この投稿は、私自身の英語の記事「Goでゴッチャを避ける方法」のバージョンですが、 ゴッチャという単語はロシア語に翻訳されていません。
Gotchaは、説明どおりに動作するシステム、プログラム、またはプログラミング言語の正しい設計ですが、同時に誤って使いやすいため、直感に反し、エラーを引き起こします。
Go言語にはそのような落とし穴がいくつかあり、それらを詳細に 説明および説明する多くの優れた記事があります 。 私は定期的に同じレーキに落ちる人を見るので、これらの記事は、特にGoの初心者にとって非常に重要だと思います。
しかし、ある質問が長い間私を苦しめました-なぜ私は自分でこれらの間違いを犯したことがないのですか? 真剣に、nilインターフェースとの混乱やappend()による不可解な結果-eスライス-などの最も人気のあるものは、私の練習では決して問題になりませんでした。 どういうわけか、Goでの仕事の最初の日からこれらの落とし穴を回避できたのは幸運でした。 何が私を助けましたか?
そして答えは非常に簡単でした。 Goのデータ構造の内部構造とその他の実装の詳細について、いくつかの優れた記事をすぐに読みました。 そして、これは実際には非常に表面的なものであり、知識は直観を開発し、これらの落とし穴を回避するのに十分でした。
定義に戻りましょう。 「gotcha ...は正しい構造です...これは直感に反します...」です。 これがすべての塩です。 実際、2つのオプションがあります。
- 言語を「修正」する
- 直観を直します
最初のオプションは、多くのhabrachitatelにアピールしますが、もちろんオプションではありません。 Goには後方互換性の約束があります -言語はこれ以上変わらず、これは素晴らしいことです-2012年に書かれたプログラムは、今日、最新バージョンのGoでコンパイルされ、1回も渦巻くことはありません。 ちなみに、囲inには混乱はありません:)
2番目のオプションは、 直感を開発するためにより正確に呼び出されます。 インターフェイスまたはスライスがどのように機能するかを裏から知るとすぐに、直感がより正確にプロンプトを出し、間違いを避けるのに役立ちます。 この方法は私を大いに助けてくれましたし、他の人にもきっと役立つでしょう。 そこで、Goの内部に関するこの基本的な知識を1つの投稿に入れて、Goが内部からどのように構築されるかについての直感を他の人が開発できるようにすることにしました。
データ型がメモリに格納される方法の基本的な理解から始めましょう。 以下に、学習する内容の短いリストを示します。
