
実際のハードウェアにCEPHを最初にインストールすると、次のようになります。
cefをインストールしましたが、速度が低下し、理由が不明になりますか? それからあなたはその住所に来ました! あなたのセフをアップグレードします。
友達に聞いて、最初のディスクを荷物車に入れたところ、彼女が地元のカルタドロームでラップ記録を作っていないことに驚き、ニュルブルクリンクを夢見ましたか? そう! 物理学からは何も得られないため、クラスターを構築する前に、IOPS(少なくともおよそ)、必要なボリューム、およびそのためのディスクを計算する必要があります。 ディスクで8TBクラスターの目詰まりを考えている場合は、数十万のIOPSを期待しないでください。 IOPSとは、さまざまなタイプのディスクの概算値です 。
注目に値するもう1つのことは雑誌です。
知らない人のために:cephは最初にデータをログに書き込み、しばらくしてから遅いOSDにデータを転送します。 保存のファンがすぐに現れ、1つまたは2つのSSDをより高速に取り、20〜25 OSDの雑誌にします。 まず、IOPSが少し低下しています。 第二に、SSDが最初に死ぬまで機能します。 次に、そのSSDにあったすべてのOSDが落下します。 ログの設定には十分に注意する必要があります。 ceph.comの推奨事項では、SSDごとに5〜6個以下のOSDが必要であることが示されましたが、指定するログサイズと選択するファイルストアの最大同期間隔オプションは示されませんでした。 残念ながら、これらのパラメーターはクラスターごとに個別であるため、多数のテストを通じて自分で選択する必要があります。
私たちの小屋であなたの目を引くのは、座席ではなく2つの大きなソファです。 2017年にあなたの車の座席の代わりに2つのソファを置くことはありませんか?

CEPHに関しては、現在プールについて話し合っています。
通常、彼らは1つの大きなプールを作り、これで停止しますが、これは間違っています。 1つの大きなプールは、管理とアップグレードの容易さに関する問題につながります。 アップグレードはプールサイズにどのように関連しますか? そしてここにあります:ライブクラスターをその場でアップグレードすることは非常に危険です。そのため、その隣に新しい小さなクラスターを展開し、新しいプールにデータを再配置して切り替えることは理にかなっています。 この推奨事項は、データを論理エンティティに分割することから生まれます。 openstackを使用している場合は、openstackゾーン上に構築するのが理にかなっています。 多数のサーバーがある場合は、それらをラックに広げてクラッシュマップルールを操作します。
今、私たちはボンネットの下に入ります。

数万IOPSのシステムを設計しない場合、プロセッサはエントリレベルで提供できます。 ただし、1つのサーバー上のディスクが多くなり、IOPSを提供できるディスクが増えるほど、負荷が大きくなることに注意してください。 したがって、サーバーごとに2〜3倍のJBODのスーパー予算構成がある場合(それ自体は悪い考えです)、プロセッサの負荷が高くなります。 1つのJBODと30個のディスクを使用して、プロセッサをまだシェルフに入れませんでした。 しかし、「配線」は変化しています。 いいえ、もちろん、1 Gbit / sから始まりますが、OSDがクラッシュすると、リバランスが始まり、ここでチャネルは完全にロードされます。 したがって、10 Gbit / s CEPHノード間の相互接続は必須です。 LACPを行うための良いマナー。
「サスペンション」を強化する方が良いです。 1TBのデータにつき推奨される1GBのRAMに基づいてメモリを設定します。 それは可能です。 RAMによると、CEPHは非常に貪欲です。

さて、彼らが作ったものを簡単に見てみましょう。
CEPHには、データの整合性チェック(いわゆるスクラブとディープスクラブ)があります。 それらの起動はIOPSに強く影響するため、夜間にスクリプトを実行して、チェックするPGの数を制限することをお勧めします。
osd_recovery_op_priorityおよびosd_client_op_priorityオプションを使用して、リバランス速度を制限します。 昼間はゆっくりとしたリバランスを生き延び、夜間は最小負荷の瞬間に完全に実行することができます。
クラスターを眼球に満たさないでください。85%の制限は作成されません。 新しいサーバーでクラスター内のスペースを増やす可能性がない場合は、使用率による再重み付けを使用します。 このユーティリティには120%のデフォルトパラメータがあり、起動するとリバランスが開始されることに注意してください。
重みパラメーターもパディングに影響しますが、間接的に影響します。 はい、CEPHには重量と再重量があります。 通常、重量はディスクのボリュームと等しくなります。

