多くの分散ストレージシステム(Cassandra、Riak、HDFS、MongoDB、Kafkaなど)は、レプリケーションを使用してデータを保存します。 通常、これらは「 単なるディスクの束、JBOD」構成で展開されます。このように、障害を処理するためのRAIDはありません。 ノード内のディスクの1つが故障すると、このディスクのデータは単に失われます。 永続的なデータ損失を防ぐため、DBMSはデータのコピー(レプリカ)を別のノードのディスクのどこかに保存します。
最も一般的な複製係数は3です。これは、データベースが3つの異なるコンピューターに接続された異なるディスクに各データの3つのコピーを保存することを意味します。 これについての説明は、およそ次のとおりです。ドライブはほとんど故障しません。 ディスクに障害が発生した場合は、ディスクを交換する時間があります。この時点で、さらに2つのコピーがあり、そこからデータを新しいディスクに復元できます。 最初のディスクを復元するときに2番目のディスクが故障するリスクは十分に低く、3つのディスクすべてが同時に死ぬ確率は非常に小さいため、小惑星で死ぬ可能性が高くなります。
ナプキンを見てみましょう:特定の期間における1つのディスクの障害の確率が0.1%(任意の数を選択する)である場合、2つのディスクの障害の確率は(0.001) 2 = 10 -6であり、3つのディスクの障害の確率は(0.001 ) 3 = 10 -9 、または10億分の1。 これらの計算は、ディスク障害が互いに独立して発生することを示唆しています。これは、実際には常に真実とは限りません。 しかし、おおよその計算では行います。
これまでのところ、常識が勝利しています。 理にかなっているように見えますが、残念ながら多くのストレージシステムではこれは機能しません。 記事では、その理由を示します。
データを紛失しやすい、la la laaa
データベースクラスターが実際に3台のマシンのみで構成されている場合、3台すべての同時障害の確率は非常に小さいです(データセンターでの火災などの相関障害を除く)。 ただし、より大きなクラスターに切り替えると、確率が変わります。 クラスタ内のノードとディスクが多いほど、データ損失の可能性が高くなります。
これは直感に反する考えです。 「もちろん、データの各部分はまだ3つのディスクに複製されています。」 ディスク障害の可能性は、クラスターのサイズに依存しません。 では、なぜクラスターサイズが重要なのでしょうか?」しかし、確率を計算し、次のようなグラフを描きました。
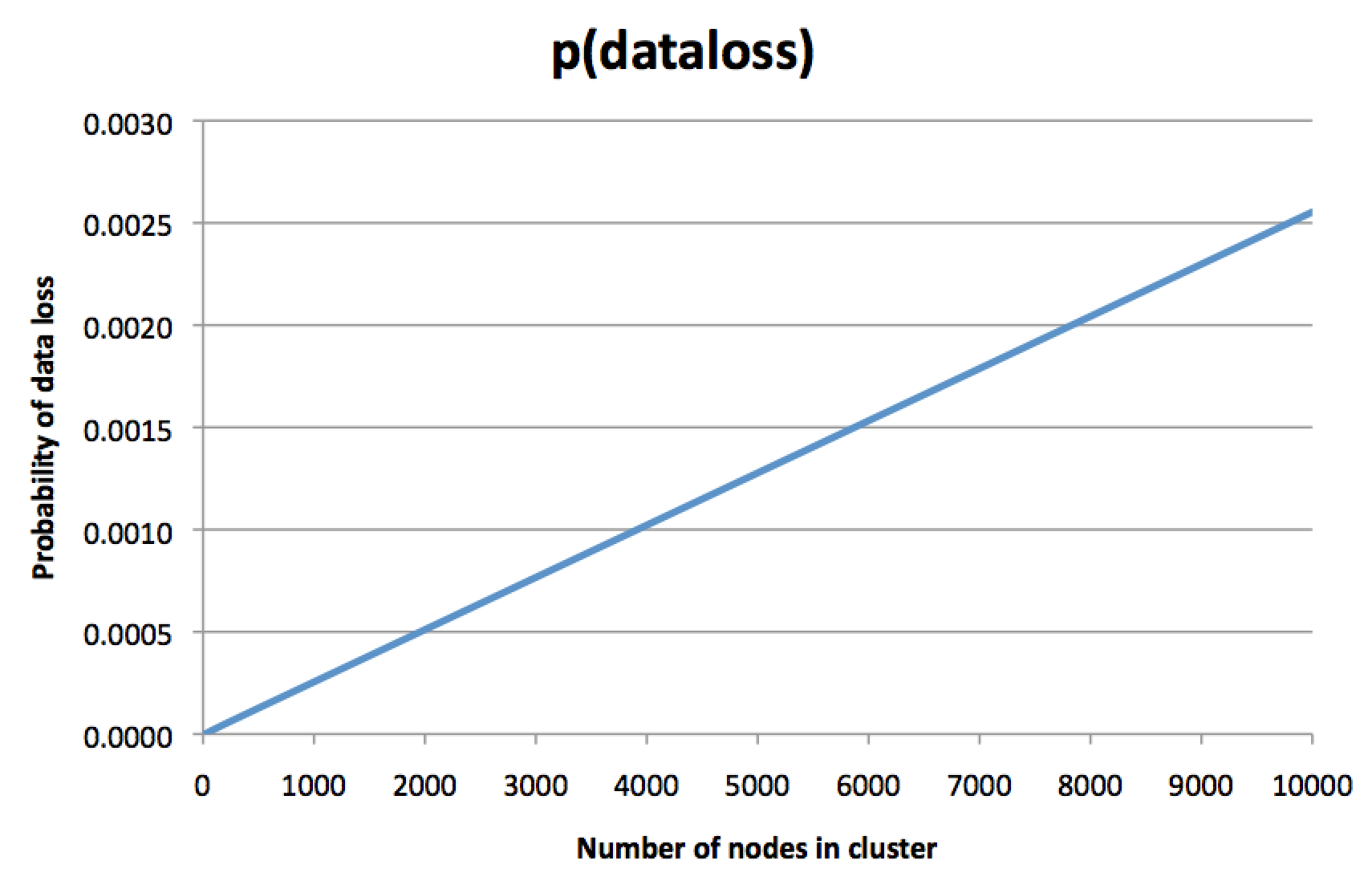
明確にするために、これは1つのノードの障害の確率ではなく、データの3つのレプリカの不可逆的な損失の確率であるため、バックアップコピー(ある場合)からの復元がデータを復元する唯一の方法のままです。 クラスターが大きいほど、データ損失の可能性が高くなります。 レプリケーションファクター3の支払いを決定したとき、おそらくこれを期待していなかったでしょう。