ポインタ
Goは、家系図にC言語が含まれているため、実際にはかなり鉄に近いものです。 int64
型(64ビットの整数値)の変数を作成する場合、メモリに必要な容量を正確に確認できます。また、 unsafe.Sizeof()を使用して他の型を見つけることができます。
私は、メモリ内のデータの視覚的表現を使用して、変数、配列、またはデータ構造のサイズを「見る」ことが本当に好きです。 視覚的アプローチは、規模をすばやく理解し、直感を開発し、生産性などを視覚的に評価するのに役立ちます。
たとえば、Goの最も単純な基本タイプから始めましょう。
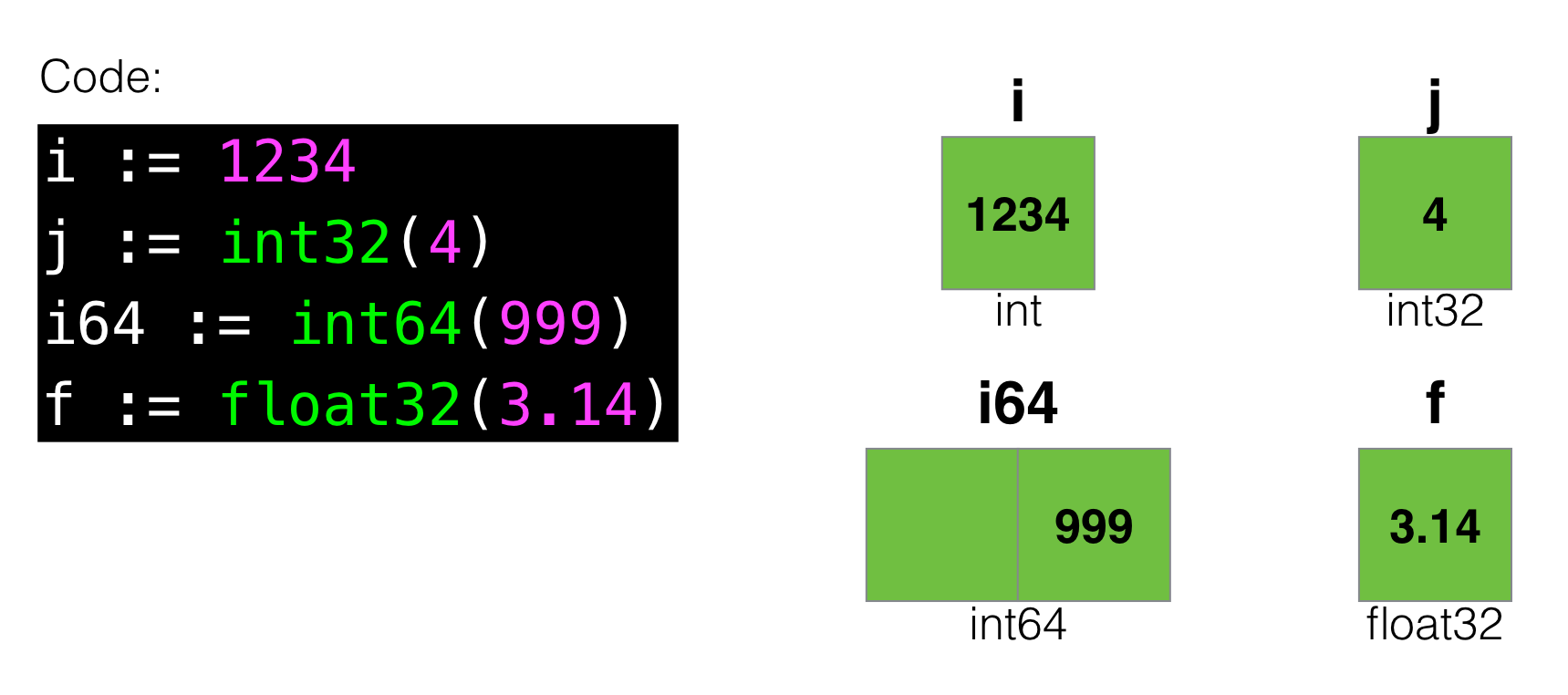
このような視覚化では、 int64型の変数がint32の 2倍の「スペース」を占有し、 intがint32を 占有することは明らかです(32ビットのマシンであると仮定)。
ポインタは少し複雑に見えます-実際、これは、データが配置されている別のメモリブロックを指すメモリ内のアドレスを含む1つのメモリブロックです。 「ポインタの逆参照」というフレーズが聞こえる場合、「ポインタのメモリブロックでアドレスが指しているメモリブロックからデータを検索する」という意味です。 次のように想像できます。

メモリアドレスは通常16進形式で示されるため、図の「0x ...」です。 ただし、ここで重要な点は、「ポインタのメモリブロック」が1つの場所にあり、「アドレスが指すデータ」がまったく異なる場所にあることです。 それはもう少し役に立つでしょう。
そして、ここでGoの落とし穴の1つについて説明します。他の言語のポインターを使用した経験のない人は、関数の「値渡し」パラメーターの理解に混乱が生じます。 ご存知のとおり、すべてがGoに「値で」渡されます。つまり、文字通りコピーされます。 パラメーターがそのまま渡され、ポインターを介して渡される関数について、これを視覚化してみましょう。

最初のケースでは、これらすべてのメモリブロックをコピーします。実際には、2つ以上、少なくとも200万ブロックが簡単に存在し、それらはすべてコピーされます。これは最も高価な操作の1つです。 2番目のケースでは、メモリの1つのブロックのみをコピーします(アドレスはメモリに保存されます)。高速で安価です。 ただし、小さなデータの場合は、値で渡すことをお勧めします。これは、ポインターがGCに追加の負荷を作成し、その結果、より高価になることが判明したためです。
