Word2Vecモデル
出版物の最初の部分で述べたように 、モデルはクラスから取得されます-分布を平滑化することにより、結合セマンティッククラスとしてword2vecテキストの結果を表します。
平滑化の考え方は次のとおりです。
- トレーニング資料の頻度辞書を取得します。各単語には、ドキュメント(つまり、この語彙素に遭遇するドキュメントの数)に応じた出現頻度が割り当てられます。
- この頻度分布に基づいて、クラスの各単語の標準偏差が考慮されます(または、この場合の分散には基本的な違いはありません)。
- クラスごとに、そのコンポーネントのすべての偏差の平均を考慮します。
- 各クラスから「外れ値」-標準偏差が大きい単語を削除します。
ここで、SDwは各単語の標準偏差、avr(SDcl)はクラス平均二乗平均平方根、kは平滑化係数です。
明らかに、結果は係数kに依存します。 彼の選択は経験的なタスクであり、言語、トレーニングサンプルのサイズ、その均質性などに依存します。しかし、いくつかの一般的なものを特定しようとします。
モデルの構築とテスト
モデルでは、最も頻度の高いキーワードのリストから収集された、毎日のインターネットストリームから収集された資料が使用されました。 英語のテキストにはロシア語で約1億7000万語の単語が含まれており、その数は10億弱です。 クラスの数の範囲は、250単位で250〜5000クラスでした。残りのパラメーターはデフォルトで使用されていました。
テストはロシア語と英語の資料で実施されました。
簡単に言えば、テスト方法論は次のとおりです。参照テストケースは分類のために取得され、さまざまなパラメーターを使用してクラスタリングモデルを実行しました:クラスの数と平滑化係数を変更することにより、結果のダイナミクス、ひいてはモデルの品質を実証できます。
英語の5つの軍団は、 オープンソースから取得されます 。
- 20NG-TEST-ALL-TERMS-20トピック(10555K)
- MINI20-TEST-20トピック(816K)
- R52-TEST-ALL-TERMS-52スレッド(1487K)
- R8-TEST-ALL-TERMS-8トピック(1167K)
- WEBKB-TEST-STEMMED-4スレッド(1271K)
ロシアのケースは、オープンソースを見つけることができなかったため、クローズド開発から使用する必要がありました。
- Ru1-ショートメッセージ隊-13トピック(76K)
- Ru2-ニュースビルディング-10トピック(577K)
テストでは、複雑なメトリックを使用せずに、最も単純な比較方法を使用しました。 このような単純な分類(ダム分類子)を支持する選択は、研究の目的は分類結果を改善することではなく、結果を異なる入力パラメーターと比較することであるという事実を考慮して行われました。 つまり、面白いのは結果そのものではなく、そのダイナミクスです。
同時に、TFiDF対数測定を使用していくつかのクラスタリングモデルでテストを実行し、これらのモデルの結果がレキシカルユニグラムでトレーニングされたモデルの結果とどの程度根本的に異なるかを確認しました。 このようなテストにより、連想セマンティッククラスのモデルの結果はユニグラムのモデルよりほとんど劣っていないことが示されました。テストケースに応じて、品質が1〜10%わずかに低下しました。 これは、最初にトピックに「合わせた」ものではなかったため、得られたクラスタリングモデルの競争力を示しています。
