
最近では、Amazon S3サービスの問題により、実際の「クラウド」が発生しています。 誤動作により、これらのAmazonクライアント企業の多数のサイトとサービスが低下しました。 問題は2月28日の夕方に始まり、ソーシャルネットワークから学ぶことができました。 その後、アイドルQuora、IFTTT、Sailthru、Business Insider、Giphy、Medium、Slack、Courserなどに関するメッセージが大量に表示されるようになりました。
サービスとサイトがクラッシュしただけでなく、多くのIoTデバイスがインターネット経由で制御することが不可能であることが判明しました(特に、IFTTTが無効になっているため)。 最も興味深いのは、最後の瞬間までAmazon S3のステータスが通常どおり表示されたことです。 しかし、リソースが問題の影響を受けた数百、または数千もの企業は、遅かれ早かれ、非常に信頼性の高い「クラウド」でさえも破綻し、全員が破片で覆われることに気付きました。 この状況でできることはありますか?
情報セキュリティの専門家はイエスと言います。 どうやって? これはより複雑な質問であり、複数の回答を一度に与えることができます。
サーバーが動作するクラウドが落ちた場合のサーバーの問題を回避する方法は、稼働時間と「ストレス耐性」を高めるためにデータセンターで使用される方法(たとえば、さまざまなシステムの複製)とは大きく異なります。 サービスとリモートデータを保護するために、さまざまな地域のデータセンターの仮想マシンでホストされているコピーを使用したり、複数のデータセンターにまたがるデータベースを使用したりできます。
この方法は、1つのプロバイダーとの連携の一部として使用できますが、AWSに加えて、Microsoft AzureやGoogle Cloud Platformを含む他のクラウド企業のサービスを使用する方が信頼性が高くなります。 これがより高価であることは明らかですが、ここでは、通常の場合のように、ゲームがろうそくに値するかどうかを検討する価値があります。 たとえば、サービスまたはサイトが継続的に機能する必要がある場合は、そのような予防措置を講じることができます。 「曇り」アーキテクチャ、それはそれが呼ばれることができるものです。
多くの場合、CloudflareのようなCDNプロバイダーのサービスを使用して自分自身を保護することができます(ちなみに、他の会社によって保存されている重要なデータのコピーを保存します)
Amazon S3の崩壊後、Cloudflareを使用していたAWSのお客様にはほとんど問題がありませんでした。

2006年にすべてがS3で始まったことを思い出してください。 Amazonが開始した最初の公共サービスは、クラウドファイルストレージでした。 仮想コンピューター(EC2)はずっと後に登場しました。
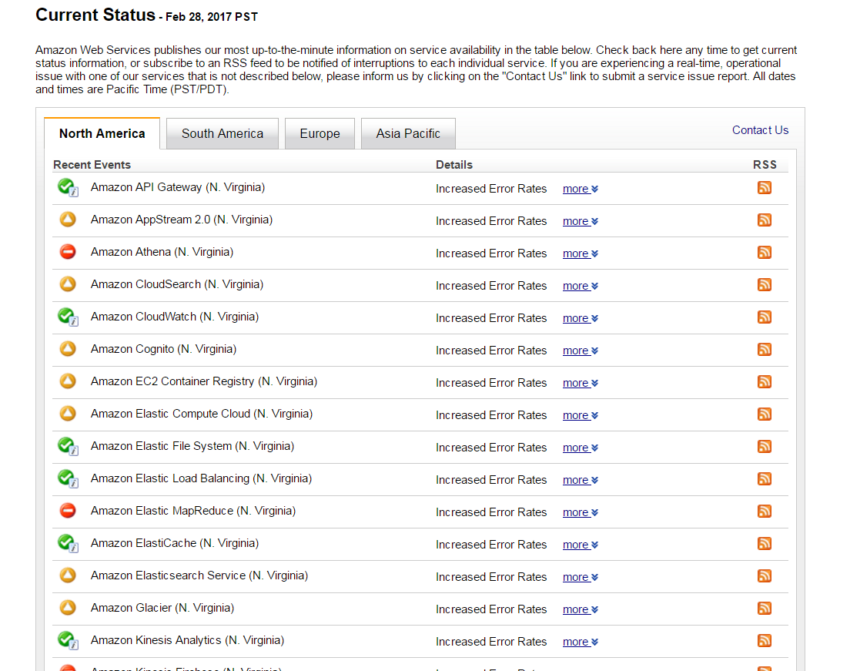
これは、Amazonクライアントの別のスクリーンショットです。ロシアのIT企業です。 45のサービスが機能しませんでした。

データはトラック(Amazonからも)に保存できますが、これが常に答えとは限りません
現在、マルチクラウドインフラストラクチャは、サービスとサイトが常に機能している企業の数が増え始めています。 もちろん、複製には費用がかかりますが、場合によっては、サービスのダウンタイムによる損失が複製のコストを大幅に上回る可能性があります。 今日、クラウド情報の複製とこのデータのセキュリティ、クラッカーからの保護-これらは2つの主要な問題です。
アナリストは、多くの企業が1つの企業の同じクラウド内にとどまりたくないため、異なるクラウドでシステムを複製しようとしていると言います。 そして、この傾向はますます明らかになっています。
ちなみに、マルチクラウドは必ずしも万能薬ではありません。 たとえば、今では多くの企業が、こうした仕事のモデルを使用していると主張しています。 ただし、同時に、異なるクラウドを異なる目的に使用できます。 たとえば、AWSは開発とテスト用であり、Googleのクラウドはサービスを展開して継続的な運用を保証するためのものです。
前のものに関連するもう1つの傾向は、Docker、Kubernetes、MesosphereのDC / OSなどのコンテナオーケストレーションツールの数の増加です。 また、マルチクラウドインフラストラクチャの原理は、通常の場合よりも整理しやすいため、作業中にテストする必要があります。
人的要因
これは、いつものように、主な問題です。 アマゾンのサーバーをクラッシュさせたのはその人だったが、同社はそのウェブサイトで認めた。 エンジニアのチームは、課金システムのデバッグに取り組みました。そのためには、多数のサーバーをオフラインにする必要がありました。 タイプミスのため、当初必要だったよりもはるかに多くのサーバーがこのモードに転送されました。
大災害と呼ぶのは難しいですが、大規模な地域のメタデータ管理システム全体が失敗しました。 Amazonは、タイプミスが発生した場合に誤ったシャットダウンコマンドを排除する設定を追加することで、サーバーを保護しています。
しかし、将来私たちを待っているものを知っている人はいますか? そして、ここで、マルチクラウドはその最良の側面を示すことができ、労働条件で事前に安全を大事にしている企業のサービスとサイトを残します。
