
この記事は、Habréのアルゴリズムの複雑さの漸近分析に関する入門記事を続けています。 ここでは、外部メモリでの平滑化分析とアルゴリズム分析の機能について学習します。 好奇心が強い人は追加の資料へのリンクを待っており、最終的には多項式を食べます。
始める前に知っておくべきことは何ですか?
勤務中、インターンシッププログラムとトレーニングコースの受講生にインタビューしました。 それらの学生の誰も、「O」-大の明確な定義を知りませんでした。 したがって、このような定義については数学文献を参照することを強くお勧めします。 一連の記事「アルゴリズムの複雑さの分析の概要」で、一般的な形式の基本情報を見つけることができます。
平滑化された分析
おそらく、このフレーズを聞くのは初めてです。 驚くことではありません、なぜなら 数学の標準によって最近発表された平滑化分析:2001年。 もちろん、これは、アイデアが表面上にないことを意味します。 最悪の場合の分析、平均分析、および最良の場合の比較的役に立たない分析を既に知っていると仮定します。3つの明らかなオプションがあります。 したがって、4番目のオプションは平滑化分析です。
それがなぜ必要なのかを説明する前に、前の3つが発明された理由を最初に明確にする方が簡単です。 漸近解析が役立つ3つの重要な状況を知っています。
-数学の論文を守りながら。
-あるアルゴリズムが別のアルゴリズムより高速であるか、メモリの消費量が少ない理由を理解する必要がある場合。
-入力サイズの増加に応じて、アルゴリズムの使用時間または使用メモリの増加を予測する必要がある場合。
最後の段落は予約が有効です。 実際の鉄は複雑であるという事実により、成長の性質の理論的評価は、実験で見られるものを下から推定するのに役立ちます。 私は「難しい」という言葉の解読を意図的に省略しています。 それには多くの時間がかかります。 したがって、読者が理解してうなずき、私に質問しないことを願っています。
私たちの目的のために、漸近推定はどのアルゴリズムがより高速に動作するかを述べておらず、さらに特定の実装については何も言っていないことを明確にすることが重要です。 漸近は、成長関数の一般的な形式を予測しますが、絶対値は予測しません。 高速乗算アルゴリズムは、この状況の教科書の例です。 カラツバ法は「数十文字」の長さに達した後にのみナイーブを追い越し、シェーンハーゲ–ストラッセン法は「10,000から40,000桁まで」の長さでカラツバ法を追い抜きます。 漸近線だけを見ると、実験なしでそのような結論を引き出すことは不可能です。
一方、実験の結果を手元に持っているので、そのような傾向が常に続くとか、入力データが幸運でなかったとは結論付けられません。 この状況では、漸近解析が役立ちます。これは、Hoarソートアルゴリズムがバブルよりも高速である理由を証明するのに役立ちます。 言い換えれば、完全な理解と安心のためには、実験データと理論結果の両方が同時に必要です。
これは、1つの漸近的な推定値の存在を説明しますが、残りはなぜですか? すべてがシンプルです。 2つのアルゴリズムのワーストケースの漸近推定が同じであり、実験結果が一方が他方よりも明確な利点を示しているとします。 このような状況では、すべてを説明する違いを求めて平均的なケースを分析する必要があります。 これは、Hoarソートとバブルソートを比較するときに起こることです。最悪の場合は漸近的には同じですが、平均は異なります。
平滑化されたスコアは、平均ケースと最悪ケースの中間です。 次のように書かれています。
どこで いくつかの小さな定数 多くの可能なサイズ入力 、 アルゴリズムが特定のデータの処理に費やす時間(またはメモリ)を返す関数、 -期待、および括弧は便宜上異なります。
簡単に言えば、滑らかな推定は、アルゴリズムが平均よりもゆっくりと動作する十分な大きさの連続したデータが存在しないことを意味します 。 したがって、平滑化されたスコアは平均よりも強くなりますが、最悪よりも弱くなります。 明らかに変化する 中から最大にシフトできます。
定義は簡単ではないため、理解のために図を描きました。
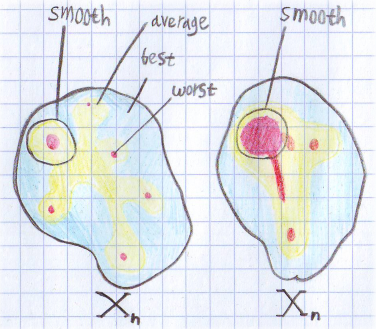 ここで、nの入力データのセット全体の時間分布をプロットします。 赤の領域が最悪の場合、黄色が中間、青が最適です。 左のセットでは、平均と平滑化された推定値はほぼ同じになります。 しかし、適切な平滑化されたスコアでは、最悪のケースに近くなります。 両方のセットについて、平滑化された推定値はアルゴリズムの動作をより正確に表します。 両方の図が同じタスクに対応しているが、アルゴリズムが異なると想像すると、興味深い状況になります。 最高、最悪、および平均のケースの評価は、それらについて同じです。 しかし実際には、左のアルゴリズムの方が気分が良くなります。 右側では、アルゴリズム攻撃をアレンジするのがはるかに簡単です。
