
しかし、まず、主なことを理解する必要があります。ネットワークがない場合、検索結果のサイトがまだ利用できないのに、なぜオフライン検索を開始したのでしょうか?
エッジ検索
Yandexのレーダーでは、リクエストを入力した後、モバイルインターネットの品質が悪いためダウンロードを待たずにページを離れる人々が、従来から目に見えています。 この状況では、ネットワークの全体的な品質とすべてのサイトのダウンロード速度に影響を与えることはできませんでしたが、検索プロセスの痛みを軽減し、時間を節約するには試してみる価値がありました。 実際、それがこのプロジェクトが元々EDGE検索と呼ばれた理由です。 遅いインターネットで検索してください。
検索を高速化するには2つの方法があります。 最初に、アプリケーションが使用するWebバージョンとAPIを最適化します。 この作業も進行中ですが、これでも十分ではありません。 第二に、接続不良の場合に役立つものをデバイスにプリロードできます。 明らかに、インターネットインデックス全体を電話に合わせるのは物理的に不可能です。 したがって、特定のクエリの既製の検索結果のローカルストレージの側面から移動する必要がありました。 何で? 人の将来の要求を高い精度で予測する方法は誰も知りません(しかし、私たちは学習しています)。 そのため、人気のある繰り返しリクエストを受け付けます。
人気のあるクエリについて話すとき、多くの人がクエリ[VKontakte]といくつかの類似したクエリを想像します。 実際、大量に定期的に繰り返される数十万のあまり明らかでないクエリがあります。 そして、これは数百メガバイトの結果です。 さらに、検索結果だけでなく、クエリの入力プロセスで表示されるヒントも保存することを計画しました。 そして、ここで多くの人が尋ねます:なぜオフラインプロンプトを保存しますか?
Yandexアプリケーションにクエリを入力すると、ユーザーには通常の検索ヒントではなく、個別の単語/単語のペア(つまり、 予測テキスト入力 )が表示されます 。 通常のヒントは編集できません。単語を追加する必要がある場合は、クエリ全体を自分で入力する必要があります。 単語の形式のヒントを使用すると、編集したり、はるかに多くのリクエストを処理したり、人による入力を大幅に加速したりできます。
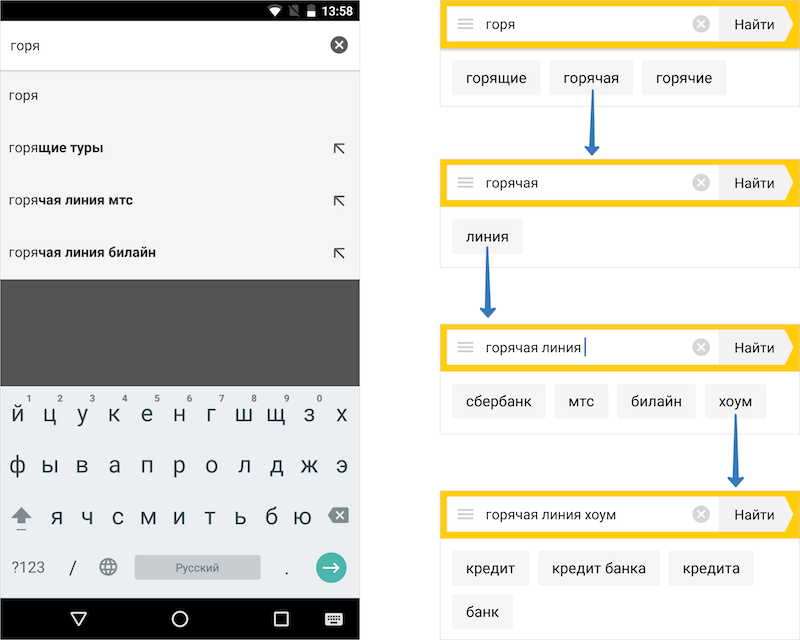
しかし、主なことは、オフラインで作業するときにヒントが特に有用だったことです。 これらのヒントは、人々が最もよく行う方法で質問を定式化するのに役立ち、これにより、回答がローカルキャッシュから受信される可能性が高くなります。 それがプロンプトを維持することが重要だった理由です。
