- 外部結合サポート。
- ケース... ... ...リクエストで終了。
- 空間(地理空間)データを操作するための関数。
- Grafanaで時系列データ(時系列)を表示することができます。
- サブクエリの限定的なサポート。
- 読み取り専用モードで動作するクラスターノード。
- PostgreSQL 9.5プロトコルのサブセットをエミュレートします。

プロジェクトのgithubでCrateDBチームにロシア語を話す開発者Ruslanがいることを嬉しく思いました。 彼から、内部構造とプロジェクトの依存関係に関する質問への回答をすぐに受け取りました。
前回「SQLのダークサイドに参加する」という記事でクエリの機能について説明したとき、クレートおよび結合操作の不完全なサポートに対する巨大なボリュームjdbcドライバーの欠点について言及しました。 これらの欠陥は最新バージョン(> 1.0)で修正されました!
これで、jdbcドライバーPostgreSQL、pgコマンドラインユーティリティを使用できるようになり、アプリケーションのクレート用に別のドライバーをパックする必要がなくなりました。 これは、サーバーでPostgreSQL 9.5 ワイヤープロトコルを部分的にエミュレートすることで可能になります。 トランザクションがサポートされていない(したがって、オートコミットがインストールされている)ことを考慮すると、ログイン/パスワードによる認証は成功し、接続用のSSLはサポートされず、UTF-8文字エンコードのみがサポートされます。 COPYサブプロトコルpgおよびストアド関数呼び出しのサブプロトコルはまだサポートされていません。 SQLクエリの構文とサポートされている関数のサブセットはCrateDBに固有であることを覚えておく必要があります。
最後に、 Left、Right、およびFull Outer Joinのサポートがサーバーに登場しました。 ただし、特別なスケジューラーの最適化は適用されず、結合はネストされたループとして実装されますが、同時にフィルターは分散して適用されます-クエリからの各テーブルシャードで。
PL / SQL CASEを連想させる奇妙な構文が SELECTに登場しました:
CASE WHEN condition THEN result [WHEN ...] [ELSE result] END
FROMのサブクエリでは、まだ奇跡は起きていません。 集計を使用したサブクエリがサポートされているか、パーサーが簡単に上書きできるクエリがサポートされています。 複雑なサブクエリが利用できるようになるという事実に、このプロジェクトが一年で驚くことを願っています。
関数、距離、範囲内、交差、緯度/経度は、クエリで空間データを操作するために使用できます。 地理データの操作は、この分散データベースの作成に基づいてElasticsearchで長年行われてきました。
Grafana用のデータアクセスプラグインがあります。 CrateDBに保存されている監視および遠隔測定データのグラフを作成できます。
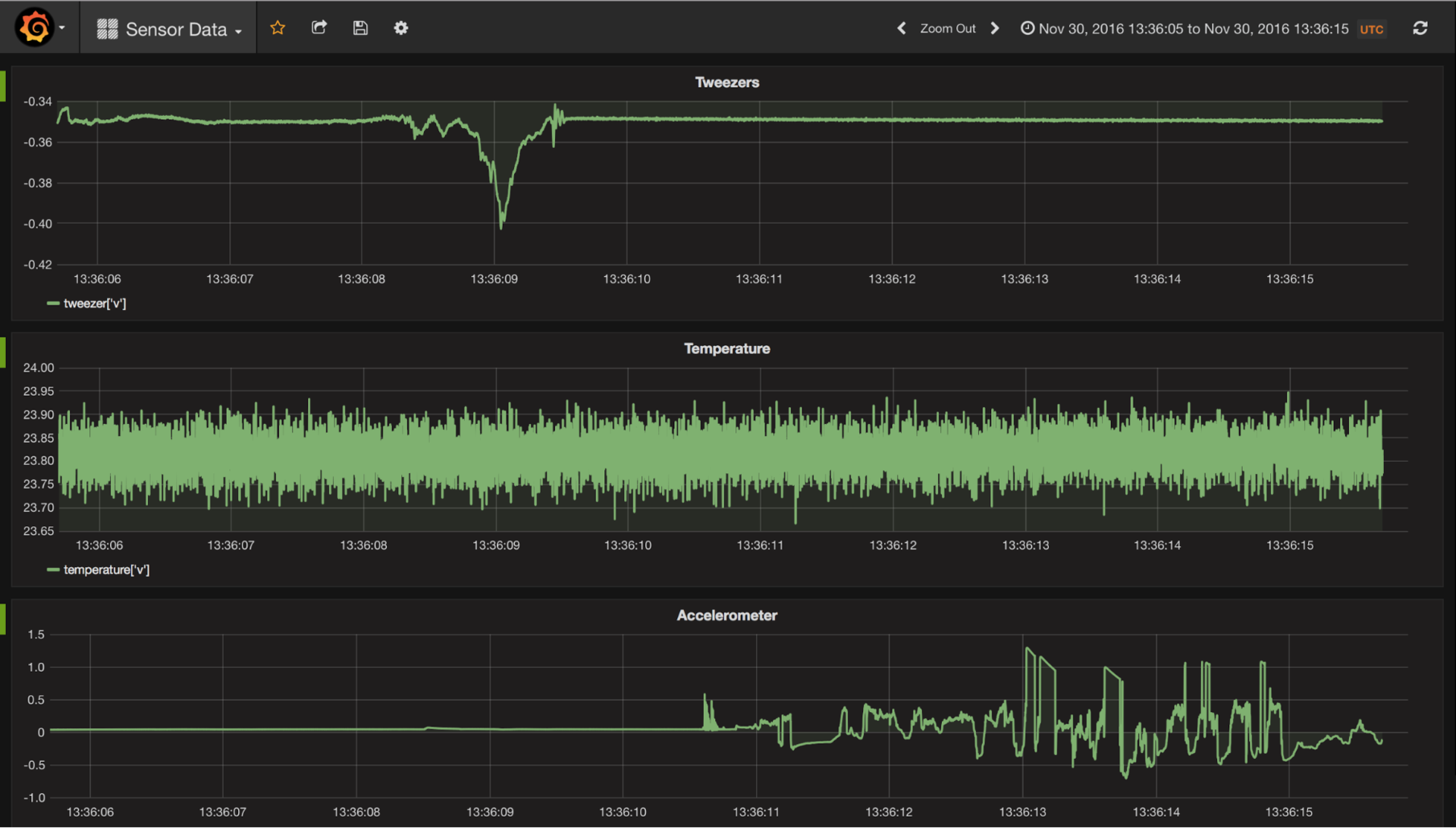
接続パラメーターを構成し、データを取得するためのクエリを指定する必要があります。

実験のためにCrateDBをダウンロードして起動するには、次のようにします。
java -jar groovy-grape-aether-2.4.5.1.jar https://raw.githubusercontent.com/igor-suhorukov/crate-io-installer/master/crate-io.groovy