ここで、nの入力データのセット全体の時間分布をプロットします。 赤の領域が最悪の場合、黄色が中間、青が最適です。 左のセットでは、平均と平滑化された推定値はほぼ同じになります。 しかし、適切な平滑化されたスコアでは、最悪のケースに近くなります。 両方のセットについて、平滑化された推定値はアルゴリズムの動作をより正確に表します。 両方の図が同じタスクに対応しているが、アルゴリズムが異なると想像すると、興味深い状況になります。 最高、最悪、および平均のケースの評価は、それらについて同じです。 しかし実際には、左のアルゴリズムの方が気分が良くなります。 右側では、アルゴリズム攻撃をアレンジするのがはるかに簡単です。
詳細については、 「アルゴリズムの平滑化分析」の記事をご覧ください。 このアプローチを使用して、シンプレックス法を分析します。 リンクから他の記事を見つけることができます。
外部メモリ内のアルゴリズムの分析
外部メモリのアルゴリズムについて説明する前に、バイパスされる1つのポイントを強調する価値があります。 議論された理論的推定は、とにかくどこでもではなく、「RAMマシン」と呼ばれるモデルで正式に導き出されます。 これは、任意のメモリ位置へのアクセスが1つの基本操作で発生するようなモデルです。 したがって、計算操作とメモリ操作を同等にし、分析を簡素化します。
外部メモリは、ディスク、ネットワーク、またはその他の低速デバイスです。 それらで動作するアルゴリズムを分析するために、外部メモリで異なる実行モデルを使用します。 単純化するために、このモデルではコンピューターに 内部メモリの機械語、費用のかからないすべての操作、CPUでの計算操作にも費用はかかりません。また、サイズのブロック全体でのみ作業できる外部メモリもあります。 単語およびそのような各操作は基本と見なされます。 さらに 大幅に 。 このモデルは、アルゴリズムのIOの複雑さについて語っています。
したがって、各ブロックのメモリでNP完全問題を解決しても、これはアルゴリズムのIO複雑性に影響しません。 しかし、この定式化では、ブロックの長さが固定されているため、これは大きな問題ではなく、このような基本演算があるとだけ言っています。 ただし、このモデルは、ディスク操作の増加を犠牲にしてCPUの操作数を劇的に削減するアルゴリズムに適用できないため、最終的には利益があります。 しかし、この場合でも、このやり取りは重要なことです。 さらに、反対方向の交換はモデルに収まるため、圧縮を追加しても問題は生じません。 また、低速の圧縮アルゴリズムを高速のアルゴリズムに置き換えることは、簡単な交換を意味します。
RAMモデルとの2番目の違いは、操作の形式です。 大きな連続ブロックのみを操作できます。 これは、実際にディスクを操作することを反映しています。 これは、内部メモリと比較したシーケンシャル操作の速度のディスクギャップが、任意のセルでの操作間の同様のギャップよりも小さいという事実によるものです。 したがって、位置決め時間を平準化することが有利です。 モデルでは、単に成功したと言い、位置決め時間はありませんが、長さの連続したブロックがあります モデルが正しいために十分です。
このモデルで分析するときは、次のように丸めに注意してください。 1つの機械語を読んで、 機械語にも同じ時間がかかります。 一般的な読書 連続した単語がかかります 操作、および小さな 特にこの値に何かを掛けた場合は、丸めの寄与が大きくなります。
モデルの特性により、タスクは高速であるかのように解決され始めます。 コンピューティング操作の費用はかかりません。 たとえば、マージソートは それはそれよりもはるかに高速です。 しかし、固定されて、だまされてはいけません そして 、これはすべて、ディスクが簡単に消費する乗法定数のみを提供します。
SSDとキャッシュ
回避できない2つのトピックがあります。 キャッシュから始めましょう。 ロジックはほぼ次のとおりです。一般に、キャッシュとRAMの関係はメモリとディスクの関係に似ています。 ただし、注意点が1つあります。RAMにはランダムアクセスの遅延はありません。 L1キャッシュからの読み取りはメモリからの読み取りよりも約200倍速いという事実にもかかわらず、モデルの基礎は依然として検索の遅れにあります。 質問の別の定式化があります:キャッシュミスの数を最小化するようにアルゴリズムを構成することですが、これは別の議論のトピックです。
SSDは、シーケンシャル読み取りメモリよりも4倍遅いだけですが、ランダム読み取りよりも1,500倍遅いです。 それは、モデル全体が彼にとって公平である理由です。 検索の遅れを平準化する必要があります。
したがって、このモデルは単純ではありますが、多くの場合に有効です。 外部メモリ内のアルゴリズムの詳細については、Maxim Babenkoのコースでの5つの講義の分析例に精通することを提案します。
ボーナス
最後に、NP完全問題の分析で使用される興味深い表記について説明します。 私自身は、この表記法についてアレクサンダー・クリコフの講義「NP困難問題のアルゴリズム」で学びました。
非公式には、記号「O」-大きなものは、シニアメンバーを除くすべてを食べ、シニアメンバーは乗法定数を食べます。 シンボルがあることが判明 、乗算定数だけでなく、多項式全体を食べます。 つまり 、そして 。 したがって、プログラムが遅いために悲しいと感じた場合は、アルゴリズム的にIOの複雑さを考えることができます 。