RMarkdown、Rおよびggplot
この記事はドキュメンテーションではなく、根本的に新しいものでもありません 。レビューまたはチートシートと見なしてください。
前文
会議は主にレポートであり、最後の場所からはほど遠いのがプレゼンテーションスライドの配置方法です。
もちろん 、1枚のスライドがなくてもレポートを実行できるスピーカーはいますが、それでも通常はストーリーをうまく補完します。 一部の人はレポートにメカニックを入れてケースを完成させ、 他の人はコードを挿入し、アセンブラーに入れる必要があります(まだ知らない-JPointはJava会議です)。グラフを表示する必要がある人もいます。 ただし、両方の組み合わせがあります。
おそらく、スライドを作成するための有名なツールは次のとおりです。
- PowerPoint、およびLibreOffice Impress、Apple KeyNoteの顔のバリエーション
- 同じアプローチのクラウドバリエーション-Googleスライド
- ラテックス
- 比較的新しい(私にとって) RMarkdown
そして、最初の2つが本質的にバイナリ形式であり、曇りのGoogleスライドもインターネットの存在を必要とする場合(これは旅行やフライト中に不快な制限です)、最後の2つはオフラインであり、テキストのみです。 git / hg /のすべての変更の履歴。 さらに、範囲はスライドに限定されません。
歴史のあるLaTeX形式-たくさん書かれ、言われていますが、RMarkdownは若いです。
マークダウン
Markdownは、読みやすく編集しやすいテキストを書くために設計された軽量のマークアップ言語です。 Markdownは、 変換しなくても理解しやすく、読みやすいです。
自分で比較してください: __
は斜体で 、 ** **
は強い選択 です 。さらに多くはマークダウンチートシートで詳しく説明されています。
Markdownは、github、habrahabr、sublime、jira(同様の構文を使用)、および他の多くをサポートしています。
R
Rは、統計データ処理とグラフィックスのためのプログラミング言語です。
原則として、これは停止します-それは非常に難しく、数学であり、必要ではありません-しかし、誰もあなたがすべての利用可能な機能、おそらく最も簡単で明白なものを使用することを強制しません-これらはグラフィックと視覚化です。
Excelはチャートの作成によく使用されますが、データの量がすでに100万に近い場合に対処することは非常に困難です。 Rの場合、これは難しい作業ではありません。
データとチャート
戦いを舞台裏に残します。テーブルまたはグラフです。 好みの問題。
プロットには、 ggplot2拡張を使用します。
拡張 : RとRStudio自体が必要です。たとえば、MacOS / Homebrewの場合:
$ brew tap homebrew / science
$ brew install r
$ brew skas install rstudio
RStudio for Rにモジュールをインストールします。
install.packages("ggplot2")
ただし、グラフを作成するにはデータが必要であり、プレゼンテーションとは別に、たとえばcsv形式で保存するのが合理的です。これも単純なテキスト形式です。
私のデータは、 jmhでhashCodeキーホールを介してVM内部でレポートを取得した結果です。 Alexei Shipilevで使用されているスタイルが好きです。ファイルの先頭にベンチマーク結果をコメントとして書き込む-grep -n-sedとcsvファイルがあります。
csv/allocations.csv
データ:
pos,alloc,value,error 10,single-threaded,2.836,0.285 20,java,9.878,2.676 28,epsilon,75.289,23.667 30,sync,186.672,21.195 40,cas,74.721,0.192 50,tlab,8.506,1.849 55,javaHashCode,60.270,12.318 57,readHashCode,7.296,0.316
csvファイルからデータフレームを作成します-デフォルトでは、ファイルにヘッダーがあると考えられています-これは、個々の列にアクセスするときに役立ちます
```{r} df = read.csv(file = "csv/allocations.csv") ```
たとえば、 alloc列の特定の値でフィルタリングする場合
df <- subset(df, alloc == "cas" | alloc == "java" | alloc == "sync" | alloc == "tlab" )
バー/バー
最初に、データテーブルから変数一致スキーム ( aes )を指定する必要があります-タイプの値、この場合は割り当てのタイプ、バーの色も割り当てのタイプに基づいて選択されます。
ggplot(data=df, aes(x=alloc, y=value, fill=alloc))
列( 棒グラフ ) + geom_bar()の形式で表示します
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity")
結果:

オプション+ coord_flip()で座標系を(垂直バーから水平バーに)回転させます
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip()

変更エラー+ geom_errorbar()を追加します( csvファイルにエラー列があることを思い出してください ):
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5)

明確にするために、バーの横に値を追加する価値があります+ geom_text() (テキストが値になるのは論理的です )
ggplot(data=df, aes(x=alloc, y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5) + geom_text(aes(label=value))

署名の光沢+ geom_text()を追加します。
- 関数を使用して署名値を変更します±エラー - ラベル=ベース:: sprintf( "%0.2f±%0.2f"、値、エラー) (hello good old sprintfとテンプレートの書式設定%f !)
