
この画像、Excel、およびデータベースアプリケーションの共通点は何ですか? そうです-データ分析へのベイジアンアプローチ。
上の写真で興味をそそられなかった場合は、ベイジアンネットワークとそれらを膝の上で使用する方法(および実際にあまり使用されない理由)について少し説明させてください。 このテーマは非常に技術的です(スタンフォード大学からの条件付きで無料のコースは少し退屈で非常に技術的ですが、トピックです。まだ少し奇妙です-10時間でコースを完了してすべてを理解でき、MATLABの問題を解決するには50時間かかります-タスクはコースの著者の博士号のようです...)。
0.少しの理論
一言で言えば、簡単な言葉で言えば、ベイジアンモデルは一連の確率分布(用語についてはごめんなさい)であり、矢印で結ばれています(ひどい音ですが、最も簡単な説明はそれです)。 古典的なベイジアンモデルでは、矢印には方向があります(マルコフチェーンでは方向はありません)。
また 、条件付きベイジアン確率の視覚化に関するリンクを再投稿しました。

教授からの定義。
指のモデルをコンポーネントに分割すると、実際には次の要素で構成されます。
- 特定のランダム変数(複雑さ、知性、下の例の推定値)の無条件の確率分布(表の重みの合計は1です);
- 他に依存するランダム変数の条件付き分布。
- そのようなモデル、因果関係、公理学を扱うことができるルール( 上記のコースを参照 );
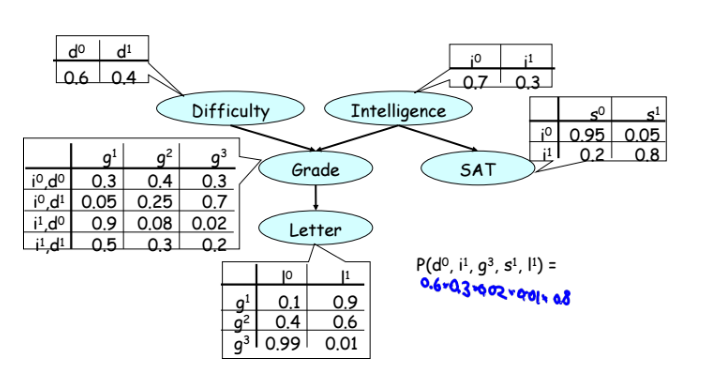
少ない言葉-より多くのアクション。 簡単に説明します。
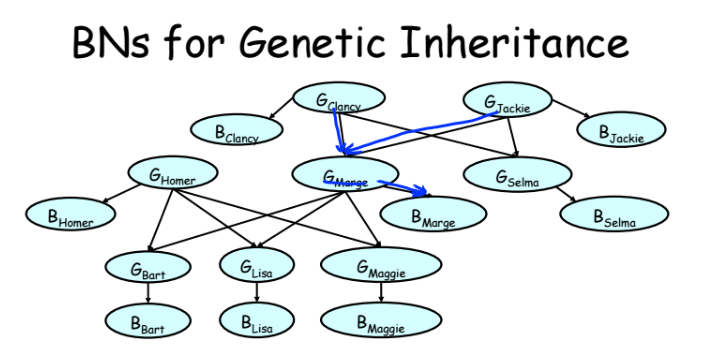
Simsonsの例に関するより複雑なモデル。
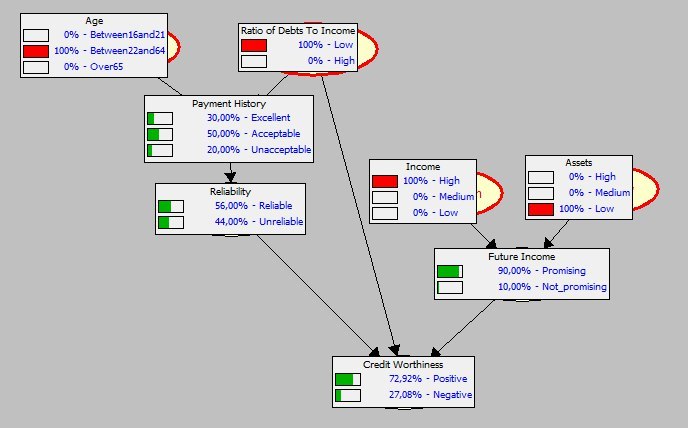
より現実に近いモデル
厳密な意味でのそのようなモデルは数学的なものであり、独自の公理論を持っています。 しかし、私の観点からすると、形式的に関連していない変数について結論を出すことは興味深いことです。 私が本当に理解していないもののジャングルに入らないように、そのようなモデルが実際の生活の中で最も単純な結論を下す方法の3つの例を挙げ、それらが適用された問題を解決するのにどのように役立ち、実際にほとんど使用されないのかを説明します。
1.ちょっとしたロジック
例1-因果関係(コースの例)または帰納(数学では、右矢印=>)。 肯定的なレビュー(手紙)が他のものと同等になる可能性は、約50%です。 同時にあなたがあまり賢くない場合は、39%に低下します。 コースが単純な場合、確率は再び51%に上昇します。 これはすべて単純で論理的なようです。
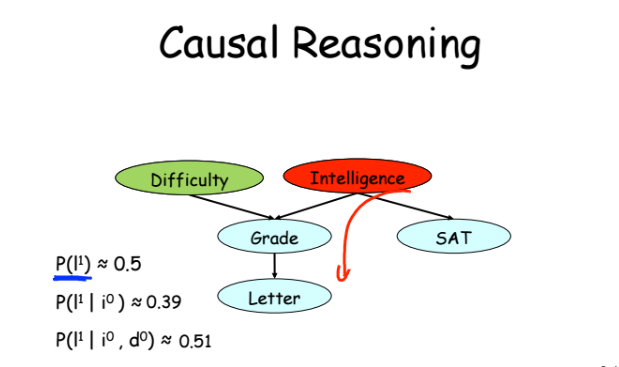
例2-演duction(特定のデータに基づく解決策、または左矢印<=)。 学生がトップ3を獲得した場合、彼があまり賢くない可能性が高まり、コースが複雑である可能性も高まっています。

