Bashスクリプト:開始
Bashスクリプト、パート2:ループ
Bashスクリプト、パート3:オプションとコマンドラインスイッチ
Bashスクリプト、パート4:入力と出力
Bashスクリプト、パート5:シグナル、バックグラウンドタスク、スクリプト管理
Bashスクリプト、パート6:関数とライブラリーの開発
Bashスクリプト、パート7:sedとワープロ
Bashスクリプト、パート8:awkデータ処理言語
Bashスクリプトパート9:正規表現
Bashスクリプト、パート10:ケーススタディ
Bashスクリプト、パート11:対話型ユーティリティの期待と自動化
sedとawkを使用してbashスクリプトでテキストを完全に処理するには、正規表現を処理するだけです。 この便利なツールの実現は文字通りどこでも見つけることができ、すべての正規表現は同じアイデアに基づいて同様の方法で配置されますが、異なる環境でそれらを操作することには特定の機能があります。 ここでは、Linuxコマンドラインスクリプトでの使用に適した正規表現について説明します。

この資料は、それが何であるかを完全に知らない可能性のある人向けに設計された正規表現の紹介を目的としています。 したがって、最初から始めます。

正規表現とは何ですか?
多くの人にとって、最初に正規表現を見ると、意味のない山のシンボルに直面しているという考えがすぐに生じます。 しかし、これはもちろん、そうではありません。 たとえば、この正規表現を見てください
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
私たちの意見では、完全な初心者でもすぐにそれがどのように機能し、なぜそれを必要とするかを理解するでしょう:)あなたがよく理解していないなら、ただ読んでください、そしてすべてが適切に落ちます。
正規表現は、sedやawkなどのプログラムがテキストをフィルタリングするために使用するパターンです。 テンプレートは、それ自体を表す通常のASCII文字と、たとえば特定の文字グループを参照できるようにするなど、特別な役割を果たすいわゆるメタ文字を使用します。
正規表現タイプ
さまざまな環境、たとえばJava、Perl、Pythonなどのプログラミング言語、sed、awk、grepなどのLinuxツールでの正規表現の実装には、特定の機能があります。 これらの機能は、パターンの解釈を処理するいわゆる正規表現処理エンジンに依存しています。
Linuxには2つの正規表現エンジンがあります。
- POSIX Basic Regular Expression(BRE)標準をサポートするエンジン。
- POSIX拡張正規表現(ERE)標準をサポートするエンジン。
ほとんどのLinuxユーティリティは、少なくともPOSIX BRE標準に準拠していますが、一部のユーティリティ(sedを含む)はBRE標準のサブセットのみを理解します。 この制限の理由の1つは、ワードプロセッシングでこのようなユーティリティを可能な限り高速にすることです。
POSIX ERE標準は、多くの場合、プログラミング言語で実装されています。 正規表現の開発に多数のツールを使用できます。 たとえば、テキスト内で個々の単語や数字のセットを検索するなど、一般的に使用されるパターンの特殊な文字シーケンスを使用できます。 AwkはERE標準をサポートしています。
プログラマーの意見と、それが作成されたエンジンの機能に応じて、正規表現を開発する多くの方法があります。 どのエンジンでも理解できる普遍的な正規表現を書くのは簡単ではありません。 したがって、最も一般的に使用される正規表現に焦点を当て、sedおよびawkの実装の機能を検討します。
POSIX BRE正規表現
おそらく最も単純なBREパターンは、テキスト内の文字シーケンスの正確な出現を見つけるための正規表現です。 sedとawkの文字列検索は次のようになります。
$ echo "This is a test" | sed -n '/test/p' $ echo "This is a test" | awk '/test/{print $0}'

sedのパターンでテキストを検索

awkのパターンでテキストを検索する
特定のテンプレートの検索は、行内のテキストの正確な位置を考慮せずに実行されることに気付くかもしれません。 さらに、発生回数は重要ではありません。 正規表現が文字列内の指定されたテキストを見つけた後、文字列は適切であると見なされ、さらなる処理に渡されます。
正規表現を使用する場合、大文字と小文字が区別されるという事実を考慮する必要があります。
$ echo "This is a test" | awk '/Test/{print $0}' $ echo "This is a test" | awk '/test/{print $0}'

正規表現では大文字と小文字が区別されます
最初の正規表現は一致しませんでした。大文字で始まる「test」という単語がテキストに表示されないためです。 2つ目は、大文字で書かれた単語を検索するように構成されており、ストリーム内で適切な文字列を見つけました。
正規表現では、文字だけでなくスペースと数字も使用できます。
$ echo "This is a test 2 again" | awk '/test 2/{print $0}'

