Bashスクリプト:開始
Bashスクリプト、パート2:ループ
Bashスクリプト、パート3:オプションとコマンドラインスイッチ
Bashスクリプト、パート4:入力と出力
Bashスクリプト、パート5:シグナル、バックグラウンドタスク、スクリプト管理
Bashスクリプト、パート6:関数とライブラリーの開発
Bashスクリプト、パート7:sedとワープロ
Bashスクリプト、パート8:awkデータ処理言語
Bashスクリプトパート9:正規表現
Bashスクリプト、パート10:ケーススタディ
Bashスクリプト、パート11:対話型ユーティリティの期待と自動化
前回、bashスクリプトの関数、特にコマンドラインからそれらを呼び出す方法について説明しました。 今日のトピックは、文字列データを処理するための非常に便利なツールです。sedと呼ばれるLinuxユーティリティです。 多くの場合、ログファイル、構成ファイル、およびその他のファイルの形式でテキストを操作するために使用されます。

bashスクリプトで何らかの方法でデータを処理する場合、 sedおよびgawkツールを理解するのに害はありません。 ここでは、sedとテキストの操作に焦点を当てます。これは、bashスクリプトを開発する広大な範囲を旅する上で非常に重要なステップだからです。

次に、sedの使用の基本を分析し、このツールの使用例が30以上あります。
Sedの基本
sedユーティリティは、ストリーミングテキストエディターと呼ばれます。 nanoなどのインタラクティブテキストエディターは、キーボードを使用したテキストの操作、ファイルの編集、テキストの追加、削除、変更を行います。 Sedを使用すると、開発者が設定した一連のルールに基づいてデータストリームを編集できます。 このコマンドの呼び出しは次のようになります。
$ sed options file
デフォルトでは、sedは、一連のコマンドとして表される呼び出しで指定されたルールを
STDIN
に適用し
STDIN
。 これにより、データを直接sedに転送できます。
たとえば、次のように:
$ echo "This is a test" | sed 's/test/another test/'
このコマンドを実行すると、次のようになります。

シンプルなsed呼び出しの例
この場合、sedは、処理のために渡された行の単語「test」を単語「another test」に置き換えます。 引用符で囲まれたテキストを処理するためのルールの実行には、スラッシュが使用されます。 この場合、
s/pattern1/pattern2/
という形式
s/pattern1/pattern2/
コマンド
s/pattern1/pattern2/
ます。 「s」という文字は、「substitute」という単語の略語です。つまり、前に置換コマンドがあります。 このコマンドを実行するSedは、転送されたテキストを見て、その中に見つかったフラグメント(以下で説明するもの)を
pattern1
に対応する
pattern2
ます。
上記は、sedを使用する基本的な例であり、速度を上げるために必要です。 実際、sedは、たとえばファイルの操作など、はるかに複雑なテキスト処理スクリプトで使用できます。
以下は、テキストの断片を含むファイルと、そのようなコマンドによる処理の結果です。
$ sed 's/test/another test' ./myfile
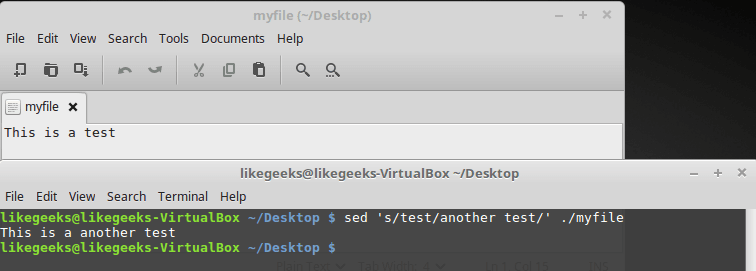
テキストファイルとその処理結果
上記で使用したのと同じアプローチがここで適用されますが、sedはファイルに保存されたテキストを処理します。 同時に、ファイルが十分に大きい場合、sedがバッチでデータを処理し、ファイル全体が処理されるのを待たずに、処理されたものを画面に表示することに気付くでしょう。
Sedは、処理中のファイルのデータを変更しません。 エディターはファイルを読み取り、読み取りを処理し、何が起こったかを
STDOUT
送信し
STDOUT
。 ソースファイルが変更されていないことを確認するには、sedに渡された後、それを開いてください。 必要に応じて、sed出力をファイルにリダイレクトし、おそらく古いファイルを上書きできます。 入力および出力ストリームのリダイレクトについて説明しているこのシリーズの以前の資料のいずれかに精通している場合は、それを行うことができます。
sedが呼び出されたときにコマンドセットを実行する
複数のデータ操作を実行するには、sedを呼び出すときに
-e
スイッチを使用します。 たとえば、2つのテキストの置換を整理する方法は次のとおりです。
$ sed -e 's/This/That/; s/test/another test/' ./myfile