しかし、今、ポインターが関数に渡される方法のこの視覚的表現があれば、最初のケースでは、 Foo()
関数の変数p
を変更すると、コピーを操作し、元の変数( p1
)の値を変更しないことを自然に「見る」ことができます、次に、ポインタが元の変数を参照するため、変更します。 どちらの場合でも、パラメーターが転送されると、データがコピーされます。
さて、ウォームアップは終わりました。深く掘り下げて、もう少し複雑なことを見てみましょう。
配列とスライス
スライスは最初は通常の配列として取得されます。 しかし、これはそうではありません。実際、これらはGoの2つの異なるタイプです。 最初に配列を見てみましょう。
配列
var arr [5]int var arr [5]int{1,2,3,4,5} var arr [...]int{1,2,3,4,5}
配列は単なるメモリブロックのシーケンシャルセットであり、Goのソース( src / runtime / malloc.go )を見ると、配列の作成は基本的に適切なサイズのメモリを割り当てるだけであることがわかります。 古き良きmalloc、少しだけ賢い:
// newarray allocates an array of n elements of type typ. func newarray(typ *_type, n int) unsafe.Pointer { if n < 0 || uintptr(n) > maxSliceCap(typ.size) { panic(plainError("runtime: allocation size out of range")) } return mallocgc(typ.size*uintptr(n), typ, true) }
これは私たちにとって何を意味するのでしょうか? これは、次々に配置されたメモリブロックのセットとして単純に配列を視覚的に表現できることを意味します。

配列の各要素は常にこの型のゼロ値に初期化されます -この場合は0、長さ5の整数の配列です。インデックスでそれらにアクセスし、組み込みのlen()
関数を使用して配列のサイズを見つけます。 インデックスによって配列の単一の要素にアクセスし、次のようなことをする場合:
var arr [5]int arr[4] = 42
次に、5番目(4 + 1)の要素を取得して、メモリ内のこのブロックの値を変更します。

さて、スライスを扱いましょう。
スライス数
一見、配列のように見えます。 まあ、右、彼らは非常に似ています:
var foo []int