経験的には、特定の最小検索クエリ(約15万件)とヒントをピックアップしましたが、それより少ないと格納する意味がなくなりました。 しかし、このすべての手荷物の量はまだまともな範囲(数百メガバイト)を超えていました。 リクエストごとに上位10件の結果のみが保存されたという事実を考慮しても。 何かをする必要がありました。
最適化からオフラインまで
彼らは「ナイフの下に」送られることができるすべてを探し始めました。 各結果には、サイトへのリンクだけでなく、ファビコンとスニペットも含まれていました。 ファビコンは写真であり、これはここで深刻な節約を達成できることを意味します。 まったく異なるクエリの結果に同じサイトが表示される場合があるため、最初はファビコンを複製せず、サイトに保存しました。 そして、ファビコンを保存する可能性が検索結果に表示されるサイトの頻度に直接比例するように作成しました。 つまり、ファビコンのほとんどを放棄しましたが、視覚的にはそれほど目立ちません。
ただし、 スニペットを拒否するのはそれほど簡単ではありません。これは、見出しよりも人々にとって重要な情報だからです。 多くの場合、スニペットには質問に対する回答が既に含まれています。 したがって、通常のクエリでは、最後の2つの結果のみからスニペットを破棄しました。 通常、最初の結果がクエリによく応答するナビゲーションの場合、スニペットの数を最初の3〜4に減らすだけでなく、結果自体を10サイトではなく5サイトに減らしました。同様に、 魔術師の答えがあるすべての結果を減らしました。
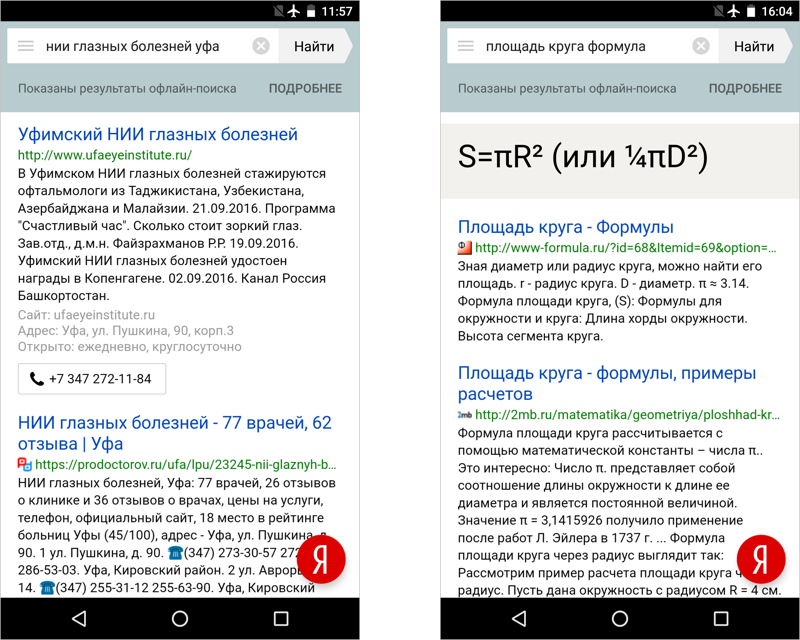
既成の回答を優先して通常の検索結果を減らすほど、EDGE検索はもはや作業を加速するだけでなく、インターネットに接続することなく幅広い質問に答えることができるという理解に近づきました。 気付かないうちに、私たちはすでにオフライン検索に取り組んでいました。 だから、既成の答えに賭ける必要があります。 これを実現するために、以前はリクエストの人気が限られていたためにそこに到達できなかった重要な事実でデータベースを充実させ始めました。 これらの結果には回答のみが含まれ、サイトは発行されません。
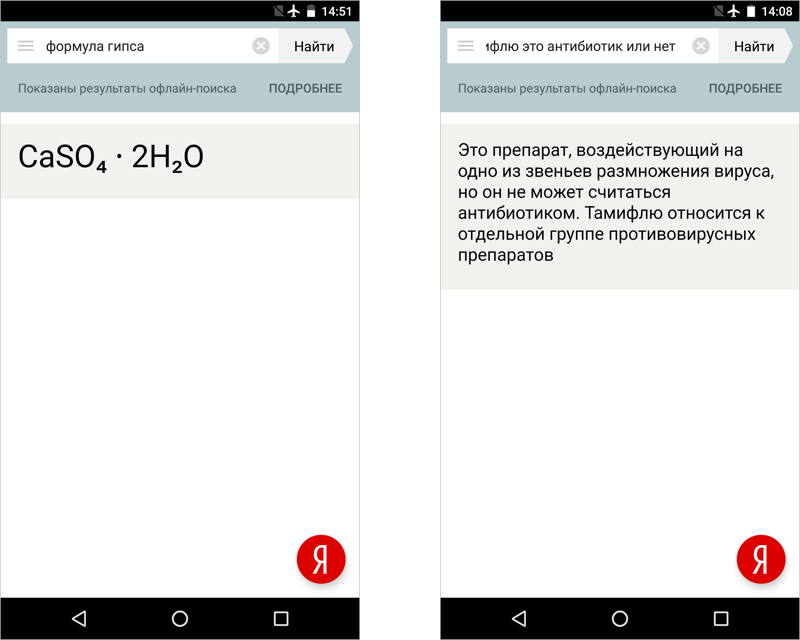
同様のスキームを使用して、すべてのオブジェクト応答カードと、オブジェクト応答がデータベースで利用可能なすべての要求をコピーしました。 オフライン検索中のカードは、写真がほとんど完全に存在しないという点でオリジナルと異なります。経済的な理由から削除しました。