CrateDB 1.0.4を起動するために、ユーザーのホームディレクトリにデータベースを自動的にインストールするGroovyスクリプトを使用しました。
@Grab(group='org.codehaus.plexus', module='plexus-archiver', version='2.10.2') import org.codehaus.plexus.archiver.tar.TarGZipUnArchiver import com.github.igorsuhorukov.smreed.dropship.MavenClassLoader; @Grab(group='org.codehaus.plexus', module='plexus-container-default', version='1.6') import org.codehaus.plexus.logging.console.ConsoleLogger; def artifact = 'crate' def version = '1.0.4' def userHome= System.getProperty('user.home') def destDir = new File("$userHome/.crate-io") def crateIoDir= new File(destDir, "$artifact-$version"); if(!crateIoDir.exists()){ destDir.mkdirs() String sourceFile = MavenClassLoader.using("https://dl.bintray.com/crate/crate/").getArtifactUrlsCollection("io.crate:$artifact:tar.gz:$version", null).get(0).getFile() final TarGZipUnArchiver unArchiver = new TarGZipUnArchiver() unArchiver.setSourceFile(new File(sourceFile)) unArchiver.enableLogging(new ConsoleLogger(ConsoleLogger.LEVEL_DEBUG,"Logger")) unArchiver.setDestDirectory(destDir) unArchiver.extract() } def proc = "$crateIoDir.absolutePath/bin/crate".execute() proc.consumeProcessOutput(System.out, System.err) proc.waitFor()
Dockerコンテナでデータベースを起動するか、 他の多数の方法で起動します。
おわりに
プロジェクトでCrateDBを使用する場合、まず、Elasticsearchに基づいた分散データベースであるため、完全なACIDがないことに注意する必要があります。 しかし、水平方向のスケーラビリティ、フルテキスト検索、およびSQLクエリを実行する機能が重要な場合、これはプロジェクトデータを保存するための優れた候補です。 幸いなことに、プロジェクトは飛躍的に発展しており、Apache 2.0ライセンスで使用できます。