スタックトレースとヒップダンプについて知りたいことすべて。 パート1
以下は、 JUGの 1つであるOdnoklassnikiのapanginとして知られるAndrey Panginによるレポートのデコードの第2部です(JPoint 2016からの彼のレポートのドップと拡張バージョン)。 今回は、スタックトレースについての会話を終了し、ダンプダンプとヒップダンプについても説明します。
それでは、続けましょう...

再帰について話し始めたので、決して返らないような再帰的なメソッドを実行するとどうなりますか。
static int depth; static void recursion() { depth++; recursion(); } public static void main(String[] args) { recursion(); }
StackOverflowErrorが表示されるまでに、標準のスタックサイズで何回の呼び出しが渡されますか?
測定してみましょう:
package demo4; public class Recursion { static int depth; static void recursion() { depth++; recursion(); } public static void main(String[] args) { try { recursion(); } catch (StackOverflowError e) { System.out.println(depth); } } }
同じコードで、キャッチStackOverflowErrorを追加しました。
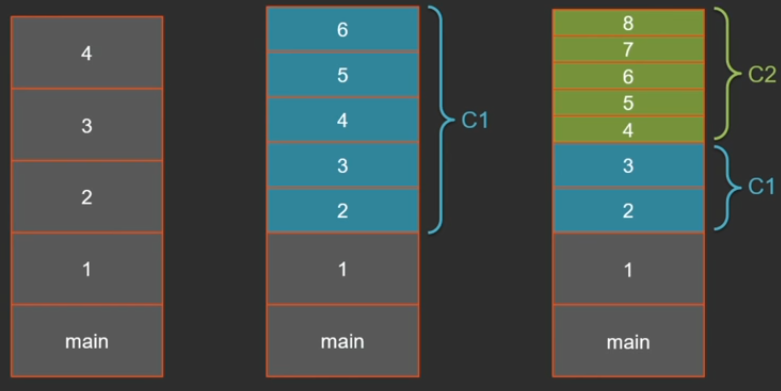
スタックサイズが1 MBの64ビットシステムでは、結果は22から35千回の呼び出しになります。 なぜそんなに大きな違いがあるのですか? ポイントはJITです。メソッドは、Javaコードの実行と並行して、コンパイラのバックグラウンドストリームでコンパイルされます。 ある時点で(再帰メソッドがすでに数回呼び出された後)、このメソッドのコンパイルが開始され、この時点でインタープリターでの実行が続行されます。 コンパイラが作業を完了するとすぐに、次の呼び出しはコンパイルされたコードに入ります。
Java 8以降、デフォルトでは、1つのVMに2つのコンパイラーがあります-「軽い」C1と「重い」C2 スタック上に3つのタイプのフレームがある場合、状況は可能です:解釈済み、コンパイル済みC1、およびコンパイル済みC2。 フレームサイズは大きく異なる場合があります。 インタプリタには最も扱いにくいフレームがあります。これは、すべてがスタックに格納されるためです(すべての引数、ローカル変数、現在のバイトコードポインターなど)。 これの多くはコンパイルされたコードには必要ありません。コンパイラーが最適であるほど、スタックに格納する必要が少なくなります。 たとえば、C2はローカル変数をスタック上に配置しません。すべてをレジスタにプッシュし、1レベル上にリンクします。
キーを使用して純粋に解釈されたモードで同じコードが実行される場合
-Xint
結果はほとんど常に12,500(±数フレーム)です。
今は同じことですが、C1コンパイラの後です。
-Xcomp -XX:TieredStopAtLevel=1
C1コンパイラの場合、結果も非常に安定しており、約2万5000です。
C2ですべてを一度にコンパイルする場合:
-Xcomp -XX:-TieredCompilation
これはすべて長くなりますが、結果は62,000フレームです。
標準スタックサイズ(1 MB)を62,000で割ると、フレームごとに約16バイトが消費されることがわかります。 コンパイルされたコードで確認しました-そうです。 フレームサイズは実際には16バイトではなく32バイトですが、1フレームでは2レベルのネストが直接接続されています。

デフォルトでは、64ビットアーキテクチャでは、スタックサイズは1 MBですが、調整可能です。 これら2つのキーは同義語です。
-Xss, -XX:ThreadStackSize
あまり知られていない事実は、特定のスレッドのスタックサイズを変更できることです。
Thread(ThreadGroup, target, name, stackSize)
しかし、大きなスタックを作成する場合、メモリ内の場所を占有することを忘れてはなりません。また、スタックサイズが大きい多くのスレッドがメモリ不足につながるような状況が発生する可能性があります。
java.lang.OutOfMemoryError: Unable to create new native thread
興味深い事実:jvm
-XX:+PrintFlagsFinal
をLinuxで見ると、1 MBのThreadStackSizeがあり、Windowsを見ると、ThreadStackSizeキーのデフォルト値は0になります。1Mbはどこから来ますか?
スタックのデフォルトサイズがexe-shnikで指定されている(アプリケーションのデフォルトサイズがexe-formatの属性で指定されている)ことは、私にとって啓示でした。
64ビットシステムの最小スタックサイズは約228 Kbです(JDKのバージョンによって異なる場合があります)。 スタックはどのように配置され、この最小サイズはどこから来ますか?

