
この記事では、HekaとElasticSearchに基づいたログ収集システムとフィールドの経験を共有し続けます。
今回の話は、ElasticSearch 2.2と5.2.2の2つのクラスター間のデータ移行に関するもので 、これにはかなりの負担がかかりました。 結局、すでに稼働しているシステムを壊さずに240億件のレコードを輸送する必要がありました。
前の記事は、システムが機能し、ログが到着してElasticSearchクラスターに追加され、Kibanaを介してリアルタイムで表示できるという事実で終わりました。 しかし、クラスターは元々、成長のためだけにかなりのメモリの余裕を持って組み立てられていました。
ElasticSearch(以降、単にES)の公式ドキュメントに目を向けると、まず、「32 GBを超えないでください」という厳しい警告が表示されます。 超過するとパフォーマンスが完全に停止するまで低下し、ガベージコレクターは「世界を停止する」という精神で再構築を実行します。 サーバーメモリに関する製造元の推奨事項:ヒープ用に32 GB(xms / xmx)および32 GBの空きキャッシュスペース。 1つのデータノードに合計64 GBの物理メモリ。
しかし、より多くのメモリがある場合はどうでしょうか? 公式の答えはすべて同じドキュメントにあります-ESの複数のインスタンスを同じホストに配置します。 しかし、このアプローチは私にはあまり適切ではないと思われました。なぜなら、これに対する通常の手段が提供されていなかったからです。 initスクリプトの複製は20世紀であるため、LXDコンテナにノードを配置するクラスター仮想化はより興味深いものに見えました。
LXD(Linux Container Daemon)-いわゆる「コンテナ軽量ビューア」。 「重い」ハイパーバイザーとは異なり、仮想化のオーバーヘッドを削減するのに役立つハードウェアエミュレーションは含まれていません。 さらに、高度なREST API、使用されるリソースの柔軟な構成、ホスト間でコンテナーを転送する機能、および従来の仮想化システムにより特徴的なその他の機能を備えています。

これは、将来のクラスターの構造です。
作業の開始時に、次のアイロンが手元にありました。
古いクラスター内の4つの作業ESデータノード:Intel Xeon 2x E5-2640 v3。 512 GB RAM、3x16 TB RAID-10。
- 前の構成アイテムと同様の2つの新しい空のサーバー。
計画どおり、 各物理サーバーには、マスターノードとクライアントノードの2つのESデータノードがあります。 さらに、サーバーは、HAProxyがインストールされたログのコンテナーレシーバーと、この物理サーバーのデータノードを処理するためのHekaプールをホストします。
新しいクラスターの準備
まず、データノードの1つを解放する必要があります。このサーバーはすぐに新しいクラスターに移動します。 残りの3つの負荷は30%増加しますが、対処します。これは先月のダウンロード統計で確認されています。 さらに、これは長くはありません。 次に、クラスターからのデータノードの標準出力に対する一連のアクションを示します。
新しいインデックスの配置を禁止することにより、4番目のデータノードから負荷を削除します。
{ "transient": { "cluster.routing.allocation.exclude._host": "log-data4" } }
残りのデータノードに不必要な負荷をかけないように、移行時にクラスターの自動リバランスをオフにします。
{ "transient": { "cluster.routing.rebalance.enable": "none" } }
解放されたデータノードからインデックスのリストを収集し、それを3つの等しい部分に分割し、次のように残りのデータノードにシャードの移動を開始します(各インデックスとシャードに対して)。
PUT _cluster/reroute { "commands" : [ { "move" : { "index" : "service-log-2017.04.25", "shard" : 0, "from_node" : "log-data4", "to_node" : "log-data1" } } }
転送が完了したら、解放されたノードをオフにし、リバランスを戻すことを忘れないでください。
{ "transient": { "cluster.routing.rebalance.enable": "all" } }
ネットワークとクラスターの負荷が許容する場合、プロセスを高速化するために、同時に移動するシャードのキューを増やすことができます(デフォルトでは、この数は2です)
{ "transient": { "cluster": { "routing": { "allocation": { "cluster_concurrent_rebalance": "10" } } } } }
古いクラスターは徐々に回復していますが、3つの既存のサーバー上に、ElasticSearch 5.2.2に基づく新しいサーバーを構築し、各ノードに個別のLXDコンテナーを使用しています。 ケースは単純であり、ドキュメントで詳しく説明されているため、詳細は省略します。 どちらかと言えば-コメントで尋ねて、私はあなたに詳細を教えます。