スペースと数字を含むテキストを検索します
スペースは、正規表現エンジンによって正規の文字として認識されます。
特殊文字
正規表現で異なる文字を使用する場合、いくつかの機能を考慮する必要があります。 そのため、テンプレートでの使用には特別なアプローチが必要な特殊文字またはメタキャラクターがいくつかあります。 ここにあります:
.*[]^${}\+?|()
テンプレートでそれらのいずれかが必要な場合は、バックスラッシュ(バックスラッシュ)-
\
エスケープする必要があります。
たとえば、テキスト内でドル記号を見つける必要がある場合は、エスケープ文字を前に付けて、テンプレートにドル記号を含める必要があります。 次のテキストを含む
myfile
とします。
There is 10$ on my pocket
ドル記号は、次のパターンを使用して検出できます。
$ awk '/\$/{print $0}' myfile

テンプレートで特殊文字を使用する
さらに、バックスラッシュも特殊文字であるため、テンプレートで使用する必要がある場合は、エスケープする必要もあります。 互いに続く2つのスラッシュのように見えます。
$ echo "\ is a special character" | awk '/\\/{print $0}'

バックスラッシュのエスケープ
上記の特殊文字のリストにはスラッシュは含まれていませんが、sedまたはawk用に記述された正規表現でスラッシュを使用しようとすると、エラーが発生します。
$ echo "3 / 2" | awk '///{print $0}'

テンプレートでのスラッシュの誤った使用
必要な場合は、エスケープする必要もあります。
$ echo "3 / 2" | awk '/\//{print $0}'

スラッシュのエスケープ
アンカー記号
テキスト文字列の先頭または末尾にパターンを添付するための2つの特殊文字があります。 カバー文字-
^
使用すると、テキスト行の先頭にある文字のシーケンスを説明できます。 目的のパターンが文字列の別の場所にある場合、正規表現はそれに応答しません。 このシンボルの使用は次のようになります。
$ echo "welcome to likegeeks website" | awk '/^likegeeks/{print $0}' $ echo "likegeeks website" | awk '/^likegeeks/{print $0}'

行の先頭でパターンを検索する
^
文字は、行の先頭でパターンを検索するために使用され、大文字と小文字の区別もあります。 これがテキストファイルの処理にどのように影響するかを見てみましょう。
$ awk '/^this/{print $0}' myfile

ファイルのテキストの行頭でパターンを検索する
sedを使用する場合、テンプレート内のどこかにカバーを配置すると、他の普通のキャラクターとして認識されます。
$ echo "This ^ is a test" | sed -n '/s ^/p'

sedのパターンの先頭にないカバー
awkでは、同じテンプレートを使用して、この文字をエスケープする必要があります。
$ echo "This ^ is a test" | awk '/s \^/{print $0}'

awkのテンプレートの先頭にないカバー
行の先頭でテキストの断片の検索を整理しました。 行末で何かを見つける必要がある場合はどうしますか?
ドル記号-
$
は、行末のアンカー記号であり、これに役立ちます。
$ echo "This is a test" | awk '/test$/{print $0}'

行末のテキストを検索する
同じパターンで両方のアンカー文字を使用できます。 次の正規表現を使用して、次の図にその内容が示されている
myfile
ファイルを処理してみましょう。
$ awk '/^this is a test$/{print $0}' myfile