スタックには、Javaメソッドのフレームに加えて、まだいくつかの予約スペースがあります。 これは、常にスタックの最上部に少なくとも1つのレッドゾーン(1ページ-4 Kbのサイズ)とイエローゾーンのいくつかのページです。
スタックオーバーフローをチェックするには、レッドゾーンとイエローゾーンが必要です。 最初は、両方のゾーンが書き込み保護されています。 各Javaメソッドは、現在のスタックポインターのアドレスへの書き込みを試行して、レッドゾーンまたはイエローゾーンをチェックします(書き込みを試みると、オペレーティングシステムは、仮想マシンがキャッチして処理する例外を生成します)。 黄色のゾーンに到達すると、スタックオーバーフローハンドラーを開始するのに十分なスペースが確保されるようにロックが解除され、StackOverflowErrorのインスタンスを作成して渡す特別なメソッドに制御が渡されます。 レッドゾーンに入ると、回復不能なエラーが発生し、仮想マシンは致命的に終了します。
いわゆるシャドウゾーンもあります。 かなり奇妙なサイズがあります。Windowsでは6ページ、Linux、Solaris、その他のオペレーティングシステムでは20ページです。 このスペースは、JDK内のネイティブメソッドと仮想マシン自体のニーズのために予約されています。
プレゼンテーションの準備をしているときに、Java 8とJava 9の両方で再帰テスターを起動しました。ついに、仮想マシン(出力フラグメント)のすばらしいクラッシュが発生しました。
#
# A fatal error has been detected by the Java Runtime Environment:
#
# EXCEPTION_STACK_OVERFLOW (0xc00000fd) at pc=0x0000019507acb5e0, pid=9048, tid=10544
#
# JRE version: Java(TM) SE Runtime Environment (9.0+119) (build 9-ea+119)
# Java VM: Java HotSpot(TM) 64-Bit Server VM (9-ea+119, mixed mode, tiered, compressed oops, g1 gc, windows-amd64)
# Problematic frame:
# J 155 C2 demo4.Recursion.recursion()V (12 bytes) @ 0x0000019507acb5e0 [0x0000019507acb5e0+0x0000000000000000]
#
# No core dump will be written. Minidumps are not enabled by default on client versions of Windows
#
# If you would like to submit a bug report, please visit:
# http://bugreport.java.com/bugreport/crash.jsp
#
...
当然、利用可能な最新のビルドをダウンロードしました(レポートの時点では9.0 + 119でした)。この問題も再現されています。
これは、クラッシュダンプ分析の非常に良いケースです(Andrey Pangin- JVMクラッシュダンプの分析 )。 ここでは、すべてのスキル、特に分解が役立ちました。
以下は、現在のスタックポインターを基準にして値を書き込む命令です。 この命令でクラッシュが発生しました:
Instructions:
00000000: 89 84 24 00 a0 ff ff mov DWORD PTR [rsp-0x6000],eax
00000007: 55 push rbp
00000008: 48 83 ec 10 sub rsp,0x10
0000000c: 49 ba 78 71 88 8d 00 00 00 00 movabs r10,0x8d887178
00000016: 41 83 42 70 02 add DWORD PTR [r10+0x70],0x2
0000001b: e8 e0 ff ff ff call 0x00000000
Registers:
RSP=0x0000007632e00ff8
Java Threads:
=>0x0000019571d71800 JavaThread "main" [_thread_in_Java, id=10544,
stack(0x0000007632e00000,0x0000007632f00000)]
0x0000007632e00ff8
RSPレジスタの値を使用して、書き込むアドレスを計算できます。 このアドレスから16進数で6000を減算する必要があります。何らかの値を取得します。

この値で記録します。 クラッシュダンプには、現在のスレッドのスタック範囲も表示されます。

この値は、このスタックの一番最初(最上部)のページの終わり、つまり レッドゾーンだけです。
実際、そのようなバグがあります。 私はそれを分析し、理由を見つけました:一部のJVM関数は、Windowsで使用可能な6つのシャドウページを欠いています(実行時に多くを占有します)。 仮想マシンの開発者が誤って計算しました。
ところで、これらのゾーンのサイズはJVMキーで変更できます。
なぜビッグスタックが必要なのですか? Java EEの場合、そうでない場合。
これは、このテーマに関する私のお気に入りの写真の1つです。

