1年以上もの間、時系列を保存するデータベースエンジンdariadbを開発している自分の趣味プロジェクトがあります。 タスクは非常に興味深いです-複雑なアルゴリズムもあり、私にとっての領域は完全に新しいです。 1年で、エンジン自体、それ用の小さなサーバー、およびクライアントが作成されました。 これはすべてC ++で書かれています。 クライアントサーバーがまだかなり粗雑な状態にある場合、エンジンは既にある程度の安定性を獲得しています。時系列を保存するタスクは、少なくともいくつかの測定がある場合に非常に一般的です(SCADAシステムからサーバーのステータスの監視まで)。
この問題を解決するために、さまざまな高度のソリューションがいくつかあります。
入門記事として、特定のサークルで広く知られているFaceBook記事「 Gorilla:A Fast、Scalable、In-Memory Time Series Database 」をお勧めします。
dariadbの主なタスクは、アプリケーションに(SQLiteなどの)組み込み可能なストレージを作成し、ストレージ、処理、時系列分析をアプリケーションに組み込むことでした。 現在のタスクのうち、測定値の受信、保存、処理は完了しています。 このプロジェクトはまだ自然の研究中であるため、現在は生産での使用には適していません。 とにかく、さようなら:)
測定の時系列
測定の時系列は、4つのシーケンス{Time、Value、Id、Flag}です。ここで、
- 時間、測定時間(8バイト)
- 値、自己測定(8バイト)
- Id、時系列識別子(4バイト)
- フラグ、測定フラグ(4バイト)
フラグは読み取り時にのみ使用されます。 特別なフラグ「データなし」( _NO_DATA = 0xffffffff)があります。これは、まったくない値またはフィルターを満たさない値に設定されます。 フラグフィールドのクエリに0(ゼロ)が含まれていない場合、クエリの時間に適切な測定ごとに、論理AND演算がフラグフィールドに適用されます。答えがフィルターに等しい場合、測定はパスします。 値はタイムスタンプの昇順になります(ただし、これは必要ではありません。「過去に」値を書き込む必要がある場合があります)、スライスを作成し、それらの間隔を要求できる必要があります。
スライスを読む
タイムスタンプTごとの時系列の値のスライスは、時刻Tまたはこの時間の「左」に存在する値です。 値がないか、フラグが一致しない場合、「データなし」。 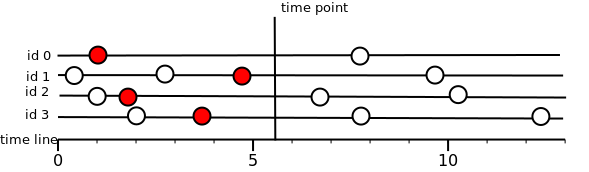
フラグに該当しない値に対して正確に「データなし」が返される理由を理解することが重要です。 格納された値がどれもフラグに該当しない場合、ストレージ全体の読み取りが発生する可能性があります。 したがって、カットの時点で値はあるが、フラグが一致しなかった場合、値はないと考えます。
間隔を読み取ります。
ここではすべてがはるかに単純です。時間間隔内にあるすべての値が返されます。 つまり <= T <= toの条件(Tは測定時間)を満たす必要があります。 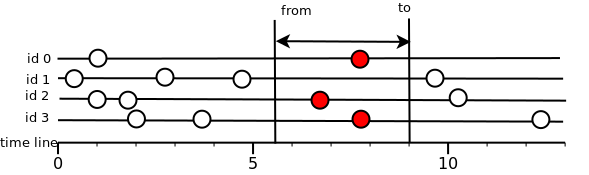
測定が間隔内に収まるが、フラグを満たさない場合、測定は拒否されます。 データは常に昇順のタイムスタンプでユーザーに提供されます。
MinMax、最近の値、統計。
また、リポジトリに記録されている最小時間と最大時間を時系列ごとに取得することもできます。 最後に記録された値 間隔に関するさまざまな統計。