例3は最も興味深いものです。 学生が上位3つを受け取ったことを記録した場合、観察された主題の複雑さが増すにつれて、学生が頭が良いという可能性も高まり始めます。 学生が受け取った評価を観察することを条件に、変数が何らかの方法で関連していないことが判明します-コースの知能と複雑さが関連します。 本質的に、これはベイズの定理を適用した例にすぎません。

2.ちょっとした練習
このようなモデルが実際には純粋な形でめったに使用されない理由をいくつか説明します。
- このようなモデルのパラメーターの数は非常に多く、多くの場合変数の数よりも多くなります。
- 過去の分布に関する大量の統計が必要です。これはあらゆる知識分野からはほど遠いものです。
- 多くの場合、即時変数を観察することは不可能ですが、観察できるのは人々の行動のログのみです。 上記のモデルでは、評価と複雑さの観察が知能の観察に取って代わることができますが、これはすべて水面に熊手で書かれています。
- 線形モデルを使用する場合、有意性の統計テストがあり、機械学習アルゴリズムを使用する場合、検証とテストサンプリングがあり、ベイジアンモデルを使用する場合、本質的に、アプリオリはすぐに対象領域と多くのデータの深い知識を必要とします;
- 一方、実際には、その論理による回帰またはニューラルネットワークは、特定のデータ構造が固定されている単純なベイジアンモデルです。
そして今、私たちはこれらすべてを頭の中に集め、このアプローチをひそかに適用して、企業データベースを操作します。 サブジェクトエリアとその特定の変数が実際にどのように関連しているかを理解するのが得意であれば、膝の上の超シンプルなベイジアンモデルを使用すると、必要な結論を非常に迅速に引き出すことができます。
会社が3つのものを収集する特定のデータベースがあると想像してください-名前、人のメールアドレスと彼のIPアドレス。 Webサービスの99%がこれらの統計にアクセスできます。 会社がグローバルであり、顧客に地理的な制限がないことを想像してください。タスクは、非常に短期間で誰もが高い確率で話す言語を決定することです。
もちろん、理想的な世界では、これを行うことができます( カッコ内に、なぜ収まらないのかを書いています ):
- クライアントの一部を作成/呼び出して、どの言語を使用しているかを尋ねます(タスクを完了するのに2時間かかり、顧客が数万または数十万人いる場合)
- 言語はその国で最も人気のある言語に等しいという平凡な仮定を受け入れます(そして、IPアドレスに多くの国があり、3-4公用語がどこにあり、言語が人口と職業の異なる層によって異なる使用されますか?);
- クライアントが選択したインターフェースの言語を使用します(まだインターフェースを入力できず、登録したばかりの場合)。
- ブラウザの言語を使用します(そのようなログがまだ保存されていない場合、または保存を忘れた場合はどうなりますか?);
この場合、いわゆる「 スクリーニング 」または原始的な直観的なベイジアン確率の適用からなるアプローチが役立ちます。 次のようになります。
- メールアドレス(aveysov@gmail.com => gmail.com)からメールドメインを選択します。
- すべての明るい国家サービス(中国のqqqまたは123、ロシアのmail.ruなど)-人の名前や最後の国に関係なく、人はサービスの言語を話すと非常に強く言っています。
- 残りから、yahoo.deなどの国内サブドメインまたは国別ドメインのみを選択します。 たとえ最後に電話をかけた国である米国であっても、ドイツ語を話す条件付き確率は、単に電話をかけた国であるドイツよりもはるかに高くなります。
- 残りから、1つの州の言語が正確に普及している明らかな国の言語を配置しました。
- 多数の言語を持つ国や、非常に多国籍/多言語の国があります。
- この場合、理想的には、言語ごとに名前がどのように分布しているかを示すベクトルを見つける必要がありますが、そのような統計をすばやく見つけることができず、残りのユーザーの国で最も人気のある言語に単純に収まりました。
3.ちょっとした美しさ
これで問題ありませんが、プリミティブモデルが機能したことをどのように確認できますか? 非常に簡単です-特定の言語を持つ人々の名前を見てください。 言語は通常、統計的に文化的な財産です(すぐに2〜3の母国語と国籍を持つ人はほとんどいません)。 確率ベクトルだけを構築することも、美しい写真を構築することもできます。
アラビア語

ドイツ語

ギリシャ語

ポルトガル語

スペイン語

中国語

スロベニア語

ハンガリー語

フランス語

ヒンディー語

ポーランド語

ロシア語

チェコ語

そして突然、英語(説明は簡単です-東南アジアの国を削除すると、すべてが適切に配置されます)

東南アジアのない英語

そのようなもの。 トレーニングセットなしで2、3時間で、最も単純なベイジアンモデルを理解すれば、このようなデータセットをふるいにかけ、労力/時間/精度の観点から許容できる結果を得ることができます。