ビジネスロジックの2つのラインは、さまざまなフレームワークとアプリケーションサーバーから数百のフレームを生成します。
パフォーマンス測定スタック
プロファイリングは、システムのパフォーマンスを測定するための重要な部分です。 すべてのプロファイラーは、サンプリングと計測の2つの大きなグループに分けることができます。
計装プロファイラーは、メソッドに単純にマークを付けます。メソッドの開始時と終了時にメソッドへの入り口に関するシグナルを追加します。メソッドからの出口に関するシグナルを追加します。 この方法で各メソッドを指示すると、測定は非常に正確になりますが、これにより大きなオーバーヘッドが発生することは明らかです。
public void someMethod(String... args) { Profiler.onMethodEnter("myClass.someMethod"); // method body Profiler.onMethodExit("myClass.someMethod"); }
実稼働環境では、サンプリングプロファイラーという別のアプローチが最もよく使用されます。 一定の周期(1秒あたり10〜100回)でフローのダンプを取得し、トレースが現在実行されているスレッドを調べます。 これらのスタックトレースに最も頻繁に該当するメソッドはホットです。
これがどのように機能するかの例を見てみましょう。 私は小さなプログラムを書きました。 それは小さいという事実にもかかわらず、あなたはすぐにそれが減速することができると言うことはできません。
まず、2つのランダムな地理座標を生成します。 次に、サイクルで、ランダムに生成された座標から別の特定のポイント(モスクワ)までの距離を計算します。 多数の数学があるdistanceTo関数があります。
結果はハッシュマップに追加されます。
ループ内のこれはすべて、何度も何度も実行されます。
package demo5; import java.util.IdentityHashMap; import java.util.Map; import java.util.concurrent.ThreadLocalRandom; public class Location { static final double R = 6371009; double lat; double lng; public Location(double lat, double lng) { this.lat = lat; this.lng = lng; } public static Location random() { double lat = ThreadLocalRandom.current().nextDouble() * 30 + 40; double lng = ThreadLocalRandom.current().nextDouble() * 100 + 35; return new Location(lat, lng); } private static double toRadians(double x) { return x * Math.PI / 180; } public double distanceTo(Location other) { double dlat = toRadians(other.lat - this.lat); double dlng = toRadians(other.lng - this.lng); double mlat = toRadians((this.lat + other.lat) / 2); return R * Math.sqrt(Math.pow(dlat, 2) + Math.pow(Math.cos(mlat) * dlng, 2)); } private static Map<Location, Double> calcDistances(Location target) { Map<Location, Double> distances = new IdentityHashMap<>(); for (int i = 0; i < 100; i++) { Location location = Location.random(); distances.put(location, location.distanceTo(target)); } return distances; } public static void main(String[] args) throws Exception { Location moscow = new Location(55.755773, 37.617761); for (int i = 0; i < 10000000; i++) { calcDistances(moscow); } } }
ここでは、すべてが遅くなる可能性があります:ランダムな座標の生成、距離の測定(多くの数学があります)、およびマップ上のレイアウトの両方。 プロファイラーを実行して、正確に時間がかかっているものを見てみましょう。