基本的なストレージデバイス
その結果、次の特性を持つプロジェクトが作成されました。
- ソートされていない値のサポート
- リポジトリに記録された値は変更できなくなります。
- さまざまなライティング戦略。
- LSMツリー形式のディスク上のストレージ( https://ru.wikipedia.org/wiki/LSM-%D0%B4%D0%B5%D1%80%D0%B5%D0%B2%D0%BE )。
- 高速書き込み速度:ディスクへの書き込み時、1秒あたり250〜350万レコード。 メモリへの書き込み時、1秒あたり700〜900万レコード。
- クラッシュ回復。
- すべての圧縮値のCRC32。
- データをリクエストするための2つのオプション:Functor API(async)-コールバック関数がリクエストに渡され、リクエストに含まれる各値に使用されます。 標準API-リストまたは辞書の形式で値を返します。
間隔に関する統計:時間min / max; 最小/最大値測定数; 値の合計
次のレイヤーが実装されています:RAM内のストレージ、ログファイル内のディスク上のストレージ、圧縮形式のストレージ。
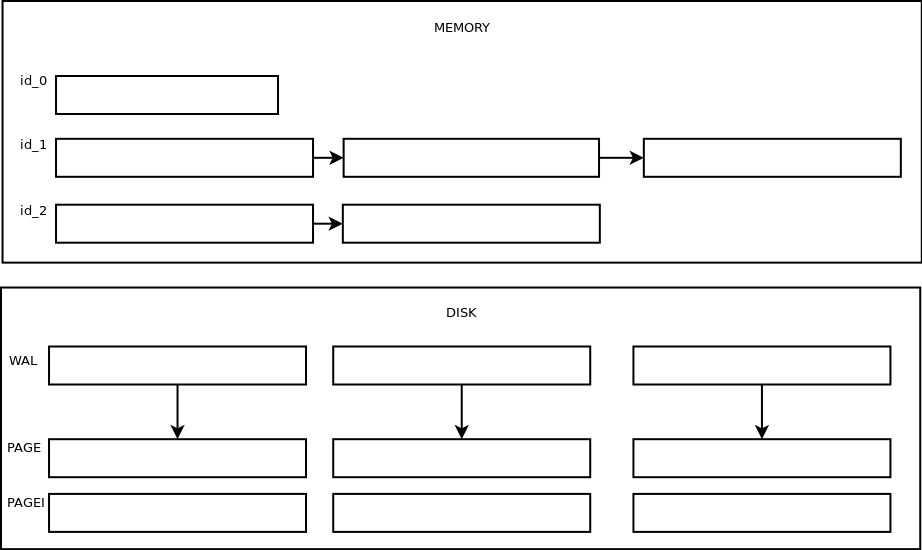
ログファイル(* .wal)
これらは単なるログファイルです。 小さなバッファはメモリに保持され、いっぱいになるとソートされ、ディスクにフラッシュされます。 バッファとファイルの最大サイズは、設定によって規制されています(以下を参照)。 プロンプトが表示されたら、ファイル全体が差し引かれ、リクエストに含まれる値がユーザーに提供されます。 検索を高速化するインデックスやマーカーはありません。ログファイルのみです。 ファイル名は、このファイルが作成された時間からマイクロ秒+拡張子(wal)で形成されます。
圧縮ページ(* .page)
ページはログファイルを圧縮することで取得され、その名前はページの受信元のログファイルと一致します。 起動時に、ログファイルと同じ名前(拡張子を除く)のページがあることがわかった場合、ストレージが通常の方法で停止されていないと判断し、ページが削除され、圧縮が再度繰り返されます。読書のため。 これらはチャンクのセットで構成され、各チャンクは1つの時系列のソートおよび圧縮された値を格納し、最大チャンクサイズは設定によって制限されます。 ファイルの最後には、時間の最小値を保存するフッター、ファイルに入力された時系列のIDのブルームフィルター、保存された時系列の統計があります。

インデックスファイルはページごとに作成されます。 インデックスファイルには、ページ内の各チャンクの時間の最小値のセット、時系列のID、ページ内の位置が含まれます。 したがって、間隔またはスライスを照会するときは、必要なチャンクをインデックスファイルで見つけてページから減算するだけで済み、各チャンクでは、値は圧縮形式で格納されます。 測定の各フィールドに異なるアルゴリズムが使用されます(有名な記事「Gorilla:A Fast、Scalable、In-Memory Time Series Database」に触発されました):
DeltaDelta-時間のため
Xor-値自体のため
LEB128-フラグ用
その結果、圧縮は異なるデータで最大3倍に達します。
インデックスファイルのフッターは常にキャッシュにあり、必要なページをすばやく見つけて結果を表示するために使用されます。
暗記