このグラフでは、y軸はわずかに任意であり、多くの仮定に依存していますが、グラフの方向は怖いです。 ノードに一定の期間、0.1%の障害の可能性があると仮定すると、グラフは、8000ノードのクラスターで、特定のデータフラグメント(同じ期間)の3つのレプリカすべての不可逆的な損失の可能性が約あることを示します0.2%。 はい、正しく読みます。データの3つのコピーすべてを失うリスクは、1つのノードを失うリスクのほぼ2倍です。 複製のポイントは何ですか?
直観的に、このグラフは次のように解釈できます:8000ノードのクラスターでは、ほぼ確実に複数のノードがいつでも死んでいます。 これは正常であり、問題ではありません。一定レベルの障害とノードの交換は、定期的なメンテナンスの一環として想定されていました。 しかし、運が悪い場合は、3つのレプリカすべてが現在停止しているノードに含まれるデータがあります。これが発生すると、データは永久に失われます。 失われたデータは、クラスター内のデータセット全体のごく一部にすぎませんが、レプリケーションファクター3を使用する場合、通常「データをまったく失いたくない」と考え、「少量のデータが定期的に失われることは気にしない」それらはほとんどありません。」 失われたデータのこの特定の部分は、本当に重要な情報かもしれません。
3つのレプリカすべてがデッドノードである可能性は、システムがレプリカ間でデータを分散するために使用するアルゴリズムに基本的に依存しています。 上部のグラフは、データがセクション(シャード)に分割され、各セクションが3つのランダムに選択されたノード(またはハッシュ関数を使用した擬似ランダム )に格納されるという仮定で計算されます。 これは、CassandraやRiakなどが使用しているシーケンシャルハッシュの場合です(私の知る限り)。 他のシステムでレプリカの割り当てがどのように機能するのかわかりませんので、さまざまなストレージシステムの機能を知っている人のヒントに感謝します。
データ損失の確率の計算
複製されたデータベースの確率モデルを使用して、上のグラフをどのように計算したかを示します。
単一のノードが失われる確率が 。 このモデルでは時間を無視し、特定の任意の期間における失敗の可能性を調べます。 たとえば、 -これは、特定の日のノード障害の確率です。ノードを交換し、失われたデータを新しいディスクに復元するために約1日が必要な場合に意味があります。 簡単にするために、ノードの障害とディスク障害を区別しませんが、不可逆的な障害のみを考慮します(再起動後にノードがサービスに戻るときの障害は無視します)。
させる クラスタ内のノードの数になります。 次に、確率 から ノードに障害が発生し(障害が互いに独立していると仮定)、 二項分布に対応します。
会員 確率は ノード障害、メンバー -残りの確率 稼働し続け、 さまざまな選択肢の数です から ノード の組み合わせの数として解釈される によって 。 この二項係数は次のように計算されます。
させる レプリケーションの要因になります(通常は ) と仮定して から ノードが故障した、特定のセクションにすべてがある確率 障害が発生したノードのレプリカ?
