようになります。
private Int32 levenshtein(String a, String b) { if (string.IsNullOrEmpty(a)) { if (!string.IsNullOrEmpty(b)) { return b.Length; } return 0; } if (string.IsNullOrEmpty(b)) { if (!string.IsNullOrEmpty(a)) { return a.Length; } return 0; } Int32 cost; Int32[,] d = new int[a.Length + 1, b.Length + 1]; Int32 min1; Int32 min2; Int32 min3; for (Int32 i = 0; i <= d.GetUpperBound(0); i += 1) { d[i, 0] = i; } for (Int32 i = 0; i <= d.GetUpperBound(1); i += 1) { d[0, i] = i; } for (Int32 i = 1; i <= d.GetUpperBound(0); i += 1) { for (Int32 j = 1; j <= d.GetUpperBound(1); j += 1) { cost = Convert.ToInt32(!(a[i-1] == b[j - 1])); min1 = d[i - 1, j] + 1; min2 = d[i, j - 1] + 1; min3 = d[i - 1, j - 1] + cost; d[i, j] = Math.Min(Math.Min(min1, min2), min3); } } return d[d.GetUpperBound(0), d.GetUpperBound(1)]; }
ここから撮影 。
そして、視覚的に「Arestant」および「Dagestan」という単語に対するアルゴリズムの動作は次のように表されます。
マトリックスの右下隅は、単語の違いを示しています。 マトリックスから、この特定のケースでは、単語間の違いは3つの条件付きオウムです。
明確でない場合は、これらの単語を別のビューで見てください。
_ A R E S T A N T
D A G E S T A N _
したがって、単語「Arestant」と「Dagestan」を有効にするには、1つの文字「D」を追加し、1つの文字「P」を「G」に置き換え、文字「T」を削除する必要があります。 なぜなら すべてのアクションの重みは1で、言葉の違いは3オウムです。
単語が完全に一致する場合、距離は0になります。これが理論全体であり、独創的なものはすべて単純です。
そして、それは見えるだろう-ここにある! すべてが私たちのために発明され、何もすることはありませんが、問題があります...
1)タイプミスの可能性は、キーボード上のキーの距離、音声グループ、および通常のタイピング速度に依存するため、重み係数を1にすることは常に完全に正しいとは限りません。
2)レーベンシュタインのアイデアは、単語の一部ではなく「単語の違いを見つける」ことを目的としています。これは、文字を入力するときに動的に生成される結果にとって重要です。
3)サービスの名前には、構成に複数の単語が含まれているため、人は単純に順序を覚えていない場合があります。
また、次のようないくつかの要素も考慮します。
•別の言語のキーボードレイアウト
•文字の音訳
これらは、この記事で解決しようとする問題です。
まず、すべての単語が1つのレジスタにつながることに同意しましょう。 私のバージョンのコードでは、小文字を選択しました。これは、必要な参照に反映されます(これらの参照は、説明の過程で与えられます)。 記事自体では、CamelCase-ProjectArmataなど、さまざまな書体に頼りますが、これは人間の知覚の便宜のためだけに行われます。分析の観点からすると、レジスタは1つ(下)です。 そしてまだ、私たちはベースとして古典ではなく、 ここからレーベンシュタイン距離を見つけるためのコードの最適化されたバージョンを取ります :
語順の変更を削除することにより、これをわずかに修正します。 レーベンシュタインのアルゴリズムでは、語順は重要ではありませんが、私たちにとっては他の理由で重要です。 その結果、次のものを受け取りました。
public int LevenshteinDistance(string source, string target){ if(String.IsNullOrEmpty(source)){ if(String.IsNullOrEmpty(target)) return 0; return target.Length; } if(String.IsNullOrEmpty(target)) return source.Length; var m = target.Length; var n = source.Length; var distance = new int[2, m + 1]; // Initialize the distance 'matrix' for(var j = 1; j <= m; j++) distance[0, j] = j; var currentRow = 0; for(var i = 1; i <= n; ++i){ currentRow = i & 1; distance[currentRow, 0] = i; var previousRow = currentRow ^ 1; for(var j = 1; j <= m; j++){ var cost = (target[j - 1] == source[i - 1] ? 0 : 1); distance[currentRow, j] = Math.Min(Math.Min( distance[previousRow, j] + 1, distance[currentRow, j - 1] + 1), distance[previousRow, j - 1] + cost); } } return distance[currentRow, m]; }
重み係数を変更することにより、検索アルゴリズムを改善し始めます。 まず、挿入および削除の要素は2です。
