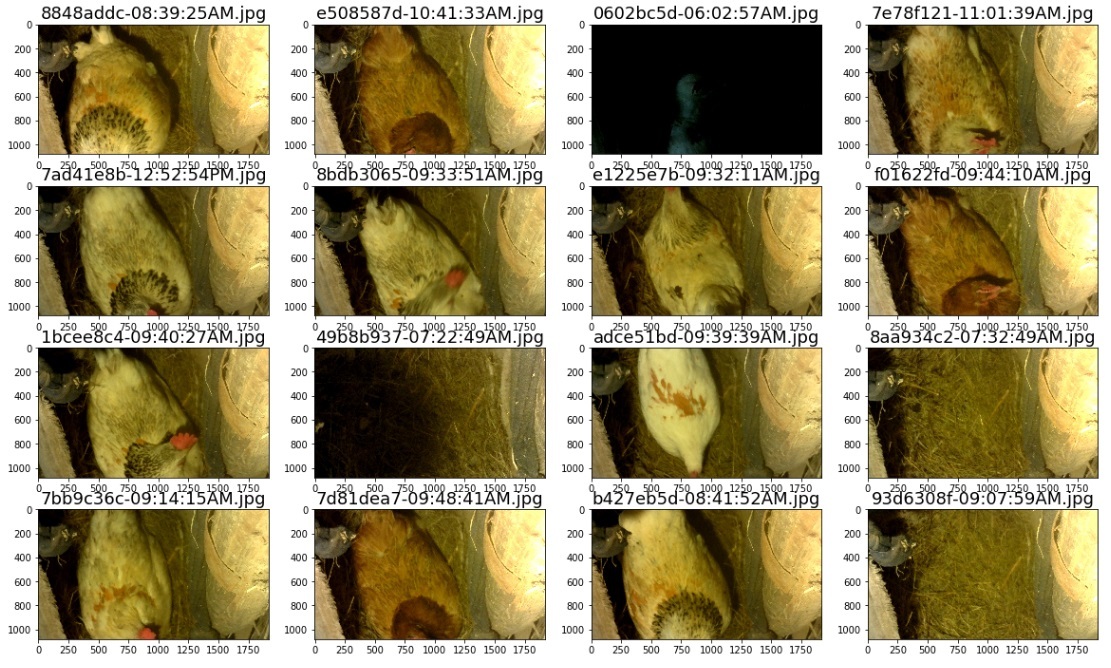
ニューロチキンの家での典型的な一日-ニワトリもしばしば巣で回る
ニューロチキンハウスプロジェクトを最終的に論理的な結論に導くために、作業モデルを作成し、実稼働環境に展開する必要があります。
- 少なくとも70〜90%の予測精度。
- 鶏小屋自体のラズベリーパイは、理想的には、クラスへの写真の帰属を決定できます。
- 少なくともすべての鶏を互いに区別することを学ぶ必要があります。 最大のプログラムはまた、卵を数える方法を学ぶことです。
この記事では、私たちが何になったのか、どのモデルを試したのか、どのような楽しいことをしたのかを説明します。
ニューロチキンハウスに関する記事
ネタバレ見出し
- ニューラルネットワークでのトレーニングの概要
- 鶏を監視するための鉄、ソフトウェア、および構成
- ニワトリの生涯のイベントを投稿するボット -ニューラルネットワークなし
- データセットのレイアウト
- 鶏小屋での鶏の認識の作業モデル
- 結果-鶏小屋で鶏を認識する作業用ボット
0. TL; DR
最もせっかちな場合:
- 精度は約80%でした。
- データセットはここからダウンロードできます 。
- すべての計算と説明付きの定型コードを含むipynb jupyterノートブックはここからダウンロードできます。htmlバージョンはここからダウンロードできます 。
- prodでの悪魔化と展開のためのスクリプト- ここ (ipynb)。
1.プレリュード
ほんの数日前にこのビデオが公開されたので、非常に便利でした。その下には非常に便利なコピーと貼り付けがあります。
この目的に適切に適合する最新のツールのうち、畳み込みニューラルネットワークのみが思い浮かびます。 (リンクを介して、学習したい場合はニューラルネットワークに関する再帰的な記事)を突っ走り、ニューラルネットワークで非常に徹底的な時間を過ごし、Kaggleでのいくつかの競技会(残念ながら既に終了)に参加しましたfast.aiからのコース、私は自分のためにこの計画のようなものを概説しました:
- 小さなデータセットをマークします(そして今日、分類器を構築するために多くのデータを本当に必要としません )
- Kerasを使用して、できるだけ多くのアーキテクチャを最大1日間テストします。
- ラベルのない写真を使用して精度を高めることができる場合(半教師付きアプローチ)。
- ニューラルネットワークの内部層の活性化の視覚化を試みてください。
2.何が起こったのか見てみましょう!