行の始めと終わりに特殊文字を使用するパターン
ご覧のとおり、テンプレートは、指定された一連の文字とその位置に完全に対応する行にのみ反応しました。
アンカー文字を使用して、空の行を除外する方法は次のとおりです。
$ awk '!/^$/{print $0}' myfile
このテンプレートでは、否定記号である感嘆符を使用しました-
!
。 このようなパターンの使用により、行の先頭と末尾の間に何も含まれていない行が検索され、感嘆符のおかげで、このパターンに一致しない行のみが印刷されます。
ドット記号
ドットは、改行文字を除く任意の単一文字の検索に使用されます。 myfileを正規表現に転送します。その内容は次のとおりです。
$ awk '/.st/{print $0}' myfile
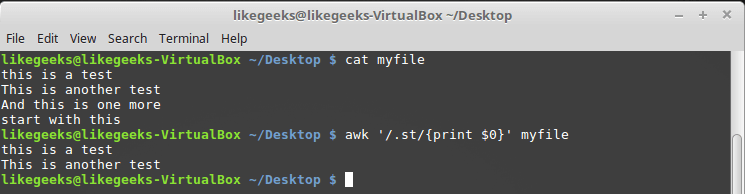
正規表現でピリオドを使用する
出力からわかるように、ファイルの最初の2行のみがパターンに対応します。これは、「st」という文字のシーケンスに別の文字が先行しているためです。行の始まり。
キャラクタークラス
ドットは任意の1文字に一致しますが、探している文字のセットをより柔軟に制限する必要がある場合はどうでしょうか? この状況では、文字クラスを使用できます。
このアプローチのおかげで、特定のセットの任意のキャラクターの検索を整理できます。 文字クラスを記述するために、角括弧が使用されます-
[]
:
$ awk '/[oi]th/{print $0}' myfile
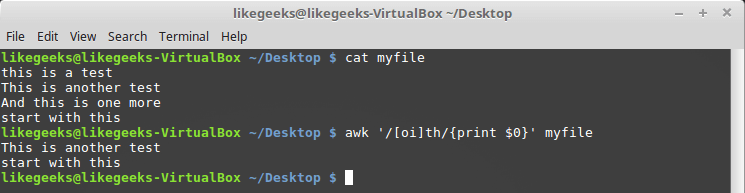
正規表現の文字クラスの説明
ここでは、記号「o」または記号「i」がある文字列「th」を探しています。
大文字または小文字で始まる単語を検索する場合、クラスが役立ちます。
$ echo "this is a test" | awk '/[Tt]his is a test/{print $0}' $ echo "This is a test" | awk '/[Tt]his is a test/{print $0}'

小文字または大文字で始まる単語を検索します
文字クラスは文字に限定されません。 ここでは、他の文字を使用できます。 どの状況クラスが必要になるかを前もって言うことはできません-それはすべて解決される問題に依存します。
文字クラスの拒否
文字クラスを使用して、上記の逆問題を解決することもできます。 つまり、クラス内の文字を検索する代わりに、クラス内にないすべてのものの検索を整理できます。 この正規表現の動作を実現するには、クラス文字のリストの前に
^
記号を配置します。 次のようになります。
$ awk '/[^oi]th/{print $0}' myfile
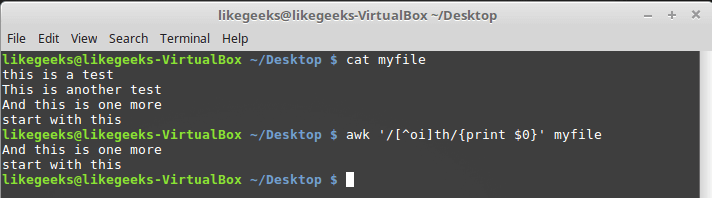
クラス外の文字を検索する
この場合、文字列「th」が見つかりますが、その前には「o」も「i」もありません。
文字範囲
文字クラスでは、ダッシュを使用して文字範囲を記述できます。
$ awk '/[ep]st/{print $0}' myfile
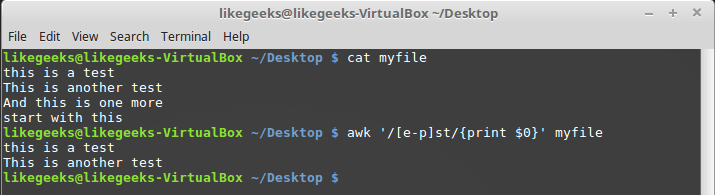
文字クラスの文字範囲の説明
この例では、正規表現は一連の文字「st」に応答します。その前には、文字「e」と「p」の間にアルファベット順に文字が配置されています。
番号から範囲を作成することもできます。
$ echo "123" | awk '/[0-9][0-9][0-9]/' $ echo "12a" | awk '/[0-9][0-9][0-9]/'