つまり 行が変更されます:
for(var j = 1; j <= m; j++) distance[0, j] = j * 2; ... distance[currentRow, 0] = i * 2; ... distance[previousRow, j] + 2 ... distance[currentRow, j - 1] + 2
そして、文字の置換係数を計算する行があります。関数CostDistanceSymbolを有効にします:
var cost = (target[j - 1] == source[i - 1] ? 0 : 1);
そして、2つの要因を検討します。
1)キーボードの距離
2)音声グループ
この点で、ソースオブジェクトとターゲットオブジェクトのより便利な作業のために、それらをオブジェクトに変換します。
class Word { // public string Text { get; set; } // public List<int> Codes { get; set; } = new List<int>(); }
これには、次の補助ガイドが必要です。
ロシア語キーボードのキーコードの比率:
private static SortedDictionary<char, int> CodeKeysRus = new SortedDictionary<char, int> { { '' , 192 }, { '1' , 49 }, { '2' , 50 }, ... { '-' , 189 }, { '=' , 187 }, { '' , 81 }, { '' , 87 }, { '' , 69 }, ... { '_' , 189 }, { '+' , 187 }, { ',' , 191 }, }
英語キーボードのキーコード比
private static SortedDictionary<char, int> CodeKeysEng = new SortedDictionary<char, int> { { '`', 192 }, { '1', 49 }, { '2', 50 }, ... { '-', 189 }, { '=', 187 }, { 'q', 81 }, { 'w', 87 }, { 'e', 69 }, { 'r', 82 }, ... { '<', 188 }, { '>', 190 }, { '?', 191 }, };
数学言語で話すこれらの2つのディレクトリのおかげで、2つの異なるシンボルスペースを1つのユニバーサルに変換できます。
また、次の関係が有効です。
private static SortedDictionary <int、List> DistanceCodeKey = new SortedDictionary <int、
List<int>> { /* '`' */ { 192, new List<int>(){ 49 }}, /* '1' */ { 49 , new List<int>(){ 50, 87, 81 }}, /* '2' */ { 50 , new List<int>(){ 49, 81, 87, 69, 51 }}, ... /* '-' */ { 189, new List<int>(){ 48, 80, 219, 221, 187 }}, /* '+' */ { 187, new List<int>(){ 189, 219, 221 }}, /* 'q' */ { 81 , new List<int>(){ 49, 50, 87, 83, 65 }}, /* 'w' */ { 87 , new List<int>(){ 49, 81, 65, 83, 68, 69, 51, 50 }}, ... /* '>' */ { 188, new List<int>(){ 77, 74, 75, 76, 190 }}, /* '<' */ { 190, new List<int>(){ 188, 75, 76, 186, 191 }}, /* '?' */ { 191, new List<int>(){ 190, 76, 186, 222 }}, };
つまり 別のキーの周りに立っているキーを取ります。 図の例によってこれを確認できます:
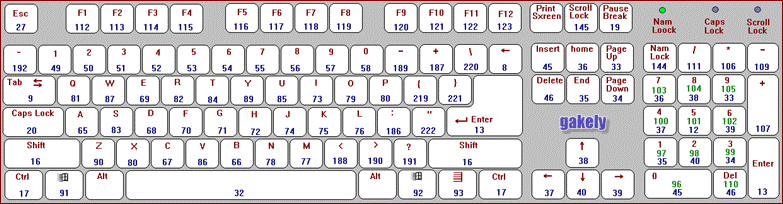
はい、QWERTYキーボードに加えて、他のレイアウトがあり、キーボード距離テーブルが一致しないことを知っていますが、最も一般的なオプションを使用します。
誰かがより良い方法を知っているなら、書いてください。
これで、最初のステップ-CostDistanceSymbol関数でエラーのあるシンボルの重みを計算する準備ができました。
前と同様に、文字が同じ場合、距離は0です。
if (source.Text[sourcePosition] == target.Text[targetPosition]) return 0;
キーコードが同じ場合、距離も0です。
if (source.Codes[sourcePosition] != 0 && target.Codes[targetPosition] == target.Codes[targetPosition]) return 0;
文字を比較した後にキーコードを比較する理由がわからない場合、答えは簡単です。「Water」と「Djlf」という言葉を同じように理解してもらいたいのです。 また、レイアウトに関係なく、異なるレイアウトで入力できる文字、たとえば「;」や「、」も同じように認識されていました。
さらに、キーコードが互いにどれだけ近いかについては、すでにコードだけを見ていきます。 近い場合、距離は1、そうでない場合、2(挿入または削除時とまったく同じ重量):
int resultWeight = 0; List<int> nearKeys; if (!DistanceCodeKey.TryGetValue(source.Codes[sourcePosition], out nearKeys)) resultWeight = 2; else resultWeight = nearKeys.Contains(target.Codes[searchPosition]) ? 1 : 2;
実際、このような小さな改良は、間違ったレイアウトから始まり、キーによるミスで終わる膨大な数のランダムエラーをカバーします。
