6か月も経たないうちに、Stepikで適応学習に関する一連の記事を完成させています! いいえ、合格しました...しかし、適応トレーニングが必要な理由、Stepikでの実装方法、チェスとの関係についての最終記事を最後にご紹介できることをうれしく思います。

はじめに
Stepik.orgの適応型推奨システムがどのように配置されているかをHabréで伝えることに決めました。 このシリーズの最初の2つの記事は、夏にサンクトペテルブルク州立大学の入学で学士号を取得するために書かれました。最初の記事は一般的にオンライン教育の推薦システムに関するもので、 2番目の記事は内部で少し見て、推薦システムのアーキテクチャについて話しました。 プラットフォームのこの部分が非常に急速に変化しているため、3番目の部分は最終的に実際の適応型の推奨事項に到達しましたが、あまり記述されていませんでした。 しかし、これで公開する準備が整いました。
なぜ適応性があるのですか?
オンライン学習の利点について話すとき、それらは大衆の間でしばしば言及されます。 実際、大学でのフルタイムコースのスループットと、ストリーミングコースであっても、実際にはスケーリングの制限がない大規模なオンラインコースのスループットを比較することは困難です。聴衆の大きさの違いは桁違いです。
しかし、この機能はオンライン教育の欠点でもあります。教室での授業の場合、教師は生徒に合わせて講義を調整できます:学期の初めに調査を実施し、教室でフォローし、全員が資料を理解し、個々の生徒と個人的にコミュニケーションをとることもできます彼らは学んでいないか、逆に、いくつかのトピックをより深く掘り下げたいと思っています。 もちろん、大規模なオンラインコースの場合、そのような対話のための教師のリソースは十分ではなく、生徒は複雑なタスクをより詳細に分析したり、単純なタスクをスキップしたりすることなく、直線的に構成されたコースの厳格なフレームワークに身を置いています。
ただし、自動(質量)モードで同様のものを実装する方法があります。 これらの方法は、3つの主要なグループに分類できます。
- 差別化されたトレーニング。 生徒の知識レベルに合わせて資料を調整する最も簡単な方法:教師は事前にさまざまな複雑さのいくつかの固定トレーニングパスを作成し、生徒は自分に最も適したものを選択し、通常の線形モードで学習します。 たとえば、さまざまなレベルの言語習熟度向けの一連の教科書。

- 個別トレーニング。 この場合、中間テストでの生徒の結果に応じて、学習プロセスで軌道が構築されます。 テストのタイミングと、異なる結果でさらに学習することをアドバイスするルールに関するルールは、教師によって事前に設定されています。 決定ツリーに似たものが判明します。これによれば、生徒は成功に応じて異なる方法で進みますが、ツリー自体は教師が考えて作成する必要があります。
- 適応学習。 アルゴリズムの観点から最も興味深いグループ。 軌跡も学習プロセスで構築されますが、教師からの最初の採点は必要ありませんが、生徒が教材をどのように勉強し、この教材が彼の前にどのように勉強されたかについての最大限の情報を使用します。 さらに記事でこれについて詳しく説明します。
適応学習メカニズム
Stepikのアダプティブトレーニングは、以前のアクションに応じて、次に学ぶべきレッスンをユーザーにアドバイスする推奨システムの形式で行われます。 これまでのところ、推奨事項は選択したコースの材料の一部( Pythonシミュレーターなど )として提供されていますが、近い将来、任意のトピックの一部(C ++や積分など)として推奨事項も利用できるようになります。 将来的には、任意のトピックを適応モードで学習できます。