sedで-eスイッチを使用する
ファイルのテキストの各行には、両方のコマンドが適用されます。 これらはセミコロンで区切る必要がありますが、コマンドの末尾とセミコロンの間にはスペースを入れないでください。
sedが呼び出されたときに複数のテキスト処理テンプレートを入力するには、最初の単一引用符を入力した後、Enterを押してから、閉じ引用符を忘れずに新しい行から各ルールを入力します。
$ sed -e ' > s/This/That/ > s/test/another test/' ./myfile
この形式で表示されるコマンドが実行された後、次のようになります。

sedを使用する別の方法
ファイルからコマンドを読み取る
テキストの処理に必要なsedコマンドが多数ある場合は、通常、ファイルに事前に書き込むのが最も便利です。 コマンドを含むsedファイルを指定するには、
-f
使用します。
mycommands
ファイルの内容は次の
mycommands
です。
s/This/That/ s/test/another test/
sedを呼び出し、コマンドを含むファイルと処理用のファイルをエディターに渡します。
$ sed -f mycommands myfile
このようなコマンドを呼び出したときの結果は、前の例で得られた結果に似ています。

sedが呼び出されたときにコマンドでファイルを使用する
交換チームフラグ
次の例をよく見てください。
$ sed 's/test/another test/' myfile
ファイルに含まれるものと、sedによって処理された後に取得されるものを次に示します。

ソースファイルとその処理結果
置換コマンドは通常、複数の行で構成されるファイルを処理しますが、各行で検索されたテキストフラグメントの最初の出現のみが置換されます。 テンプレートのすべての出現を置き換えるには、適切なフラグを使用する必要があります。
フラグを使用するときに置換コマンドを記述するスキームは次のようになります。
s/pattern/replacement/flags
このコマンドの実行は、いくつかの方法で変更できます。
- 番号を転送するとき、文字列へのテンプレートのエントリのシーケンス番号が考慮され、このエントリは置き換えられます。
-
g
フラグは、その行にあるパターンのすべての出現を処理する必要があることを示します。
-
p
フラグは、ソース文字列の内容を表示する必要があることを示します。
-
w file
という形式のフラグは、テキスト処理の結果をw file
に書き込むようコマンドに指示します。
置換コマンドの最初のオプションの使用を検討し、目的のフラグメントの置換されたオカレンスの位置を示します。
$ sed 's/test/another test/2' myfile

置換されたフラグメントの位置で置換コマンドを呼び出す
ここでは、置換フラグとして番号2を示しました。これにより、各行で2番目に出現する目的のテンプレートのみが置換されるという事実に至りました。 次に、グローバル置換フラグ
g
試してください。
$ sed 's/test/another test/g' myfile
出力からわかるように、このようなコマンドは、テキスト内のテンプレートのすべての出現を置き換えました。

