Junctionには、
ConcurrentMap_Crude
と呼ばれる「世界で最も簡単な」マップインターフェイスのマルチスレッド実装がいくつか含まれています。 簡潔にするために、これを粗マップと呼びます。 この投稿では、粗マップとジャンクションライブラリの線形マップの違いについて説明します。 線形は、ジャンクションで最も単純なマップであり、サイズ変更と削除の両方をサポートします。
原油マップがどのように機能するかの説明は、元の投稿で読むことができます。 要するに、 オープンアドレッシングとリニアプローブに基づいてい ます 。 これは、基本的に線形検索を使用したキーと値の大きな配列であることを意味します。 特定のキーを追加または検索する場合、キーからハッシュを計算して、検索を開始する場所を決定します。 マルチスレッドモードでは、データの追加と検索が可能です。
Junctionの線形マップは同じ原則に基づいていますが、次の例外があります。配列がオーバーフローすると、そのすべてのコンテンツがより大きな次元の新しい配列に転送されます。 データ転送が終了すると、古いテーブルは新しいテーブルに置き換えられます。 しかし、マルチスレッド操作をサポートするにはどうすればよいでしょうか? 線形マップアプローチは、いくつかの違いを除いて、Java のクリッククリフのノンブロッキングハッシュマップに基づいています。
データ構造
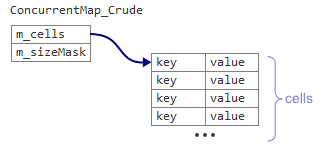
まず、データ構造をわずかに変更する必要があります。 粗マップには、最初に
m_cells
ポインターと
m_cells
整数の2つのデータ要素がありました。
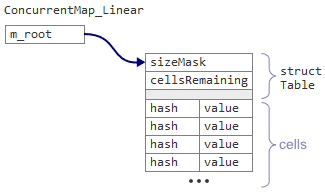
Linearでは、マップは
Table
構造を指す唯一の
m_root
データ要素であり、単一の連続したメモリブロックの形でセル自体が続きます。
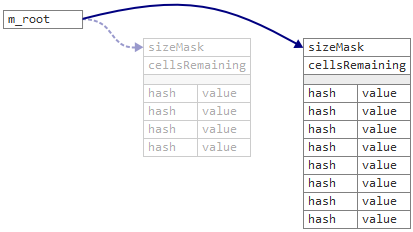
新しい共有
cellsRemaining
カウンターは、テーブルのサイズの75%の初期値で
Table
構造に格納されます。 スレッドは、新しいキーを追加しようとするたびに、最初に
cellsRemaining
減らし
cellsRemaining
。
cellsRemaining
がゼロより
cellsRemaining
なると、テーブルがいっぱいになり、データを新しいものに移動します。
このようなデータ構造を使用すると、
m_root
ポインターをリダイレクトするだけで、1つのアトミックステップでtable、
sizeMask
、
cellsRemaining
を同時に置き換えることができます。
2つのマップのもう1つの違いは、線形マップが元のキーではなくハッシュキーを保存することです 。 この場合、ハッシュ関数を再計算する必要がないため、移行を高速化できます。 Junctionで使用されるハッシュ関数も可逆であるため、ハッシュされたキーから元のキーをいつでも復元できます。
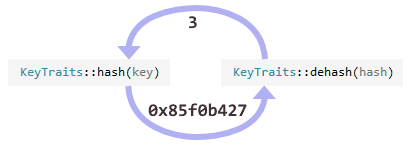
ハッシュ関数は可逆であるため、既存のキーを見つけるタスクは、ハッシュを計算するのと同じくらい簡単です。 したがって、Junctionは現在、整数キーとポインターキーのみをサポートしています。 (私の意見では、マップの代わりにマルチスレッドセット(セット)を実装することにより、より複雑なキーのサポートを提供することが最善です)。
データを新しいテーブルに転送するのは間違った方法です
データの移行を開始するタイミングがわかったので、移行タスク自体を見てみましょう。 基本的に、古いテーブルで使用されている各セルを見つけて、そのコピーを新しいテーブルに追加する必要があります。 一部のエントリは配列内の同じ場所に配置され、一部のエントリはより高いインデックスを持ち、一部は理想的なインデックスに近づきます。
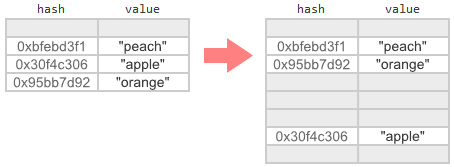
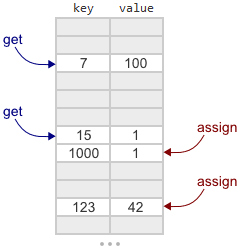
もちろん、移行中に他のスレッドが古いテーブルのデータを変更できる場合、事態は少し複雑になります。 素朴なアプローチを使用すると、変更を失うリスクがあります。 たとえば、マップがほぼ一杯で、この時点で2つのスレッドが次のことを実行するとします。
- スレッド1は
assign(2, "apple")
呼び出し、cellsRemaining
を0に減らします。 - スレッド2は
assign(14, "peach")
をassign(14, "peach")
cellsRemaining
を-1に減らします。 移行が必要です。 - ストリーム2は、古いテーブルの内容を新しいテーブルに転送しますが、新しいテーブルでのアクセスは開きません。
- ストリーム1は、古いテーブルで
assign(2, "banana")
を呼び出します。 このキーにはセルがすでに存在するため、関数はcellsRemaining
削減しません。 彼女は単純に古いセルの「リンゴ」を「バナナ」に置き換えます。 - ストリーム2は、新しいテーブルを
m_root
ポインターに関連付けて、変更をストリーム1にマッシュします。 - スレッド1は、新しいテーブルで
get(2)
を呼び出します。
この時点で、キーが1つのスレッドによってのみ変更され、これが最後に記録された値であるため、
get(2)
「banana」
get(2)
返すことが予想されます。 残念ながら、
get(2)
は古い「apple」値を返しますが、これは間違っています。 したがって、別の戦略が必要です。
安全なデータ転送
上記の問題を回避するために、 readers-writer lockを使用してマルチスレッドの変更をブロックできますが、この場合は「共有排他ロック」の定義の方が適しています。 このアプローチでは、テーブルの内容を変更するすべての関数がロックをまとめます。 テーブル間でデータを転送するスレッドは、例外的なロックをかけます。 QSBRのおかげで、
get
ロックはまったく必要ありません。
しかし、線形マップはそうではありません。 これは一歩先を行きます-データを変更するために共同ロックさえ必要としません。 このメソッドの本質は次のとおりです。古いテーブルからデータを転送するプロセスでは、各セルの
value
フィールドが特別な
Redirect
マーカーに置き換えられます。