しかし、Goのソース( src / runtime / slice.go )を見ると、スライスは実際には3つのフィールドの構造であることがわかります-配列へのポインター、長さ、および容量:
type slice struct { array unsafe.Pointer len int cap int }
新しいスライスを作成すると、「ボンネットの下」ランタイムは、nullポインター( nil
)で長さおよび容量がゼロのこのタイプの新しい変数を作成します。 これは、スライスのゼロ値です。 それを視覚化してみましょう:
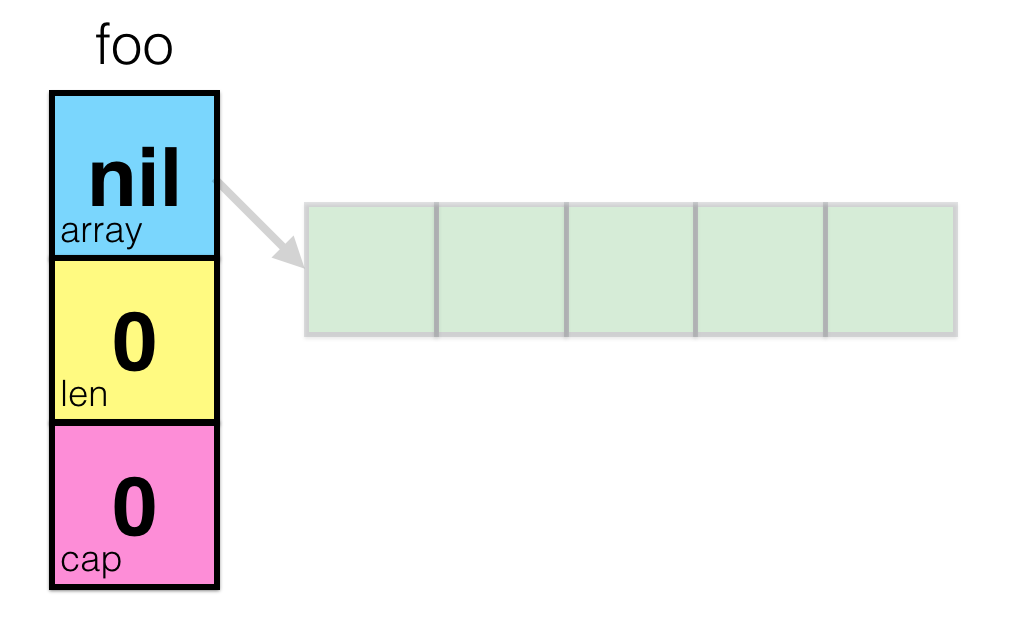
これはあまり面白くないので、組み込みのmake()
コマンドで必要なサイズのスライスを初期化しましょう。
foo = make([]int, 5)
このコマンドは、最初に5つの要素の配列を作成し(メモリを割り当ててゼロで埋めます)、 len
とcap
値を5に設定しますCap
は容量を意味し、スライスが大きくなったときに不要なメモリ割り当て操作を避けるために将来のメモリ領域を予約するのに役立ちます。 少し高度な形式make([]int, len, cap)
を使用して、容量を最初に示すことができます。 スライスを自信を持って使用するには、長さと容量の違いを理解することが重要です。
foo = make([]int, 3, 5)
両方の呼び出しを見てみましょう。

次に、ポインター、配列、スライスの配置方法に関する知識を組み合わせて、次のコードが呼び出されたときに何が起こるかを視覚化しましょう。
foo = make([]int, 5) foo[3] = 42 foo[4] = 100
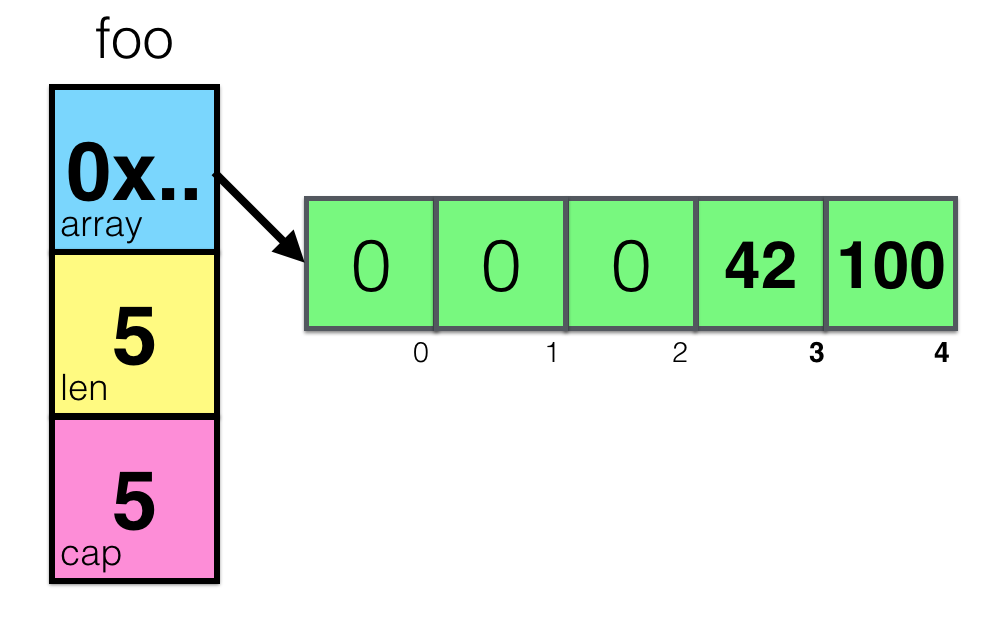
簡単でした。 しかし、 foo
から新しいサブスライスを作成し、要素を変更するとどうなりますか? 見てみましょう:
foo = make([]int, 5) foo[3] = 42 foo[4] = 100 bar := foo[1:4] bar[1] = 99

同じ見た? bar
スライスを変更することで、実際に配列を変更しbar
が、これはfoo
スライスが指す配列と同じです。 そして、これは実際に本物です-このようなコードを書くことができます:
var digitRegexp = regexp.MustCompile("[0-9]+") func FindDigits(filename string) []byte { b, _ := ioutil.ReadFile(filename) return digitRegexp.Find(b) }