Java VisualVM(標準のJDKパッケージに含まれています-より簡単なものはありません)を使用し、Samplerタブでプロセスを見つけ、CPUをクリックして測定を開始します(30分間動作させます)。 デフォルトの測定間隔は100ミリ秒ごとに1回です。
何が起こった:
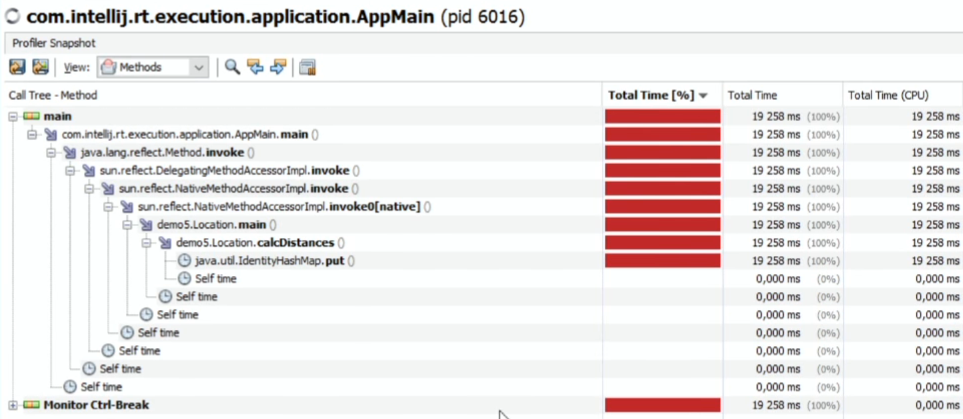
(Java VisualVMプロファイラーによれば)少し完全ではありませんが、IdentiryHashMap.putに時間を費やしています。
SelfTimeでソートされた方法で平板を見ると:
他に何もされていないかのように。
同じことは、他のプロファイラー(JProfiler、YourKitなど)でも測定できます。結果は同じになります。
HashMapは非常にブレーキがかかっていますか? いや プロファイラーだけが嘘をつく。
同時に、それらは同じ方法で配置されます。指定された頻度で、すべてのスレッドのダンプを受け取るJMXまたはJVMTIを介してメソッドを呼び出します。 たとえば、JVMTIにはGetAllStackTracesメソッドがあります。 仮想マシンの言うことは、ここでまとめて印刷します。
実は、これらはプロファイラーではなく、JVMであり、誤ったスタックトレースを提供します。 すべてのプロファイラーには1つの大きな問題があります。スレッドのスタックトレースは、安全な時点でのみ削除できます。これらは、仮想マシンがスレッドを安全に停止できることを認識するコードの特定のポイントです。 そして、実際にはそのようなポイントはほとんどありません。それらはループの内側にあり、メソッドの出口ポイントにあります。 コードの大きなキャンバスがある場合-同じ数学; サイクルなし-セーフポイントがまったくない場合があります。つまり、このキャンバスはスタックトレースに到達しません。
別の問題は、スリープ中のスレッドと実行中のスレッドが同じ方法でサンプリングされることです。 すべてのスレッドからダンプをダンプします。 これはあまり良くありません スタックトレースでスレッドをスリープ状態にする必要はありません。
また、ほとんどのプロファイラーは、ある種のブロッキングシステムコールでスリープするネイティブメソッドを区別できません。 たとえば、ソケットからのデータを待機している場合、ストリームはRUNNABLE状態になり、プロファイラーはストリームがCPUを100%消費していることを示します。 しかし、彼はCPUを消費しません。仮想マシンだけが、動作中のネイティブメソッドとブロッキングシステムコールを区別できません。
どうする
OSは、ネイティブコードのプロファイリング機能を提供します。 Linuxについて話すと、タイマーを設定し、特定の周波数でプロファイリングするための特別なOSシグナル(SIGPROF)を生成するsetittimerシステムコールがあります。 現在実行中のスレッドがそれを受け取ります。 OSの機能とSIGPROFシグナルハンドラーを使用して、現在のストリームのスタックトレースを安全な場所になくても収集できると便利です。 また、HotSpot仮想マシンでは、このような機会が提供されます。 文書化されていないプライベートAPIがあります:AsyncGetCallTraceは、セーフポイントにない現在のスレッドスタックを取得するために呼び出すことができます。
この穴は、特にOracle Developer Studioで見られました。 これはほとんど正直なスタックトレースを取得するプロファイラーです。
このレポートの準備中に、これらの方法を使用する他の人がいるかどうかを監視しました。 文字通り2つのプロジェクトが見つかりました。1つは古いもので既に放棄されたプロジェクトで、もう1つは比較的最近(2015年)登場し、正直プロファイラーと呼ばれています。
ここのAPIは非常に単純です。スタックをスタックする場所を準備し、メソッドを呼び出します。
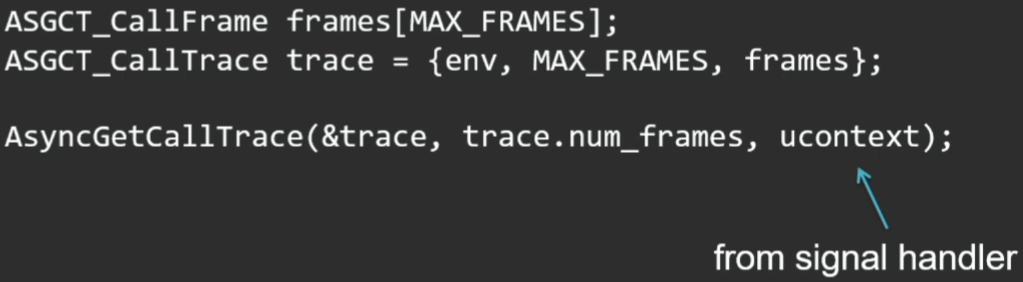
このメソッドの3番目のパラメーターは、シグナルハンドラーで取得される現在のコンテキストです。
私自身のオープンソースプロファイラーへのリンク: https : //github.com/apangin/async-profiler それを取る-それを使用します。 現在、彼はすでに人々を見せることを恥じていない状態にあります。 確かに、現在はLinuxのみに実装されています(注:レポートからmacOSサポートが追加されています)。
同じ例を確認しましょう。
プロファイリングするプロセスを言います。
pidは3202です。
私のプロファイラー(これまで見たことのない)の機能は、オンザフライで接続できることです(言及されている正直なプロファイラーは、アプリケーションの起動時にJavaエージェントとして実行する必要があります)。
プロファイリングに数秒を与えましょう。 結果として得られるものは次のとおりです。

