このゲームでは、2人の男がこのように戦っています。

それらは座標軸上にあり、ある程度のヘルスリザーブがあり、「クールダウン」パラメーターもあります。 クールダウン-これは、ファイターがこのアクションを実行したために逃すバーの数です。 たとえば、アクション「go」はクールダウン2を引き起こし、アクション「stab」はクールダウン4を引き起こします。クールダウンがゼロになったときにのみ動作できます(ゼロに等しくない場合は1単位減少します)。
そのため、2人の戦闘機がいます。 それぞれに座標、ヘルス、クールダウンがあります:
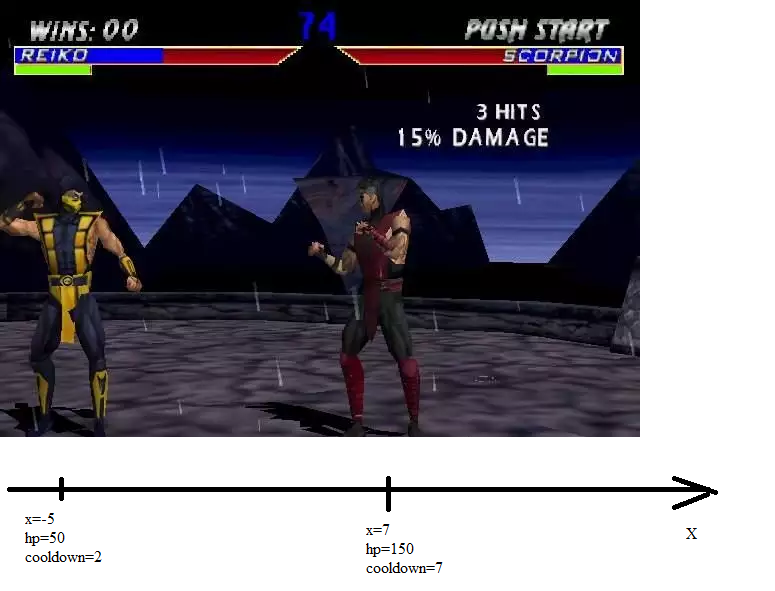
各ファイターは、自分の順番で6つのアクションのいずれかを実行できます。
1)1で右に進みます(クールダウン2を呼び出します)
2)1で左に移動します(クールダウン2を呼び出します)
3)待機(クールダウン1を呼び出します)
4)ナイフストライク(クールダウン4を引き起こす。敵までの距離が1以下の場合、20のダメージを与える)
5)クロスボウショット(クールダウン10を引き起こす;最大5セルのダメージを与える;最大12セルの4ダメージを与える)
6)中毒(クールダウン10を引き起こします。最大8セルの距離で2つのダメージと毒を与えます。毒された敵は毎ターン1馬力を失います。中毒は戦闘終了まで続き、2回毒することはできません)
入り口で、各戦闘機は次の情報を受け取ります。x、hp、および状態は毒されており、自分と相手について毒されていません。 さらに、敵のクールダウン値が到着します。 出力では、各戦略は1から6までの数字を与えます。
ニューラルネットワークが戦略を実装する場合、6つの数値を生成します。各数値は、「私が望む限り、そのようなオプションを実装する」ことを意味します。 たとえば、ニューラルネットワークが0 0 1 0 -1 0を生成した場合、シーケンスの3番目の要素の値が最も大きいため、アクション3を選択することを意味します。
1つの戦闘は70ティック続きます(または、これが早く発生した場合、ある戦闘機が別の戦闘機を殺すまで)。 70小節は7ショットまたは35ステップです。
AIファイターの品質指標を決定します。 1回の戦闘でのニューラルネットワークのゲームの品質= -100-(どれだけの体力を失ったか)+(敵が体力をどれだけ失ったか)を想定しています。 私のオプティマイザーは負の値のみを最大化するため、100未満が必要です。
q = -100-(入力(3)-単位(1).hp)+(入力(4)-単位(2).hp);
この戦略のパラメーターは、ニューラルネットワークの重みとシフトです-AIのテストは次のとおりです:重みのセットがニューラルネットワークに読み込まれ、このニューラルネットワークはしばらくの間敵と戦ってから、品質評価を受け取ります。 オプティマイザーは、結果の品質を分析し、新しい重みのセットを生成し(おそらく最高の品質を提供します)、サイクルを繰り返します。
このゲームの重要な要素は、ニューラルネットワークの係数に対する品質メトリックの段階的な依存性です。

なぜそう ニューラルネットワークが次の出力ベクトルを生成したとしましょう:0 0 1 0 00。そして、1つのパラメーターをわずかに変更しました。 そして、次のような出力ベクトルを得ました:0 0 0.9 0 00。または0.1 -0.1 0.9 0 0 -0.1。 同時に、ニューラルネットワークはオプション3に投票し、引き続きオプション3に投票します。
つまり、小さな変更(勾配降下など)に基づく最適化方法はここでは機能しません。
一連の戦闘の結果としてのAIの品質は、すべての戦闘の平均品質に、2で割った最悪の品質を加えたものと見なされます。
q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.00001;%sum(abs(k)) – . , – .