そして、たとえば、ファイルから10 MBのデータをスライスに読み込んだ後、数字を含む3バイトを見つけますが、サイズが10 MBの配列を参照するスライスを返します。
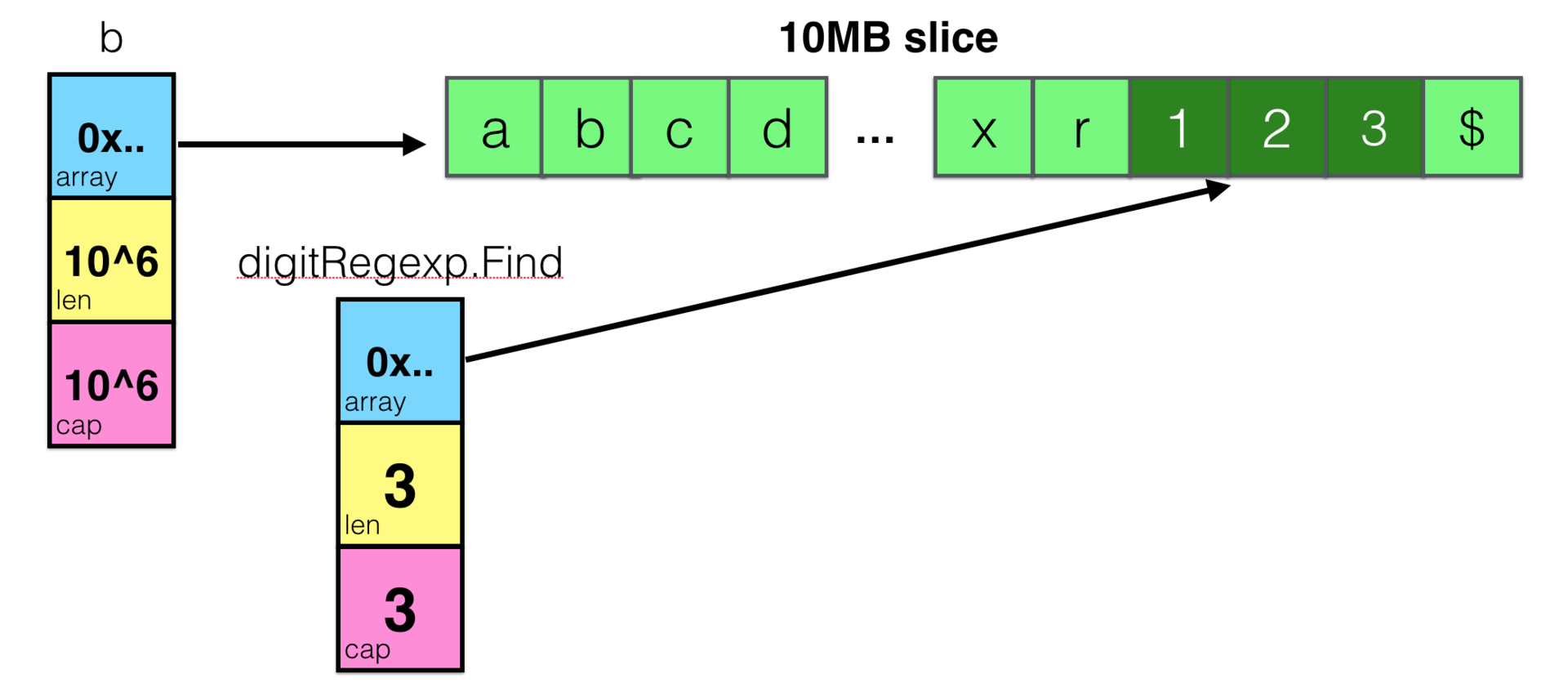
これは、Goで最も頻繁に言及される落とし穴の1つです。 しかし今、これがどのように機能するかを明確に理解すると、あなたがそのような間違いを犯すことは難しいでしょう。
スライスへの追加(追加)
スライスのトリッキーなエラーに続いて、組み込み関数append()
動作はあまり明確ではありません。 彼女は、原則として、1つの簡単な操作を行います-要素を追加します。 しかし、内部ではかなり複雑な操作が行われ、必要な場合にのみメモリを割り当て、効果的に実行します。
次のコードを見てください。
a := make([]int, 32) a = append(a, 1)
彼は32個の整数の新しいスライスを作成し、それに33番目の要素を追加します。
cap
-スライス容量を覚えていますか? 容量は、アレイに割り当てられたスペースの量を意味します。 append()
関数は、スライスに別の要素を追加するのに十分なスペースがあるかどうかを確認し、ない場合は、より多くのメモリを割り当てます。 メモリの割り当ては常に高価な操作であるため、 append()
は最適化を試みappend()
この場合、1つの変数ではなく、別の32x(初期サイズの2倍)のメモリを要求します。 メモリパックの割り当ては、数回に分けて行うよりも1倍安くなります。
ここで明らかなことは、さまざまな理由で、メモリを割り当てることは通常、メモリを別のアドレスに割り当て、古い場所から新しい場所にデータを移動することを意味することです。 これは、スライスによって参照される配列のアドレスも変更されることを意味します! これを視覚化しましょう:
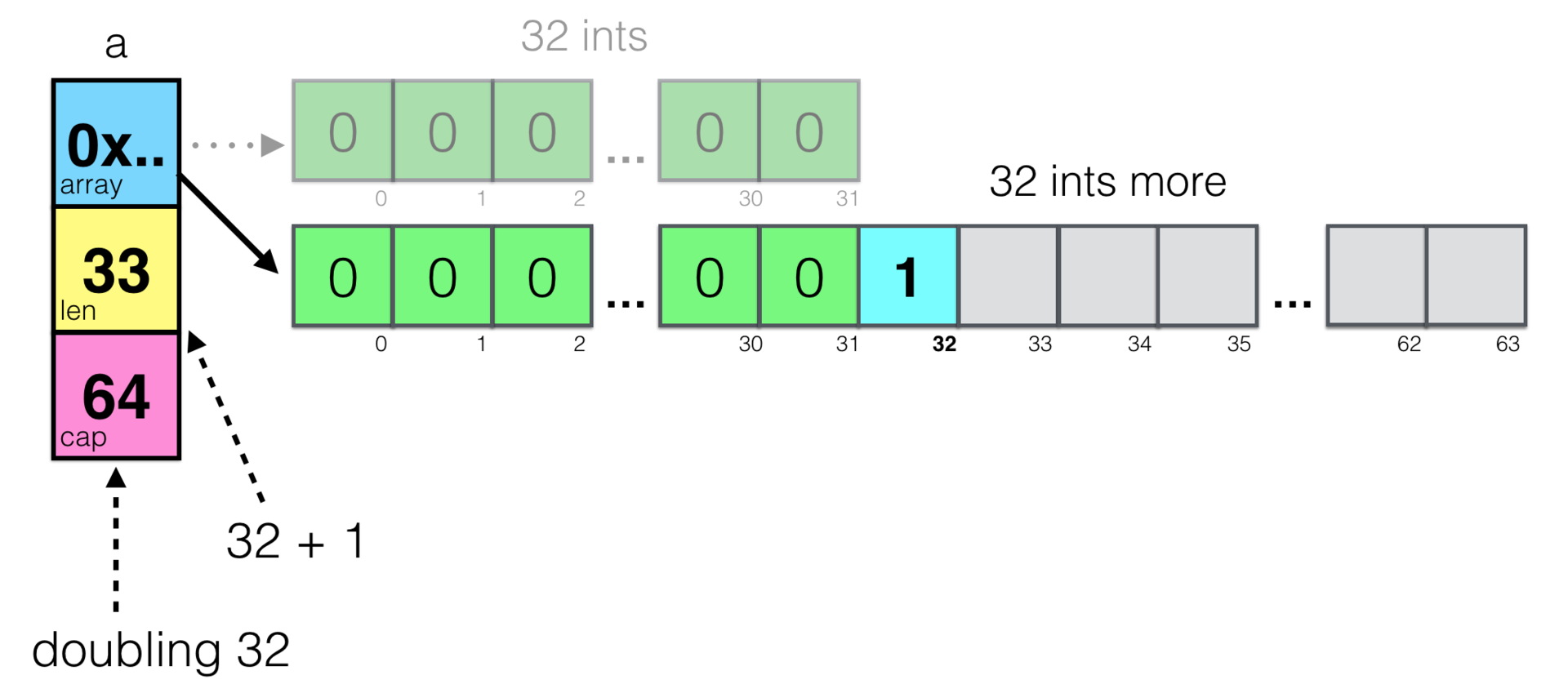
古い配列と新しい配列の2つの配列を簡単に確認できます。 複雑なことは何もないようで、ガベージコレクターは、次のパスで古いアレイが占有していたスペースを単純に解放します。 しかし、これは実際、スライスを使用した落とし穴の1つです。 サブスライスb
を実行し、スライスb
を増やして、同じ配列を使用することを意味する場合はどうなりますか?