メモリには、各時系列がチャンクのリスト(stlからの単純なstd ::リスト)に格納され、とりわけクイック検索のために、各チャンクの最大時間で構築されたB +ツリーが構築されます。 したがって、間隔またはスライスを要求するとき、必要なデータを含むチャンクを見つけ、それらをアンパックして返します。 メモリ内のストレージは、最大サイズ、つまり あまりにも精力的に書き込むと、制限はすぐに終了し、すべてはストレージ戦略によって決定されるシナリオに従って進みます
ストレージ戦略
WAL-データはログファイルにのみ書き込まれ、ページの圧縮は自動的に開始されませんが、すべてのログファイルの圧縮を手動で開始することは可能です。
COMPRESSED-データはログファイルに書き込まれますが、ファイルが制限(設定を参照)に達するとすぐに新しいファイルが作成され、古いファイルが圧縮のためにキューに入れられます。
MEMORY-すべてがメモリに書き込まれます。制限に達するとすぐに、最も古いチャンクがディスクにダンプされ始めます。
- CACHE-メモリとディスクの両方に書き込みます。 この戦略により、COMPRESSEDのような書き込み速度が得られますが、新しく記録されたデータをすばやく検索できます。 メモリ制限もこれに関連します;それに達すると、古いチャンクは単に削除されます。
再パッケージ化して過去に書き込みます。
任意の順序でデータを記録することが可能です。 戦略がMEMORYであり、メモリにまだ保存されている過去に書き込む場合、既存のチャンクに新しいデータを追加するだけです。 過去に書き込みを行って、この時間がメモリにない場合、またはストレージ戦略がMEMORYでない場合、データは現在のチャンクに書き込まれますが、データを読み取るときにkマージアルゴリズムが使用され、読み取りが遅くなりますそのようなチャンクはたくさんあります。 これを防ぐために、ページを再パックし、重複を削除し、タイムスタンプの昇順でデータを並べ替える再パック呼び出しがあります。 同時に、ページが折りたたまれるため、各レベルで設定(LSM-ツリー)で指定されたページより多くのページはありません。
時系列の作成
時系列の識別子の選択は、独立して実装するか、dariadbに割り当てることができます-名前付き時系列を作成する機能が実装され、その後、名前で識別子を取得し、目的のディメンションに登録できます。 これは思ったより簡単です。 いずれにせよ、測定値を記録しても、時系列のファイルに記述されていない場合(ストレージの初期化時に自動的に作成されます)、測定値は問題なく記録されます。
設定
設定は、Settingsクラスを介して設定できます(以下の例を参照)。 次の設定を使用できます。
- wal_file_size-次元単位のログファイルの最大サイズ(バイト単位ではありません!)。
- wal_cache_size-ログファイルに入る前に測定値が書き込まれるメモリ内のバッファのサイズ。
- chunk_size-チャンクサイズ(バイト)戦略-ストレージ戦略。
- memory_limit RAMのストレージが使用するメモリの最大サイズ。
- percent_when_start_droping-チャンクがダンプを開始するときのRAMメモリの割合。
- percent_to_drop-メモリー制限に達したときにクリアする必要があるメモリーの割合。
- max_pages_in_level-各レベルの最大ページ数(.page)。
最終的なベンチマーク
典型的なタスクの速度特性を示します。
条件:
2つのストリームは、2日間の測定の各シリーズで、50時系列で書き込まれます。 測定頻度-1秒あたり2回の測定。 その結果、2,000,000の測定値が得られます。 Intel Core i5 2.8 760 @ GHz、8 Gb RAM、WDC WD5000AAKSハードドライブ、Windows 7
1秒あたりの平均書き込み速度:
| WAL、予備/秒 | 圧縮、スペア/秒 | メモリ、予備/秒 | キャッシュ、予備/秒 |
|---|---|---|---|
| 2.600.000 | 420.000 | 5.000.000 | 420.000 |
読み取りスライス。
N個のランダムな時系列が選択されます。それぞれに対して、正確に値があり、この間隔でランダムな瞬間にスライスが要求される時間があります。
| WAL、秒 | 圧縮、秒 | メモリ、秒 | キャッシュ、秒 |
|---|---|---|---|
| 0.03 | 0.02 | 0.005 | 0.04 |
すべての値の2日間の読み取り時間間隔:
| WAL、秒 | 圧縮、秒 | メモリ、秒 | キャッシュ、秒 |
|---|---|---|---|
| 13 | 13 | 0.5 | 5 |
ランダムな期間の読み取り間隔
| WAL、スペア/秒 | 圧縮された | メモリ、スペア/秒 | キャッシュ、スペア/秒 |
|---|---|---|---|
| 2.043.925 | 2.187.507 | 27.469.500 | 20.321.500 |
すべてを集めて試す方法。
このプロジェクトはすぐにクロスプラットフォームとして構想され、その開発はWindowsとubuntu / linuxで行われます。 gcc-6およびmsvc-14コンパイラがサポートされています。 clangによるビルドはまだサポートされていません。
依存関係
Ubuntu 14.04では、ppa ubuntu-toolchain-r-testを接続する必要があります。
$ sudo add-apt-repository -y ppa:ubuntu-toolchain-r/test $ sudo apt-get update $ sudo apt-get install -y libboost-dev libboost-coroutine-dev libboost-context-dev libboost-filesystem-dev libboost-test-dev libboost-program-options-dev libasio-dev libboost-log-dev libboost-regex-dev libboost-date-time-dev cmake g++-6 gcc-6 cpp-6 $ export CC="gcc-6" $ export CXX="g++-6"
組み込みプロジェクトとしての使用例( https://github.com/lysevi/dariadb-example )
$ git clone https://github.com/lysevi/dariadb-example $ cd dariadb-example $ git submodule update --init --recursive $ cmake .
開発者とプロジェクトを構築する
$ git clone https://github.com/lysevi/dariadb.git $ cd dariadb $ git submodules init $ git submodules update $ cmake .
テストを実行する
$ ctest --verbose .