なぜ最悪なのですか? 次に、ニューラルネットワークが1つのまれなケースで完全にプレイする方法を学習せず、他のすべてのケースでプレイがうまくいかず、そのために「平均」ポイントを大量に受け取らないようにしました。 なぜ平均を取るのですか? 次に、評価に関与するニューラルネットワークの選択肢が多いほど、これは大きくなります。
次のようになります。

また、2番目のオプションは、最初のオプションよりも小さな変更を使用して最適化する方がはるかに簡単です。
一連のテストを実施します。 品質メトリックは約-100のままです。 つまり、AIは戦わなかった。 まあ、何? 逃げることを学ぶことは、勝つことを学ぶことよりもはるかに簡単です。
制限を導入します。 戦闘機がアリーナを超えたとき(-20から20倍まで)、彼は死にます。 実行中の「ステップバックではない」注文。
はい、手書きボットの戦略について話し合いましょう。その中にはいくつかあります。
手書きボット「グラディエーター」。 和解に行きます。 彼がナイフで敵に到達した場合、彼はヒットします。 敵を1発で殺すことがわかった場合にのみ撃ちます(これはほとんど起こりません)。
AIは、15分間のトレーニングの後、負けるよりも勝ち始めるようになりました(メトリック:-95.6)。 さらに1分後、彼はスキルを向上させました(メトリック:-88)。 さらに1分後、メトリックは-77.4でした。 1分で-76.2。
彼が勝つ方法を確認してください。 戦いを始めます。
Gladiatorの座標は10、hp = 80、ニューラルネットワークの座標は-9、hp = 80です。
剣闘士が前進し、ニューラルネットワークが静止し、ナイフで空中に息を吹き込みます。 剣闘士が中毒のラインに到達するとすぐに、ニューラルネットワークが起動します。 その後、クールダウンが経過すると、ニューラルネットワークは無用にナイフを振り続けます...毒は8個の細胞で発生します。 8つのセルを通過するには、16の動きを費やす必要があります。 ナイフで刺すのは4手です。 16は4で完全に割り切れます。これは、剣闘士がニューラルネットワークのポイントブランクに近づくと、剣闘士の前で刺すことを意味します。 実際、AIはナイフストライククールダウンをタイマーとして使用しました。 現在、ヘルス比は80:34であり、グラディエーターに有利ではありません。 ニューラルネットワークがクロスボウから発砲した場合(ナイフで空中を突き刺すよりも合理的と思われる)、先制攻撃のチャンスを逃します。
スコアが45:5の時点で時間が経過し、ニューラルネットワークに有利になりました。
新しい手書きボットをいくつか作成します。
手書きボット「Stormtrooper」。 和解に行きます。 毒で中毒し、敵がまだ毒されていない場合、毒を使用します。 クロスボウから短距離(5ユニット)でシュートする場合、シュートします。 敵がポイントに近づいた場合、ナイフを適用します。
手書きボット「シューター」。 和解に行きます。 彼が少なくとも何らかの形で石弓から撃つ場合-撃つ。 毒で中毒し、敵が毒されていない場合、毒を使用します。 ナイフで仕上げる場合は、ナイフを使用します。
手書きボット「タワー」。 近づかない 彼が少なくとも何らかの形で石弓から撃つ場合-撃つ。 毒で中毒し、敵が毒されていない場合、毒を使用します。 ナイフで仕上げる場合は、ナイフを使用します。
そして、ニューラルネットワークを離れて、夜に彼らと戦う。 ユーティリティ機能をよりスムーズにするために、1つのテスト(70ではなく85)でより多くのテスト(13個)とより多くのメジャーを設定します。
したがって、これはすべてゆっくりと動作するようになりますが、適切な最適値を見つける可能性はもっとあると思います。
午前10時30分 ネットワークトレーニングの品質を確認します。 -90.96。 最悪の場合、メトリックは-100です(つまり、AIとその敵はお互いに等しいダメージを与えます)。 平均的なケースでは、-81.9231、つまり、AIはさらに18のダメージを与えました。
ニューラルネットワークがさまざまな種類のボットとどのように戦うかを見てみましょう。
1)グラディエーター。 初期座標:ニューラルネットワークで-9、グラディエーターで10。 グラディエーターは近づいていますが、ニューラルネットワークはボイドに向かっています。 したがって、ニューラルネットワークはほとんどの場合、大きなクールダウンを伴います。 そして...グラディエーターがニューラルネットワークから9の距離にあるとき、クールダウンは終了し、ニューラルネットワークは待機していました。 撃ちません。 剣闘士は彼の動きを作り、ニューラルネットワークはすぐに彼を毒します。 グラディエーターがニューラルネットワークから4の距離に到達するまでに、中毒後のクールダウンが経過しました。 ニューラルネットワークはナイフでボイドに突き刺さります。そして、剣闘士が攻撃の距離に近づくと、クールダウンが終了します。 ニューラルネットワークが最初にヒットし、次に打撃の交換が開始されます。 85サイクルには有効期限がありません-ニューラルネットワークがグラディエーターを殺しました。 剣闘士は-18馬力、ニューラルネットワークは40馬力です。違いは58ユニットです。
2)航空機を攻撃します。 初期座標:ニューラルネットワーク5、Sturmovik -10。 攻撃機は攻撃を続け、ニューラルネットワークは静止し、ナイフを振ります。 攻撃機がポイズンゾーンに入るとすぐに、ニューラルネットワークはポイズンを使用します。 そして、攻撃機のコードと他のすべてのボットのコードにエラーがあることに気付きました。 このエラーのため、彼らは毒を使用できません。