最後に、メソッドのフラットリストがあります。 わずかに高い-個別の詳細(スレッドのすべてのスタック)。 状況は根本的に異なります。 すべての時間のほぼ3分の1が数学に費やされています-距離の計算です。 IdentityHashMap.put-通常は下部にあり、結果は2%です(最初のプロファイラーによると、100%を占めています)。 しかし、オブジェクトのidentityHashCodeの計算には本当に時間がかかります。 そして、プットとリサイズ自体に多くの時間が費やされます。 ちなみに、ランダムな場所の生成も無料ではありません(少なくとも12%)。
違いを感じてください。
このプロファイラーのオーバーヘッドははるかに少ないです。 1秒間に少なくとも1000回起動できますが、アクティブなスレッドのみのスタックトレースが削除されるため、これは正常です。 そして、彼は結果を非常にコンパクトな構造に追加します-彼はメソッド、クラスのこれらすべての名前を生成しません。 これはすべて、印刷時にのみ計算されます。 そして、プロファイリング中に、jmethodID(実際には、メソッドへのポインター)のみが追加されます。
ストリームダンプ
スレッドをダンプする方法は多数あります。Javaコードから、ネイティブから、プロセス自体の中から、または外部から。
内部からプロセス、つまりJava API getAllStackTracesを分析することについて話す場合、StackTraceElementの配列とそれが意味するすべてを提供します。

