
コグニティブサービスは、視覚、音声、テキスト情報を操作できるさまざまなクラウドサービスへのアクセスを提供します。 さらに、さまざまなBing検索機能を使用できます。
認知サービスを実際に試すには、Microsoftアカウントを持つ必要さえありません。 GitHubまたはLinkedInアカウントを使用して試用版キーを取得することもできます。 試用版サブスクリプションの期間は制限されていませんが、その期間に使用されるリソースの量には制限があります。 オンラインデモを表示するには、 Speaker Recognition APIにアクセスしてください。
以下は、Voice in Actionを使用してユーザー認証をテストする方法の説明です。 サービスもプレビュー状態ですが、それにもかかわらず、すでに非常に興味深いものです。
このサービスはさまざまなプラットフォームから使用できますが、C#/ XAML UWPアプリケーションの作成を検討します。
こちらから試用版キーを入手できます: Microsoft Cognitive Services-無料で始めましょう

[+]を押して、[ スピーカー認識-1か月あたり10,000トランザクション、1分あたり20のプレビュー]を選択します。
または、Azureアカウントからキーを取得できます(ただし、キーがない場合はどうなりますか)。 Cognitive Services APIを見つけて、Speaker Recognition APIタイプのアカウントを作成します。
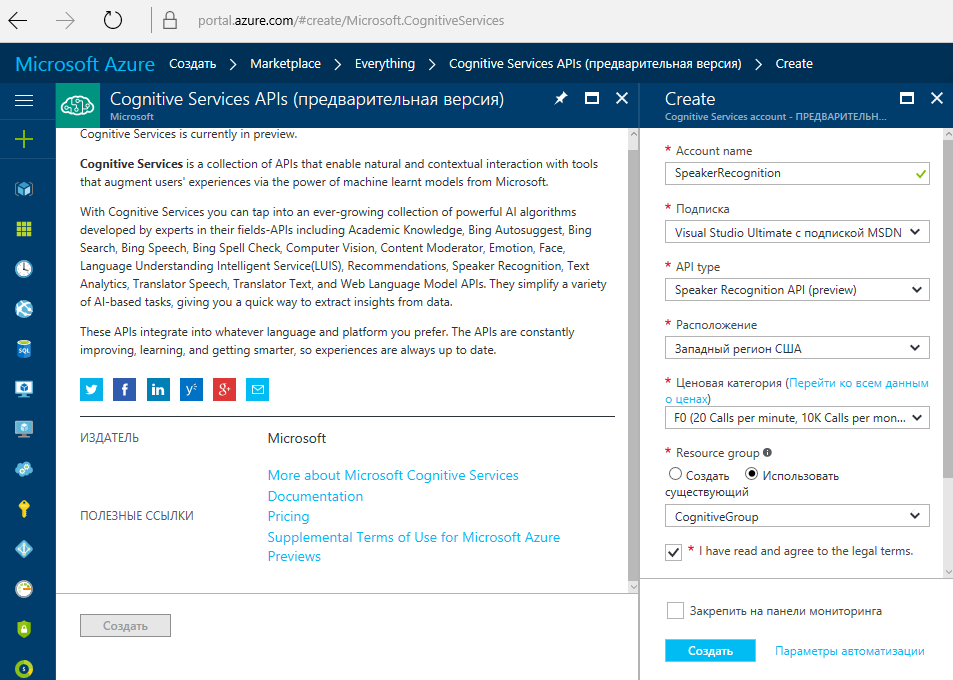
この方法は、試用機能のみで停止する予定がない人に適しています。
ここでキーを見つけることができます:
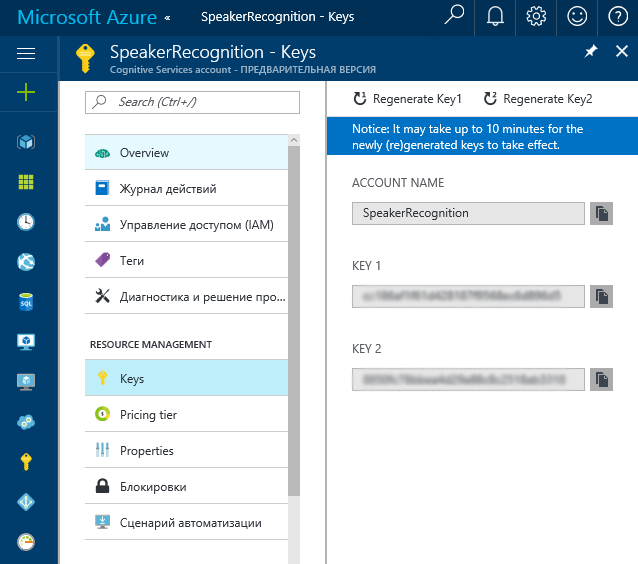
続行する前に、タスクの一部として用語を定義しましょう。
検証 -スピーチが特定の人によって配信されたことの確認。 スピーカーの身元の確認。
識別 -私たちに知られている多くのユーザーのどれがフレーズを発声したかを決定します。
登録 -サービスがユーザーの音声を認識するようにトレーニングするプロセス。 サービスが一定数のフレーズの例を受信すると、ユーザープロファイルが登録され、認識に使用できるようになります。
音声認識の構成とプロセスの説明
ユーザープロファイルが作成されます
登録が作成されます。 同じフレーズの繰り返しが何度もサービスに送信されます。
現在サポートされている言語は、en-US(米国英語)およびzh-CN(中国語)のみです。
英語のフレーズは、次のリストから選択できます。
「私は彼を拒否できない申し出にしよう」
「ヒューストンに問題がありました」
「私の声は私のパスポートです」
「歯磨き粉の後にリンゴジュースがおかしい」
「パスワードなしで入ることができます」
「セキュリティシステムを今すぐアクティブ化できます」
「私の声はパスワードよりも強い」
「私のパスワードはあなたのビジネスではない」
「私の名前は知らない」
「他のすべての人がすでに服用されている」
最初に話されるフレーズは、プロファイルに関連付けられています。 ResetEnrollmentsAsyncで登録をリセットすることによってのみ、フレーズを変更できます。
ロシア語の一連のフレーズがどのように見えるか想像してみましょう。 まず始めに、コメントでオプションを提案します。
「これはアントン・セメノビッチ・シュパクのアパートですか?」
「穏やかで、マーシャ、私はドゥブロブスキーです!」
「私は頭が良く、ハンサムで、適度に栄養が豊富な男です。満開です」
UWPアプリケーションの作成
UWPアプリケーションを作成して、次のMicrosoft.ProjectOxford.SpeakerRecognition NuGetパッケージを追加しましょう
マニフェストの機能セクションにマイクを追加します。 インターネット(クライアント)はデフォルトで追加する必要があります。 設定が完了し、コードに進むことができます。 サービスを操作するために必要な名前空間のリスト:
using Microsoft.ProjectOxford.SpeakerRecognition; using Microsoft.ProjectOxford.SpeakerRecognition.Contract; using Microsoft.ProjectOxford.SpeakerRecognition.Contract.Verification;