3つの数字を検索するための正規表現
文字クラスには、いくつかの範囲を含めることができます。
$ awk '/[a-fm-z]st/{print $0}' myfile
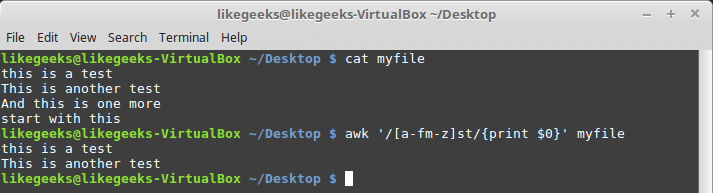
いくつかの範囲で構成される文字クラス
この正規表現は、すべてのシーケンス「st」を検出し、その前に
af
および
mz
範囲の文字があります。
特殊文字クラス
BREには、正規表現を作成するときに使用できる特別な文字クラスがあります。
-
[[:alpha:]]
-大文字または小文字で書かれたアルファベット文字に一致します。 -
[[:alnum:]]
-任意の英数字、つまり範囲0-9
、AZ
、az
文字に一致します。 -
[[:blank:]]
-スペースとタブ文字に一致します。 -
[[:digit:]]
-0
デジタル文字。 -
[[:upper:]]
-大文字のアルファベット文字AZ
-
[[:lower:]]
-アルファベットの小文字az
。
-
[[:print:]]
-印刷可能な文字に一致します。 -
[[:punct:]]
-句読点に一致します。 -
[[:space:]]
-特に空白文字-スペース、タブ文字、NL
、FF
、VT
、CR
文字。
次のようなテンプレートで特別なクラスを使用できます。
$ echo "abc" | awk '/[[:alpha:]]/{print $0}' $ echo "abc" | awk '/[[:digit:]]/{print $0}' $ echo "abc123" | awk '/[[:digit:]]/{print $0}'

特殊な正規表現の文字クラス
アスタリスク記号
パターン内の文字の後にアスタリスクが置かれている場合、文字が文字列に何度も現れると、文字が文字列にない場合も含めて、正規表現が機能することを意味します。
$ echo "test" | awk '/tes*t/{print $0}' $ echo "tessst" | awk '/tes*t/{print $0}'

正規表現で*文字を使用する
このワイルドカード文字は、通常、タイプミスが常に見られる単語、または異なるスペルを許可する単語を処理するために使用されます。
$ echo "I like green color" | awk '/colou*r/{print $0}' $ echo "I like green colour " | awk '/colou*r/{print $0}'

スペルが異なる単語を検索する
この例では、同じ正規表現が単語「color」と単語「color」の両方に応答します。 これは、アスタリスクが後に続く記号「u」が存在しないか、連続して数回出現する可能性があるためです。
アスタリスク記号の機能から生じるもう1つの便利な機能は、アスタリスク記号をドットと組み合わせることです。 この組み合わせにより、正規表現は任意の数の文字に応答できます。
$ awk '/this.*test/{print $0}' myfile

任意の数の任意の文字に応答するテンプレート
この場合、「this」と「test」という単語の間にいくつの文字が含まれていても関係ありません。
アスタリスクは、文字クラスでも使用できます。
$ echo "st" | awk '/s[ae]*t/{print $0}' $ echo "sat" | awk '/s[ae]*t/{print $0}' $ echo "set" | awk '/s[ae]*t/{print $0}'