Layer (type) Output Shape Param # ================================================================= batch_normalization_1 (Batch (None, 700, 400, 3) 2800 _________________________________________________________________ conv2d_1 (Conv2D) (None, 698, 398, 32) 896 _________________________________________________________________ batch_normalization_2 (Batch (None, 698, 398, 32) 2792 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 232, 132, 32) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 230, 130, 64) 18496 _________________________________________________________________ batch_normalization_3 (Batch (None, 230, 130, 64) 920 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 76, 43, 64) 0 _________________________________________________________________ flatten_1 (Flatten) (None, 209152) 0 _________________________________________________________________ dense_1 (Dense) (None, 200) 41830600 _________________________________________________________________ batch_normalization_4 (Batch (None, 200) 800 _________________________________________________________________ dense_2 (Dense) (None, 8) 1608 ================================================================= Total params: 41,858,912 Trainable params: 41,855,256 Non-trainable params: 3,656 _________________________________________________________________
約80%の精度を実現した、モデルの最終的なアーキテクチャ
まず、鶏小屋で何が起こっているのかを把握しましょう。 適用されたプロジェクトを正常に作成するには、常に技術チェーンの最大部分を制御する必要があります。 「ここにひどい品質の10テラバイトのビデオがあり、10,000ルーブルのリアルタイムビデオ認識モデルを作成します」または「ここにビールラベルの写真が50枚あります」(ユーモア、しかしこれらは例です)の形式のデータがあれば、プロジェクトを行うことはできません実際の...プロジェクトに基づいて、私のものではなく善に感謝します)。
- 鶏は絶えず巣に登り、好奇心を抱いたり、特に好奇心を失ったりします。
- 若い鶏(上の写真の白)-ある時点まで、彼らは巣に卵を産みませんでしたが、単に他の人の卵を選びました。
- 鶏には手間がかかりますが、95%の場合、ルールに従います:i)巣の中の1羽の鶏ii)鶏の巣の中に10から20個のユニークな写真が撮影されますiii)鶏は通常、卵を完全に閉じますiv)鶏の現在のビューは製品です最適なカメラ位置を見つけるためのいくつかの反復。
- 1日に約300〜400枚の写真が撮影され、5〜8個の卵が産まれます(若い鶏は愚かで怖がって文字通り床の下に走り、22個の卵の塊が床の下で見つかった後、巣に突入し始めました)
- 夜に、鶏は明かりを消します-彼らは寝ます。
- 約900枚の写真にタグが付けられました。
クラスごとに何枚の写真が出たか見てみましょう。
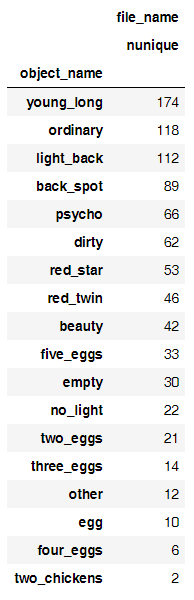
当初、この配置を見て、写真を卵の数で区別することさえ可能になると考えましたが、そうではありませんでした。 このような小さなサンプルで精度を最大化するには、いくつかのことを試してください。
