声明
私は決して専門家ではありません。 私の目標は、AFとその範囲を理解しようとすることでした。 この記事では、c ++を使用してOOPコードを一種の関数に変換する方法をステップごとに説明します。 関数型プログラミング言語の中で、私はErlangの経験しかありませんでした。 言い換えれば、ここで私のトレーニングのプロセスを説明します-おそらくこれは誰かを助けるでしょう。 そしてもちろん、建設的な批判やコメントを歓迎します。 私はあなたがコメントを残すことさえ主張しています-私が間違ったこと、改善できること。
はじめに
記事では、FPの理論については説明しません-ハブを含め、ネットワーク上には多くの資料があります プログラムを純粋なFPに近づけようとしましたが、100%はできませんでした。 場合によっては、不便さのために、場合によっては経験不足のために。 したがって、たとえば、レンダリングは通常のOOPスタイルで作成されます。 なんで? FPの原則の1つは、不変のデータと状態の欠如です。 しかし、DirectX(私が使用するAPI)の場合、バッファー、テクスチャ、デバイスを保存する必要があります。 もちろん、フレームごとにすべてを再作成することは可能ですが、非常に長くなります(パフォーマンスについては記事の最後で説明します)。 別の例-FPでは、遅延評価がよく使用されます。 しかし、プログラムで使用する場所を見つけられなかったので、会うことはありません。
メイン
ソースコードはこのコミットにあります。
すべては
main()
関数で始まります。ここでは、
struct Shape
(
struct Shape
)を作成し、シミュレーションを更新する無限ループを開始します。 すぐにコードの設計に注意を払う必要があります-関数を別のcppファイルに記述し、使用場所で
extern
を宣言します-この方法では、コンパイル時間にプラスの影響を与え、コードをより一般的にする別のヘッダーファイルまたは別のタイプを作成する必要はありません読み取り可能:1つの関数-1つのファイル。
そのため、メイン関数でデータセットを作成し、それをさらに
updateSimulation()
関数に渡す必要があります。
シミュレーションを更新する
これがプログラムの中心であり、まさにAFが適用された部分です。 署名は次のとおりです。
vector<Shape> updateSimulation(float const dt, vector<Shape> const shapes, float const width, float const height);
元のデータのコピーを受け入れ、変更されたデータを含む新しいベクトルを返します。 しかし、なぜ一定のリンクではなくコピーなのでしょうか? 結局のところ、FPの原則の1つはデータの不変性であり、
const reference
がこれを保証するということです。 これは事実ですが、次に重要な原則は純粋な機能です。 副作用がなく、関数が同じ入力で同じ値を返すことを保証します。 しかし、リンクを受け取ると、これを保証できません。 例を見てみましょう。 定数参照をとる関数があるとします:
int foo(vector<int> const & data) { return accumulate(data.begin(), data.end(), 0); }
そして、次のように呼び出します:
vector<int> data{1, 1, 1}; int result{foo(data)};
foo()
は
const &
受け入れますが、データ自体は一定ではありません。つまり、データは、別のスレッドなどで呼び出される前に変更できます。 これが、すべてのデータがコピーの形で提供される理由です。
さらに、データの不変性の原則をサポートするために、すべてのユーザータイプのすべてのフィールドは定数でなければなりません。 これは、たとえば次のようなベクタークラスの外観です。
struct Vec2 { float const x; float const y; Vec2(float const x = 0.0f, float const y = 0.0f) : x{ x }, y{ y } {} // member functions }
ご覧のとおり、オブジェクトが作成されると状態が設定され、変更されることはありません! つまり 状態でさえストレッチと呼ぶことができます-単なるデータセットです。
updateSimulation()
関数に
updateSimulation()
ます。 次のように呼び出されます。
shapes = updateSimulation(dtStep, move(shapes), wSize.x, wSize.y);
移動のセマンティクス(
std::move()
)を使用します-これにより、余分なコピーを取り除くことができます。 ただし、この場合、これは効果がありません。 プリミティブ型で動作し、移動はコピーと同等です。
もう1つの興味深い点があります。この関数は新しいデータセットを返し、それを古い変数
shapes
割り当てます。これは、本質的に、状態の欠如の原則に違反します。 ただし、ローカル変数を大胆に変更できると考えています。これは関数の結果に影響を与えません。 この変更は、この関数内にカプセル化されたままです。
関数の本体は次のようになります。
updateSimulation