グローバル置換
置換コマンド
p
のフラグを使用すると、一致が見つかった行を表示できますが、sedの呼び出し時に指定された
-n
スイッチは通常の出力を抑制します。
$ sed -n 's/test/another test/p' myfile
その結果、この構成でsedを起動すると、指定したテキストの断片が見つかった行(この場合は1行)のみが表示されます。

replace pコマンドフラグの使用
w
フラグを使用して、テキスト処理結果をファイルに保存できます。
$ sed 's/test/another test/w output' myfile

テキスト処理結果をファイルに保存する
コマンドの操作中にデータがSTDOUTに出力され、処理された行が
w
後に名前が指定されたファイルに書き込まれることが明確にわかります。
区切り文字
/bin/bash
を
/etc/passwd
/bin/csh
に置き換える必要があると想像してください。 タスクはそれほど難しくありません:
$ sed 's/\/bin\/bash/\/bin\/csh/' /etc/passwd
ただし、これはすべて非常によく見えません。 問題は、直接スラッシュが区切り文字として使用されるため、sed文字列では同じ文字をエスケープする必要があるということです。 その結果、チームの可読性が低下します。
幸いなことに、sedを使用すると、置換コマンドで使用する独自の区切り文字を設定できます。 区切り文字は、
s
後に出現する最初の文字です。
$ sed 's!/bin/bash!/bin/csh!' /etc/passwd
この場合、感嘆符がセパレーターとして使用されます。その結果、コードは読みやすくなり、以前よりずっときれいに見えます。
処理するテキストフラグメントの選択
これまで、エディターに渡されたデータストリーム全体を処理するためにsedを呼び出しました。 場合によっては、sedを使用して、テキストの特定の部分(特定の特定の行または行のグループ)のみを処理する必要があります。 この目標を達成するには、2つのアプローチを使用できます。
- 処理される行の数に制限を設定します。
- 処理する行に対応するフィルターを指定します。
最初のアプローチを検討してください。 ここでは2つのオプションを使用できます。 最初に、以下で説明するように、処理する必要がある1行の数を示します。
$ sed '2s/test/another test/' myfile
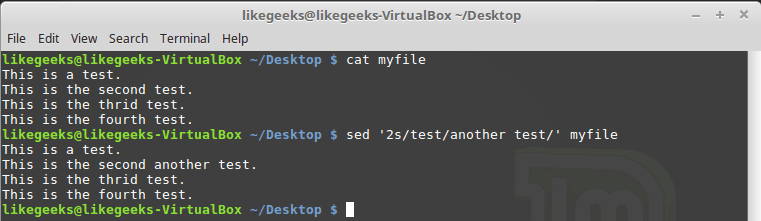
sedの呼び出し時に設定された番号である1行のみを処理する
2番目のオプションは行の範囲です:
$ sed '2,3s/test/another test/' myfile

行範囲処理
さらに、置換コマンドを呼び出して、ファイルが特定の行から最後まで処理されるようにすることができます。
$ sed '2,$s/test/another test/' myfile

2行目から最後までのファイル処理
置換コマンドを使用して、指定されたフィルターに対応する行のみを処理するには、次のようにコマンドを呼び出す必要があります。
$ sed '/likegeeks/s/bash/csh/' /etc/passwd
上記で説明した内容と同様に、テンプレートはコマンド名
s
前に渡されます。

フィルターマッチング文字列の処理
ここでは、非常に単純なフィルターを使用しました。 このアプローチの可能性を完全に明らかにするために、正規表現を使用できます。 これらについては、このシリーズの次の資料のいずれかで説明します。
行を削除
sedユーティリティは、文字列の1つの文字シーケンスを他の文字シーケンスに置き換えるのに適しているだけではありません。 つまり、
d
コマンドを使用して、テキストストリームから行を削除できます。
コマンド呼び出しは次のようになります。
$ sed '3d' myfile
3行目をテキストから削除する必要があります。 これはファイルではないことに注意してください。 ファイルは変更されないままで、削除はsedが形成する出力にのみ影響します。
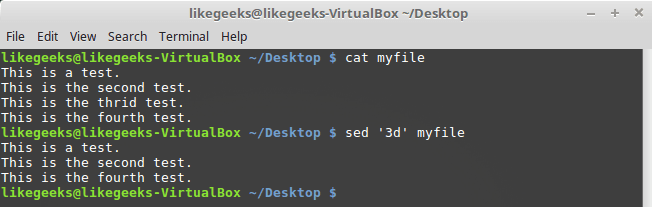
3行目を削除
d
を呼び出すときに削除する行の番号を指定しない場合、ストリーム内のすべての行が削除されます。
d
コマンドを行の範囲に適用する方法は次のとおりです。
$ sed '2,3d' myfile