- 水平方向のジャストと垂直方向のジャストシグネチャレイアウトを試してみましょう
署名のフォント サイズとフォントフォントを変更する
ggplot(データ= df、aes(x = alloc、y =値、fill = alloc))+
geom_bar(stat = "identity")+
coord_flip()+
geom_errorbar(aes(ymin =値-エラー、ymax =値+エラー)、幅= 0.5、アルファ= 0.5)+
geom_text(aes(label = base :: sprintf( "%0.2f±%0.2f"、値、エラー))、hjust = -0.1、vjust = -0.4、size = 5、fontface = "bold")

- テーマをねじる+ theme_classic()
- 凡例+テーマを削除します(legend.position = "none")
ラベル+ラボ(タイトル= ...、x = ...、y = ..)およびAxes +テーマ(axis.text.y = ..)のフォントを追加します
ggplot(データ= df、aes(x = alloc、y =値、fill = alloc))+
geom_bar(stat = "identity")+
coord_flip()+
geom_errorbar(aes(ymin =値-エラー、ymax =値+エラー)、幅= 0.5、アルファ= 0.5)+
geom_text(aes(label = base :: sprintf( "%0.2f±%0.2f"、value、error))、hjust = -0.1、vjust = -0.4、size = 5、fontface = "bold")+
labs(タイトル= "@Threads(4)"、x = ""、y = "ns / op")+
theme_classic()+
テーマ(axis.text.y = element_text(size = 16、face = "bold"))+
テーマ(axis.title = element_text(size = 16、face = "bold"))+
テーマ(legend.position = "none")

そして最終的な光沢を与えるため
- 色を指定+ scale_fill_manual()
- 垂直軸とバー+ scale_y_continuous()の間のギャップを削除し、値の範囲をわずかに拡大して、エラーが収まるようにし、署名
- pos列に従ってバーの順序を修正します。x = reorder(alloc、-pos)
ggplot(data=df, aes(x=reorder(alloc, -pos), y=value, fill=alloc)) + geom_bar(stat="identity") + coord_flip() + geom_errorbar(aes(ymin = value - error, ymax = value + error), width=0.5, alpha=0.5) + geom_text(aes(label=base::sprintf("%0.2f ± %0.2f", value, error)), hjust=-0.1, vjust=-0.4, size=5, fontface = "bold") + scale_fill_manual(values=c(java'='#a9a518','sync'='#fa8074', 'cas'='#00b3f6', 'tlab'='#e67bf3')) + labs(title = "@Threads( 4 )", x = "", y = "ns/op") + theme_classic() + scale_y_continuous(limits=c(0, max(df$value) + 40), expand = c(0, 0)) + theme(axis.text.y = element_text(size = 16, face = "bold")) + theme(axis.title = element_text(size = 16, face = "bold")) + theme(legend.position="none")

ヒント :グラフをファイル+ ggsave( "allocations.svg")に保存できますが、ベクトル形式を乱用しないでください。グラフに多数のドットがある場合は、ラスタ(たとえばpng)に保存してください。
install.packages("svglite")
それとは別に、デフォルトのカラーパレットに注目する価値があります。選択した色は、色覚が弱くなっている人でもはっきりと区別できます。
良い/悪いものを強調するために2色のみを使用する場合でも、赤/緑の組み合わせを使用しないでください。これらの色は、色の知覚が悪い人にとってはほとんど区別できません。
ヒント : colorbrewer2は選択に役立ちます 安全な色。
ポイント
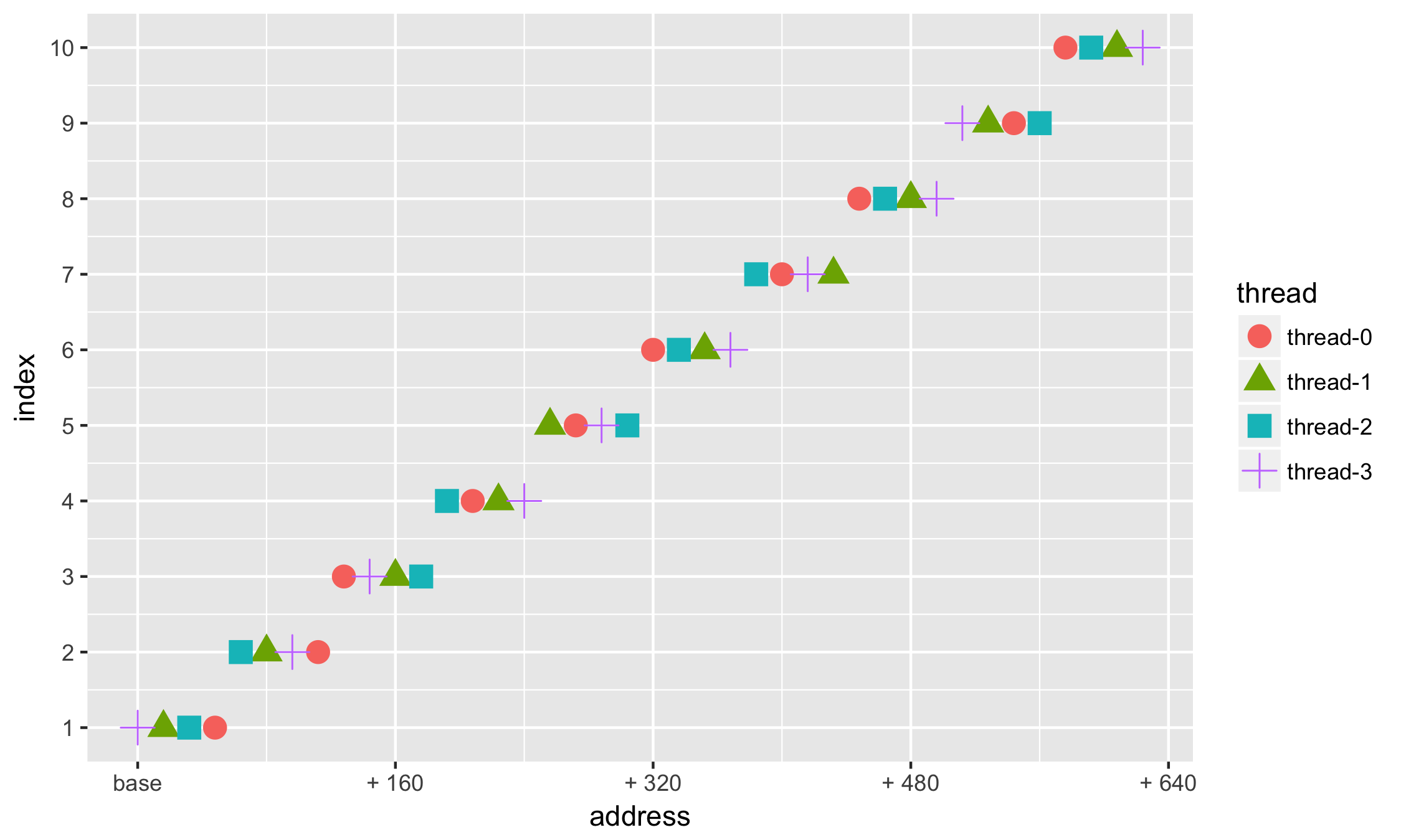
スレッドによるアドレスの分布があります
step,thread,address 1,thread-0,807437816 1,thread-1,807437784 1,thread-2,807437800 ..........