新しいクラスターのセットアップ中に、次のようにメモリを割り当てました。
マスターノード:4 GB
クライアントノード:8 GB
データノード:32 GB
- XMSはどこでもXMXと等しく設定されます。
このような分布は、ドキュメントを理解し、古いクラスターの統計を表示し、常識を適用した後に生まれました。
クラスターを同期します
したがって、2つのクラスターがあります。
古い-それぞれが鉄サーバー上の3つのデータノード。
- 新しく、LXDコンテナーに6つのデータノードがあり、サーバーごとに2つ。
最初に行うことは、両方のクラスターでトラフィックミラーリングを有効にすることです。 Heka受信プール(詳細な説明については、シリーズの前の記事を参照)で、処理中の各サービスに別の出力セクションを追加します。
[Service1Output_Mirror] type = "ElasticSearchOutput" message_matcher = "Logger == 'money-service1''" server = "http://newcluster.receiver:9200" encoder = "Service1Encoder" use_buffering = true
その後、トラフィックは両方のクラスターに並行して送信されます。 21日以内の運用コンポーネントログでインデックスを保存することを考えると、ここで停止できます。 21日後、クラスターのデータは同じになり、古いデータは切断して逆アセンブルできます。 しかし、長く待つのは長くて退屈です。 したがって、最後の最も興味深い段階であるクラスター間のデータ移行に進みます。
クラスター間でインデックスを転送する
プロジェクトの時点ではESクラスター間でデータを移行するための公式の手順がないため、「クランチ」を発明したくありません-Logstashを使用します。 Hekaとは異なり、彼はESにデータを書き込むだけでなく、そこからデータを読み取ることもできます。
前の記事のコメントから判断すると、多くの人が何らかの理由でLogstashが好きではないという意見を形成しています。 ただし、各ツールは独自のタスク用に設計されており、Logstashはクラスター間の移行に最適です。
移行期間中、インデックスのメモリバッファのサイズをデフォルトの10%から40%に増やすと便利です。40%は、ESデータノードの空きメモリの平均量によって選択されます。 また、各データノードでインデックスの更新をオフにする必要があります。そのために、次のパラメータをデータノード構成に追加します。
memory.index_buffer_size: 40% index.refresh_interval: -1
デフォルトでは、インデックスは毎秒更新されるため、余分な負荷がかかります。 したがって、誰も新しいクラスターを見ていませんが、更新を無効にすることができます。 同時に、新しいクラスターのデフォルトテンプレートを作成しました。これは、新しいインデックスを作成するときに使用されます。
{ "default": { "order": 0, "template": "*", "settings": { "index": { "number_of_shards": "6", "number_of_replicas": "0" } } } }
テンプレートを使用して、移行中にレプリケーションをオフにすることで、ディスクシステムの負荷を軽減します。
Logstashの場合、次の構成が取得されました。
input { elasticsearch { hosts => [ "localhost:9200" ] index => "index_name" size => 5000 docinfo => true query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'} } output { elasticsearch { hosts => [ "log-new-data1:9200" ] index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}"}} }
入力セクションでは、データ取得のソースを説明し、5000レコードごとにデータをまとめて収集するようシステムに指示し、タイムスタンプでソートされたすべてのレコードを選択します。
出力では、受信したデータの送信先を指定する必要があります。 古いインデックスから取得できる次のフィールドの説明に注意してください。
document_type-ドキュメントのタイプ(マッピング)。移動時に示す方が適切であるため、新しいクラスターで作成されたマッピングの名前は古いクラスターの名前と一致します。保存されたクエリとダッシュボードで使用されます。
- document_idは、インデックス内のエントリの内部識別子であり、一意の20文字のハッシュです。 明示的な転送により、2つのタスクが解決されます。まず、数十億のレコードごとにIDを生成することなく新しいクラスターの負荷を軽減します。一致するIDを持つエントリは無視されます。