まあ、シーケンシャルハッシュシステムでは、各セクションは独立したランダムな(または擬似ランダムな)方法でノードに割り当てられます。 このセクションにあります さまざまな予約方法 ノードへのレプリカ、およびこれらすべての割り当ては同じ確率で発生する可能性があります。 また、 さまざまな選択方法 のレプリカ 故障したノード-これらはすべての方法です 障害のあるノードにレプリカを割り当てることができます。 次に、すべてのレプリカの失敗につながる割り当ての部分を計算します。
(「パーティションが失われた」後の垂直バーは「提供された」を意味し、 条件付き確率を示します 。確率は、 ノードが失敗しました)。
そのため、特定のセクションのすべてのレプリカが失われる可能性があります。 クラスターはどうですか セクション? 1つ以上のパーティションが失われると、データが失われます。 したがって、データを失わないためには、すべての セクションは失われませんでした:
CassandraとRiakはセクションをvnodeと呼びますが、これは同じです。 一般的に、セクションの数 ノードの数に依存しない 。 Cassandraの場合、通常、ノードには一定数のパーティションがあります 。 デフォルトで (
num_tokens
パラメーターで設定)、これは、上部のグラフに対して行った別の仮定です。 Riakでは、 クラスターの作成時にパーティションの数は固定されますが 、通常はノードが多いほどパーティションが多くなります。
1か所ですべてを収集したら、サイズのクラスターで1つ以上のパーティションが失われる確率を計算できるようになりました 複製係数あり 。 失敗の数 複製係数よりも少ない場合、データが失われないことを確認できます。 したがって、失敗数のすべての可能な値の確率を追加する必要があります と :
これは少し過剰ですが、私には正確な評価のようです。 そして、あなたが代わりに 、 そして 値を確認します 3から10,000までで、それから一番上のチャートを取得します。 この計算用に小さなRubyプログラムを作成しました。
ユニオン境界を使用して 、より簡単な近似を取得できます。
あるパーティションの障害が別のパーティションの障害と独立していない場合でも、そのような近似は依然として適用可能です。 そして、それは正確な結果と非常によく一致しているようです:グラフでは、データ損失の確率はノードの数に比例して直線のように見えます。
近似では、この確率はセクションの数に比例し、ノードごとに固定された256セクションの数に基づいて同じになると言われています。
さらに、近似で10000ノードの数を代入すると、次のようになります。 これは、Rubyプログラムの結果とほぼ一致しています。
しかし、実際には...?
これは実際には問題ですか? 知りません 基本的に、これは興味深い直観に反する現象だと思います。 これにより、大規模なデータベースクラスターを備えた企業で実際のデータ損失が発生したという噂を聞きましたが、どこかで文書化された問題は見ませんでした。 このテーマに関する議論を知っているなら、見せてください。
計算によると、データ損失の可能性を減らすには、パーティションの数を減らすか、レプリケーション係数を増やす必要があります。 より多くのレプリカを使用するとコストがかかるため、これはすでに高価な大規模クラスターにとって理想的なソリューションではありません。 ただし、パーティションの数を変更することは興味深い妥協案です。 Cassandraは最初はノードごとに1つのパーティションを使用していましたが、数年前にノードごとに256パーティションに切り替えて、より優れた負荷分散とより効率的なバランス回復を実現しました。 計算からわかるように、裏側は、少なくとも1つのセクションが失われる可能性がはるかに高くなります。
クラスターサイズに応じてデータ損失の可能性が大きくならない、または少なくともそれほど大きくはならないが、同時に適切な負荷分散とバランス復元の特性が保持されるレプリカを割り当てるためのアルゴリズムを開発することは可能だと思います。 これは今後の研究にとって興味深い分野です。 これに関連して、同僚のステファンは、レプリカ割り当てアルゴリズムに関係なく、特定のサイズのクラスターで予想されるデータ損失率が変わらないことに気付きました-つまり、少量のデータを失う可能性が高いか、大量のデータを失う可能性が低いかを選択できます! 2番目のオプションの方が良いと思いますか?
この効果が実際に現れる前に本当に大きなクラスターが必要ですが、数千のノードのクラスターが異なる大企業で使用されているため、このような規模の経験を持つ人々を聞くのは興味深いでしょう。 10,000ノードのクラスターでの不可逆的なデータ損失の可能性が実際に1日あたり0.25%である場合、これは1年あたり60%のデータ損失の可能性を意味します。 これは、冒頭で述べた小惑星で死ぬ「10億分の1」の可能性よりもはるかに大きいものです。
分散データシステムの設計者は問題を認識していますか? 正しく理解できれば、複製スキームを設計する際に考慮すべきことがいくつかあります。 おそらく、この投稿では、3つのレプリカを作成しただけでは安全に感じられないという事実に注目するでしょう。