しかし、タイプミスの後では、人は単語のつづり方を知らないかもしれません。 例:パイク、下品。 テスト。
そのような言葉はロシア語だけでなく、英語でもあります。 そのような場合も考慮する必要があります。 英語の単語については、音声グループに関するZobelとDarthの研究を基本とします 。
「Aeiouy」、「bp」、「ckq」、「dt」、「lr」、「mn」、「gj」、「fpv」、「sxz」、「csz」
そして、ロシア人のために、私は自分自身で作曲します:
「Yy」、「eee」、「ay」、「oye」、「uy」、「shch」、「oa」、「yo」
これらの音声グループをタイプのオブジェクトに変換します。
PhoneticGroupsEng = { { 'a', { 'e', 'i', 'o', 'u', 'y'} }, { 'e', { 'a', 'i', 'o', 'u', 'y'} } ... }
これは手作業でもコードの記述方法でも行えますが、結果は同じです。 そして今、キーコードをチェックした後、前のステップと同じエラーを見つけるためのロジックで音声グループに入るための文字をチェックすることができます:
List<char> phoneticGroups; if (PhoneticGroupsRus.TryGetValue(target.Text[targetPosition], out phoneticGroups)) resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2); if (PhoneticGroupsEng.TryGetValue(target.Text[targetPosition], out phoneticGroups)) resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2);
上記のタイプミスに加えて、テキストの「タイピング速度」のタイプミスがあります。 これは、2つの連続した文字が入力されたときに混同される場合です。 さらに、これはある種の数学者フレデリック・ダメラウが文字の転置(順列)の操作を追加することでレーベンシュタインアルゴリズムを完成させたというよくある間違いです。
ソフトウェアの観点から、LevenshteinDistance関数に次を追加します。

if (i > 1 && j > 1 && source.Text[i - 1] == target.Text[j - 2] && source.Text[i - 2] == target.Text[j - 1]) { distance[currentRow, j] = Math.Min(distance[currentRow, j], distance[(i - 2) % 3, j - 2] + 2); }
発言
基礎として採用した最適化コードには、距離行列を初期化する次の形式があります。var distance = new int [2、m + 1];
したがって、「distance [(i-2)%3、...」というコードのこのセクションは現在の形式では機能しません。記事の最後に正しいバージョンの関数を示します。
したがって、「distance [(i-2)%3、...」というコードのこのセクションは現在の形式では機能しません。記事の最後に正しいバージョンの関数を示します。
したがって、コードを完成させる最初のステップを完了しました。 2番目のポイントに進みます。 レーベンシュタインのアイデアは、単語の一部ではなく、「単語を区別する」ことを目的としていることを思い出してください。これは、文字を入力する際の動的な出力にとって重要です。
たとえば、ディレクトリには2つの単語があります。
•「ProjectArmata」
•「ヤク」
クエリ「Pro」を検索バーに入力すると、2つの文字を置き換えて1つを削除するだけで3つのオウムになるため、「ヤク」が優先度の高いものになります(ユニット係数と従来のレーベンシュタインアルゴリズムを考慮せずに変更します)。 「jectArmata」という単語の一部を10個のオウムに追加します。
この状況で最も論理的なのは、単語全体ではなく、検索された単語の一部のみを入力された文字列と比較することです。
なぜなら 検索クエリは「Pro」という3文字で構成されています。比較対象の「ProjectArmata」という単語から最初の3文字を取得します。 「プロ」と100%の一致を取得します。 この特定の場合-完璧。 しかし、さらにいくつかのオプションを見てみましょう。 データベースに次の単語セットがあるとします。
•「共同」
•「コンベヤー」
•「コロニー」
•「化粧品」
検索クエリは「Com」のようになります。 その結果、単語の一致率は次のようになります。
共同-0
コンベア-1
コロニー-1
化粧品-1
「Kommunalka」という単語ですべてが順調であれば、他の3つの単語は何らかの形で統一されているように見えます。 そして私たちの仕事は、すべてを一列に並べるのではなく、彼に最適な結果を与えることです。 さらに、ダメラウが言ったように、ほとんどの間違いは文字の順列です。
このような間違いをなくすために、小さな修正を行います。
最初の「n」文字ではなく、「n + 1」文字を取ります。nはクエリ内の文字数です。 そして、「Com」のリクエストでの係数は次のようになります。
共同-1
化粧品-1
コンベヤー-2
コロニー-2
「化粧品」は修正されましたが、「コムムナルカ」は残りました...しかし、私は次の理由でこのオプションがより好きです。 通常、検索が必要な場合、最初に文字を入力すると、検索バーの下にドロップダウンリストの形式でユーザーに情報が表示されます。 このドロップダウンリストの長さは、3〜7エントリのサイズによって制限されます。 その結果、3つのエントリしかない場合、2番目のバージョンでは「Kommunalka」、「Cosmetics」、「Conveyor」が表示されます[as それは、guidのために、または単に作成日のために、最初の発行では愚かです。 そして、最初のケースでは、「Kommunalka」、「Conveyor」、「Colony」があり、「Cosmetics」はありません。 彼女は他の理由で不運でした...