本番環境で使用しようとすると、それぞれが50〜60フレームのスタック深度を持つ2000ストリームの場合、このアレイだけで約50 Mbを占有しました。
JMXには同様の方法があります(リモートでプルできるという点で便利です)。 同じStackTraceElement配列と、キャプチャされたモニターに関する情報を返します。
アプリケーション自体からスタックトレースを生成する場合、はるかに優れた方法はJVMTI(Tool Interface)です。これは、ツール、プロファイラー、アナライザーなどを開発するためのネイティブインターフェイスです。

通常、プロファイラーのみが使用するGetAllStackTracesメソッドがあります。 Java APIと比較すると、非常にコンパクトな表現です。
ダンプを外部から削除する場合、最も簡単な方法はSIGQUITプロセスを送信することです(kill -3またはコンソールで適切な組み合わせのいずれか)。

この方法の利点は、Javaマシン自体がスタックトレースを出力することです。 これは最大速度で行われます。 とにかくこれはセーフポイント中に起こりますが、中間構造を作成する必要はありません。
別の方法はjstackユーティリティです。 これは、動的なアタッチメカニズムを介して機能します(詳細については後述します)。
jstackおよびjmapユーティリティには2つの動作モードがあることを理解することが重要です。 1つの-Fスイッチだけが異なりますが、本質的には同じ機能を提供する2つの異なるユーティリティですが、2つのまったく異なる方法で動作します。
それらの違いは何ですか。
ダイナミックアタッチは、特別なインターフェイスを介してユーティリティをJVMと通信するためのメカニズムです。 これはどのように起こりますか(例としてLinuxを使用)?
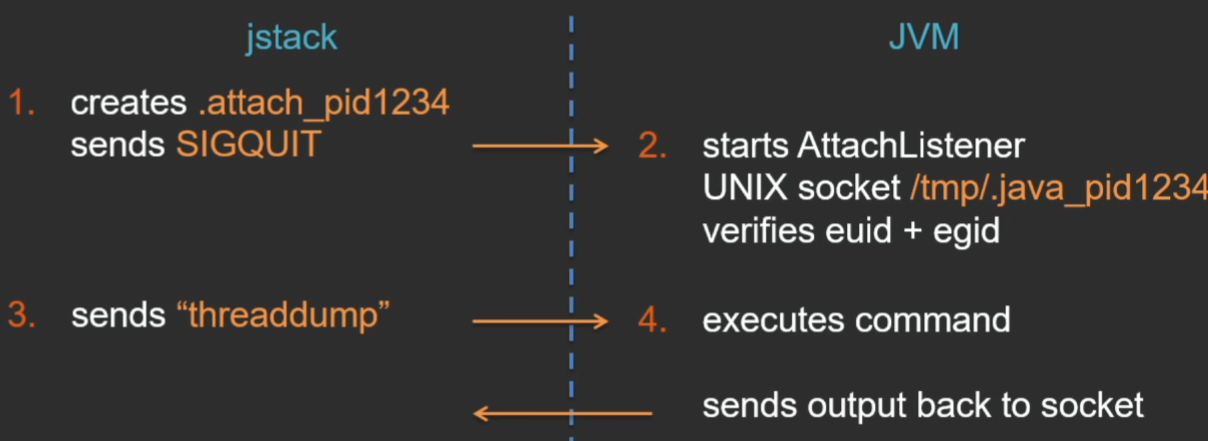
jstackユーティリティは、現在のディレクトリに特定のファイルを作成します。これは、ユーティリティがJVMに接続したいというシグナルであり、SIGQUITシグナルを仮想マシンに送信します。 仮想マシンはこのシグナルを処理し、現在のディレクトリにある.attach_pidシグナルファイルを確認し、これに応答して、特別なスレッドAttachListenerを起動します(既に実行されている場合は何もしません)。 また、このスレッドでは、jstackユーティリティとJVM間の通信用にUNIXドメインソケットが開きます。 ユーティリティがこのソケットに接続すると、JVMは相手側のユーザー権限をチェックし、他のユーザーが仮想マシンに接続して何らかの個人情報を取得できないようにします。 しかし、そこのチェックは非常に簡単です-有効なUIDとGIDの正確な対応のみがチェックされます(最終的には、他のユーザー(rootでさえ)からjstackを起動すると、このチェックのために正確にダンプを取得できないという一般的な問題があります)
UNIXソケット上の接続が確立された後、ユーティリティはコマンドを送信し、仮想マシンはこのコマンドを実行し、応答は同じソケット上のユーティリティに送り返されます。
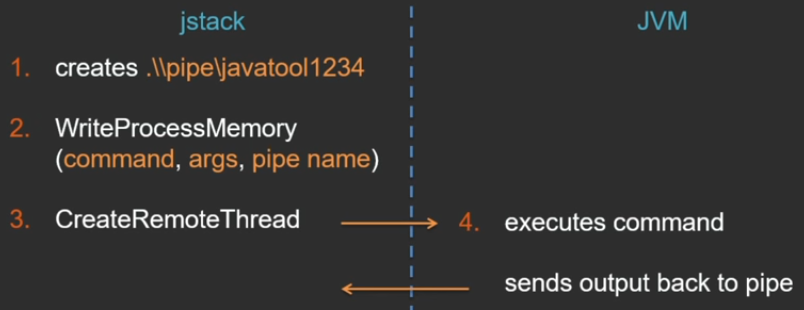
Windowではすべてが少し異なる方法で動作します(なぜ同じようにできないのかわかりません。WindowsにはUNIXソケットはありませんが、名前付きパイプがあります)-私が好きな別の美しいAPIがあります。こちら。
始まりはほぼ同じです-名前付きパイプが作成されます。 さらに、Windows APIには、他のプロセスに権限がある場合、別のプロセスのメモリにデータを直接書き込むことができるWriteProcessMemory関数があります。 この関数を介して、Javaプロセスのアドレス空間に一時的な補助メモリページが作成され、そこに実行されるコマンド、引数、およびパイプ名が書き込まれます。 スレッドを他の誰かのプロセスに実装できるようにするもう1つの優れた機能は、CreateRemoteThreadです。 jstackユーティリティは、リモートスレッドを開始します。これは、仮想マシンプロセスのコンテキストで既に実行されています。 そして、このスレッドへの引数として、以前に作成されたメモリ領域にポインタが渡され、そこにはコマンドに関するすべての情報があります。
その後、すべてが同じになります。JVM自体がコマンドを実行し、結果を送り返します。
このアプローチの利点:
- すべての操作は、最も効率的な方法で仮想マシンによって直接実行されます。
- インターフェイスはVMのバージョンに依存しないため、1つのjstackユーティリティは、これらのVMが実行されているJavaのバージョンに関係なく、異なるプロセスからダンプを削除できます。
欠点は次のとおりです。
- 既に述べたユーザーのコンプライアンス違反に関する制限。
- コマンドは仮想マシン自体によって実行されるため、「ライブ」仮想マシン上でのみ実行できます。
- このメカニズムは、特別なJVMオプションで無効にすることができます(セキュリティ上の理由などにより)。
-XX:+DisableAttachMechanism
。
「概念実証」として、私はCで簡単なユーティリティを作成することにしました。この方法でリモートJavaプロセスに接続し、コマンドライン( https://github.com/apangin/jattach )で渡されたコマンドを実行します 。
仮想マシンは次のコマンドをサポートしています。

これは、スレッドダンプ、ヒップダンプ、ヒップヒストグラムの取得、仮想マシンのフラグの印刷と設定、jcmdユーティリティが実行できるコマンドの実行です。ロードは、おそらくJVMTIエージェントライブラリをリモート仮想マシンにロードできる最も興味深いコマンドです。loadコマンドを使用すると、非同期プロファイラーが機能します(ライブラリをリモートJVMにアップロードします)。
これがどのように機能するかを簡単に示します。tomcatなどのプロセスを開始します。
プロセスpidは8856

です。コマンドでストリームの同じダンプが発行されます。これはJavaユーティリティではなくCなので、Javaの起動に時間を浪費する必要はありません。このユーティリティは非常に短く、WindowsおよびLinuxでは文字通り100行です。GitHubで利用できます。
このメカニズムにより、jstackユーティリティだけでなく、jmap、jinfo、jcmdユーティリティも動作します(実際、jattachの1つがこれらすべてのユーティリティの役割を果たします)。
2番目の方法はjstack -Fモードです。JVMからの協力がもはやないという点で異なります-ユーティリティはすべてを行います。
Linux PTRACE_ATTACH ( Windows ) , , . API, , jstack , , JVM . JVM , .
PTRACE_PEEKDATA 1 1 , , (, , ).
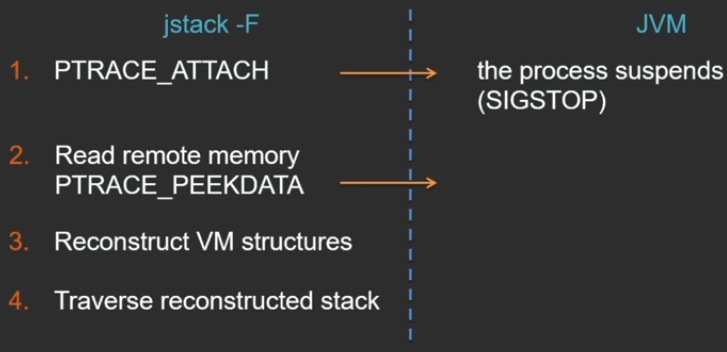
, :
- — jstack -F VM;
- root , .
:
- , ;
- jstack , , , jstack JVM, .