しかし、私はAIがTowerボットで何をするかを理解しています。 はい、面白いことは何もありません-彼はただ彼と戦っていないだけです。 どうやら、防衛ゲームは非常に優れているため、ニューラルネットワークはこの戦略に反対しようとはせず、単に関与しているだけではありません。 そして、ゲームは引き分けで終了します。
そこで、11:02に毒を使用できるように戦略「Sturmovik」、「Shooter」、「Tower」を完成させ、トレーニング用のニューラルネットワークを立ち上げました。 品質メトリックはすぐに-107に低下しました。
11:04に最初の改善が行われました。メトリックは-97.31に達しました。
それだけです。 最悪の結果は-100よりも悪いため、11:59にゼロから検索を再開します。
マルチスタートと主要な進化の後、メトリックは-133前後でした。 12:06に、メトリックはすでに-105.4でした。
しかし、その後、メトリックは何とかゆっくりと成長しました。 何が問題なのか調べることにしました。 もちろんです! ニューラルネットワークは、-20から20の間隔でさえ逃げることを学びました。そして、ほとんどの戦いは引き分けに終わりました。 いくつかの戦闘では、AIは何らかの理由で退却できず、その有効性は-53(敵を破片にする)から-108(中程度の敗北)の範囲でした。
戦場のサイズを小さくします。 -10から+10までのセグメントとします。 そして、私たちはセンターを保持できる人に報酬を与えます-1つの保持に対して1ポイント。 ニューラルネットワークの中心あたりのポイント数は、戦闘ごとのメトリックに追加され、敵の中心ポイントの数が差し引かれます。
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp)+(center.me-center.enemy);
そして、16:06にゼロからトレーニングを開始します。 マルチスタートと主要な進化の後、私は-126の品質を取得します。
翌日の9:44に、-100.81の品質が得られます。 つまり、ボットは平均して勝ちますが、時々負けます。 私たちは、彼がさまざまな試験でどれだけ利益を得たかを調べます。
-45-98 -108-99-100-100 -76 -104-100-100 105 -99-96
3敗、2引き、6勝。 ニューラルネットワークが失われる状況を見てみましょう。
バトルナンバー3、最も負けた。 ニューラルネットワークと敵の初期座標は-9と9です。ヘルス-それぞれ80、敵の戦略-Sturmovik。
最初に、ニューラルネットワークがボイドに撃ち込み、攻撃機が中毒距離に近づくまで待機し、戦闘機が中毒を交換します(ニューラルネットワークは先に撃つため、敵の5馬先です。なぜ2ではなく5であるかわかりません)、ニューラルネットワークが起動します敵を待っている間にナイフを振るのはすでに通常の方法です。その結果、攻撃機はクロスボウから近距離に到達し、ニューラルネットワークを撃ちます。 このショットは致命的でした。 合計、Sturmovikは5馬力、ニューラルネットワークは0です。さらに、Sturmovikは中心を通過するために3ポイントを受け取りました。
-104ポイントは、7回目の戦闘でネットワークがノックアウトしたことを示します。 ニューラルネットワークと敵の座標はそれぞれ-6と9で、両方とも400馬力で、敵の戦略はStrelokでした。
神経回路網がナイフを振りながら、射手は攻撃を続けます。 その結果、ニューラルネットワークはショットの最適なタイミングを逃し、敵はイニシアチブを傍受します。 これに長時間の銃撃戦が続き、シューティングゲームはニューラルネットワークよりも1ショット多く処理することができます。 クロスボウからの長距離ショットはわずか4馬力を撃ちます。
-105ポイントは、9回目の戦闘でネットワークがノックアウトしたものです。 ニューラルネットワーク140 hp、敵40、敵戦略-Sturmovikの場合、ニューラルネットワークと敵の座標はそれぞれ-1と9でした。 ニューラルネットワークはナイフで待機し、毒の使用に最適な瞬間を逃します。 攻撃機は、毒を発射する最初のものです。 その結果、彼はニューラルネットワークよりも5つ多くの損害を与えました。
中間結論。
最初に、ニューラルネットワークは攻撃しませんが、防御側に位置し、次に、次善の方法を期待します;待機ボタンを押す代わりに、ヒットボタンを押します。
「タワー」戦略では、ニューラルネットワークが既にショット距離にある場合にのみ戦います。 戦略「グラディエーター」ニューラルネットワークは引き裂かれます。-45と-76はまさにその上に詰め込まれています。 戦略「攻撃機」および「射手」は、最初に撃ち、毒または撃ち数のいずれかで有利になるという事実により、ニューラルネットワークを打ち負かします。
まあ、そのようなAIでさえ長い間研究されてきました。 そして残り...実際、これは個別の意思決定を行うAIであり、機能するのではなく機能します。
バーサーカーニューラルネットワーク
私がこのAIを軍から帰ってきたばかりの友人に話したとき、彼は私の品質指標に非常に驚いていました。 彼は、退却を撃ったことは悪い決断だったと言いました。 HPを節約するよりもAIに敵へのダメージを考慮させる方が良いでしょう。