オーディオを操作するために必要な名前空間:
using Windows.Media.Capture; using Windows.Media.MediaProperties; using Windows.Storage.Streams;
サービスを使用するには、いくつかのオブジェクトを作成する必要があります。 サブスクリプションキーとクライアント検証を含む行。 クライアントはサービスと対話します
private SpeakerVerificationServiceClient _serviceClient; private string _subscriptionKey;
ページが初期化された後、これらの変数を初期化する必要があります。
_subscriptionKey = "ec186af1f65d428137f9568ec8d896b5"; _serviceClient = new SpeakerVerificationServiceClient(_subscriptionKey);
_subscriptionKeyを使用して、サブスクリプションキーを指定します。 論理的に、ユーザープロファイルを作成する必要があります。
CreateProfileResponse response = await _serviceClient.CreateProfileAsync("en-us");
サービスの応答から、プロファイル識別子を取得できます。
String _profileId=response.ProfileId;
次のステップは、音声認識の「トレーニング」です。 オーディオストリームの作成方法を見てみましょう。 最も簡単な方法は、ディスクからファイルを読み取ることです。
Windows.Storage.Pickers.FileOpenPicker picker = new Windows.Storage.Pickers.FileOpenPicker(); picker.FileTypeFilter.Add(".wav"); Windows.Storage.StorageFile fl = await picker.PickSingleFileAsync(); string _selectedFile = fl.Name; AudioStream = await fl.OpenAsync(Windows.Storage.FileAccessMode.Read);
フレーズは、16 kHzの周波数でモノラルで録音する必要があります。
2番目のオプションは、マイクからの音声を録音することです。 音声録音を開始します。
MediaCapture CaptureMedia = new MediaCapture(); var captureInitSettings = new MediaCaptureInitializationSettings(); captureInitSettings.StreamingCaptureMode = StreamingCaptureMode.Audio; await CaptureMedia.InitializeAsync(captureInitSettings); MediaEncodingProfile encodingProfile = MediaEncodingProfile.CreateWav(AudioEncodingQuality.High); encodingProfile.Audio.ChannelCount = 1; encodingProfile.Audio.SampleRate = 16000; IRandomAccessStream AudioStream = new InMemoryRandomAccessStream(); CaptureMedia.RecordLimitationExceeded += MediaCaptureOnRecordLimitationExceeded; CaptureMedia.Failed += MediaCaptureOnFailed; await CaptureMedia.StartRecordToStreamAsync(encodingProfile, AudioStream);