ポイント+ geom_pointで個別に表示
ggplot(データ= df、aes(x =アドレス、y =インデックス、グループ=スレッド、色=スレッド、形状=スレッド))+
geom_point(サイズ= 2)
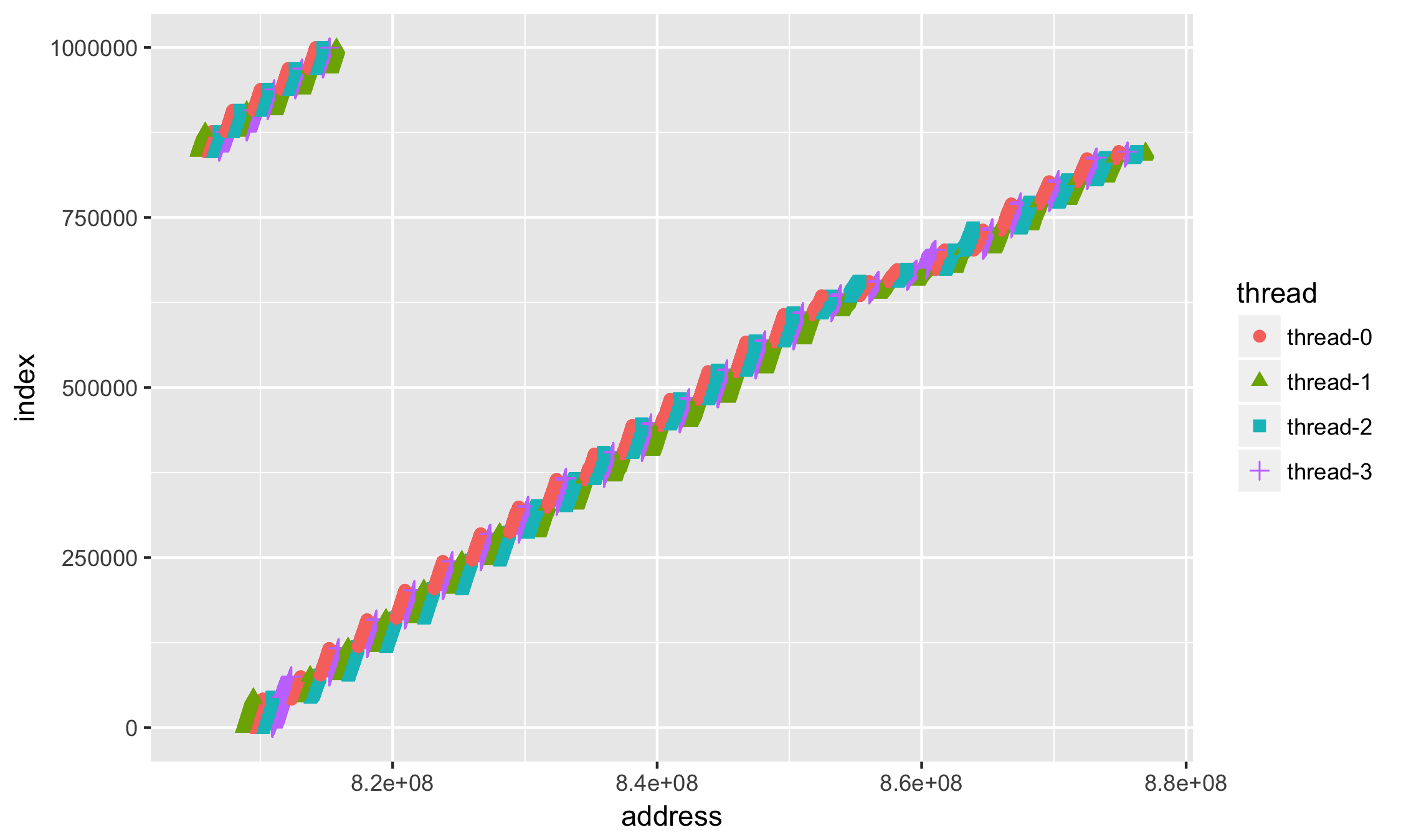
最初に目を引くのは(大量のデータがあることを除いて)、科学表記法でのアドレスの値です。 16進システムでアドレスを扱う方がなにかおなじみです 。X軸+ scale_x_continuous()に沿って値のフォーマットを追加します。
ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n){base::sprintf("0x%X", as.integer(n))} )
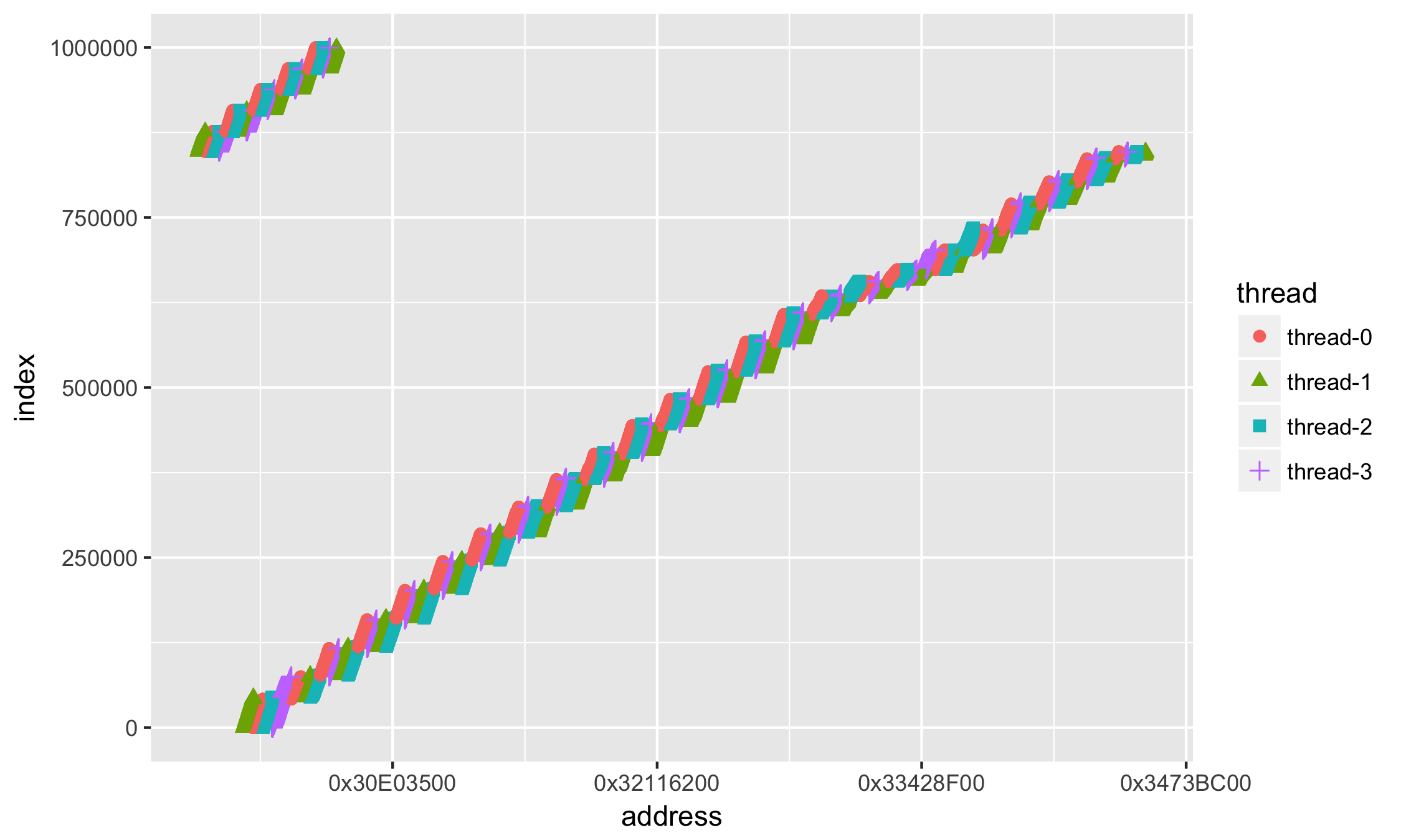