Logstash起動オプション:
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8
移行の速度に影響する重要なパラメーターは、LogstashがESに送信するバンドルのサイズと、処理のために同時に起動されるプロセス(pipeline.workers)の数です。 これらの値の選択を決定する厳密なルールはありません。次の方法で実験的に選択されました。
小さなインデックスを選択します。テストでは、100万のマルチライン(これは重要です)レコードを持つインデックスを使用しました。
Logstashを使用して、このインデックスの移行を開始します。
「拒否された」エントリの数に注意しながら、受信データノードのthread_poolを調べます。 この値の増加は、ESが着信データのインデックスを作成する時間がないことを明確に示しています。その場合、並列Logstashプロセスの数を減らす必要があります。
- 「拒否された」レコードの急激な増加がない場合、バルク/ワーカーの数を増やして、プロセスを繰り返します。
すべてが準備された後、移動のためのインデックスのリストがコンパイルされ、構成が作成され、今後の負荷に関する警告がネットワークインフラストラクチャと監視の部門に送信され、プロセスを開始しました。
logstashプロセスを停止して再起動しないように、次のインデックスの移行が完了した後、新しい構成ファイルで次のことを行いました。
移動のためのインデックスのリストは、3つのほぼ等しい部分に分割されました。
/etc/logstash/conf.d/migrate.confには、構成の静的な部分のみが残っています。
input { elasticsearch { hosts => [ "localhost:9200" ] size => 5000 docinfo => true query => '{ "query": { "match_all": {} }, "sort": [ "@timestamp" ] }'} } output { elasticsearch { hosts => [ "log-new-data1:9200" ] index => "%{[@metadata][_index]}" document_type => "%{[@metadata][_type]}" document_id => "%{[@metadata][_id]}"}} }
ファイルからインデックス名を読み取り、logstashプロセスを呼び出すスクリプトをコンパイルし、インデックス名とノードアドレスを動的に置き換えて移行しました。
- 合計で、各ファイルに1つずつ、 indexes.to.move.0.txt 、 indexes.to.move.1.txt 、 indexes.to.move.2.txtの 3つのスクリプトインスタンスを実行する必要があります。 その後、データは1番目、3番目、5番目のデータノードに送られます。
スクリプトインスタンスの1つのコード:
cat /tmp/indices_to_move.0.txt | while read line do echo $line > /tmp/0.txt && /usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/migrate.conf --pipeline.workers 8 --config.string "input {elasticsearch { index => \"$line\" }} output { elasticsearch { hosts => [ \"log-new-data1:9200\" ] }}" done;
移行ステータスを表示するには、別のスクリプトを「収集」し、別のプロセスで画面を実行する必要がありました( watch -d -n 60を使用) 。
#!/bin/bash regex=$(cat /tmp/?.txt) regex="(($regex))" regex=$(echo $regex | sed 's/ /)|(/g') curl -s localhost:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P $regex |sort > /tmp/indices.local curl -s log-new-data1:9200/_cat/indices?h=index,docs.count,docs.deleted,store.size | grep -P$regex | sort > /tmp/indices.remote echo -e "index\t\t\tcount.source\tcount.dest\tremaining\tdeleted\tsource.gb\tdest.gb" diff --side-by-side --suppress-common-lines /tmp/indices.local /tmp/indices.remote | awk '{print $1"\t"$2"\t"$7"\t"$2-$7"\t"$8"\t"$4"\t\t"$9}'