a := make([]int, 32) b := a[1:16] a = append(a, 1) a[2] = 42
これを取得します。

そうです、2つの異なる配列を取得し、2つのスライスはメモリの完全に異なるセクションを指します! そして、これは、控えめに言っても、非常に直感に反するものです、同意します。 したがって、原則として、 append()
およびsub-slicesを使用している場合は、注意してこれに留意してください。
ちなみに、 append()
は、スライスを1024バイトに倍増するだけで増やし、別のアプローチ(いわゆる「メモリサイズクラス」)の使用を開始します。これにより、最大12.5%が割り当てられます。 32バイトの配列に64バイトを割り当てるのは問題ありませんが、スライスのサイズが4GBの場合、要素を1つだけ追加したい場合でも、別の4GBを割り当てるのはコストがかかりすぎます。
インターフェース
さて、インターフェイスはおそらくGoについて最もわかりにくいものです。 通常、理解が頭に収まるまで、特に他の言語のクラスでの長時間の作業の悲惨な結果の後は、ある程度時間がかかります。 最も一般的な問題の1つは、 nil
インターフェイスを理解することです。
いつものように、元のGoコードに戻りましょう。 インターフェースとは何ですか? これは一般的な2フィールド構造であり、その定義( src / runtime / runtime2.go )は次のとおりです。
type iface struct { tab *itab data unsafe.Pointer }
itab
はインターフェイステーブルを意味し、インターフェイスとベースタイプに関する追加情報が格納される構造体でもあります。
type itab struct { inter *interfacetype _type *_type link *itab bad int32 unused int32 fun [1]uintptr // variable sized }
インターフェースでの型強制の仕組みについては詳しく説明しませんが、本質的にインターフェースは型に関するデータのセット(インターフェースとその中の変数の型)と、実際には静的な変数自体へのポインターであることを理解することが重要です(コンクリート)タイプ( iface
data
フィールド)。 それがどのように見えるかを見て、 error
インターフェイスタイプのerr
変数を定義してみましょう。
var err error
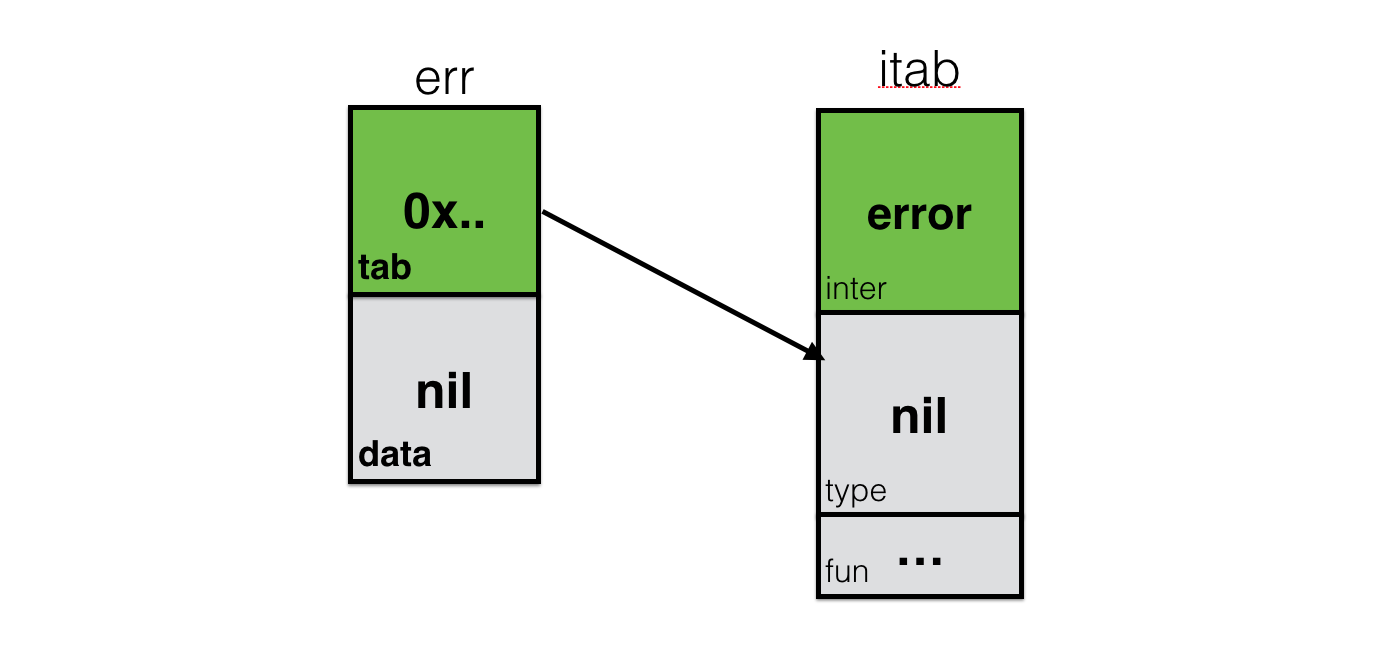