vector<Shape> updateSimulation(float const dt, vector<Shape> const shapes, float const width, float const height) { // step 1 - update calculate current positions vector<Shape> const updatedShapes1{ calculatePositionsAndBounds(dt, move(shapes)) }; // step 2 - for each shape calculate cells it fits in uint32_t rows; uint32_t columns; tie(rows, columns) = getNumberOfCells(width, height); // auto [rows, columns] = getNumberOfCells(width, height); - c++17 structured bindings - not supported in vs2017 at the moment of writing vector<Shape> const updatedShapes2{ calculateCellsRanges(width, height, rows, columns, move(updatedShapes1)) }; // step 3 - put shapes in corresponding cells vector<vector<Shape>> const cellsWithShapes{ fillGrid(width, height, rows, columns, updatedShapes2) }; // step 4 - calculate collisions vector<VelocityAfterImpact> const velocityAfterImpact{ solveCollisions(move(cellsWithShapes), columns) }; // step 5- apply velocities vector<Shape> const updatedShapes3{ applyVelocities(move(updatedShapes2), velocityAfterImpact) }; return updatedShapes3; }
ここで再びデータのコピーを取得し、変更されたデータのコピーを返します。 私の意見では、コードは非常に明確で理解しやすいように見えます-ここでは、関数ごとに呼び出し、変更されたデータをパイプラインのように渡します。
次に、シミュレーションアルゴリズム自体について説明し、数式を使用せずに機能スタイルに合わせて変更する方法を説明します。 したがって、それは興味深いはずです。
位置と境界の計算
データのコピーを処理し、新しいコピーを返す別のクリーンな関数。 次のようになります。
calculatePositionsAndBounds
vector<Shape> calculatePositionsAndBounds(float const dt, vector<Shape> const shapes) { vector<Shape> updatedShapes; updatedShapes.reserve(shapes.size()); for_each(shapes.begin(), shapes.end(), [dt, &updatedShapes](Shape const shape) { Shape const newShape{ shape.id, shape.vertices, calculatePosition(shape, dt), shape.velocity, shape.bounds, shape.cellsRange, shape.color, shape.massInverse }; updatedShapes.emplace_back(newShape.id, newShape.vertices, newShape.position, newShape.velocity, calculateBounds(newShape), newShape.cellsRange, newShape.color, newShape.massInverse); }); return updatedShapes; }
標準ライブラリは、長年にわたってFPをサポートしています。
for_each
アルゴリズムは高階関数です。 他の関数を受け入れる関数。 一般に、
stl
アルゴリズム
stl
非常に豊富であるため、関数型スタイルで記述する場合、ライブラリの知識は非常に重要です。
上記のコードには興味深い点がいくつかあります。 1つ目は、ラムダキャプチャリスト内のベクトルへのリンクです。 はい、リンクなしでやろうとしましたが、この場所では単に必要です。 そして、上で書いたように、これは原則に違反するべきではありません。なぜなら、 リンクはローカルベクトル、つまり 外の世界に閉じた。 ここでは
for
ループを使用せずに実行できますが、可視性と読みやすさの方向に進みました。
2番目のポイントは、サイクル自体に関連しています。 繰り返しますが、状態があるべきではないので、サイクルカウンタは状態であるため、サイクルはありません。 純粋な相転移では、サイクルはなく、再帰に置き換えられます。 それを使用して関数を書き直してみましょう。
calculatePositionsAndBounds
vector<Shape> updateOne(float const dt, vector<Shape> shapes, vector<Shape> updatedShapes) { if (shapes.size() > 0) { Shape shape{ shapes.back() }; shapes.pop_back(); Shape const newShape{ shape.id, shape.vertices, calculatePosition(shape, dt), shape.velocity, shape.bounds, shape.cellsRange, shape.color, shape.massInverse }; updatedShapes.emplace_back(newShape.id, newShape.vertices, newShape.position, newShape.velocity, calculateBounds(newShape), newShape.cellsRange, newShape.color, newShape.massInverse); } else { return updatedShapes; } return updateOne(dt, move(shapes), move(updatedShapes)); } vector<Shape> calculatePositionsAndBounds(float const dt, vector<Shape> const shapes) { return updateOne(dt, move(shapes), {}); }