モデルの品質のクラス数への依存
さまざまな数のセマンティッククラスを使用したテストが、すべてのケースで実行されました。250から5000まで、250クラスのステップで実行されました。
図1と図2は、ロシア語と英語の言語のモデルクラスの数に対する分類精度の依存性を示しています。

図1 ロシア語隊のword2vecセマンティッククラスの数に対する分類精度の依存性。 横軸はクラスの数、縦軸は精度値。
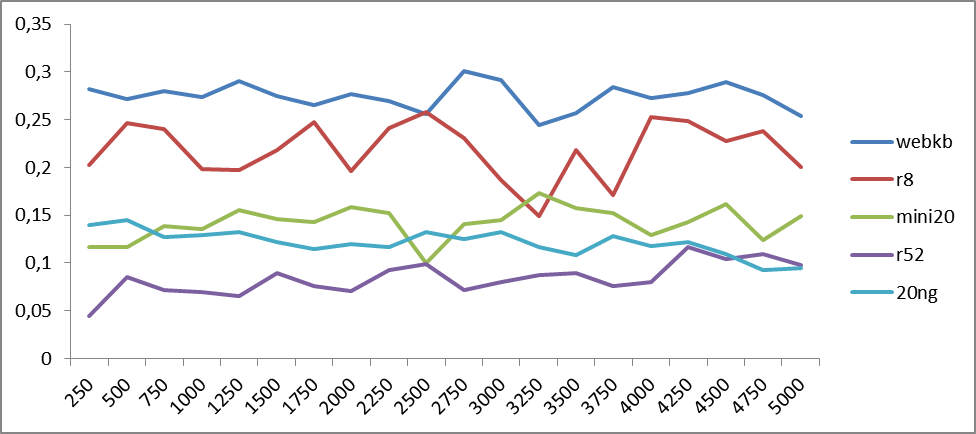
図2。 英語の場合のword2vecセマンティッククラスの数に対する分類精度の依存性。 横軸はクラスの数を表し、縦軸は分類精度を表します。
グラフは、精度の変動が本質的に周期的であることを示しており、その周期はテストされる材料によって異なる場合があります。 傾向を判断するために、平均値のグラフを作成します。

図3 平均値は、ロシア語の場合のword2vecセマンティッククラスの数に対する分類精度の依存性です。 横軸はクラスの数、縦軸は精度の値。 多項式(6次)トレンドラインが追加されました。

図4 平均値は、英語の場合のword2vecセマンティッククラスの数に対する分類精度の依存性です。 横軸はクラスの数、縦軸は精度の値。 多項式(6次)トレンドラインが追加されました。
図3と4から、クラスの数が4〜5000の範囲で増加すると、結果の品質が平均して向上することがすでにわかりました。 一般的に言って、これは驚くことではありません。スペースのより微妙なパーティションが具体化につながります。 しかし、さらに分割すると、セマンティッククラスが同質の部分に階層化し始めるという事実につながる可能性があります。 そして、これはすでにクラスの「フック」をやめるため、精度の低下につながります。異なる意味クラスは同じ意味に対応します。 これは、ロシア語と英語の両方で約5,000クラスに見られます。
500クラスの領域の両方の図に存在するピークは奇妙です:セマンティッククラスが少ないという事実にもかかわらず(したがって、クラスが混合されます)、それにもかかわらず、マクロセマンティックの統一が観察されます:クラスは一般的にトピックまたは別のものに引き寄せられます。
得られた結果から、それにもかかわらず、より最適なパーティションは4〜5000クラスのどこかにあると結論付けることができます。
モデルの品質の平滑化係数への依存。
図5は、異なる平滑化係数(1500クラス)でのR8ケースの分類精度の変化を示しています。 同じ建物内の任意の数のクラスの変更頻度は同じです。 すべてのケースで同様のグラフが観察されます。
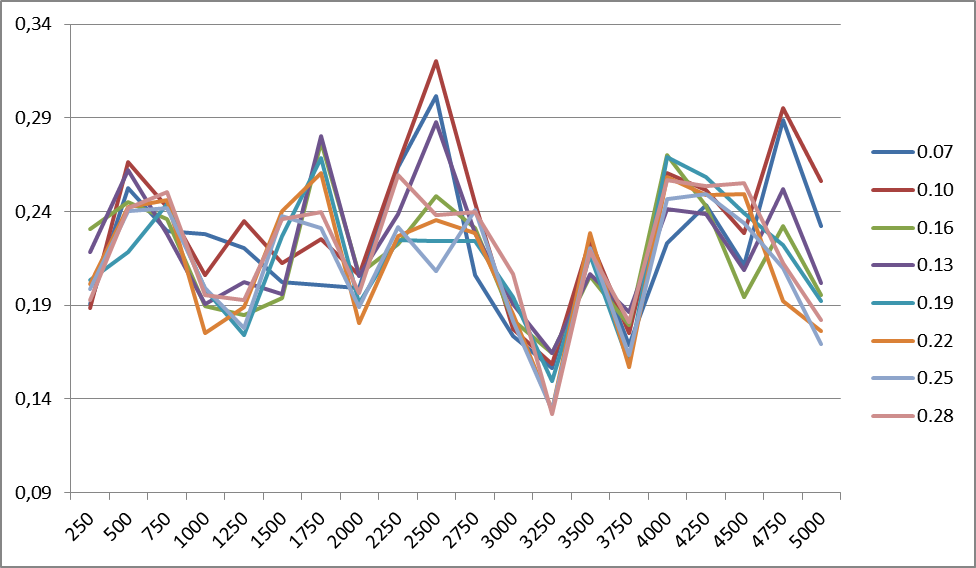
図5 平滑化係数の異なる値に対するR8ケースの分類精度の変化。 右側には、平滑化係数の値があります。
主な傾向を特定するために、英語とロシア語のすべての場合の平滑化係数の精度の平均値のグラフを作成します。
 | 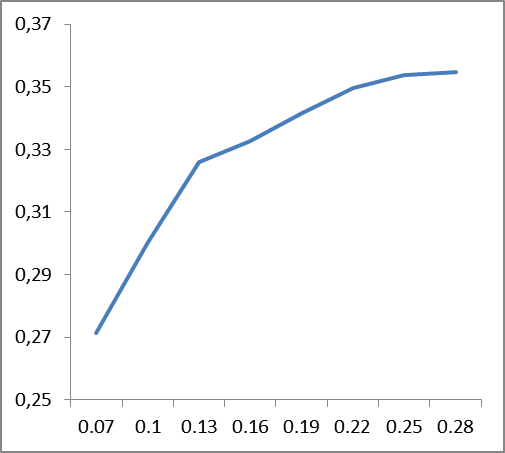 |
図6.分類精度の変化(垂直)の平滑化係数(水平)の値への依存性、建物の平均データ:左側-英語、右側-ロシア語。