この視覚化で確認できるのは、nilインターフェイスです。 error
を返す関数でnil
を返すと、まさにこのオブジェクトを返します。 インターフェース自体に関する情報( itab.inter
)をitab.type
が、 data
とitab.type
空ですitab.type
と等しいです。 このオブジェクトをnil
と比較するとif err == nil {}
に条件でtrue
を返しtrue
。
func foo() error { var err error // nil return err } err := foo() if err == nil {...} // true
さて、Goの有名な落とし穴でもあるこのケースを見てみましょう。
func foo() error { var err *os.PathError // nil return err } err := foo() if err == nil {...} // false
インターフェイスが何であるかわからない場合、これらの2つのコードは非常に似ています。 しかし、 *os.PathError
型変数が「ラップ」されているerror
インターフェイスがどのように見えるかを見てみましょう。

ここでは、変数自体*os.PathError
タイプを明確に確認できます。これは、 nil
書き込まれるメモリの一部です。これは、これが任意のポインターのゼロ値であるためです。 しかし、関数foo()
から返されるオブジェクトは、より複雑な構造であり、インターフェイスに関する情報だけでなく、変数の型に関する情報と、 nil
ポインターが存在するブロックのメモリ内のアドレスも格納します。 違いを感じますか?
どちらの場合もnil
が表示されるようですが、 「値がnilである内部変数を 持つインターフェイス 」と「内部変数のないインターフェイス 」の間には大きな違いがあります 。 この違いを理解したら、次の2つの例を混同してみてください。

これで、コード内でこのような問題に遭遇するのは難しいはずです。
空のインターフェイス
いわゆる空のインターフェース- interface{}
に関するいくつかの言葉。 Goソースでは、 eface
( src / runtime / malloc.go )という別の構造体によって実装されます 。
type eface struct { _type *_type data unsafe.Pointer }
この構造がiface
に似ていることは簡単にわかりますが、インターフェイステーブル(itab)はありません。 定義上、静的型は空のインターフェイスを満たすため、これは論理的です。 したがって、 interface{}