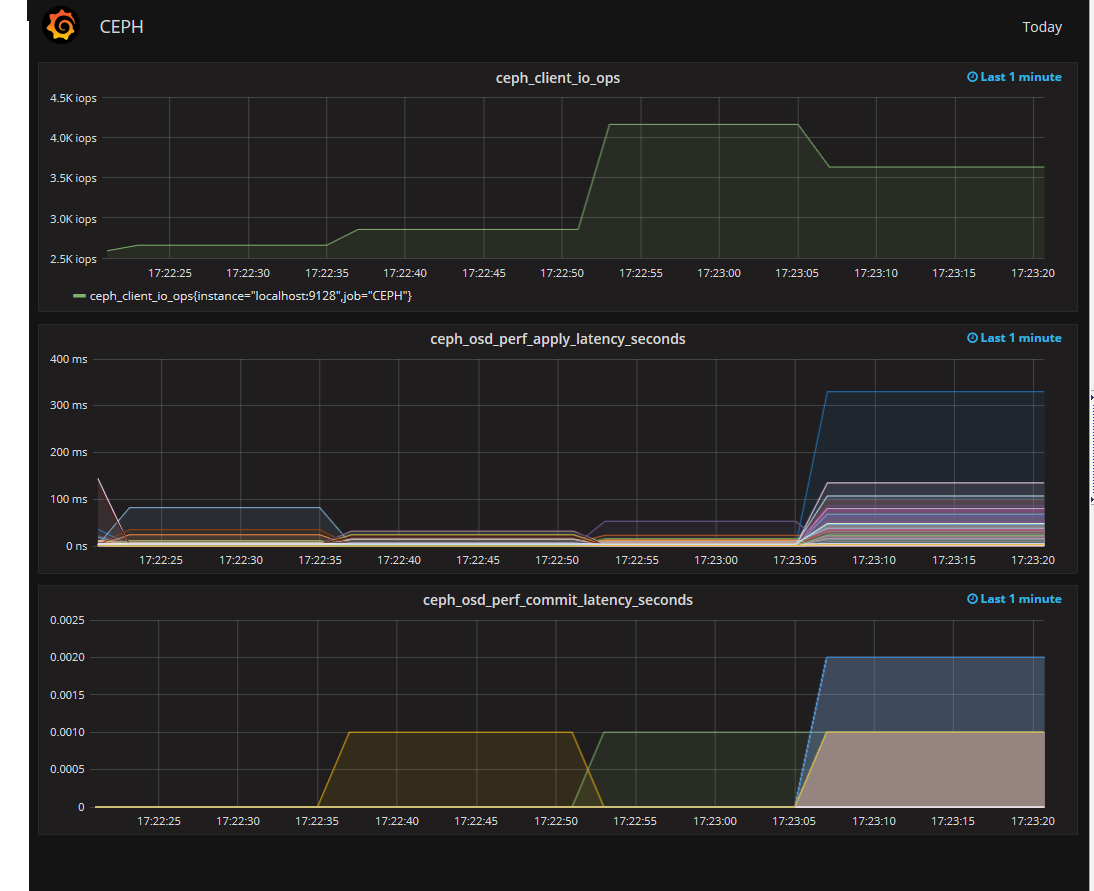
したがって、CEPHはほとんどポンプでくみ上げられ、モニターを接続するためだけに残ります。 何でも監視できますが、cef osd perfの出力の監視は特に興味深いものです。 最も興味深いのはfs_apply_latencyです。 どのOSDが長時間応答し、クラスターのパフォーマンスが低下するかを示すのは彼です。 さらに、これらのOSDのSMARTは非常に優れている場合があります。
こんな感じです。

これで、古いコリミガを回す撮影が終了しました。 舞台裏を見せて、私が聞いた神話について反論する時が来ました。
- 正常に実行します-それは正常です。 CEPHが適切に設計されていれば、CEPHをサポートするために大規模な管理者チームは必要ありません。
- バグがあります。 OSDでOOMを見ました。 OOMが来て、OSDを殺してから、もう1つを殺しました。 これは止まりました。 CEPHを更新し、OOMは数回来ましたが、その後突然停止しました。 偏向に失敗しました。
- ほとんどの場合、CEPHはスワップ時に非常に大食いです。 おそらく、swapiness設定を編集する必要があります。
- デュアルレプリケーションからトリプルレプリケーションへの切り替えは悲しくて長いため、慎重に検討してください。
- 同じタイプのサーバー、クラスター内の1つのOS、マイナーバージョンまでの1つのバージョンのCEPHを使用します。 理論的には、CEPHはすべてを開始しますが、なぜ各鉄片を個別にディベースするのですか?
- CEPHには、見かけよりもバグが少ない。 バグを発見したと思われる場合は、まずドキュメントを注意深く読んでください。
- 物理ハードウェアで1つのテストベンチを取得します。 仮想マシンですべてを検証できるわけではありません。
それとは別に、私はすべきでないことについて言いたい:
- 「これはセフです、どうなりますか?」という言葉で、フラットクラスタの異なるノードからディスクを削除しないでください。 ヘルスエラーになります。 クラスター内のデータ量とレプリケーションのレベルに依存します。
- 二重複製は極値の方法です。 第一に、データを失う可能性が高くなり、第二に、リバランスが遅くなります。
- 開発者向けリリースでは、開発者、特にbluestoreを使用する新しい開発者をテストできます。 もちろん動作しますが、クラッシュした場合、理解できないファイルシステムからどのようにデータを取得しますか?
- パラメーターengine = rbdのFIOが存在する可能性があります。 テスト中はこれに依存しないでください。
- ドキュメントで見つかった新しいものをすべてすぐに製品にドラッグしないでください。 最初に物理的なスタンドを確認します。
ご清聴ありがとうございました。