もちろん、この問題には他の解決策もあります。 たとえば、最初に「n」文字でソートしてから、インデックスが一致する単語のグループを取得し、さらに「n + 1」文字を再ソートすると、何度も何度も再ソートできます...解決される問題、計算能力。
今、上記の問題の解決に焦点を当てないでください...私たちは道の真っin中にいるだけで、まだ伝えたいことがあります。
正しい検索結果の次のニュアンスは、ソ連の時代からもたらされます。 その後、いくつかの単語を1つにまとめた名前を作るのが好きでした。 はい、今ではそれが関連しています:
消費者組合
GazPromBank
ロシア農業銀行
Projectarmata
銀行URALSIB
等
[ps 名前の一部がスペースで書かれていることは知っていますが、鮮明な例を取り上げる必要がありました]
しかし、アルゴリズムに従えば、常に単語の最初の「n + 1」文字を取得します。 また、「Bank」という単語を入力すると、適切な引き渡しは行われません。 なぜなら 行を比較します。
BankU
ポトレ
ガスプル
ロッセ
「プロジェクト」
位置に関係なく「bank」という単語を見つけるには、フレーズごとにフローティングウィンドウを作成し、最低の係数を返す必要があります。
double GetRangeWord(Word source, Word target) { double rangeWord = double.MaxValue; Word croppedSource = new Word(); int length = Math.Min(source.Text.Length, target.Text.Length + 1); for (int i = 0; i <= source.Text.Length - length; i++) { croppedSource.Text = target.Text.Substring(i, length); croppedSource.Codes = target.Codes.Skip(i).Take(length).ToList(); rangeWord = Math.Min(LevenshteinDistance(croppedSource, target) + (i * 2 / 10.0), rangeWord); } return rangeWord; }
ご覧のとおり、レーベンシュタイン距離を計算した後に得られた誤差に、別の値(i * 2 / 10.0)を追加します。 「i * 2」の場合-すべてが明確な場合、これは、レーベンシュタイン距離を見つけるための古典的なアルゴリズムのように、単語の先頭に文字を挿入するエラーですが、なぜ10で割るのですか? 要するに、「i * 2」だけを残すと、短い単語の長さが短くなり、再び銀行の名前を残すことになります。 したがって、係数を10で除算する必要があり、これによりこのバイアスが減少します。 なぜちょうど10 私たちのベースについては、通常は多少適合しますが、より多くに分割できることを除外しません。 すべては、単語の長さと単語の類似性に依存します。 最適な係数の計算については少し後で説明します。
検索ユニットのように、並べ替えられた単語で、フレーズに移動します。 そして、まず最初に、いくつかの例を示します。
•ウォーフェイス
•戦車の世界
•軍用機の世界
•船の世界
フレーズの検索から基本的に必要なものを理解しましょう。 欠けている単語を追加したり、不要なフレーズを削除したり、場所を変えたりする必要があります。 すでにどこかでこれを言っていました...そして、確かに、私は思い出しました...記事の冒頭で、レーベンシュタインの言葉と距離関数について話しました。 あなたの時間を無駄にしないために、私はすぐにそれを純粋な形で使用することはできなかったと言いますが、それに触発されて、フレーズに適用できるコードを書くことができました。
レーベンシュタイン距離関数の実装と同様に、フレーズの1つが空の場合、すべての文字の挿入または削除[空のフレーズがどちら側から来たかによる]に等しいエラー値を返します。
if (!source.Words.Any()) { if (!search.Words.Any()) return 0; return search.Words.Sum(w => w.Text.Length) * 2 * 100; } if (!search.Words.Any()) { return source.Words.Sum(w => w.Text.Length) * 2 * 100; }
つまり フレーズ内の文字数を要約し、2を掛けます(この係数は文字の記事の冒頭で選択しました)。100を掛けます。これらの100は、アルゴリズム全体で最も矛盾する係数です。 なぜ必要なのかを以下でより明確に示し、その後、理論的には天井からだけでなく、計算する必要があることを説明します。
double result = 0; for (int i = 0; i < search.Words.Count; i++) { double minRangeWord = double.MaxValue; int minIndex = 0; for (int j = 0; j < source.Words.Count; j++) { double currentRangeWord = GetRangeWord(source.Words[j], search.Words[i], translation); if (currentRangeWord < minRangeWord) { minRangeWord = currentRangeWord; minIndex = j; } } result += minRangeWord * 100 + (Math.Abs(i - minIndex) / 10.0); } return result; }
このコードでは、データベース内のレコードの各単語を各検索クエリと比較し、各単語の最低係数を取得します。 フレーズの合計係数は次のとおりです。
result + = minRangeWord * 100 +(Math.Abs(i-minIndex)/ 10.0);
ご覧のように、ロジック全体は上記と同じです。単語minRangeWordの最小係数に100を掛けて、単語が最適な位置にどれだけ近いかを示す係数を追加します(Math.Abs(i-minIndex)/ 10.0)。
前のステップで検索語の最適な位置を検索するときに発生する可能性のある追加の係数を補正するために、100の乗算が使用されます。 その結果、この係数は、検索行のフレーズとデータベース内のすべての単語の間の最大値として計算できます。 フレーズではなく、言葉で。 ただし、このためには、変更を加えてレーベンシュタイン距離を「空にする」必要がありますが、これは非常にリソースを浪費します。
つまり GetRangeWord関数を実行し、フレーズ「i * 2」の最適な場所からの偏差の最大値を取得します。 そして、最高値を取得した後、最も近い10倍の数値(10、100、1000、10000、100000など)に移動します。 したがって、2つの値を取得します。
最初の値は、GetRangeWord関数で混合語を分割する値です。 次に、前のオフセットを補正するためにminRangeWordを乗算する値。 したがって、フレーズの類似性の正確な指標を取得します。 しかし、実際には、大きな偏差を無視し、平均を大まかに見積もることができます...私は実際にこれを行いました。