文字クラスでアスタリスクを使用する
3つすべての例で、正規表現は機能します。これは、文字クラスの後にアスタリスクがあると、「a」または「e」の文字がいくつでも見つかった場合、文字列が特定のパターンに一致するためです。
POSIX ERE正規表現
一部のLinuxユーティリティをサポートするPOSIX EREテンプレートには、追加の文字が含まれる場合があります。 すでに述べたように、awkはこの標準をサポートしていますが、sedはサポートしていません。
ここでは、独自の正規表現を作成するときに役立つEREテンプレートで最も一般的に使用される文字について説明します。
▍疑問符
疑問符は、先行する文字がテキスト内で1回出現する場合と出現しない場合があることを示します。 この文字は、繰り返しメタ文字の1つです。 以下に例を示します。
$ echo "tet" | awk '/tes?t/{print $0}' $ echo "test" | awk '/tes?t/{print $0}' $ echo "tesst" | awk '/tes?t/{print $0}'
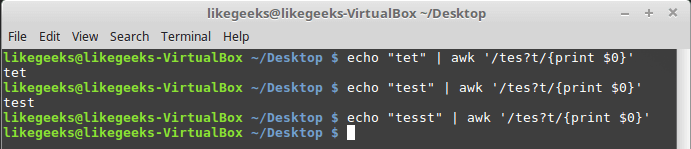
正規表現の疑問符
ご覧のとおり、3番目のケースでは、文字 "s"が2回出現するため、正規表現は単語 "tesst"に応答しません。
疑問符は、文字クラスでも使用できます。
$ echo "tst" | awk '/t[ae]?st/{print $0}' $ echo "test" | awk '/t[ae]?st/{print $0}' $ echo "tast" | awk '/t[ae]?st/{print $0}' $ echo "taest" | awk '/t[ae]?st/{print $0}' $ echo "teest" | awk '/t[ae]?st/{print $0}'
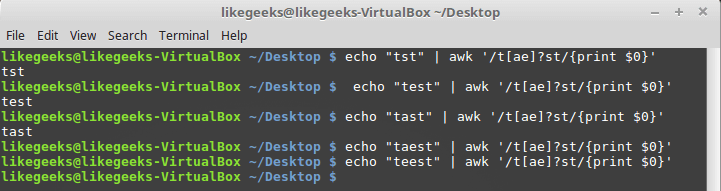
疑問符とキャラクターのクラス
行にクラスの文字がない場合、またはその1つが1回出現する場合、単語に2文字が表示され、システムがテキストのパターンと一致しなくなった場合、正規表現は機能します。
▍プラス記号
パターン内のプラス記号は、前の文字がテキストに1回以上出現する場合、正規表現が探しているものを見つけることを示します。 同時に、そのようなデザインはシンボルの不在に反応しません:
$ echo "test" | awk '/te+st/{print $0}' $ echo "teest" | awk '/te+st/{print $0}' $ echo "tst" | awk '/te+st/{print $0}'
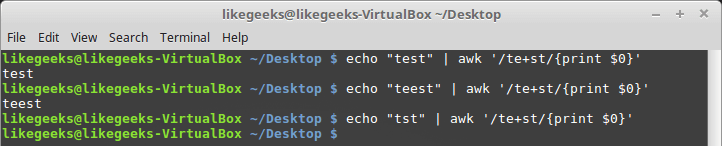
正規表現のプラス記号
この例では、単語に「e」がない場合、正規表現エンジンはテキスト内で一致するものを見つけません。 プラス記号は文字クラスでも機能します。これにより、アスタリスクと疑問符のように見えます。
$ echo "tst" | awk '/t[ae]+st/{print $0}' $ echo "test" | awk '/t[ae]+st/{print $0}' $ echo "teast" | awk '/t[ae]+st/{print $0}' $ echo "teeast" | awk '/t[ae]+st/{print $0}'

プラス記号と文字クラス
この場合、文字列にクラスの文字が含まれている場合、テキストはパターンに一致すると見なされます。
▍図括弧
EREテンプレートで使用できる中括弧は上記の文字に似ていますが、前の文字の必要な出現回数をより正確に指定できます。 次の2つの形式で制限を指定できます。
-
n —
検索するエントリの正確な数を指定する数値です
-
n, m —
次のように解釈される2つの数値:「少なくともn回、ただしm以下」。
最初のオプションの例を次に示します。
$ echo "tst" | awk '/te{1}st/{print $0}' $ echo "test" | awk '/te{1}st/{print $0}'

正確な出現回数を見つける、パターンの中括弧
古いバージョンのawkでは、プログラムが正規表現で間隔を認識するように
--re-interval
コマンドライン
--re-interval
を使用する必要がありましたが、新しいバージョンではこれを行う必要はありませんでした。
$ echo "tst" | awk '/te{1,2}st/{print $0}' $ echo "test" | awk '/te{1,2}st/{print $0}' $ echo "teest" | awk '/te{1,2}st/{print $0}' $ echo "teeest" | awk '/te{1,2}st/{print $0}'
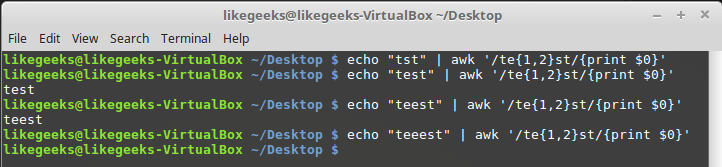
中括弧で指定された間隔
この例では、文字「e」が1行または2行に表示されるはずです。その後、正規表現はテキストに応答します。
中括弧は、文字クラスでも使用できます。 すでにおなじみの原則はここで有効です。
$ echo "tst" | awk '/t[ae]{1,2}st/{print $0}' $ echo "test" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teest" | awk '/t[ae]{1,2}st/{print $0}' $ echo "teeast" | awk '/t[ae]{1,2}st/{print $0}'