登録ユーザーの場合、適応モードで学習を開始するには、適応コースで「学習」ボタンをクリックするだけです(コースに登録すると利用可能になります)。
トレーニング用に推奨された資料を受け取ったら(レッスン)、ユーザーは次の3つの方法のいずれかで応答できます。
- レッスンを受ける(問題を解決する)、
- レッスンを単純すぎるとマークする
- レッスンを複雑すぎるとマークします。
反応を受け取った後、ユーザーの知識とレッスンの複雑さに関する情報が更新され、ユーザーは新しい推奨事項を受け取ります。
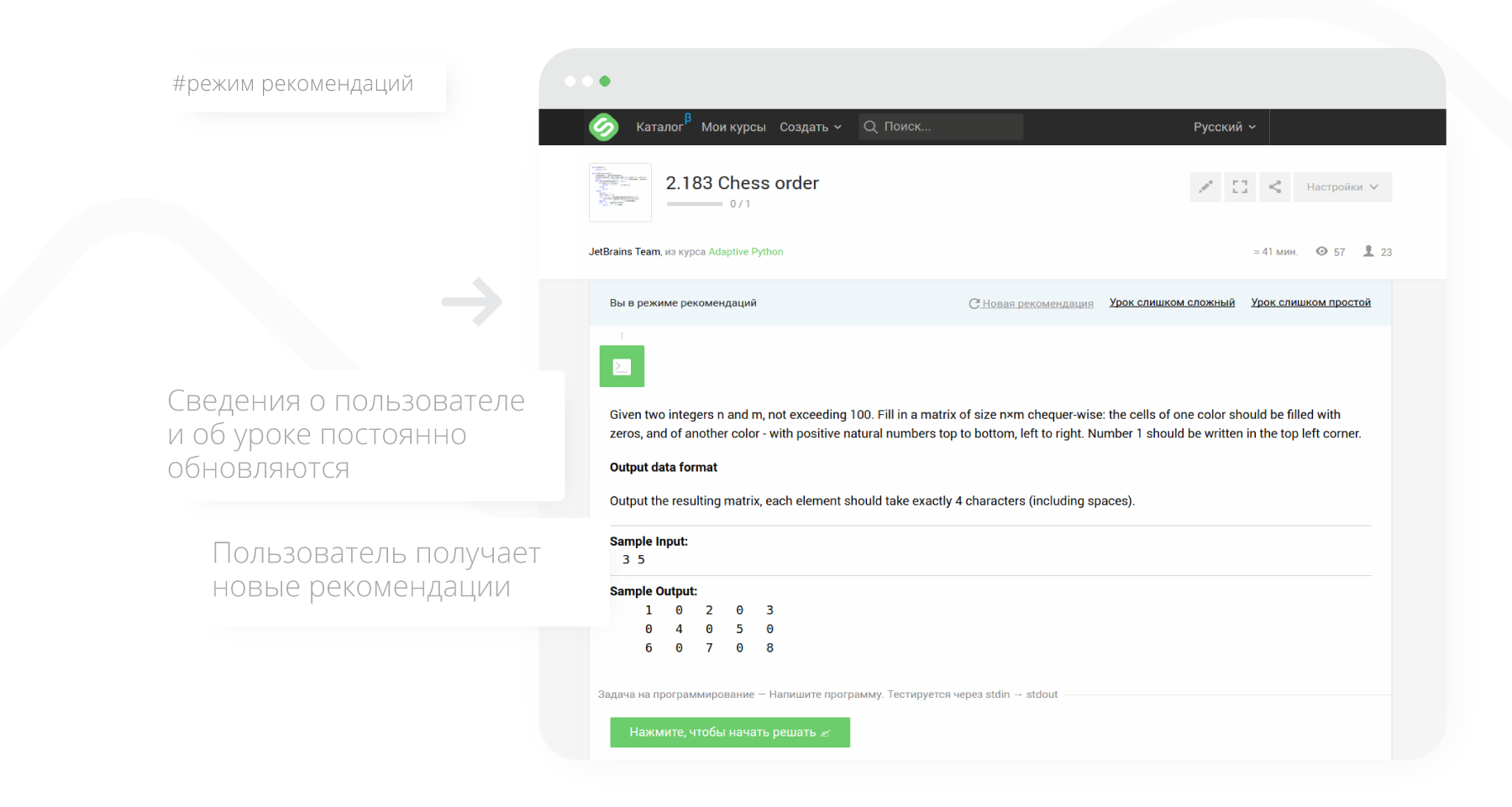
適応型の推奨事項には、2つの方法(「ハンドラー」)が使用されます。複雑さに基づくトピック間の依存関係(ハンドラーの詳細については、シリーズの2番目の記事を参照してください )。
複雑さに基づく推奨事項の下には、2つのアイデアがあります。
- アイテム応答理論 。 ロシア語に翻訳できない名前のこの心理測定パラダイムは、非常に簡単に定式化できます。生徒が問題を解決する確率は、生徒のパラメーターと課題の関数として表されます。 パラメーターとして、たとえば、何らかの方法で計算されたユーザーの知識レベルとタスクの複雑さ、およびこれらの値に対する自信を使用できます。
- チェスの評価Elo。 1960年代にArpad Eloによって開発されたチェスプレーヤーのレーティングモデルは次のように機能します。新しいプレーヤーにはそれぞれデフォルトのレーティング(たとえば、ゼロ)が割り当てられ、各ゲームの後に両方のプレーヤーのレーティングが更新されます。 これを行うには、まず、各プレーヤーのゲームの予想結果を計算します( プレーヤーAを失った場合、 -勝利の場合、 -ドロー)、そしてゲームの予測結果と実際の結果の差に応じて評価が更新されます。
結果を予測するための式 、
評価を更新するには 、
どこで 、 -プレーヤーAとBの評価、 -プレーヤーの評価Aを更新しました。 -プレイヤーA.オッズのゲームの実際の結果 レーティング評価に対する自信を特徴づけます:プレイヤーについてまだあまり知らない場合、そのレーティングはすぐに変わるはずですが、経験豊富なマスターになると、予測されていない1つのゲームがレーティングをあまり変えないはずです。
これら2つのアイデアが統合された結果、次のシステムモデルが得られます。 ユーザーとレッスンを「プレーヤー」と見なし、レッスンの推薦に対するユーザーの反応は「ゲーム」の結果であり、この結果は生徒とレッスンのパラメーターに基づいて予測します。 このモデルの主な機能は、子供向けの算数を学習するサービスであるMaths Gardenに関する科学記事から引用しました 。 推奨事項として、このようなレッスン、つまりユーザーにとって最適なものを決定する確率を選択します。
レッスンの複雑さに加えて、トピックを含むコンテンツのレイアウトも考慮する必要があります。 Wikidataのナレッジグラフを使用し、レッスン作成者が2種類のトピックでタグ付けできるようにします。
- このレッスンに関連するトピック(説明されている)
- このレッスンを学習するために理解する必要があるトピック。
たとえば、ユーザーがレッスンを複雑すぎるとマークした場合、このレッスンに必要なトピックを学習するようアドバイスすることができます。
指標
適応型推奨の品質を評価するための主な指標は、第一に、推奨されるものの数から解決されたレッスンの割合(本質的に保持)であり、第二に、決定の予測結果と実際の結果(チェス評価に基づくモデルから)の違いです。
学んだ教訓のシェアは、ユーザーが推奨事項を検討する複雑さの点でどれほど有用で適切であるかについて語っています。 過去7日間の結果に基づいてこのメトリックを定期的に計算し、昨年末から60パーセントから80パーセントに成長しました。
