
まず、少しのコンテキスト。 TPUは、ニューラルネットワークの「出力」(最終結果-約翻訳者を意味する)のプロセスを加速するためにGoogleエンジニアによって開発された特殊なASICであり、その目的は、すでに訓練されたネットワークのこれらのアプリケーションの生産段階を加速することです。 たとえば、ユーザーが音声検索を開始したり、テキストの翻訳を要求したり、画像と一致するものを検索したりするたびに、これは機能します。 ただし、トレーニング段階では、「ディープラーニング」のテクノロジーを使用するすべての企業と同様に、GoogleはGPUを使用します。
トレーニングは通常32ビットまたは16ビットの浮動小数点演算を使用して行われますが、ほとんどの場合8ビット整数演算を使用して「出力」を行うことができるため、区別は重要です。 GoogleがTPU分析で指摘したように、8ビット整数を乗算する場合、16ビット浮動小数点数を乗算する場合よりも6倍少ないエネルギーを使用でき、さらに、13倍少ないエネルギーを使用できます。
ASIC TPUは、64K乗算演算を並行して実行できる8ビットマトリックス乗算器を組み込むことにより、これを活用しています。 最高のパフォーマンスで、1秒あたり92兆回のオペレーションを実現します。 プロセッサには24 MBの内部メモリもあり、このサイズのチップにはかなりの量です。 ただし、メモリ帯域幅はかなり控えめです-34 Gb / s。 エネルギー消費を最適化するため、TPUは700 MHzというかなり控えめな周波数で動作し、40ワットの電力を消費します。 ASICは28ナノメートルプロセステクノロジーを使用して製造され、75ワットのTDPを備えています。
コンピューター機器に関連するすべてのことにおいて、Googleはデータセンターの機器の総所有コスト(TCO)のかなりの部分を占めるため、エネルギー消費に焦点を当てています。 また、大規模なデータセンターでは、機器がタスクに対して強力すぎる場合、エネルギーコストが急速に増大する可能性があります。 GoogleのTPU分析の著者によると、「何千台もの機器を購入する場合、パフォーマンス自体よりもパフォーマンスのコストが重要です。」
TPU設計のもう1つの重要な側面は、応答時間です。 出力はユーザーの要求に応じて実行されるため、システムはできるだけ早く結果を生成する必要があります。 したがって、開発者は高帯域幅よりも低遅延を好んでいます。 GPUの場合、この比率は逆になるため、トレーニング段階で使用されますが、これには多くの計算能力が必要です。
「出力」企業向けの特別なチップを開発する可能性は、約6年前に検索エンジンに「ディープラーニング」の技術を導入し始めたときにGoogleにもたらされました。 これらの製品は何百万人もの人々によって毎日使用されているため、必要なコンピューティング能力は威圧的に見え始めています。 たとえば、ニューラルネットワークを使用した音声検索を1日3分間しか使用しない場合、従来の機器を使用する場合、会社はGoogleデータセンターの数を2倍にする必要があることが判明しました。
TPUは出力専用に設計されているため、IntelプロセッサやNVIDIA GPUよりも優れたパフォーマンスとエネルギー効率を提供します。 TPUの機能を判断するために、Googleは「出力」用に設計された他の2015プロセッサ、つまりIntel Haswell XeonおよびNVIDIA K80 GPUと比較しました。 テストは、最も一般的に使用される3つのタイプのニューラルネットワーク(畳み込み(CNN)、リカレント(RNN)、および多層パーセプトロン(MLP))の6つのベンチマークで行われました。 関連する構成とテスト結果を以下の表に示します。
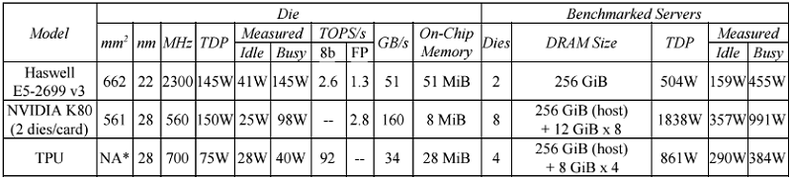
その結果、TPUはK80 GPUおよびHaswellプロセッサよりも15〜30倍高速で実行されることが発見されました。 エネルギー効率はさらに印象的で、TPUは競合他社の30〜80倍も優れていました。 Googleは、TPUでより高い帯域幅を持つGDDR5メモリを使用すると、チップのパフォーマンスを3倍にできると主張しています。
K80 GPUはHPCおよびニューラルネットワークトレーニングに焦点を合わせているが、出力用に最適化されていないことを考えると、このような結果はそれほど驚くことではありません。 Xeonプロセッサーに関しては、どのタイプの「ディープラーニング」アルゴリズムにも最適化されていませんが、同様のシナリオではK80よりもわずかに遅いだけです。
ある程度、これはすべて古いニュースです。 2017年のNVIDIAプロセッサの新しいPascalシリーズは、K80よりも大幅に優れています。 出力に関しては、NVIDIAは現在、TPUと同様に8ビット整数演算をサポートするTesla P4およびP40 GPUを提供しています。 これらのNVIDIAプロセッサは、専用TPUを上回るほど高速ではないかもしれませんが、それらの間のパフォーマンスギャップは大幅に小さくなる可能性があります。
いずれにせよ、TPUは「ディープラーニング」の分野におけるNVIDIAのリーダーシップを脅かすものではありません。 GPUメーカーは依然としてこの分野で優位を占めており、明らかに、P4およびP40の「出力」アクセラレータの多くを大規模なデータセンターに販売する予定です。 「出力」設計の分野におけるNVIDIAのより一般的な脅威はIntelであり、Intelはこの種の作業に向けてアルテラFPGAを位置付けています。 そのため、Microsoftは、アルテラ/ Intelプロセッサを使用して世界最大のAIクラウドを展開することにより、すでにアルテラFPGA供給契約を締結しています。 また、他のAIサービスプロバイダーも同様です。
ほぼ確実に、Googleはすでに第2世代のTPUに取り組んでいます。 このチップには、おそらく帯域幅の高いメモリ(GDDR5など)が搭載されています。 Googleのエンジニアは、クロック速度を上げるためにTPUのロジックと設計を実験する可能性があります。 14ナノメートルなど、より小さな製造プロセスに切り替えると、これらの目標を達成しやすくなります。 もちろん、これらのTPUがすでにリリースされており、Googleクラウドの一部で使用されている可能性は十分にありますが、これを知った場合は、数年後になります。