彼を血に飢えさせてください!
つまり、修正します。
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp);
これに:
q=-100-(input(3)-units(1).hp)+2*(input(4)-units(2).hp); %2 –
次に、このメトリックは、損害の単位を取得した場合に1罰金を科し、1単位を処理した場合に2を報奨します。
最初からトレーニングを開始します。 バーサーカーを作成する前に、プロセッサをより強力なものに変更し、ニューラルネットワークのより高速な実装を作成することができたため、すべてのトレーニングは20分で完了しました。20分-品質メトリックは-65 ... AIは本当にどれほどリアルですか?
非バーサーカーメトリックを返す
q=-100-(input(3)-units(1).hp)+(input(4)-units(2).hp);
そして恐ろしい。 「慎重な」指標は-117です;多くの戦いで、AIは失われたよりも少ないHPを取りました。 AIは血に飢えていることが判明-私は自分の馬力を完全に忘れていました。
メトリックを変更します
q=-100-(input(3)-units(1).hp)+1.7*(input(4)-units(2).hp); %1.7 –
そして、トレーニングを続けます。
約5分後、結果が表示されます:q = -75.75。
個々のテスト結果:
0 -91.2000 -76.3000 -49.300 -49.500 -29.5000 -87.200 -73.600 -64.00 -57.00 -82.0000
再度、メトリックを「慎重」に変更し、結果を確認します。
Q = -114.98。 11の戦闘のうち、AIは負けます。
AIが1つの敗北、つまり11の戦闘の1つが-100未満のスコアで終了するように、攻撃性係数のこのような値を選択します。 一方で、AIが攻撃と同じように勝利と敗北を理解できるように、攻撃からAIを再生し続けるためにこれを行いたいと思います。 生物学の観点から、私は現在、AIの進化の軌跡を設定しています。
したがって、1.18のアグレッシブネスファクターでは、AIは、それが時々失われることを既に理解していますが、それでもどのくらいの頻度かを理解していません。
トレーニングを継続します。
30分後、q = -96に達します。
「慎重な」メトリックを返し、q = -106.23を取得します
AIがどのバトルで獲得したポイントを調べます。
-44-94 -119 -99 -110 -75 -104 -96 -95 -93 -96
負け:3バトル。 勝った:8戦。 引き分け:0。これは、3敗、2引き、6勝よりも優れており、攻撃性のないテストで判明しました。
AIが最後から3回目の戦いでどのように勝ったかを見てみましょう。攻撃せずに負けました。
この戦いの敵のタイプはスターモビックです。 最初に、戦闘機は、クロスボウからロングショットを発射する可能性を無視して、近づきます。 それから、彼らはできるだけ早く互いに毒します(AIは以前にこれを行い、この統一xnのために勝ちます)。 その後、AIはクロスボウを発射し(遠距離でペナルティを科します)、攻撃機は接近戦に突入します。 Sturmovikが狙撃の距離(5ステップ)に到達するまでに、AIはすでに充電され、再び撃たれていました。 攻撃機は生き残りませんでした。
AIがどのように失うかを見てみましょう。 戦闘番号3を開始します。敵は再び攻撃機です。
前回同様、敵は有毒ショットの距離で収束しますが、今回は攻撃機が最初に撃ち、1馬力(エラー番号1)の利点を得ることができました。 その後、戦闘機は収束を続け、銃撃戦はクロスボウで始まります。 AIは急いで、敵が狙った射撃ゾーンに来る前に最初の砲弾が発砲しました(エラー番号2)。 彼は少し前にダメージを与えましたが、Sturmovikは一歩前進し、4ではなく10のダメージを与えました。さらなる銃撃戦の間に、SturmovikはAIを首尾よく殺しました。
結論
この実験から、次の結論を導き出します。
1)自動操縦の作成に適したAIの作成方法は、戦闘ロボットの作成にも適しています。
2)場合によっては、AIが特定の目標を達成するために、より達成可能な目標と呼ばれ、目標を達成したい目標に徐々に置き換える必要があります。
3)ステップ関数の最適化は、スムーズよりもはるかに困難です。
4)11ニューロンの3層-これは、7つのセンサーと6つの出力を持つロボットを制御するのに十分です。 通常、33個のニューロンでは、同様の次元のタスクには不十分です。
機能コード
1つの戦闘をシミュレートする機能:
function q = evaluateNN(input_,nn) units=[]; %input_: AI.x, enemy.x, AI.hp, enemy.hp, enemy.strategy units(1).x=input_(1); units(1).hp=input_(3); units(1).cooldown=0; units(1).poisoned=0; units(2).x=input_(2); units(2).hp=input_(4); units(2).cooldown=0; units(2).poisoned=0; me=1; enemy=2; center.me=0; center.enemy=0; for i=1:85 if(units(1).cooldown==0 || units(2).cooldown==0) cooldown=[units(1).cooldown;units(2).cooldown]; [ampl,turn]=min(cooldown); %choose if(turn==me) %me answArr=fastSim(nn,[units(me).x;units(me).hp;units(me).poisoned; units(enemy).x;units(enemy).hp; units(enemy).poisoned;units(enemy).cooldown]); [ampl, action] = max(answArr); else if(turn==enemy) %enemy action=3; if(input_(5)==0)%Human player units(1),units(2) 'Player2: 1: x++, 2: x--, 3: wait, 4: knife, 5: crossbow, 6: poison' action=input('Action number:') end; if(input_(5)==1)%gladiator if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=5 && units(enemy).hp<=10) action=5; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==2)%stormtrooper if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=5) action=5; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==3)%archer if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(abs(units(me).x-units(enemy).x)<=12) action=5; elseif(units(enemy).x>units(me).x) action=2; else action=1; end; end; if(input_(5)==4)%tower if(abs(units(me).x-units(enemy).x)<=1) action=4; elseif(abs(units(me).x-units(enemy).x)<=8 && units(me).poisoned==0) action=6; elseif(abs(units(me).x-units(enemy).x)<=12) action=5; else action=3; end; end; end; end; %actions %move if(action==1) if(turn==1) another=2; else another=1; end; if(units(turn).x+1~=units(another).x) units(turn).x=units(turn).x+1; end; units(turn).cooldown=units(turn).cooldown+2; end; if(action==2) if(turn==1) another=2; else another=1; end; if(units(turn).x-1~=units(another).x) units(turn).x=units(turn).x-1; end; units(turn).cooldown=units(turn).cooldown+2; end; if(action==3) %pause units(turn).cooldown=units(turn).cooldown+1; end; %knife if(action==4) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=1) units(another).hp=units(another).hp-20; end; units(turn).cooldown=units(turn).cooldown+4; end; %crossbow if(action==5) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=5) %meely units(another).hp=units(another).hp-10; elseif(abs(units(turn).x-units(another).x)<=12) %long-range units(another).hp=units(another).hp-4; end; units(turn).cooldown=units(turn).cooldown+10; end; %poison if(action==6) if(turn==1) another=2; else another=1; end; if(abs(units(turn).x-units(another).x)<=8) units(another).hp=units(another).hp-2; units(another).poisoned=1; end; units(turn).cooldown=units(turn).cooldown+10; end; else