- データ前処理アルゴリズムを正しく選択します(鶏が巣の中で回転しているため、写真を少なくとも180度回転させることができます!);
- 適切なサイズと複雑さのモデルを選択してください。
前処理では、最も簡単です-最も単純な線形モデルを取得し、パラメーターの5-10の組み合わせを試すだけです-Kerasで十分な砂糖を使用して、これはそのような小さなデータセットに1時間パラメーターを代入することによって行われます(10の時代をトレーニングするには1時代に50-100秒かかります) ) 最後になりましたが、これは正規化の目的でも行われます。 ベストプラクティスの1つの例を次に示します。
genImage = imageGeneratorSugar( featurewise_center = False, samplewise_center = False, featurewise_std_normalization = False, samplewise_std_normalization = False, rotation_range = 90, width_shift_range = 0.05, height_shift_range = 0.05, shear_range = 0.2, zoom_range = 0.2, fill_mode='constant', cval=0., horizontal_flip=False, vertical_flip=False)
ここで、実験のほぼ完全なログを見ることができます。
多くのデータセットで異なるアーキテクチャをテストしたモデル自体の選択に関しては、そのようなモデルについて停止しました(ドロップアウトを忘れました-しかし、それを使用したテストでは精度が向上しませんでした):
def getTestModelNormalize(inputShapeTuple, classNumber): model = Sequential([ BatchNormalization(axis=1, input_shape = inputShapeTuple), Convolution2D(32, (3,3), activation='relu'), BatchNormalization(axis=1), MaxPooling2D((3,3)), Convolution2D(64, (3,3), activation='relu'), BatchNormalization(axis=1), MaxPooling2D((3,3)), Flatten(), Dense(200, activation='relu'), BatchNormalization(), Dense(classNumber, activation='softmax') ]) model.compile(Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy']) return model
これが彼女のグラフィック表現です。
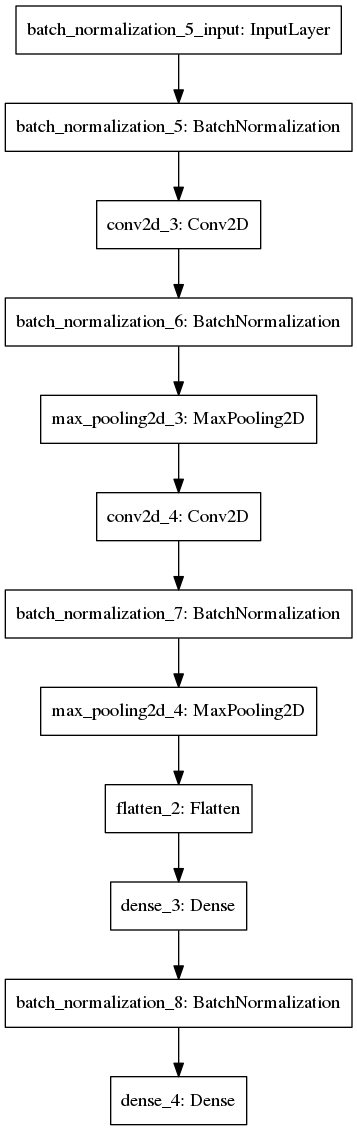
レイヤーの構成と、原則として、現代のほとんどのCNNが非常によく似ている理由を説明します。
- BatchNormalization-入力データを平均し(平均値を減算し、標準偏差で除算します)、ニューラルネットワークのトレーニングを数十倍高速化します。 何らかの理由で興味深い場合は、 ここまたはここで再帰に進んでください 。 使用が必須です。
- Convolution2D-畳み込み層。 実際、これらはフィルターであるため、ニューラルネットワークは抽象的な画像の認識を学習できます。 理論的には、この記事に視覚化を含めるべきでしたが、最終的にはマスターしませんでした(内部からニューラルネットワークがどのように見えるかわからない場合は、 1 2 3のリンクをご覧ください。
- MaxPooling2D-フィルター値の平均化。 畳み込み層の後は必須。
- ドロップアウト-正則化に本質的に必要。 他のプロジェクトからコードを取得し、モデルの精度が高いためにコードを忘れてしまったため、このモデルの仕様には含めませんでした。
- 平坦化-密なレイヤーを挿入します。そうしないと機能しません。
ドロップアウトのあるモデルの仕様は次のようになります(しかし、何らかの理由で、後で歪まないため、一見しただけでは精度が向上しませんでした。おそらく、写真と大きな写真の前処理によって正則化が達成されました)。