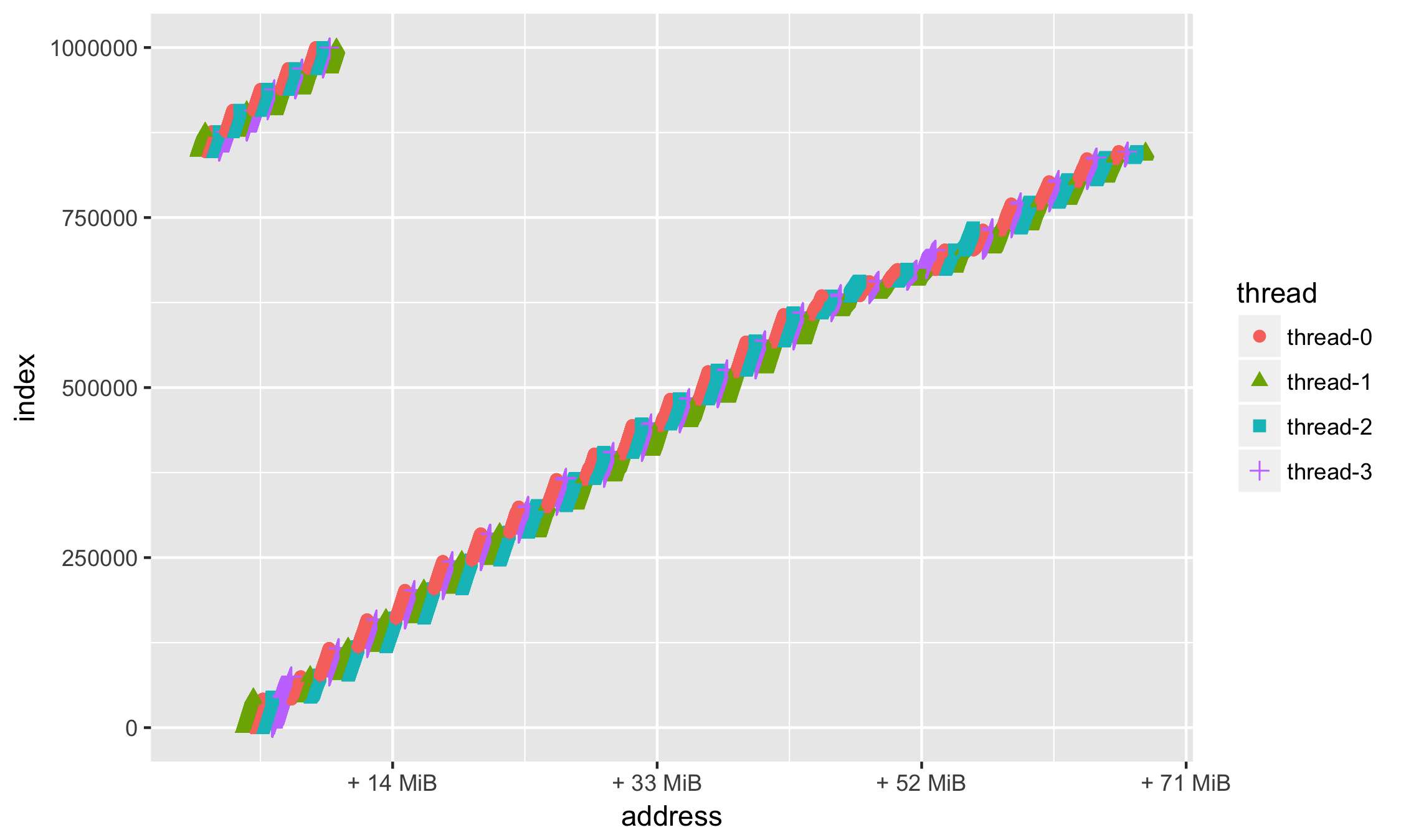
より良いが、それでもどういうわけか複雑で、ほとんど理解されていない。
任意の関数を指定できるので、いくつかの基本的な(たとえば最小の)アドレスに対するオフセットを表示しないのはなぜですか。
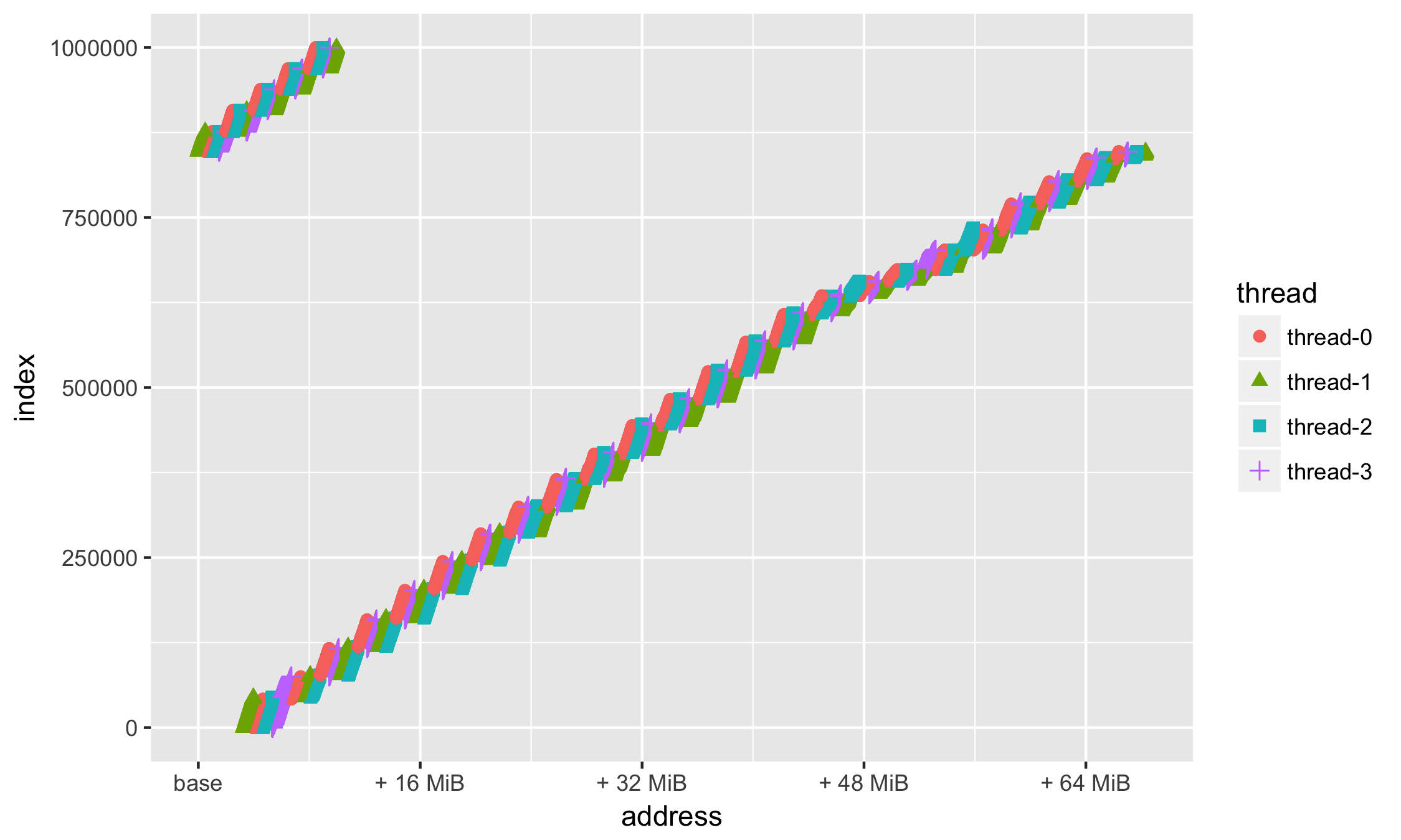
min_address = min(df$address) ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n){base::sprintf("+ %d MiB", as.integer((n - min_address)/1024/1024))} )
繰り返しになりますが、習慣により、ラベル( breaks = )を整数( 16、32、48、64 MB)で配置します。
ggplot(data=df, aes(x = address, y = index, group=thread, colour=thread, shape=thread)) + geom_point(size=2) + scale_x_continuous( labels = function(n){ifelse(n == min_address, base::sprintf("base"), base::sprintf("+ %d MiB", as.integer((n - min_address)/1024/1024)))}, breaks=c(min_address, min_address + 16*1024*1024, min_address + 32*1024*1024, min_address + 48*1024*1024, min_address + 64*1024*1024) )
大量のデータ-ほんの一部を見たい
- read.csvのロード時にデータセットをnrowの数に制限します(...)