units(1).cooldown=units(1).cooldown-1; units(2).cooldown=units(2).cooldown-1; end; if(units(me).poisoned>0) units(me).hp=units(me).hp-1; end; if(units(enemy).poisoned>0) units(enemy).hp=units(enemy).hp-1; end; if(units(me).hp<=0) break; end; if(units(me).x==0) center.me=center.me+1; end; if(units(enemy).x==0) center.enemy=center.enemy+1; end; if(abs(units(me).x)>=10) units(me).hp=0; break; end; if(units(enemy).hp<=0) break; end; end; q=-100-(input_(3)-units(1).hp)+1.0*(input_(4)-units(2).hp); if(q>0) q=0; end; end
一連の戦闘を行う機能:
function q = testSeria(k) global nn sum_=0; countOfPoints=0; nnlocal=ktonn(nn,k); arr=[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20]; %% input=[[-3.,9.,80,80,1];[-2.,8.,10,10,2];[-4.,3.,60,60,4];[-4.,8.,20,20,3];[-2.,9.,15,15,2];[5.,-8.,100,100,4];[-5.,0.,50,50,1];[-5.,4.,80,80,2];[4.,7.,70,100,3];[7.,-6.,10,10,3];[-1.,9.,140,140,3]]; %input=[-3.,9.,80,80,0];%Player 2 is a human sz=size(input); for (i=1:sz(1)) val=evaluateNN(input(i,:),nnlocal); sum_=sum_+val; arr(i)=val; end; countOfPoints=sz(1); q=(min(arr)+sum_/countOfPoints)/2 - sum(abs(k))*0.001; end
ニューラルネットワークを実行する関数:
function arr = fastSim(nn,input) %fast simulation for fast network sz=size(nn.LW); sum=cell([1,sz(1)]); LW=nn.LW; b=nn.b; sum{1}=nn.IW{1}*input; arr=sum{1}; for i=1:sz(1)-1 sum{i+1}=tansig(LW{i+1,i}*(sum{i}+b{i})); end; arr=sum{sz(1)}; end
ニューラルネットワークを最適化するには、一連の数値をニューラルネットワーク係数に変換する関数が必要です。
function nn = ktonn(nn,k) %neuro net to array of koefficients ksize=size(k); if(ksize(2)==1) k=k'; end; bsz=size(nn.b); counter=1; for i=1:bsz(1)-1 sz=size(nn.b{i}); nn.b{i}=k(counter:counter+sz(1)-1)'; counter=counter+sz(1); end; lsz=size(nn.LW); for i1=1:(lsz(1)-1) x=i1+1; y=i1; szW=size(nn.LW{x,y}); nn.LW{x,y}=reshape(k(counter:counter+szW(1)*szW(2)-1),szW(1),szW(2)); counter=counter+szW(1)*szW(2); end; sz=size(nn.IW{1}); arr=k(counter:counter+sz(1)*sz(2)-1); arr=reshape(arr,sz(1),sz(2)); nn.IW{1}=arr; end
Main.m:
clc; global nn X=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]]; Y=[[(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)], [(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5);(rand()-0.5)]]; nnBase=newff(X,Y,[11,11,11],{'tansig' 'tansig' 'tansig'},'trainrp'); nn.b=nnBase.b; nn.IW=nnBase.IW; nn.LW=nnBase.LW; f=load('./conf.mat'); k=f.rtailor; q=testSeria(k)
ネットワーク構成ファイル 。 残念なことに、私はそのファイルを勝ち取ったAIで失いましたが、これはそれほど悪くはありません。
希望する場合は、AIと対戦できます。この場合、Test Seriaの行のコメントを解除する必要があります。
input = [-3.、9.、80.80.0];%Player 2は人間です