# let's try a model w dropout! def getTestModelNormalizeDropout(inputShapeTuple, classNumber): model = Sequential([ BatchNormalization(axis=1, input_shape = inputShapeTuple), Convolution2D(32, (3,3), activation='relu'), BatchNormalization(axis=1), Dropout(rate=0.3), MaxPooling2D((3,3)), Convolution2D(64, (3,3), activation='relu'), BatchNormalization(axis=1), Dropout(rate=0.1), MaxPooling2D((3,3)), Flatten(), Dense(200, activation='relu'), BatchNormalization(), Dense(classNumber, activation='softmax') ]) model.compile(Adam(lr=1e-4), loss='categorical_crossentropy', metrics=['accuracy']) return model
categorical_crossentropyがsoftmaxとともに使用されることに注意してください。 Adamはオプティマイザーとして使用されます。 私がそれらを選んだ理由を止めるつもりはありません(そのような組み合わせは基本的に標準です)が、ここを読んで、 1、2、3を見ることができます
最適なモデルを見つけるプロセスは次のようになります。
- 最も単純なモデルでデータ前処理のさまざまな方法を試します(3層からの最も単純な密集モデルの重みは、大きな写真では数ギガバイトになりますが、これはあまり良くありません)。最適なものを選択します。
- 畳み込み(またはその他の)ニューラルネットワークのさまざまなアーキテクチャを試し、最適なものを選択します。
- 重要なベンチマークに到達したら(50%+精度、75%の精度-タスクから選択すると、クラスが多いほど、ベンチマークはソフトになります)-モデルに問題がある写真とクラスを分析する必要があります。
- 大規模なニューラルネットワークアーキテクチャの外層のアンサンブルと微調整-オプション-競争に勝ちたい場合。
- テスト、検証、または単にデータセットのパーティション分割されていない部分の写真の20-30%をサンプルに混ぜてみてください(半監視、理論上のコードは機能しますが、カーネルはこのタスクで絶えず死にました、私は得点しました)。
- 広告を無限に繰り返します。
42/42 [==============================] - 87s - loss: 2.4055 - acc: 0.2783 - val_loss: 4.7899 - val_acc: 0.1771 Epoch 2/15 42/42 [==============================] - 90s - loss: 1.7039 - acc: 0.4049 - val_loss: 2.4489 - val_acc: 0.2011 Epoch 3/15 42/42 [==============================] - 90s - loss: 1.4435 - acc: 0.4827 - val_loss: 2.1080 - val_acc: 0.2402 Epoch 4/15 42/42 [==============================] - 90s - loss: 1.2525 - acc: 0.5311 - val_loss: 2.4556 - val_acc: 0.2179 Epoch 5/15 42/42 [==============================] - 85s - loss: 1.2024 - acc: 0.5549 - val_loss: 2.2180 - val_acc: 0.1955 Epoch 6/15 42/42 [==============================] - 84s - loss: 1.0820 - acc: 0.5858 - val_loss: 1.8620 - val_acc: 0.2849 Epoch 7/15 42/42 [==============================] - 84s - loss: 0.9475 - acc: 0.6535 - val_loss: 2.1256 - val_acc: 0.1955 Epoch 8/15 42/42 [==============================] - 84s - loss: 0.9283 - acc: 0.6665 - val_loss: 1.2578 - val_acc: 