この変更は、すべてのマップ操作に影響します。 特に、
assign
関数は、セルの
value
フィールドを盲目的に変更できなくなりました。 代わりに、
Redirect
トークンが設定されている場合に上書きされないように、
value
に対してread-modify-write操作を実行する必要があります 。 関数が
value
に対応する
Redirect
トークンを見つけた場合、新しいテーブルが既に存在し、そのテーブルで操作を実行する必要があります。
データ転送中にマルチスレッド操作を許可する場合、明らかに、同じ値が両方のテーブルの各キーに対応することを確認する必要があります。 残念ながら、古いセルへの
Redirect
を自動的に設定し、同時に古い値を新しいセルにコピーする方法はありません。 ただし、ループで各値を転送することにより、データの整合性を確保できます。 線形マップは次のループを使用します。

このループでは、
Redirect
マーカーがまだ設定されていないため、競合するスレッドは移行を担当するスレッドが読み取った直後に元の
value
変更できます。 この場合、データを運ぶストリームがCASを使用して
Redirect
トークンを設定しようとすると、CASはエラーを返し、ストリームは既に新しい値で操作を再実行しようとします。 ソーステーブルの
value
が変更される限り、データ転送ストリームは試行を続けますが、遅かれ早かれ転送は成功します。 このアプローチでは、マルチスレッドのget呼び出しで新しいテーブルの値を安全に見つけることができますが、パラレル
assign
呼び出しでは、移行が完了するまで新しいテーブルを変更できません(Cliff Clickハッシュマップにはそのような制限がないため、移行サイクルにはもう少しステップがあります)。
現在のバージョンの線形マップでは、すべてのデータが移行されるまで、
get
呼び出しも新しいテーブルから読み取られません。 したがって、最新バージョンでは、ループは必要ありません。 移行は、元のテーブルで
value
アトミックな交換を実行し、新しいテーブルに
value
を保存するだけで実装できます(この投稿を既に書いたときに理解しました)。 これで、
get
呼び出しが
Redirect
でつまずいた場合、これは移行の完了に役立ちます。 おそらく、代わりに彼がすぐに新しいテーブルから値を読み取ると、ソリューションはよりスケーラブルになります。 これは、さらなる研究のためのトピックです。
マルチスレッドデータ転送
Table
構造には、まだ言及していない他のデータ要素があります。 それらの1つは
jobCoordinator
です。 データ転送中、
jobCoordinator
は、移行プロセスを反映する
TableMigration
オブジェクトを
TableMigration
ます。
m_root
されるまで、新しいテーブルを保存します。 詳細は説明しませんが、
jobCoordinator
では複数のスレッドが移行プロセスに参加できます。

複数のスレッドが一度に移行を開始しようとした場合はどうなりますか? このような競合状態が発生した場合、線形マップはダブルチェックロックを使用して、重複した
TableMigration
オブジェクトが
TableMigration
れないようにします。 これが、すべての
Table
オブジェクトにミューテックスがある理由です(Cliff Clickのハッシュマップもここでは異なります。スレッドレースが新しいテーブルを楽観的に作成できるようにします)。
この投稿では、
erase
関数は気取らないため、十分な注意を払っていません。セル
value
を、初期化に使用した特別な
NullValue
値に単純に置き換えます。 ただし、
hash
フィールドは変更されません。 つまり、遅かれ早かれ、テーブルは削除されたセルでいっぱいになる可能性がありますが、新しいテーブルへの移動中はクリアされます。 また、新しいテーブルのディメンションの選択に関していくつかの微妙な点がありますが、ここではこれらの詳細を省略します。
これは、線形マップが一般的にどのように見えるかです! ジャンクションのLeapfrogマップとGrampaマップは同じ考え方に基づいていますが、展開方法が異なります。
並列プログラミングは難しい作業ですが、マルチコアプロセッサが使用されなくなることはないので、理解を深める価値があると思います。 そのため、線形マップの実装における私の経験を共有することにしました。 例は、何かを学んだり、少なくとも新しい分野に精通するための良い方法です。
ああ、仕事に来てくれませんか? :)wunderfund.ioは、 高頻度アルゴリズム取引を扱う若い財団です。 高頻度取引は、世界中の最高のプログラマーと数学者による継続的な競争です。 私たちに参加することで、あなたはこの魅力的な戦いの一部になります。
熱心な研究者やプログラマー向けに、興味深く複雑なデータ分析と低遅延の開発タスクを提供しています。 柔軟なスケジュールと官僚主義がないため、意思決定が迅速に行われ、実施されます。
チームに参加: wunderfund.io