図に示されているグラフから 6平滑化係数は言語に依存します。英語の安定性が0.22付近で発生する場合、ロシア語の場合は約0.12です。 どうやら、これは何らかの形で言語の複雑さ、その複雑さに関連しているはずです。
英語の最初(0.07)の精度のピークを説明するものを言うのは困難です。 その存在は、R8ケースの動作、および場合によってはケース自体の語彙内容に起因します。
実際、モデル自体のデータをさまざまな平滑化係数と比較すると、上記のしきい値では、高頻度の単語(前置詞、接続詞、冠詞)の一部がフィルタリングされていることがわかります。 したがって、ストップリストを入力しても意味がありません。このボキャブラリは、フィルタリングされるか、かなり低い重みを持つ別の関連セマンティッククラスを形成します。
平滑化係数の変動性がクラスの数に依存することは、精度の変化にほとんど影響しません。 ただし、さまざまな材料でこのような効果の傾向を特定することはできませんでした。
結論
もちろん、これは経験的であり、多くの要因に依存するため、モデルを取得する唯一の方法ではなく、おそらく最良の方法ではありません。 さらに、スムージングは非常に複雑な方法で実行できます。 それでも、この方法を使用すると、モデルを迅速かつ効率的に構築し、大量の情報に対して優れたクラスタリング結果を得ることができます。
ロシア語の資料でのクラスタリングの使用例を示します。
例
Sberbank検索クエリを使用したソーシャルメディアメッセージフローのクラスタリング。 メッセージの数は1万です。 これは、Sberbankのトピックに関する約10 MBのテキストまたは5〜6時間のメッセージフローです。
その結果、285クラスターが得られ、そこからSberbankに関する主要なイベントがすぐにわかります。
ここで、たとえば、最初の10個のクラスター(最初のメッセージのヘッダー):
- Sberbankクライアントは、オンラインサービスの誤動作について不満を述べています -この種の327メッセージ
- ユダヤ人は今後3年間でズベルバンクの民営化を望んでいる -77の投稿
- Sberbankは次のように回答します。 <name>こんにちは、残念ながら、現時点では本当に作業が中断されています ...-74メッセージ
- 2017年、Sberbankは量子情報転送ハイテクのテストを実施します-73メッセージ
- 175周年を迎えたSberbankが美術館への無料入場を許可 -71メッセージ
- 若者のズベルバンクビザデビットカードのメリットと、nルーブルのスウェットシャツの購入方法について学ぶ -57メッセージ
- 経済開発省は、民営化計画にズベルバンクを含めることを提案している -58件の投稿
- Sberbankはシステムの誤動作を報告しました -60メッセージ
- ウラジミール・プーチンは、ロシアの将来の役割と場所に向けて会議に参加しました -61メッセージ(スベルバンクも参加しました)。
- GrefはSberbankの民営化に関する情報を否定しました-64レポート
最も可能性が高いのは、ジオタグ、メッセージソース、オブジェクト間の述語関係などの追加情報に基づいて、1番目と8番目のクラスターを組み合わせてマクロクラスターにすることができることですが、これは別のタスクです。 。
ここでアルゴリズムの例とデモの実装を理解できます 。