以下のパラメーターが必要です。
encodingProfile.Audio.ChannelCount = 1; encodingProfile.Audio.SampleRate = 16000;
一定時間後に録音を停止します。
await CaptureMedia.StopRecordAsync(); Stream str = AudioStream.AsStream(); str.Seek(0, SeekOrigin.Begin);
そして、登録のためにサービスにストリームを送信します。
Guid _speakerId = Guid.Parse(_profileId); Enrollment response = await _serviceClient.EnrollAsync(str, _speakerId);
応答から、次のデータを取得できます。
response.Phrase-話し言葉
response.RemainingEnrollments-フレーズの残りの繰り返しの数
認識は、VerifyAsyncメソッドが使用されるという点でのみ登録と異なります。
Guid _speakerId = Guid.Parse(_profileId); Verification response = await _serviceClient.VerifyAsync(str, _speakerId);
結果のアプリケーションのソースコードはGitHubで入手できます。
以下の出来事のスクリーンショット:
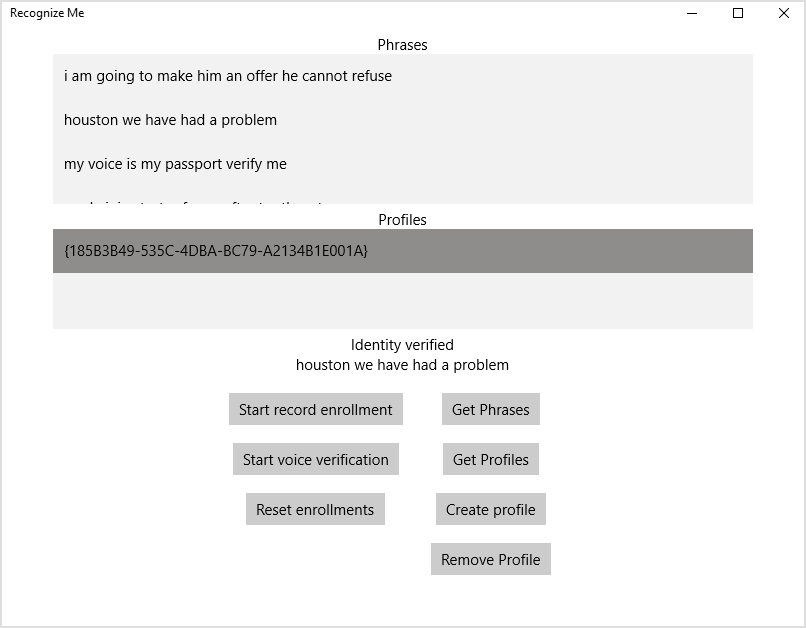
保護する唯一の方法として、音声認証はおそらく最も信頼できるオプションではありません。 しかし、今では、多要素認証の要素の1つとして、非常にうまく使用できます。
繰り返しますが、識別の可能性は興味深いものです。コードは似ていますが、いくつかの変更があります。
記録を行う期間は長くなる可能性があるため、操作を完了するためのサービス時間を与えるために、チェックはサイクルで開始されます。 登録操作の例:
_speakerId = Guid.Parse((lbProfiles.SelectedItem as ListBoxItem).Content.ToString()); OperationLocation processPollingLocation; processPollingLocation = await _serviceClient.EnrollAsync(str, _speakerId); EnrollmentOperation enrollmentResult = null; int numOfRetries = 10; TimeSpan timeBetweenRetries = TimeSpan.FromSeconds(5.0); while (numOfRetries > 0) { await Task.Delay(timeBetweenRetries); enrollmentResult = await _serviceClient.CheckEnrollmentStatusAsync(processPollingLocation); if (enrollmentResult.Status == Status.Succeeded) { break; } else if (enrollmentResult.Status == Status.Failed) { txtInfo.Text = enrollmentResult.Message; return; } numOfRetries--; }
識別には、同じNuGetパッケージが使用されます。
識別アプリケーションのソースコードもGitHubに投稿されています 。
GitHubでのWPFプロジェクトの公式例は、次の場合にも役立ちます。
Microsoft Speaker Recognition API:Windowsクライアントライブラリとサンプル
Pythonの例: Microsoft Speaker Recognition API:Python Sample
Microsoft Speaker Recognition APIのAndroid SDKは GitHubにもあります。