Y軸の適切な場所にラベルを追加します。 + scale_y_continuous(breaks = c(...))
df = read.csv(ファイル= "csv / hashCodesNoTLAB.csv"、nrows = 36、ヘッダー= TRUE)
min_address = min(df $アドレス)
ggplot(データ= df、aes(x =アドレス、y =インデックス、グループ=スレッド、色=スレッド、形状=スレッド))+
geom_point(サイズ= 4)+
scale_x_continuous(
labels = function(n){ifelse(n == min_address、base :: sprintf( "base")、base :: sprintf( "+%d"、as.integer((n-min_address))))}、
breaks = c(最小アドレス、最小アドレス+ 16 10、最小アドレス+ 2 16 10、最小アドレス+ 3 16 10、最小アドレス+ 4 16 10、最小アドレス+ 5 16 * 10)
)+
scale_y_continuous(breaks = c(1,2,3,4,5,6,7,8,9,10))+
棒グラフ
そしてもちろん- ヒストグラム 、度数分布。 これは大まかに言って、値の範囲に入る要素の数として説明できます。 たとえば、シリーズ[1、2、3、1、1]の場合、ヒストグラムは[3、1、1]のようになります-要素1は3回、要素2と3は 1回出現したためです。
addressHashCode = read.csv(file = "csv/addressHashCode.csv") defaultHashCode = read.csv(file = "csv/defaultHashCode.csv") ggplot() + geom_histogram(data=addressHashCode, aes(x=hashCode, fill="address"), alpha=0.7, bins = 500) + geom_histogram(data=defaultHashCode, aes(x=hashCode, fill="MXSRng"), alpha=0.7, bins = 500) +
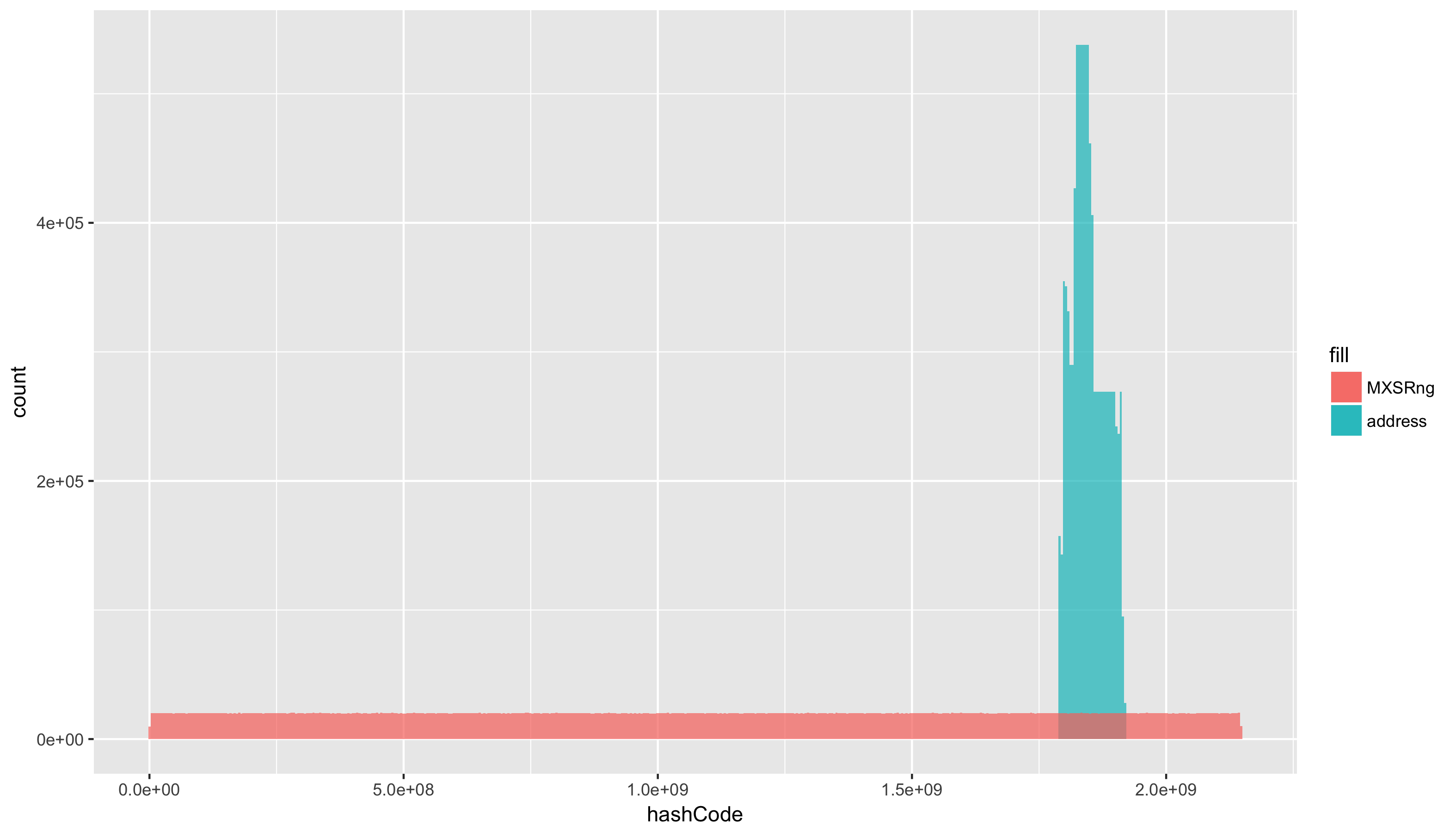
既知のオプションを追加して、目的の外観を提供します。
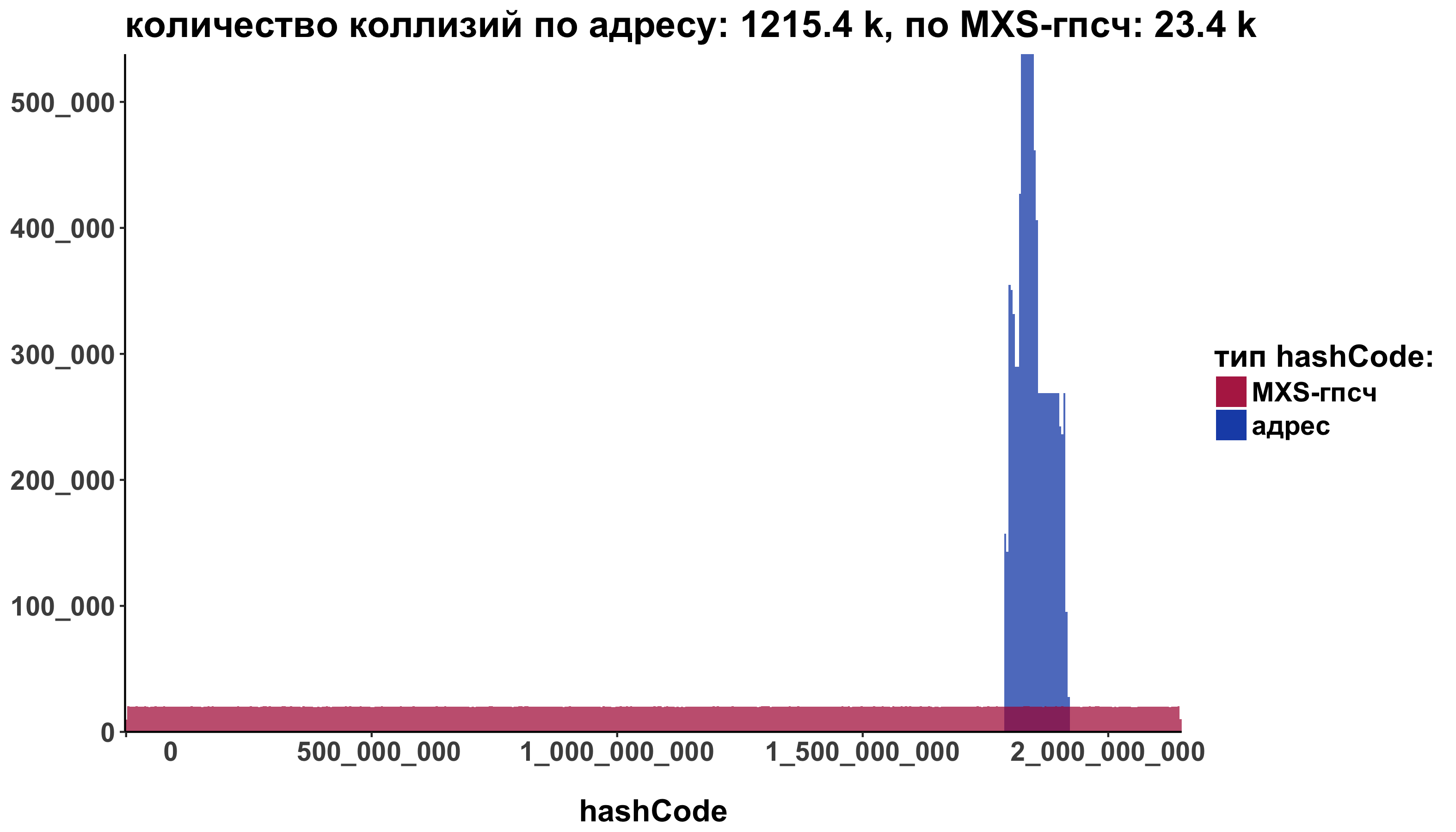