0.5642 Epoch 9/15 42/42 [==============================] - 84s - loss: 0.9238 - acc: 0.6792 - val_loss: 1.1639 - val_acc: 0.5698 Epoch 10/15 42/42 [==============================] - 84s - loss: 0.8451 - acc: 0.6963 - val_loss: 1.4899 - val_acc: 0.4581 Epoch 11/15 42/42 [==============================] - 84s - loss: 0.8026 - acc: 0.7183 - val_loss: 0.9561 - val_acc: 0.6480 Epoch 12/15 42/42 [==============================] - 84s - loss: 0.8353 - acc: 0.7064 - val_loss: 1.0533 - val_acc: 0.6145 Epoch 13/15 42/42 [==============================] - 84s - loss: 0.7687 - acc: 0.7380 - val_loss: 0.9039 - val_acc: 0.6760 Epoch 14/15 42/42 [==============================] - 84s - loss: 0.7683 - acc: 0.7287 - val_loss: 1.0038 - val_acc: 0.6704 Epoch 15/15 42/42 [==============================] - 84s - loss: 0.7076 - acc: 0.7451 - val_loss: 0.8953 - val_acc: 0.7039
そして、インジケーター催眠のプロセスはこのように見えます...
ところで、このコードスニペットは、ケラで半教師付きモデルを作成する場合に役立ちます
# Mix iterator class for pseudo-labelling class MixIterator(object): def __init__(self, iters): self.iters = iters self.multi = type(iters) is list if self.multi: self.N = sum([it[0].N for it in self.iters]) else: self.N = sum([it.N for it in self.iters]) def reset(self): for it in self.iters: it.reset() def __iter__(self): return self def next(self, *args, **kwargs): if self.multi: nexts = [[next(it) for it in o] for o in self.iters] n0s = np.concatenate([n[0] for n in o]) n1s = np.concatenate([n[1] for n in o]) return (n0, n1) else: nexts = [next(it) for it in self.iters] n0 = np.concatenate([n[0] for n in nexts]) n1 = np.concatenate([n[1] for n in nexts]) return (n0, n1) mi = MixIterator([batches, test_batches, val_batches) bn_model.fit_generator(mi, mi.N, nb_epoch=8, validation_data=(conv_val_feat, val_labels))
しかし、鶏に戻ると、ステップ3の後、モデルの結果を分析した後、面白いパターンが見られました。
写真の数に対する正しい予測の比率は次のとおりです
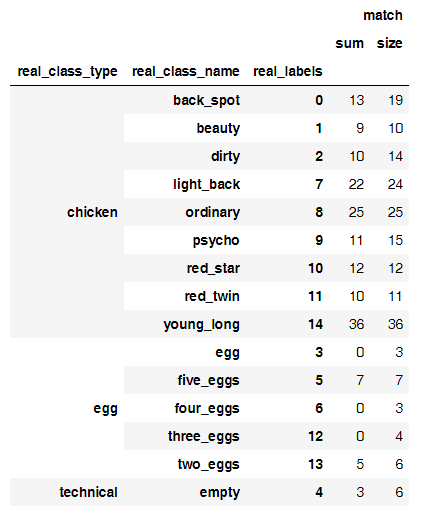
そして、これが誤った分類の主な原因です
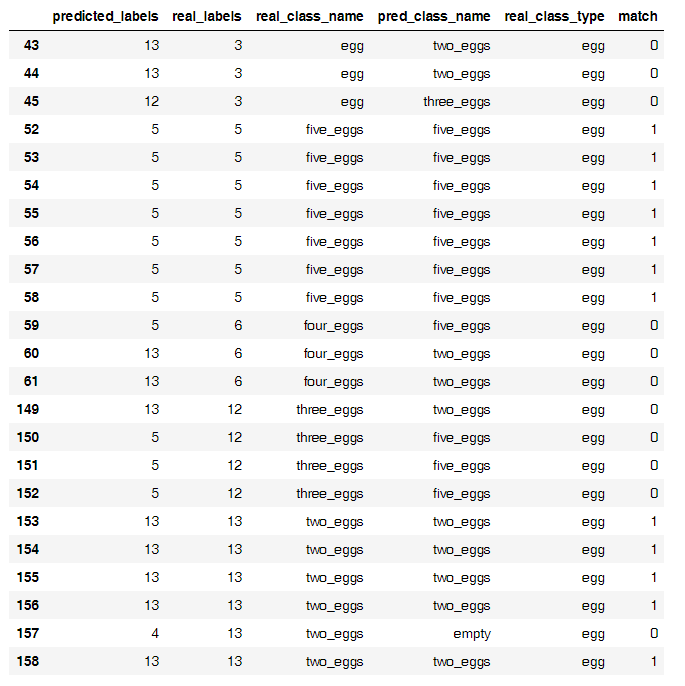
奇妙なことに、このような小さなサンプルでは、ニューラルネットワークが鶏を卵からうまく分離しますが、卵は難しいことがわかりました。 私は卵を50%の精度で数える別のモデルを構築することができましたが、それを訓練し続けませんでした。たぶん卵はそう考えやすいでしょう。