で変数を明示的にまたは暗黙的に(引数として渡すか、関数から戻るなど)何らかの「ラップ」すると、実際にこの構造を操作します。
func foo() interface{} { foo := int64(42) return foo }
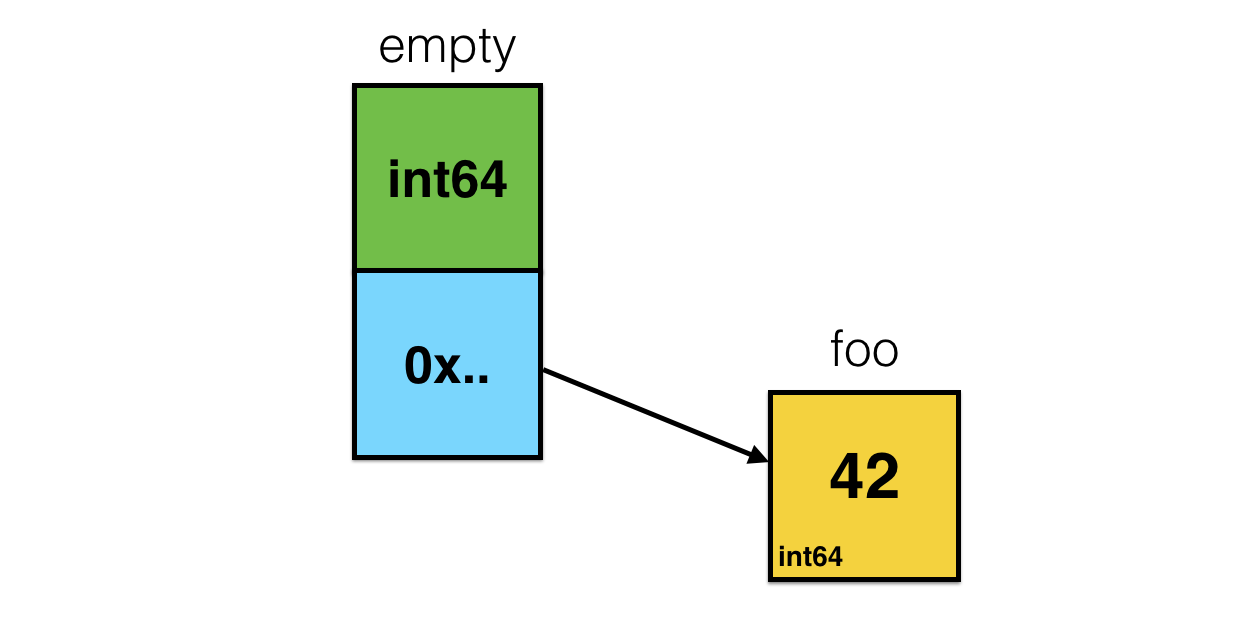
空のインターフェイスに関するよく知られている問題の1つは、特定のタイプのスライスを一気にインターフェイスのスライスに持ち込むことができないことです。 このようなものを書く場合:
func foo() []interface{} { return []int{1,2,3} }
コンパイラは非常に明確に誓います:
$ go build cannot use []int literal (type []int) as type []interface {} in return argument
これは最初は混乱します。 何が問題なのか-任意のタイプの変数を空のインターフェイスに持ち込めるのに、スライスで同じことができないのはなぜですか? ただし、空のインターフェイスとスライスの配置方法を知っている場合、この「スライスのキャスト」は実際にはかなり高価な操作であり、スライスの全長を渡してメモリを比例配分することを直感的に理解する必要がありますアイテムの数。 また、Goの原則の1つは- 何か高価なことをしたい場合-明示的に行うことなので、そのような変換はプログラマーに委ねられます。
[]interface{}
への[]int
キャストが何であるかを視覚化してみましょう。
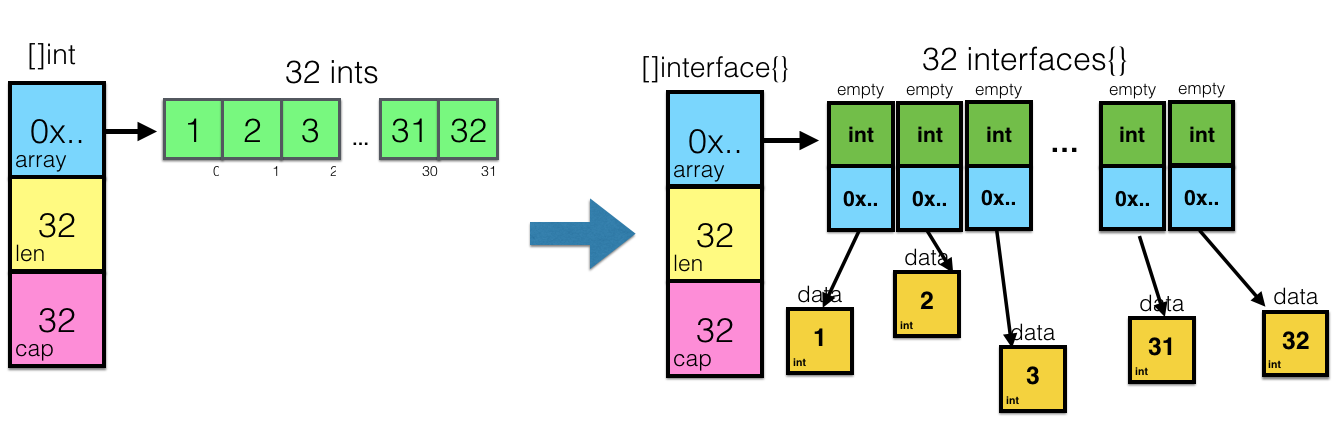
この瞬間があなたにとって意味があることを願っています。
おわりに
もちろん、実装の内部を掘り下げて、言語の落とし穴や誤解をすべて解決できるわけではありません。 それらのいくつかは、単に古い経験と新しい経験の違いであり、私たち全員にとっては異なります。 それにもかかわらず、最も人気のあるこのアプローチは回避に役立ちます。 この投稿が、プログラムで何が起こっているのか、Goが内部でどのように配置されているのかをより深く理解するのに役立つことを願っています。 Goはあなたの友人であり、それをもう少し良く知ることは常に有益です。
Goの内部についての詳細を読むことに興味がある場合は、ここで私が役立った記事の短い選択を以下に示します。
まあ、もちろん、これらのリソースなしではどうでしょうか:)
良いコーディング!