リンクを削除しました! しかし、1つの機能の代わりに、2つが判明しました。 そして、最も重要なことは、読みやすさが悪化したことです(少なくとも私にとって-伝統的なOOPで育った人)。 興味深い点-いわゆる末尾再帰がここで使用されます-理論的には、この場合、スタックをクリアする必要があります。 ただし、c ++標準にはこの動作に関するエントリが見つからなかったため、スタックオーバーフローがないことを保証できません。 上記のすべてを考慮して、私はループに焦点を合わせることにしました。この記事ではこれ以上の再帰はありません。
セル範囲の計算とグリッドの塗りつぶし
計算を高速化するために、セルに分割された2Dグリッドを使用します。 このグリッド内にあるオブジェクトは、図に示すように、いくつかのセルを占有できます。
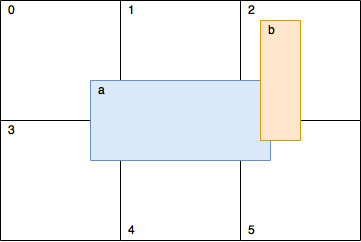
calculateCellsRanges()
関数は、Figureが占めるセルを
calculateCellsRanges()
、変更されたデータを返します。
fillGrid()
関数で、各セル(この例では、セルは
std::vector
)を対応する形状で塗りつぶします。 つまり セルに何も含まれていない場合、空のベクターが返されます。 コードの後半で、各セルを実行し、その内部で各図の交差を確認します。 しかし、図で
a
、図
b
と図
b
が(他のセルの中でも)セル2とセル5の両方にあることがわかります。これは、チェックが2回実行されることを意味します。 したがって、チェックが必要かどうかを示すロジックを追加します。 これを行うための行と列を知ることは簡単です。
衝突を解決する
以前の記事では、次の手法を使用しました。オブジェクトが重なっていることが判明した場合は、それらをバラバラにしました。
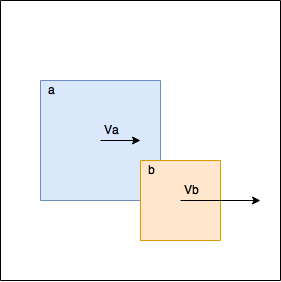
つまり オブジェクト
a
と
b
触れないようにしました。 これにより多くの複雑さが追加されました。オブジェクトを移動するたびに境界ボックスを再計算する必要がありました。 順列の繰り返しを避けるために、すべての順列が折り畳まれた特別なバッテリーを導入し、後でこのバッテリーを一度だけ使用しました。 何らかの方法で、同期のためにミューテックスを導入する必要がありました。コードは複雑で、この形式では機能的なアプローチには適していませんでした。 新しい試みでは、オブジェクトをまったく移動しません。さらに、本当に必要な場合にのみ計算を行います。 たとえば、図では、計算は必要ありません。 図
b
は図
b
よりも速く移動します。 彼らはお互いから離れて移動し、遅かれ早かれ彼らは私たちの参加なしに連絡を取りやめるでしょう。 もちろん、これは物理的に信じられませんが、速度が遅い場合や小さなシミュレーションステップを使用する場合は、かなり正常に見えます。 計算が必要な場合は、衝突中に発生した速度の変化を考慮し、これらの速度を形状識別子とともに返します。
速度を適用する
速度の変更が手元にある場合、
applyVelocities()
関数はそれらを単純に合計してオブジェクトに適用します。 繰り返しますが、信頼性については言及していません。特定の条件下でアーティファクトが発生する可能性が非常に高いですが、テストデータでは、このアプローチの問題に気付きませんでした。 そして、実験の目的はまったく信頼性ではなかった。
結果
これらの簡単な手順の後、レンダラーに渡す新しいデータが作成されます。 その後、何度も繰り返して、無限に続きます。 ここですべてが機能することの証拠として、短いビデオがあります:
映像
コードはこのコミットにあります。
おわりに
AFは思考の再構築を必要とします。 しかし、それだけの価値はありますか? ここに私の長所と短所があります。
のために:
- コードの読みやすさ。 SRPを使用すると、コードを非常に簡単に理解できます。
- テスト容易性。 関数の結果は環境に依存しないため、テストに必要なものはすべて揃っています。
- 私の意見では-最も重要なポイント。 優れた並列化機能。 各(はい、はい!各!)この例の関数は、複数のスレッドから安全に呼び出すことができます! 同期なし!
に対して:
- スプーン1杯のみ-スプーン、ひしゃくでさえありません。 パフォーマンス。 前の記事で、2Dグリッドを使用した同じスレッドで、8,000の形状をシミュレートできたことを思い出してください。 今ではわずか330です。カール、330!
私はゲーム開発で10年間働いて、すべてのラインを最大限に活用しようとしました。 3Dエンジンの場合、今日の形式での機能的アプローチは間違いなく自殺です。 ただし、c ++は単なるゲーム開発者ではありません。 確かに言うことはできませんが、ほとんどのアプリケーションでは、FPは非常に競争力のある手法になることが直感的に示唆されています。
いくつかのテクニックを使って、それらを組み合わせてみませんか? 次回の記事では、OOP、DOD、およびFPのクロスを試みます。 結果はわかりませんが、生産性を大幅に高めることができる場所をすでに見ています。 だから連絡を取り合う-それは興味深いはずです。