これは何のためですか? , , - . (, thread pool), , , , .
Java API , . Dynamic Attach — Java API, jstack. pid , Dynamic Attach .
public static void dump() throws AttachNonSupportedException, IOException { String vmName = ManagementFactory.getRuntimeMXBean().getName(); String pid = vmName.substring(0, vmName.indexOf('@')); HotSpotVirtualMachine vm = (HotSpotvirtualMachine) VirtualMachine.attach(pid); try { vm.localDataDump(); } finally { vm.detach(); } }
GitHub : https://github.com/odnoklassniki/one-nio/blob/master/src/one/nio/mgt/
-
jmap .
jmap -dump:live,format=b,file=heap.bin PID
, , :
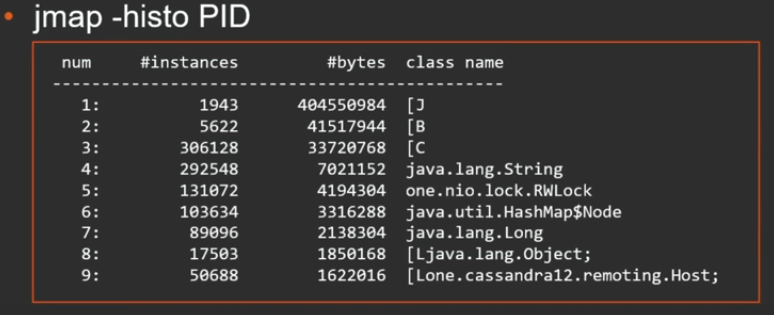
, . , . , .
jmap 2 : Dynamic Attach Serviceability Agent ( ).

jmap -F , , JVM. jmap -F , .
jmap? , - . , - , VM — , , . , Dynamic Attach . , , - , -F. . , . jmap , - .
, , forced-.
$ sudo gcore 1234
$ jmap -dump:format=b,file=heap.bin /path/to/java core.1234
, — , — core dump. . , . .
jmap «» core dump.
.
tomcat pid 2362. jmap forced-:

. . , gcore, core dump . 227 .
: , tomcat .
jmap core-.

, .. , , , ( , jmap -F, , 1 ). , , jmap -F .
, - , - . :
-XX:+HeapDumpOnOutOfMemoryError
— out of memory. GC , .
:

, .

, manageable, .. , jinfo, JMX-.
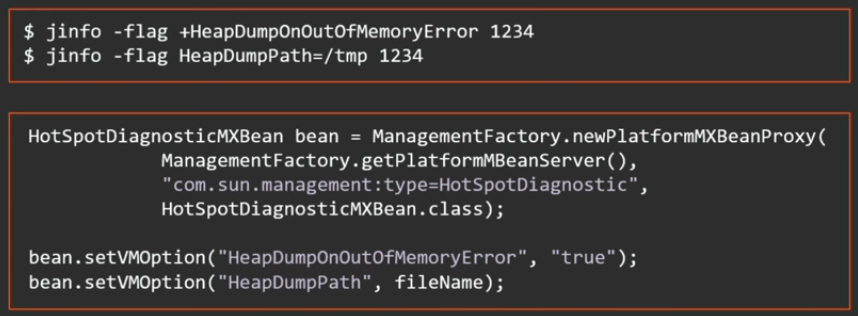
Java 8 update 92 2 - ( downtime ):

, , , , . 2 ( out of memory ):