ファクトベースの成長には、デバイスのリソースを慎重に扱うようなデータストレージ構造の最適化に関するさらなる作業が必要でした。
辞書
データベースは完全にデバイスにダウンロードされるのではなく、個別の辞書の形式で、Wi-Fi接続と十分な充電レベルでのみダウンロードされます。 辞書への分類は、2つの理由で行われます。 まず、ロード中に接続が切断された場合、次の試行中に、以前にダウンロードする時間がなかった辞書のみがダウンロードされます。 次に、スペースをさらに節約するために、データベースがダウンロードされ、圧縮された形式でデバイスに保存されますが、リクエストごとに完全に解凍されるのではなく、必要な部分のみが解凍されます。
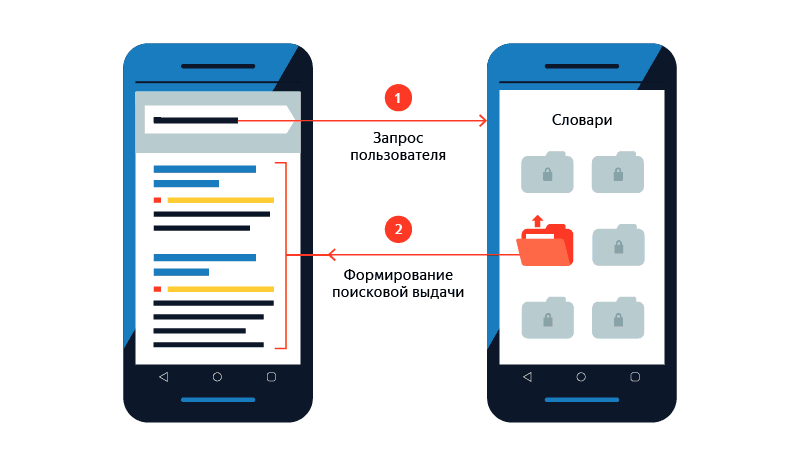
各辞書には、特定の文字で始まるクエリと、これらのクエリの発行およびヒントに関するすべてのデータが含まれています。 例えば、人気などよりも、クエリの最初の文字で正確に辞書に分割する前にデータをソートする方が論理的であることが判明しました。 状況を想像してください。最初の辞書では最も人気のあるクエリ、2番目の辞書では-少し人気が低いなどです。 ただし、クエリの人気は頻繁に変化するため、クエリを別のクエリに移動するためにのみ辞書を定期的に更新する必要が生じます。 これは、交通、エネルギー、時間のコストです。 したがって、データベースを更新するときに、クエリが辞書間で移動しないようにすることが重要でした。 アルファベット順は、シンプルで効果的なソリューションであることが証明されています。
同じ問い合わせに対する回答は国によって異なる場合があるため、辞書は地域ごとに作成されます。 さらに、別の地域への短期訪問のために、アプリケーションは辞書を更新するために急ぐことはありません-旅行と観光のシナリオを提供しました。
どんなに一生懸命試してみても、オフライン検索はすべての可能なクエリを網羅しているわけではありませんが、現在では平均して3分の1に役立ちます。 平均的な結果に関しては、これはユーザーの一部が他のユーザーよりもオフラインの回答に頻繁に直面することを意味します。 したがって、もちろん、設定でオフライン検索を完全に無効にすることができます。
私たちのチームは、この分野に関するHabr読者の意見を知り、Android向けのYandexベータアプリケーションの操作に関するフィードバックを得ることに興味があります。 ありがとう