2番目のメトリックである予測誤差は、むしろ適応システムの内部機構の精度を特徴づけます。 同時に、モデルを変更してユーザーの反応を予測し、ユーザーの実際の行動を評価することで、モデルが以前のバージョンと比べて良くなったか悪くなったかを示す可能性が低いこのメトリックに大きな変化を得ることができるため、解釈がより困難です。 ここでエラーを評価するため、私たちも異なります。
たとえば、predicted_scoreおよびreal_scoreの値が以前の範囲にあった場合 、および新しいバージョン-で 、エラーの絶対値は劇的に増加しますが、これは緊急にロールバックする必要があるという意味ではありません。 もちろん、この例は誇張されていますが、メトリックを分析するときは、エラーを変更する同様の理由を考慮する必要があります。
私が書いたように、これら2つのメトリックは基本的なものですが、網羅的なものではありません。 また、推奨リクエストの数(週に数千のオーダー)、数日間の予測エラーの移動平均(ピークを平滑化することで改善または悪化する傾向を特定するのに役立ちます)、新しい推奨のリクエストの処理時間(このパラメーターは常に)によってシステムの状態を監視します努力するものがあります:))。
また、A / Bテストを実施して、異なるモデルのパフォーマンスを比較します。 次に、上記の毎日の監視のメトリックに加えて、ダッシュボードを特定の実験の特定のメトリックで拡張できます。 ただし、通常、残すモデルに関する決定は、基本的なメトリックに基づいて行われます。
適応プロジェクト履歴
- 2016年3月1日-適応推奨の最初のプロトタイプがStepikに登場しました(当時はStepicとも呼ばれていました)
- 2016年3月21日-ベータテストの開始(Pythonのロシア語タスクブック)
- 2016年8月11日-JetBrains Python学習ツールであるPyCharm Edu 3の適応システム統合
- 2016年9月は、Pythonの一定レベルの「適応的」知識を達成するために、オンラインプログラムComputer Science CenterとAcademic Universityでプログラミング教育を割引きしたため、ユーザーアクティビティのピークです。 いくつかの面白いバグを修正しました。
- 2016年12月-2017年3月- 適応コンテンツの作成を めぐるコンペティション 。これについては、すでにHabréについて詳しく書いています 。
次の表に、Stepikの主な適応コースとその使用に関する情報を示します。
| コース | レッスン | 学生 | レッスンの反応 |
|---|---|---|---|
| アダプティブPython | 382 | 1874 | 22904 |
| Python適応シミュレータ | 55 | 2298 | 20546 |
| ポケモン! すべてをキャッチする | 101 | 243 | 7661 |
| 適応GMATデータの十分性の問題 | 265 | 29日 | 94 |
| SDA 2017 | 800 | 560 | 17649 |
おわりに
この記事では、Stepikプラットフォームの適応型推奨システムの一般的な機能について説明しました。 生徒の材料に対する決定の結果をどのように予測するか、実際の行動をどのように評価するか、ユーザーの知識の評価とレッスンの複雑さをどのように更新するかなど、舞台裏には多くが残っています。 おそらくいつかこれについての記事もHabrahabrに掲載されるかもしれませんが、現在、システムのこれらの部分は、説明できるよりも速く変化しています。
それでも、この記事を読んで興味を持っていただけたことを願っています。 コメントまたはプライベートメッセージでご質問にお答えいたします。