原則として、すべて。 私が整理した主な問題は、「文字の音訳」のほんの少しの改良です。 上記の検索と音訳の検索の違いは、CostDistanceSymbol関数ではキー距離に応じて応答値を調整しないことです。 この場合の発行は正しくありません。
また、検索文字列の3文字で結果が適切に返されることにも注意してください。文字数が少ない場合は、文字列を正確に一致させるより不器用な方法を使用することをお勧めします。
次に、上記のすべての最も完全なコードを提供しますが、最初に:
1)このコードは、私が自由な時間に個人的に書いたものです。
2)アルゴリズムは、私が自由時間に個人的に考えたものです。
それとは別に、リンクとインスピレーションに感謝します。DmitryPanyushkin、Pavel Grigorenko。
記事に記載されている名前は、オープンソースから取得されたものであり、所有者のものです。 広告ではありません。
読んでくれたみんなに感謝します。 批判やアドバイスを歓迎します。
完全なコード
public class DistanceAlferov { class Word { public string Text { get; set; } public List<int> Codes { get; set; } = new List<int>(); } class AnalizeObject { public string Origianl { get; set; } public List<Word> Words { get; set; } = new List<Word>(); } class LanguageSet { public AnalizeObject Rus { get; set; } = new AnalizeObject(); public AnalizeObject Eng { get; set; } = new AnalizeObject(); } List<LanguageSet> Samples { get; set; } = new List<LanguageSet>(); public void SetData(List<Tuple<string, string>> datas) { List<KeyValuePair<char, int>> codeKeys = CodeKeysRus.Concat(CodeKeysEng).ToList(); foreach (var data in datas) { LanguageSet languageSet = new LanguageSet(); languageSet.Rus.Origianl = data.Item1; if (data.Item1.Length > 0) { languageSet.Rus.Words = data.Item1.Split(' ').Select(w => new Word() { Text = w.ToLower(), Codes = GetKeyCodes(codeKeys, w) }).ToList(); } languageSet.Eng.Origianl = data.Item2; if (data.Item2.Length > 0) { languageSet.Eng.Words = data.Item2.Split(' ').Select(w => new Word() { Text = w.ToLower(), Codes = GetKeyCodes(codeKeys, w) }).ToList(); } this.Samples.Add(languageSet); } } public List<Tuple<string, string, double, int>> Search(string targetStr) { List<KeyValuePair<char, int>> codeKeys = CodeKeysRus.Concat(CodeKeysEng).ToList(); AnalizeObject originalSearchObj = new AnalizeObject(); if (targetStr.Length > 0) { originalSearchObj.Words = targetStr.Split(' ').Select(w => new Word() { Text = w.ToLower(), Codes = GetKeyCodes(codeKeys, w) }).ToList(); } AnalizeObject translationSearchObj = new AnalizeObject(); if (targetStr.Length > 0) { translationSearchObj.Words = targetStr.Split(' ').Select(w => { string translateStr = Transliterate(w.ToLower(), Translit_Ru_En); return new Word() { Text = translateStr, Codes = GetKeyCodes(codeKeys, translateStr) }; }).ToList(); } var result = new List<Tuple<string, string, double, int>>(); foreach (LanguageSet sampl in Samples) { int languageType = 1; double cost = GetRangePhrase(sampl.Rus, originalSearchObj, false); double tempCost = GetRangePhrase(sampl.Eng, originalSearchObj, false); if (cost > tempCost) { cost = tempCost; languageType = 3; } // tempCost = GetRangePhrase(sampl.Rus, translationSearchObj, true); if (cost > tempCost) { cost = tempCost; languageType = 2; } tempCost = GetRangePhrase(sampl.Eng, translationSearchObj, true); if (cost > tempCost) { cost = tempCost; languageType = 3; } result.Add(new Tuple<string, string, double, int>(sampl.Rus.Origianl, sampl.Eng.Origianl, cost, languageType)); } return result; } private double GetRangePhrase(AnalizeObject source, AnalizeObject search, bool translation) { if (!source.Words.Any()) { if (!search.Words.Any()) return 0; return search.Words.Sum(w => w.Text.Length) * 2 * 100; } if (!search.Words.Any()) { return source.Words.Sum(w => w.Text.Length) * 2 * 100; } double result = 0; for (int i = 0; i < search.Words.Count; i++) { double minRangeWord = double.MaxValue; int minIndex = 0; for (int j = 0; j < source.Words.Count; j++) { double currentRangeWord = GetRangeWord(source.Words[j], search.Words[i], translation); if (currentRangeWord < minRangeWord) { minRangeWord = currentRangeWord; minIndex = j; } } result += minRangeWord * 100 + (Math.Abs(i - minIndex) / 10.0); } return result; } private double GetRangeWord(Word source, Word target, bool translation) { double minDistance = double.MaxValue; Word croppedSource = new Word(); int length = Math.Min(source.Text.Length, target.Text.Length + 1); for (int i = 0; i <= source.Text.Length - length; i++) { croppedSource.Text = source.Text.Substring(i, length); croppedSource.Codes = source.Codes.Skip(i).Take(length).ToList(); minDistance = Math.Min(minDistance, LevenshteinDistance(croppedSource, target, croppedSource.Text.Length == source.Text.Length, translation) + (i * 2 / 10.0)); } return minDistance; } private int LevenshteinDistance(Word source, Word target, bool fullWord, bool translation) { if (String.IsNullOrEmpty(source.Text)) { if (String.IsNullOrEmpty(target.Text)) return 0; return target.Text.Length * 2; } if (String.IsNullOrEmpty(target.Text)) return source.Text.Length * 2; int n = source.Text.Length; int m = target.Text.Length; //TODO ( ) int[,] distance = new int[3, m + 1]; // Initialize the distance 'matrix' for (var j = 1; j <= m; j++) distance[0, j] = j * 2; var currentRow = 0; for (var i = 1; i <= n; ++i) { currentRow = i % 3; var previousRow = (i - 1) % 3; distance[currentRow, 0] = i * 2; for (var j = 1; j <= m; j++) { distance[currentRow, j] = Math.Min(Math.Min( distance[previousRow, j] + ((!fullWord && i == n) ? 2 - 1 : 2), distance[currentRow, j - 1] + ((!fullWord && i == n) ? 2 - 1 : 2)), distance[previousRow, j - 1] + CostDistanceSymbol(source, i - 1, target, j - 1, translation)); if (i > 1 && j > 1 && source.Text[i - 1] == target.Text[j - 2] && source.Text[i - 2] == target.Text[j - 1]) { distance[currentRow, j] = Math.Min(distance[currentRow, j], distance[(i - 2) % 3, j - 2] + 2); } } } return distance[currentRow, m]; } private int CostDistanceSymbol(Word source, int sourcePosition, Word search, int searchPosition, bool translation) { if (source.Text[sourcePosition] == search.Text[searchPosition]) return 0; if (translation) return 2; if (source.Codes[sourcePosition] != 0 && source.Codes[sourcePosition] == search.Codes[searchPosition]) return 0; int resultWeight = 0; List<int> nearKeys; if (!DistanceCodeKey.TryGetValue(source.Codes[sourcePosition], out nearKeys)) resultWeight = 2; else resultWeight = nearKeys.Contains(search.Codes[searchPosition]) ? 1 : 2; List<char> phoneticGroups; if (PhoneticGroupsRus.TryGetValue(search.Text[searchPosition], out phoneticGroups)) resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2); if (PhoneticGroupsEng.TryGetValue(search.Text[searchPosition], out phoneticGroups)) resultWeight = Math.Min(resultWeight, phoneticGroups.Contains(source.Text[sourcePosition]) ? 