?
java, native, , .
MXBean:
HotSpotDiagnosticMXBean bean = ManagementFactory.newPlatformMXBeanProxy( ManagementFactory.getPlatformMBeanServer(), "com.sun.management:type=HotSpotDiagnostic", HotSpotDiagnosticMXBean.class); bean.dumpHeap("/tmp/heap.bin", true);
JMX remote interface, .
: jmap , ssh - , , — JMX remote interface.
JVMTI. IterateOverInstancesOfClass .
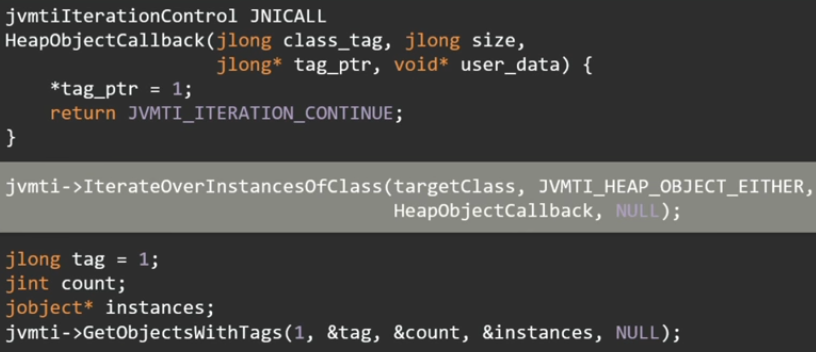
, - . , , 16 .
, . , , . GetObjectsWithTags jobject.
— serviceability agent — API, HotSpot. JDK JVM, Java-.
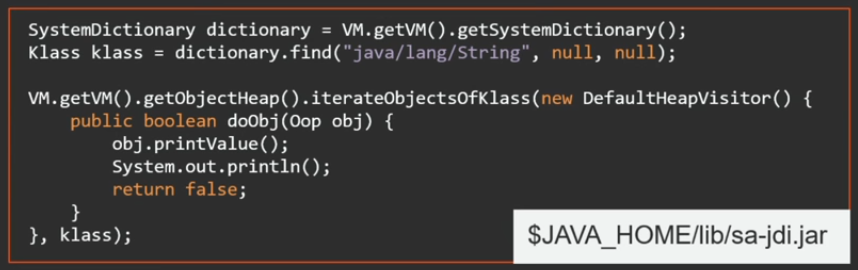
Java sa-jdi.jar — API serviceability agent. : JVM, , Java API, . , VM .
例を見てみましょう。
, — , . - , , . , , .. . serviceability agent .
API .
package demo6; import sun.jvm.hotspot.oops.DefaultHeapVisitor; import sun.jvm.hotspot.oops.Klass; import sun.jvm.hotspot.oops.Oop; import sun.jvm.hotspot.runtime.VM; import sun.jvm.hotspot.tools.Tool; public class KeyScanner extends Tool { @Override public void run() { Klass klass = VM.getVM().getSystemDictionary().find("java/security/PrivateKey", null, null); VM.getVM().getObjectHeap().iterateObjectsOfKlass(new DefaultHeapVisitor() { @Override public boolean doObj(Oop oop) { oop.iterate(new FieldPrinter("key"), false); return false; } }, klass); } public static void main(String[] args) { new KeyScanner().execute(args); } }
( Tool), execute ( ). run .
serviceability agent, Java-. .
tomcat .
— , .

, , . Print , .

. FieldPrinter, , fieldName, .
package demo6; import sun.jvm.hotspot.oops.DefaultOopVisitor; import sun.jvm.hotspot.oops.OopField; import sun.jvm.hotspot.oops.TypeArray; public class FieldPrinter extends DefaultOopVisitor { private String fieldName; FieldPrinter(String fieldName) { this.fieldName = fieldName; } @Override public void doOop(OopField field, boolean isVMField) { if (field.getID().getName().equals(fieldName)) { TypeArray array = (TypeArray) field.getValue(getObj()); long length = array.getLength(); System.out.print(fieldName + ": "); for (long i = 0; i < length; i++) { System.out.printf("%02x", array.getByteAt(i)); } System.out.println(); } } }
private key .
serviceability agent , API . , : , , oldGen. serviceability agent , API. Java- oldGen, , oldGen, .
tomcat, oldGen:
package demo6; import sun.jvm.hotspot.gc_implementation.parallelScavenge.PSOldGen; import sun.jvm.hotspot.gc_implementation.parallelScavenge.ParallelScavengeHeap; import sun.jvm.hotspot.gc_interface.CollectedHeap; import sun.jvm.hotspot.oops.DefaultHeapVisitor; import sun.jvm.hotspot.oops.Klass; import sun.jvm.hotspot.oops.Oop; import sun.jvm.hotspot.runtime.VM; import sun.jvm.hotspot.tools.Tool; public class OldGen extends Tool { @Override public void run() { CollectedHeap heap = VM.getVM().getUniverse().heap(); PSOldGen oldGen = ((ParallelScavengeHeap) heap).oldGen(); Klass klass = VM.getVM().getSystemDictionary().find("java/lang/String", null, null); VM.getVM().getObjectHeap().iterateObjectsOfKlass(new DefaultHeapVisitor() { @Override public boolean doObj(Oop oop) { if (oldGen.isIn(oop.getHandle())) { oop.printValue(); System.out.println(); } return false; } }, klass); } public static void main(String[] args) { new OldGen().execute(args); } }
:
- ;
- , , . API ( , JVM ).
.
— 7-8 JPoint 2017 . « JVM- », , , . «» , !
, JPoint Java — , .