例
ストレージの作成と値の入力
#include <iostream> #include <libdariadb/dariadb.h> #include <libdariadb/utils/fs.h> int main(int, char **) { const std::string storage_path = "exampledb"; // , if (dariadb::utils::fs::path_exists(storage_path)) { dariadb::utils::fs::rm(storage_path); } // . auto settings = dariadb::storage::Settings::create(storage_path); settings->save(); // . p1 p2 // auto scheme = dariadb::scheme::Scheme::create(settings); auto p1 = scheme->addParam("group.param1"); auto p2 = scheme->addParam("group.subgroup.param2"); scheme->save(); // . auto storage = std::make_unique<dariadb::Engine>(settings); auto m = dariadb::Meas(); auto start_time = dariadb::timeutil::current_time(); // // // [currentTime:currentTime+10] m.time = start_time; for (size_t i = 0; i < 10; ++i) { if (i % 2) { m.id = p1; } else { m.id = p2; } m.time++; m.value++; m.flag = 100 + i % 2; auto status = storage->append(m); if (status.writed != 1) { std::cerr << "Error: " << status.error_message << std::endl; } } }
ストレージを開き、間隔を読み取ります。
#include <libdariadb/dariadb.h> #include <iostream> // void print_measurement(dariadb::Meas&measurement){ std::cout << " id: " << measurement.id << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } void print_measurement(dariadb::Meas&measurement, dariadb::scheme::DescriptionMap&dmap) { std::cout << " param: " << dmap[measurement.id] << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } class QuietLogger : public dariadb::utils::ILogger { public: void message(dariadb::utils::LOG_MESSAGE_KIND kind, const std::string &msg) override {} }; class Callback : public dariadb::IReadCallback { public: Callback() {} void apply(const dariadb::Meas &measurement) override { std::cout << " id: " << measurement.id << " timepoint: " << dariadb::timeutil::to_string(measurement.time) << " value:" << measurement.value << std::endl; } void is_end() override { std::cout << "calback end." << std::endl; dariadb::IReadCallback::is_end(); } }; int main(int, char **) { const std::string storage_path = "exampledb"; // . , // dariadb::utils::ILogger_ptr log_ptr{new QuietLogger()}; dariadb::utils::LogManager::start(log_ptr); auto storage = dariadb::open_storage(storage_path); auto scheme = dariadb::scheme::Scheme::create(storage->settings()); // . auto all_params = scheme->ls(); dariadb::IdArray all_id; all_id.reserve(all_params.size()); all_id.push_back(all_params.idByParam("group.param1")); all_id.push_back(all_params.idByParam("group.subgroup.param2")); dariadb::Time start_time = dariadb::MIN_TIME; dariadb::Time cur_time = dariadb::timeutil::current_time(); // dariadb::QueryInterval qi(all_id, dariadb::Flag(), start_time, cur_time); dariadb::MeasList readed_values = storage->readInterval(qi); std::cout << "Readed: " << readed_values.size() << std::endl; for (auto measurement : readed_values) { print_measurement(measurement, all_params); } // std::cout << "Callback in interval: " << std::endl; std::unique_ptr<Callback> callback_ptr{new Callback()}; storage->foreach (qi, callback_ptr.get()); callback_ptr->wait(); { // auto stat = storage->stat(dariadb::Id(0), start_time, cur_time); std::cout << "count: " << stat.count << std::endl; std::cout << "time: [" << dariadb::timeutil::to_string(stat.minTime) << " " << dariadb::timeutil::to_string(stat.maxTime) << "]" << std::endl; std::cout << "val: [" << stat.minValue << " " << stat.maxValue << "]" << std::endl; std::cout << "sum: " << stat.sum << std::endl; } }
データスライスの読み取り
ここでは、リポジトリを開いて識別子を取得することは前の例と変わりません。そのため、スライスを取得する例を示します。
dariadb::Time cur_time = dariadb::timeutil::current_time(); // ; dariadb::QueryTimePoint qp(all_id, dariadb::Flag(), cur_time); dariadb::Id2Meas timepoint = storage->readTimePoint(qp); std::cout << "Timepoint: " << std::endl; for (auto kv : timepoint) { auto measurement = kv.second; print_measurement(measurement, all_params); } // dariadb::Id2Meas cur_values = storage->currentValue(all_id, dariadb::Flag()); std::cout << "Current: " << std::endl; for (auto kv : timepoint) { auto measurement = kv.second; print_measurement(measurement, all_params); } // . std::cout << "Callback in timepoint: " << std::endl; std::unique_ptr<Callback> callback_ptr{new Callback()}; storage->foreach (qp, callback_ptr.get()); callback_ptr->wait();