行の範囲を削除する
そして、指定された行からファイルの最後までの行を削除する方法は次のとおりです。
$ sed '3,$d' myfile

ファイルの最後までの行を削除します
パターンを使用して行を削除することもできます。
$ sed '/test/d' myfile
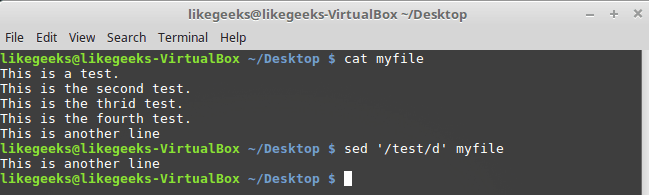
パターンごとに行を削除する
d
呼び出されると、パターンのペアを指定できます。パターンを含む行とその間にある行は削除されます。
$ sed '/second/,/fourth/d' myfile
パターンを使用して一連の行を削除する
ストリームにテキストを挿入する
sedでは、
i
およびコマンドを使用してテキストストリームにデータを挿入できます。
-
i
コマンドは、指定された行の前に新しい行を追加します。
-
a
コマンドは、指定された行の後に新しい行を追加します。
i
コマンドの使用例を考えてみましょう。
$ echo "Another test" | sed 'i\First test '

チームi
次に、
a
コマンドを見てみましょう。
$ echo "Another test" | sed 'a\First test '

チームA
ご覧のとおり、これらのコマンドはストリームのデータの前後にテキストを追加します。 途中に行を追加する必要がある場合はどうしますか?
ここでは、ストリームまたはテンプレート内の参照行の番号を示すことで役立ちます。 範囲として文字列をアドレス指定しても、ここでは機能しないことに注意してください。
i
コマンドを呼び出して、新しい行を挿入する前に行番号を指定します。
$ sed '2i\This is the inserted line.' myfile

参照行番号でコマンド
a
コマンドでも同じことを行います。
$ sed '2a\This is the appended line.' myfile
参照行番号を持つコマンドa
チーム
i
と
a
作業の違いに注意してください。 最初は指定された前に新しい行を挿入し、2番目は指定された行の後に挿入します。
文字列の置換
c
コマンドを使用すると、データストリームのテキスト行全体の内容を変更できます。 呼び出すときは、行番号を指定する必要があります。代わりに、ストリームに新しいデータを追加する必要があります。
$ sed '3c\This is a modified line.' myfile
文字列全体の置換
コマンドを呼び出すときにプレーンテキストまたは正規表現の形式のテンプレートを使用すると、テンプレートに一致するすべての行が置き換えられます。
$ sed '/This is/c This is a changed line of text.' myfile

パターンによる文字列の置換
キャラクター置換
y
コマンドは個々の文字を処理し、呼び出し中に渡されたデータに従ってそれらを置き換えます。
$ sed 'y/123/567/' myfile
キャラクター置換
このコマンドを使用すると、テキストストリーム全体に適用されることを考慮する必要があります。特定の文字の出現に制限することはできません。
出力行番号
=
コマンドを使用してsedが呼び出された場合、ユーティリティはデータストリームの行番号を出力します。
$ sed '=' myfile