ggplot() + geom_histogram(data=addressHashCode, aes(x=hashCode, fill="address"), alpha=0.7, bins = 500) + geom_histogram(data=defaultHashCode, aes(x=hashCode, fill="MXSRng"), alpha=0.7, bins = 500) + scale_fill_manual(name=" hashCode:", labels=c("address"="", "MXSRng"="MXS-"), values=c("address" ="#003dae", "MXSRng" = "#ae003d")) + labs(title = sprintf(" : %sk, MXS-: %s k", round( sum(duplicated(addressHashCode)) / 1000, 1), round( sum(duplicated(defaultHashCode)) / 1000, 1)), x = "hashCode") + theme_classic() + theme(axis.title.y=element_blank()) + scale_y_continuous(labels = function(n){format(n, big.mark = "_", scientific = FALSE)}, expand = c(0, 0)) + scale_x_continuous(labels = function(n){format(n, big.mark = "_", scientific = FALSE)}, expand = c(0, 0)) + theme(axis.title = element_text(size = 16, face = "bold")) + theme(axis.text.y = element_text(size = 14, face = "bold")) + theme(axis.text.x = element_text(size = 14, face = "bold")) + theme(axis.title = element_text(size = 16, face = "bold")) + theme(axis.title.x=element_text(margin=margin(t=20))) + theme(legend.text = element_text(size = 14, face = "bold")) + theme(title = element_text(size = 16, face = "bold")) +
