Fronteraの開発はScrapinghub Ltd.によって資金提供されており、完全なオープンソースコード(GitHubにあるBSD 3条項ライセンス)とモジュールアーキテクチャを備えています。 開発プロセスをできる限り透明でオープンにしようとしています。
この記事では、Fronteraを開発し、それに基づいてロボットを操作するときに発生した問題について説明します。
Fronteraに基づいた分散ロボットのデバイスは次のようになります。
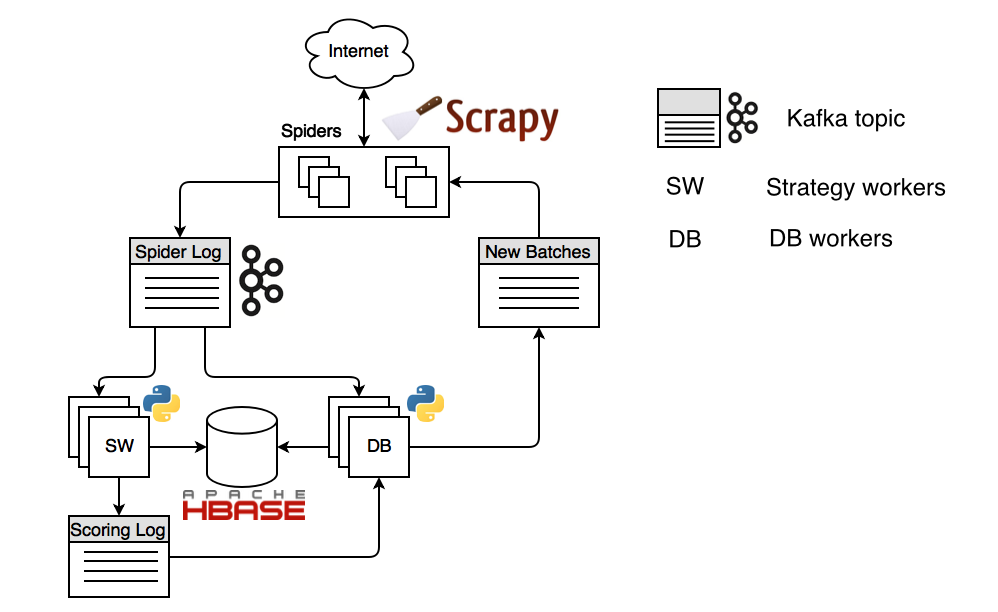
この図は、Apache HBaseストレージとApache Kafkaデータバスを使用した構成を示しています。 このプロセスは、クロールを開始するURLを計画するクロール戦略(SW)ワーカーから始まります。 これらのURLはスコアリングログであるkafkaトピック(専用メッセージチャネル)に分類され、データベースワーカーによって消費されます。また、Scrapyに基づいてスパイダーに到達する新しいバッチトピックも計画されます。 ScrapyスパイダーはDNS名を解決し、開いている接続のプールを維持し、コンテンツを受信して「スパイダーログ」トピックに送信します。 コンテンツが戦略ワーカーによって再び消費される場所から、クロール戦略でエンコードされたロジックに応じて、彼は新しいURLを計画します。
興味のある方は、Fronteraを使用してスペインのインターネットをどのように回ったかについての私のレポートのビデオをご覧ください。
現時点では、ロボットを自宅に配備しようとしている人々は、分散コンポーネントを構成するのが非常に難しいという事実に直面しています。 残念ながら、クラスタへのFronteraの展開には、そのアーキテクチャを理解し、ドキュメントを読み、そのためのデータバスとストレージを適切に構成する必要があります。 これらはすべて非常に時間がかかり、初心者には決して意味がありません。 したがって、クラスターへの展開を自動化する必要があります。 これらの目標を達成するために、 KubernetesとDockerを選択しました。 Kubernetesの大きなプラスは、多くのクラウドプロバイダー(AWS、Rackspace、GCEなど)によってサポートされていることです。 これを使用すると、Kubernetesクラスターを構成しなくてもFronteraを展開できます。
もう1つの問題は、Fronteraが原子力発電所の給水システムのようなものであることです。 消費者とメーカーがいますが、システムのさまざまな場所で流量や生産性などの特性を制御することが非常に重要です。 ここで、Fronteraはオンラインシステムであることを思い出してください。 対照的に、古典的なロボット( Apache Nutch )はバッチモードで動作します。最初に一部が計画され、次にダウンロードされ、次に解析され、再び計画されます。 このようなシステムでは、解析と計画を同時に行うことはできません。 したがって、さまざまなコンポーネントの速度を同期させるという問題に直面しています。 多数のスレッドを使用して一定のパフォーマンスでページをバイパスし、それらをストレージに保存して新しいスレッドを計画するロボットを設計することは非常に困難です。 Webサーバーの応答速度、サイト上のページのサイズと数、リンクの数はさまざまであるため、パフォーマンスのためにコンポーネントを正確に調整することはできません。 この問題の解決策として、Djangoに基づいたWebインターフェイスを作成したいと考えています。 それは主要なパラメータを表示し、それが判明した場合、ロボットオペレータにどのステップを実行するかを確認します。
モジュラーアーキテクチャについては既に説明しました。 他のオープンソースプロジェクトと同様に、私たちはサポートするさまざまな技術に努めています。 そのため、Pull Requestで分散Redisのサポートを準備しています。ApacheCassandraをサポートする試みはすでに2回あります。RabbitMQをデータバスとしてサポートしたいと考えています。
Google Summer Of Code 2017のフレームワーク内でこれらの問題を少なくとも部分的に解決する予定です。何かおもしろいものを見つけて、学生である場合は、 frontera @ scrapinghub.comでお知らせください。GSoCフォームからアプリケーションを送信してください。 アプリケーションの提出は3月20日に始まり、4月3日まで実行されます。 GSoC 2017の完全なスケジュールはこちらです。
もちろん、パフォーマンスの問題もあります。 現在、ScrapinghubはFronteraに基づく大規模なページダウンロードサービスのパイロットモードで動作しています。 クライアントは、コンテンツの受信先となる一連のドメインを提供し、それらをダウンロードしてS3ストレージに配置します。 ダウンロードしたボリュームの支払い。 このような状況では、単位時間あたりできるだけ多くのページをダウンロードしようとします。 Fronterを60個のスパイダーにスケーリングしようとすると、見つかったすべてのリンクが書き込まれると、HBase(Thriftインターフェイス経由)が低下するという事実に直面しました。 このデータを参照ベースと呼びますが、いつ、何をダウンロードしたか、どのような応答を受け取ったかなどを知るために必要です。 7つのサーバー領域のクラスターでは、リクエストの数が1秒あたり40〜50Kに達し、そのようなボリュームでは、応答時間が大幅に増加します。 記録パフォーマンスが劇的に低下します。 この問題を解決するには、いくつかの方法があります。たとえば、個別の高速ログに保存し、後でバッチメソッドを使用してHBaseに書き込むか、独自のJavaクライアントを介してThriftを直接バイパスしてHBaseに連絡します。
また、信頼性の向上にも常に取り組んでいます。 ダウンロードしたドキュメントが大きすぎる場合や、突然のネットワークの問題により、コンポーネントが停止することはありません。 ただし、これは時々起こります。 このようなケースを診断するために、プロセスの現在のスタックをログに保存するシグナルプロセッサOS SIGUSR1を作成しました。 何回かは、問題が何であるかを理解するのに役立ちました。
Fronteraをさらに改善する予定であり、アクティブな開発者のコミュニティが成長することを願っています。