移行プロセスには約1週間かかりました。 正直なところ、今週は落ち着きがありませんでした。
移動後
インデックスを移動した後、実行することはほとんどありません。 土曜日のある晴れた夜、古いクラスターはオフになり、DNSエントリが変更されました。 したがって、月曜日に仕事に来た人は全員、5番目のKibanaの新しいピンクブルーのインターフェイスを見ました。 スタッフは更新された配色に慣れ、新しい機会を探りながら、仕事を続けました。
古いクラスターから、別の無料サーバーを取得し、新しいクラスター用のESデータノードを持つ2つのコンテナーを配置しました。 残りの鉄はすべて予備になりました。
最終的な構造は、最初のスキームで計画されたとおりになりました。
3つのマスターノード。
3つのクライアントノード。
8つのデータノード(サーバーごとに2つ)。
- 4つのログ受信者(HAProxy + Hekaプール、各サーバーに1つ)。
クラスターを運用モードに移行します-バッファーのパラメーターとインデックスを更新する間隔を返します。
memory.index_buffer_size: 10% index.refresh_interval: 1s
クラスタのクォーラム(3つのマスターノードを考慮)は2に設定されます。
discovery.zen.minimum_master_nodes: 2
次に、8つのデータノードが既にあることを考慮して、シャード値を返す必要があります。
{ "default": { "order": 0, "template": "*", "settings": { "index": { "number_of_shards": "8", "number_of_replicas": "1" } } } }
最後に、適切な瞬間(すべての従業員が家に帰った)を選択し、クラスターを再起動します。
ナシャード、しかし混ぜないでください
このセクションでは、システムの全体的な信頼性の低下に特に注意を払いたいと思います。これは、1台のIronサーバーに複数のESデータノードを配置し、実際に仮想化を行う場合に発生します。
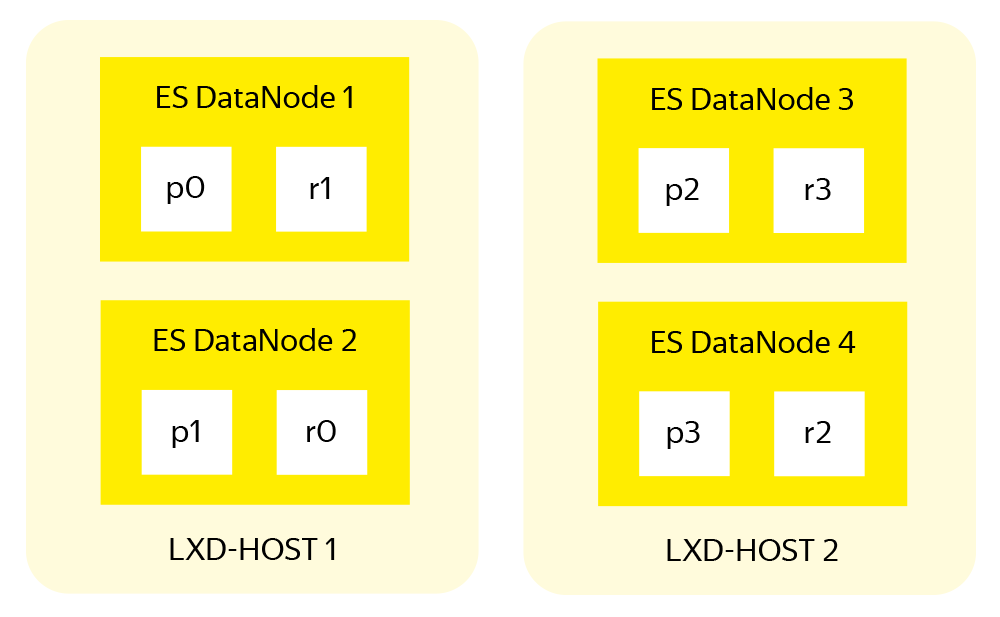
ESクラスターの観点からは、すべてが問題ありません。データノードの数によってインデックスがシャードに分割され、各シャードにはレプリカがあり、プライマリシャードとレプリカシャードは異なるノードに格納されます。
ESのシャーディングおよびレプリケーションシステムは、作業の速度とデータストレージの信頼性の両方を向上させます。 ただし、このシステムは、機器の問題が発生した場合に1つのESデータノードのみが失われる場合に、単一サーバー上の1つのESノードの配置を考慮して設計されました。 クラスターの場合、 2つが落ちます。 すべてのノード間のインデックスの均等分割と各シャードのレプリカの存在を考慮しても、同じシャードのプライマリとレプリカが同じ物理サーバーの2つの隣接するデータノードにある可能性があります。
そのため、ES開発者は、単一クラスター内のシャードの配置を管理するためのツールであるシャード割り当て認識 (SAA)を提案しています。 このツールにより、シャードはデータノードではなく、LXDコンテナを備えたサーバーのようなよりグローバルな構造で動作できます。
各データノードの設定では、それが配置されている物理サーバーを記述するES属性を配置する必要があります。
node.attr.rack_id: log-lxd-host-N
次に、ノードをリロードして新しい属性を適用し、次のコードをクラスター構成に追加する必要があります。
{ "persistent": { "cluster": { "routing": { "allocation": { "awareness": { "attributes": "rack_id" } } } } } }
この順序でのみ、SAAを有効にした後、クラスターは指定された属性のないノードにシャードを配置しないためです。
ところで、同様のメカニズムをいくつかの属性に使用できます。 たとえば、クラスターが複数のデータセンターにあり、それらの間でシャードをやり取りしたくない場合。 この場合、使い慣れた設定は次のようになります。
node.attr.rack_id: log-lxd-hostN node.attr.dc_id: datacenter_name
{ "persistent": { "cluster": { "routing": { "allocation": { "awareness": { "attributes": "rack_id, dc_id" } } } } } }
このセクションのすべてが明らかであるように思われます。 しかし、そもそも私の頭から飛び出すのは明らかに明らかなので、別に確認してください-移動した後は耐え難いほど痛みはありません。
シリーズの次の記事は、私の2つのお気に入りのトピック-既に構築されたシステムの監視と調整に専念します。 すでに書かれているか計画されているものが特に興味深く、質問を提起する場合は、コメントを必ず書いてください 。