出力行番号
ストリームエディターは、コンテンツの前に行番号を印刷しました。
このコマンドにテンプレートを渡し、sed
-n
キーを使用すると、テンプレートに対応する行番号のみが表示されます。
$ sed -n '/test/=' myfile

パターンに一致する行番号を表示する
ファイルから挿入されるデータの読み取り
上記では、データをストリームに挿入する方法を調べ、sedが呼び出されたときに何を挿入するべきかを示しました。 ファイルをデータソースとして使用することもできます。 これを行うには、
r
コマンドを使用します。これにより、指定したファイルのデータをストリームに挿入できます。 呼び出すときに、行番号を指定できます。その後、ファイルまたはテンプレートの内容を挿入する必要があります。
例を考えてみましょう:
$ sed '3r newfile' myfile
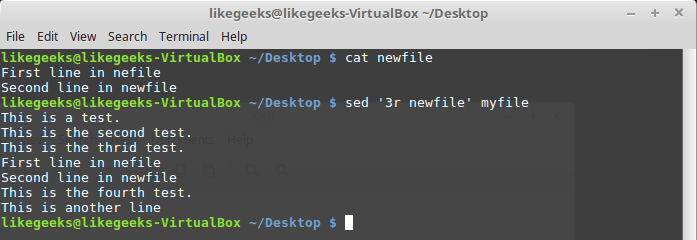
ファイルの内容をストリームに貼り付ける
ここでは、
newfile
ファイルの内容が
myfile
ファイルの3行目の後に挿入されました。
r
コマンドを呼び出すときにテンプレートを使用すると、次のようになります。
$ sed '/test/r newfile' myfile
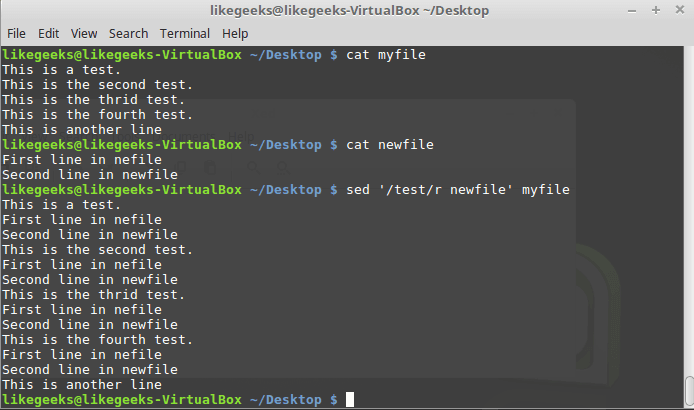
rコマンドを呼び出すときにパターンを使用する
ファイルの内容は、パターンに一致する各行の後に挿入されます。
例
そのようなタスクを想像してください。 ある特定の文字シーケンスがあり、それ自体は無意味なファイルがありますが、これは別のファイルから取得したデータで置き換える必要があります。 すなわち、
DATA
文字のシーケンスが
newfile
役割を果たす
newfile
とします。
DATA
代わりに使用される
DATA
は、
data
ファイルに保存されます。
この問題は、sedストリームエディターの
r
および
d
コマンドを使用して解決できます。
$ Sed '/DATA>/ { r newfile d}' myfile

プレースホルダーを実際のデータに置き換える
ご覧のとおり、
DATA
プレースホルダーの代わりに、sedは
data
ファイルから出力ストリームに2行を追加しました。
まとめ
今日は、sedストリーミングエディターでの作業の基本について説明しました。 実際、sedは大きなトピックです。 その研究は、新しいプログラミング言語の研究と比較できますが、基本を理解すれば、必要なレベルでsedをマスターできます。 その結果、テキストを処理する能力は想像力によってのみ制限されます。
今日は以上です。 次回は、awkデータ処理言語について説明します。
親愛なる読者! 毎日の仕事でsedを使用していますか? もしそうなら、あなたの経験を共有してください。