1 : 2); return resultWeight; } private List<int> GetKeyCodes(List<KeyValuePair<char, int>> codeKeys, string word) { return word.ToLower().Select(ch => codeKeys.FirstOrDefault(ck => ck.Key == ch).Value).ToList(); } private string Transliterate(string text, Dictionary<char, string> cultureFrom) { IEnumerable<char> translateText = text.SelectMany(t => { string translateChar; if (cultureFrom.TryGetValue(t, out translateChar)) return translateChar; return t.ToString(); }); return string.Concat(translateText); } #region static Dictionary<char, List<char>> PhoneticGroupsRus = new Dictionary<char, List<char>>(); static Dictionary<char, List<char>> PhoneticGroupsEng = new Dictionary<char, List<char>>(); #endregion static DistanceAlferov() { SetPhoneticGroups(PhoneticGroupsRus, new List<string>() { "", "", "", "", "", "", "" }); SetPhoneticGroups(PhoneticGroupsEng, new List<string>() { "aeiouy", "bp", "ckq", "dt", "lr", "mn", "gj", "fpv", "sxz", "csz" }); } private static void SetPhoneticGroups(Dictionary<char, List<char>> resultPhoneticGroups, List<string> phoneticGroups) { foreach (string group in phoneticGroups) foreach (char symbol in group) if (!resultPhoneticGroups.ContainsKey(symbol)) resultPhoneticGroups.Add(symbol, phoneticGroups.Where(pg => pg.Contains(symbol)).SelectMany(pg => pg).Distinct().Where(ch => ch != symbol).ToList()); } #region /// <summary> /// /// </summary> private static Dictionary<int, List<int>> DistanceCodeKey = new Dictionary<int, List<int>> { /* '`' */ { 192 , new List<int>(){ 49 }}, /* '1' */ { 49 , new List<int>(){ 50, 87, 81 }}, /* '2' */ { 50 , new List<int>(){ 49, 81, 87, 69, 51 }}, /* '3' */ { 51 , new List<int>(){ 50, 87, 69, 82, 52 }}, /* '4' */ { 52 , new List<int>(){ 51, 69, 82, 84, 53 }}, /* '5' */ { 53 , new List<int>(){ 52, 82, 84, 89, 54 }}, /* '6' */ { 54 , new List<int>(){ 53, 84, 89, 85, 55 }}, /* '7' */ { 55 , new List<int>(){ 54, 89, 85, 73, 56 }}, /* '8' */ { 56 , new List<int>(){ 55, 85, 73, 79, 57 }}, /* '9' */ { 57 , new List<int>(){ 56, 73, 79, 80, 48 }}, /* '0' */ { 48 , new List<int>(){ 57, 79, 80, 219, 189 }}, /* '-' */ { 189 , new List<int>(){ 48, 80, 219, 221, 187 }}, /* '+' */ { 187 , new List<int>(){ 189, 219, 221 }}, /* 'q' */ { 81 , new List<int>(){ 49, 50, 87, 83, 65 }}, /* 'w' */ { 87 , new List<int>(){ 49, 81, 65, 83, 68, 69, 51, 50 }}, /* 'e' */ { 69 , new List<int>(){ 50, 87, 83, 68, 70, 82, 52, 51 }}, /* 'r' */ { 82 , new List<int>(){ 51, 69, 68, 70, 71, 84, 53, 52 }}, /* 't' */ { 84 , new List<int>(){ 52, 82, 70, 71, 72, 89, 54, 53 }}, /* 'y' */ { 89 , new List<int>(){ 53, 84, 71, 72, 74, 85, 55, 54 }}, /* 'u' */ { 85 , new List<int>(){ 54, 89, 72, 74, 75, 73, 56, 55 }}, /* 'i' */ { 73 , new List<int>(){ 55, 85, 74, 75, 76, 79, 57, 56 }}, /* 'o' */ { 79 , new List<int>(){ 56, 73, 75, 76, 186, 80, 48, 57 }}, /* 'p' */ { 80 , new List<int>(){ 57, 79, 76, 186, 222, 219, 189, 48 }}, /* '[' */ { 219 , new List<int>(){ 48, 186, 222, 221, 187, 189 }}, /* ']' */ { 221 , new List<int>(){ 189, 219, 187 }}, /* 'a' */ { 65 , new List<int>(){ 81, 87, 83, 88, 90 }}, /* 's' */ { 83 , new List<int>(){ 81, 65, 90, 88, 67, 68, 69, 87, 81 }}, /* 'd' */ { 68 , new List<int>(){ 87, 83, 88, 67, 86, 70, 82, 69 }}, /* 'f' */ { 70 , new List<int>(){ 69, 68, 67, 86, 66, 71, 84, 82 }}, /* 'g' */ { 71 , new List<int>(){ 82, 70, 86, 66, 78, 72, 89, 84 }}, /* 'h' */ { 72 , new List<int>(){ 84, 71, 66, 78, 77, 74, 85, 89 }}, /* 'j' */ { 74 , new List<int>(){ 89, 72, 78, 77, 188, 75, 73, 85 }}, /* 'k' */ { 75 , new List<int>(){ 85, 74, 77, 188, 190, 76, 79, 73 }}, /* 'l' */ { 76 , new List<int>(){ 