中括弧と文字クラス
シンボル「a」またはシンボル「e」が1回または2回含まれている場合、テンプレートはテキストに応答します。
▍記号「または」
シンボル
|
-正規表現の縦線は、論理的な「または」を意味します。 このような記号で区切られたいくつかのフラグメントを含む正規表現を処理すると、エンジンは、フラグメントのいずれかに一致する場合、分析されたテキストが適切であると見なします。 以下に例を示します。
$ echo "This is a test" | awk '/test|exam/{print $0}' $ echo "This is an exam" | awk '/test|exam/{print $0}' $ echo "This is something else" | awk '/test|exam/{print $0}'

正規表現の論理「または」
この例では、テキスト内の単語「test」または「exam」を検索するように正規表現が設定されています。 テンプレートのフラグメントとそれらを分離するシンボルの間
|
スペースを入れないでください。
正規表現フラグメントのグループ化
括弧を使用して、正規表現フラグメントをグループ化できます。 特定の文字列をグループ化すると、システムは通常の文字として認識します。 つまり、たとえば、繰り返しのメタキャラクターを適用することが可能になります。 これは次のようなものです。
$ echo "Like" | awk '/Like(Geeks)?/{print $0}' $ echo "LikeGeeks" | awk '/Like(Geeks)?/{print $0}'

正規表現フラグメントのグループ化
これらの例では、「オタク」という単語が括弧で囲まれています。この構造の後に疑問符があります。 疑問符は「0または1回の繰り返し」を意味することを思い出してください。その結果、正規表現は「Like」行と「LikeGeeks」行の両方に応答します。
実用例
正規表現の基本を説明した後、それらを使って何か役に立つことをします。
filesファイルの数を数える
PATH環境変数に書き込まれるディレクトリにあるファイルをカウントするbashスクリプトを作成します。 これを行うには、まず、ディレクトリへのパスのリストを作成する必要があります。 これをsedで行い、コロンをスペースに置き換えます:
$ echo $PATH | sed 's/:/ /g'
置換コマンドは、テキストを検索するためのパターンとして正規表現をサポートしています。 この場合、すべてが非常に単純であり、コロン記号を探していますが、ここや他のものを使用する人はいません-それはすべて特定のタスクに依存します。
ここで、ループ内のリストを調べて、必要なアクションを実行して、そこにあるファイルの数を計算する必要があります。 スクリプトの一般的なスキームは次のとおりです。
mypath=$(echo $PATH | sed 's/:/ /g') for directory in $mypath do done
次に、
ls
を使用して各ディレクトリ内のファイル数に関する情報を取得し、スクリプトの全文を記述します。
#!/bin/bash mypath=$(echo $PATH | sed 's/:/ /g') count=0 for directory in $mypath do check=$(ls $directory) for item in $check do count=$[ $count + 1 ] done echo "$directory - $count" count=0 done
スクリプトを実行すると、
PATH
一部のディレクトリが存在しないことが判明する場合がありますが、既存のディレクトリ内のファイルをカウントできなくなることはありません。
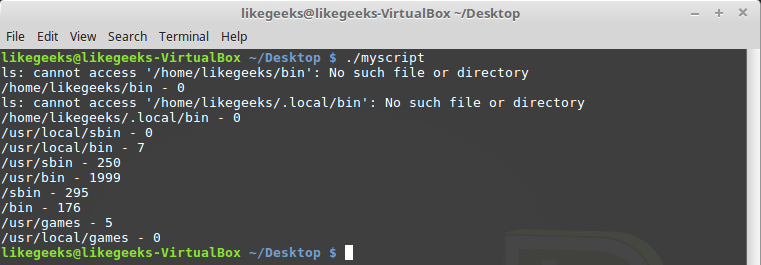
ファイルカウント
この例の主な価値は、同じアプローチを使用して、はるかに複雑な問題を解決できることです。 — .
▍
- , , , . , — , — - . . . , , :
username@hostname.com
,
username
, - . , , , , «». @.
, , . 取得したものは次のとおりです。
^([a-zA-Z0-9_\-\.\+]+)@
: « , , , @».
— —
hostname
. , , :
([a-zA-Z0-9_\-\.]+)
. , (, ), . , :
\.([a-zA-Z]{2,5})$
: « , — 2 5 , ».
, :
^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$
, :
$ echo "name@host.com" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}' $ echo "name@host.com.us" | awk '/^([a-zA-Z0-9_\-\.\+]+)@([a-zA-Z0-9_\-\.]+)\.([a-zA-Z]{2,5})$/{print $0}'

, awk , , .
まとめ
, , , , . — . , — , , , , , .
bash-, . - .
親愛なる読者! ?