すべての卵を1つのクラスに配置した結果、最終的に小さなデータセットで約80%の精度のモデルが得られました。
3.何が発売されますか?
最後の仕上げは、モデルの製品への展開でした。 ここでは、もちろん、バックグラウンドで悪魔を回転させるいくつかの関数を軽量化して記述する必要があります。 しかし、ここでは記事の冒頭のビデオからのペーストが助けになりました。
このような戦闘展開のコード全体は次のようになります(ここではテンソルフローがバックエンドとして使用されます)。
それは基本的にそれです。
# dependencies import numpy as np import keras.models from keras.models import model_from_json from scipy.misc import imread, imresize,imshow import tensorflow as tf In [3]: def init(model_file,weights_file): json_file = open(model_file,'r') loaded_model_json = json_file.read() json_file.close() loaded_model = model_from_json(loaded_model_json) #load woeights into new model loaded_model.load_weights(weights_file) print("Loaded Model from disk") #compile and evaluate loaded model loaded_model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy']) #loss,accuracy = model.evaluate(X_test,y_test) #print('loss:', loss) #print('accuracy:', accuracy) graph = tf.get_default_graph() return loaded_model,graph loaded_model,graph = init('model.json','model7_20_epochs.h5') In [4]: def predict(img_file, model): # here you should read the image img = imread(img_file,mode='RGB') img = imresize(img,(400,800)) #convert to a 4D tensor to feed into our model img = img.reshape(1,400,800,3) # print ("debug2") #in our computation graph with graph.as_default(): #perform the prediction out = model.predict(img) print(out) print(np.argmax(out,axis=1)) # print ("debug3") #convert the response to a string response = (np.argmax(out,axis=1)) return response In [6]: chick_dict = {0: 'back_spot', 1: 'beauty', 2: 'dirty', 3: 'egg', 4: 'empty', 5: 'light_back', 6: 'ordinary', 7: 'psycho', 8: 'red_star', 9: 'red_twin', 10: 'young_long'} In [7]: prediction = predict('test.jpg',loaded_model) print (chick_dict[prediction[0]]) [[ 2.34186242e-04 5.02209296e-04 5.61403576e-04 9.51264706e-03 2.03147720e-04 1.70257801e-04 4.71635815e-03 5.06504579e-03 1.84403792e-01 7.92831838e-01 1.79908809e-03]] Out [9] red_twin In [11]: import matplotlib.pyplot as plt img = imread('test.jpg',mode='RGB') plt.imshow(img) plt.show()
モデルは忠実な鶏を予測します)忠実な鶏を掲示する最終的なボットを待ちます。