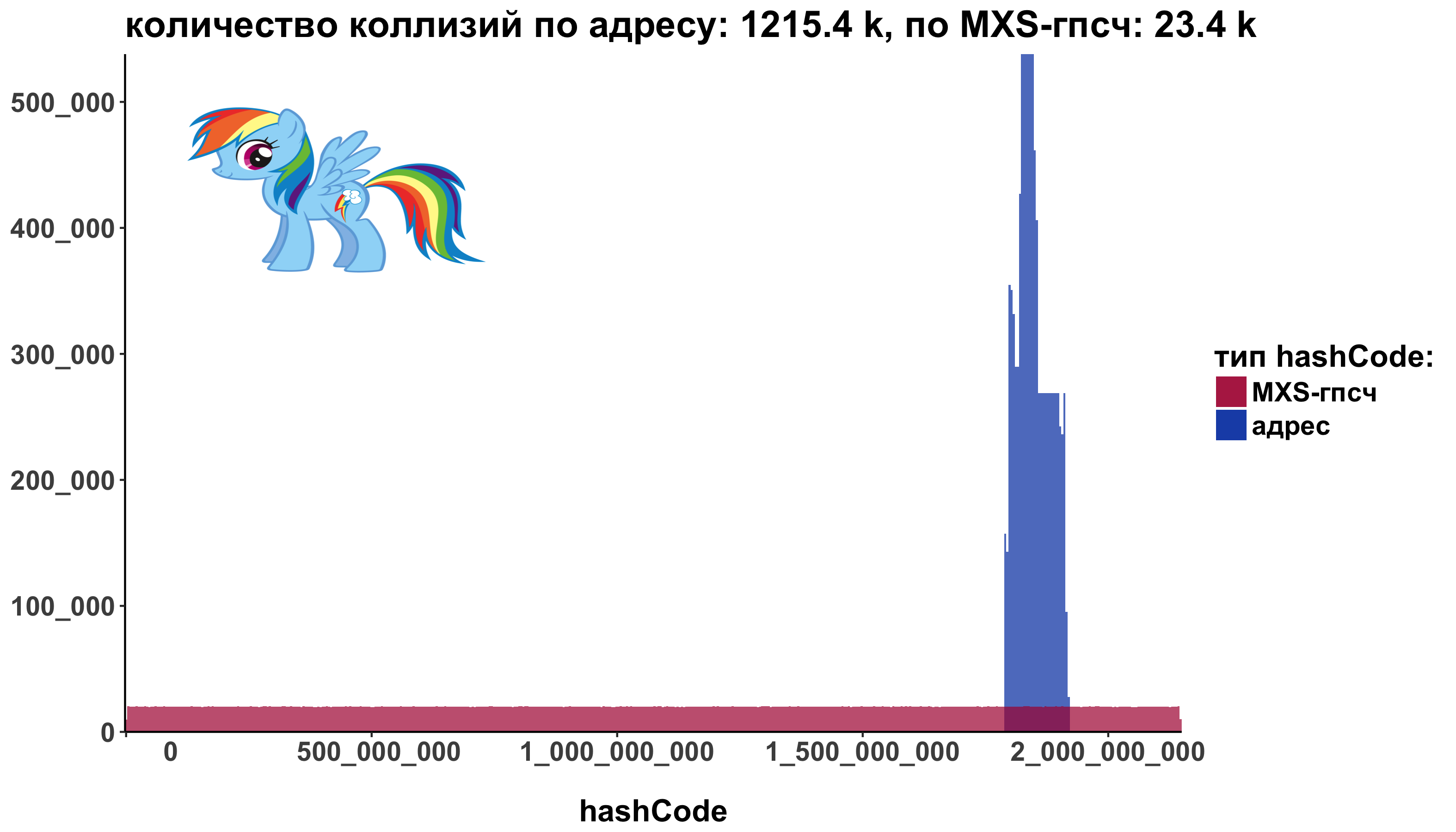
ポニーはどうですか? 簡単!
- pngパッケージが必要:
install.packages('png')
- img <-readPNG( "images / pony.png")
- 内部バッファにレンダリング g <-rasterGrob(img)
- 注釈として+ポニーを追加+ annotation_custom() :
# install.packages('png') img <- readPNG("images/pony.png") g <- rasterGrob(img, interpolate=TRUE, x = 0.1, y = 0.9, width = 0.2, height = 0.2) ggplot() + annotation_custom(g, xmin=-Inf, ymin = -Inf, xmax=Inf, ymax=Inf) + geom_histogram(data=addressHashCode, aes(x=hashCode, fill="address"), alpha=0.7, bins = 500) + geom_histogram(data=defaultHashCode, aes(x=hashCode, fill="MXSRng"), alpha=0.7, bins = 500)
便利なリンク: ggplot2チュートリアルと別の便利なブログRを使用したデータの分析、調査、分析
RMarkdown
RMarkdownがR + Markdownであることを理解するのに大きなキャプテンである必要はありません。
Rのモジュールをインストールします。
install.packages("rmarkdown")
そして、 私が知っているHTMLの言葉で、LaTeXは RMarkdownのレンダリングが大好き です :
rmarkdown :: render( "path_to_file.Rmd"、エンコーディング= "UTF-8")
ヘッダーで示すだけで十分です。たとえば:
出力:pdf_document
- スライド/プレゼンテーション:
これを行うには、ヘッダーの出力を変更します 。
出力:ioslides_presentation