73, 75, 188, 190, 191, 186, 80, 79 }}, /* ';' */ { 186 , new List<int>(){ 79, 76, 190, 191, 222, 219, 80 }}, /* '\''*/ { 222 , new List<int>(){ 80, 186, 191, 221, 219 }}, /* 'z' */ { 90 , new List<int>(){ 65, 83, 88 }}, /* 'x' */ { 88 , new List<int>(){ 90, 65, 83, 68, 67 }}, /* 'c' */ { 67 , new List<int>(){ 88, 83, 68, 70, 86 }}, /* 'v' */ { 86 , new List<int>(){ 67, 68, 70, 71, 66 }}, /* 'b' */ { 66 , new List<int>(){ 86, 70, 71, 72, 78 }}, /* 'n' */ { 78 , new List<int>(){ 66, 71, 72, 74, 77 }}, /* 'm' */ { 77 , new List<int>(){ 78, 72, 74, 75, 188 }}, /* '<' */ { 188 , new List<int>(){ 77, 74, 75, 76, 190 }}, /* '>' */ { 190 , new List<int>(){ 188, 75, 76, 186, 191 }}, /* '?' */ { 191 , new List<int>(){ 190, 76, 186, 222 }}, }; /// <summary> /// /// </summary> private static Dictionary<char, int> CodeKeysRus = new Dictionary<char, int> { { '' , 192 }, { '1' , 49 }, { '2' , 50 }, { '3' , 51 }, { '4' , 52 }, { '5' , 53 }, { '6' , 54 }, { '7' , 55 }, { '8' , 56 }, { '9' , 57 }, { '0' , 48 }, { '-' , 189 }, { '=' , 187 }, { '' , 81 }, { '' , 87 }, { '' , 69 }, { '' , 82 }, { '' , 84 }, { '' , 89 }, { '' , 85 }, { '' , 73 }, { '' , 79 }, { '' , 80 }, { '' , 219 }, { '' , 221 }, { '' , 65 }, { '' , 83 }, { '' , 68 }, { '' , 70 }, { '' , 71 }, { '' , 72 }, { '' , 74 }, { '' , 75 }, { '' , 76 }, { '' , 186 }, { '' , 222 }, { '' , 90 }, { '' , 88 }, { '' , 67 }, { '' , 86 }, { '' , 66 }, { '' , 78 }, { '' , 77 }, { '' , 188 }, { '' , 190 }, { '.' , 191 }, { '!' , 49 }, { '"' , 50 }, { '№' , 51 }, { ';' , 52 }, { '%' , 53 }, { ':' , 54 }, { '?' , 55 }, { '*' , 56 }, { '(' , 57 }, { ')' , 48 }, { '_' , 189 }, { '+' , 187 }, { ',' , 191 }, }; /// <summary> /// /// </summary> private static Dictionary<char, int> CodeKeysEng = new Dictionary<char, int> { { '`', 192 }, { '1', 49 }, { '2', 50 }, { '3', 51 }, { '4', 52 }, { '5', 53 }, { '6', 54 }, { '7', 55 }, { '8', 56 }, { '9', 57 }, { '0', 48 }, { '-', 189 }, { '=', 187 }, { 'q', 81 }, { 'w', 87 }, { 'e', 69 }, { 'r', 82 }, { 't', 84 }, { 'y', 89 }, { 'u', 85 }, { 'i', 73 }, { 'o', 79 }, { 'p', 80 }, { '[', 219 }, { ']', 221 }, { 'a', 65 }, { 's', 83 }, { 'd', 68 }, { 'f', 70 }, { 'g', 71 }, { 'h', 72 }, { 'j', 74 }, { 'k', 75 }, { 'l', 76 }, { ';', 186 }, { '\'', 222 }, { 'z', 90 }, { 'x', 88 }, { 'c', 67 }, { 'v', 86 }, { 'b', 66 }, { 'n', 78 }, { 'm', 77 }, { ',', 188 }, { '.', 190 }, { '/', 191 }, { '~' , 192 }, { '!' , 49 }, { '@' , 50 }, { '#' , 51 }, { '$' , 52 }, { '%' , 53 }, { '^' , 54 }, { '&' , 55 }, { '*' , 56 }, { '(' , 57 }, { ')' , 48 }, { '_' , 189 }, { '+' , 187 }, { '{', 219 }, { '}', 221 }, { ':', 186 }, { '"', 222 }, { '<', 188 }, { '>', 190 }, { '?', 191 }, }; #endregion #region /// <summary> /// => ASCII (ISO 9-95) /// </summary> private static Dictionary<char, string> Translit_Ru_En = new Dictionary<char, string> { { '', "a" }, { '', "b" }, { '', "v" }, { '', "g" }, { '', "d" }, { '', "e" }, { '', "yo" }, { '', "zh" }, { '', "z" }, { '', "i" }, { '', "i" }, { '', "k" }, { '', "l" }, { '', "m" }, { '', "n" }, { '', "o" }, { '', "p" }, { '', "r" }, { '', "s" }, { '', "t" }, { '', "u" }, { '', "f" }, { '', "x" }, { '', "c" }, { '', "ch" }, { '', "sh" }, { '', "shh" }, { '', "" }, { '', "y" }, { '', "'" }, { '', "e" }, { '', "yu" }, { '', "ya" }, }; #endregion }
Vitaly Alferov、2017