
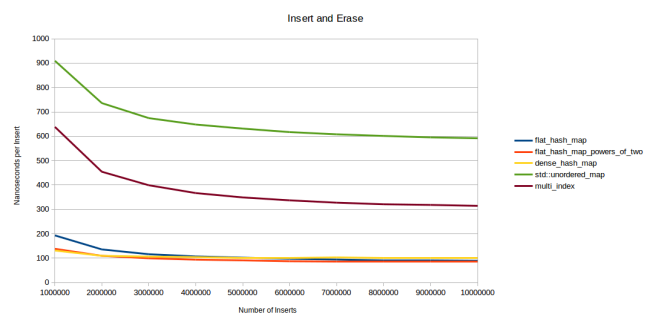
最後に、私はこれに来なければなりませんでした。 「 クイックハッシュテーブルを作成しました 」という記事を公開した後、「 さらに高速なハッシュテーブルを作成しました 」という記事を公開しました。 これで、最速のハッシュテーブルでの作業が完了しました。 これにより、私が見つけたすべてのハッシュテーブルと比較して、最速の検索を実装したことになります。 同時に、挿入および削除操作も非常に高速に動作します(ただし、競合他社よりも高速ではありません)。
セットの最大数を制限して、Robin Hoodハッシュを使用しました。 要素がその理想位置からX位置よりも大きい距離にある場合、テーブルを増やし、この場合、各要素がその望ましい位置により近くなることを望みます。 これは本当にうまくいくようです。 Xの値は比較的小さく、ハッシュテーブルの内部検索サイクルをある程度最適化できます。
仕事で試してみたい場合は、こちらからダウンロードできます。 または、「ソースコードと使用法」セクションまでスクロールします。 詳細が必要な場合は、続きをお読みください。
ハッシュテーブルタイプ
ハッシュテーブルには多くの種類があります。 私自身のために、私は選択しました:
- オープンアドレッシング。
- 線形配置。
- ハッシュロビンフッド。
- スロットの数は素数です(ただし、この目的のために2の累乗の数を使用できることに気付きました)。
- セットの最大数を制限します。
最後のポイントは、ハッシュテーブルの分野における新規性だと思います。 これが私のソリューションの高いパフォーマンスの主な理由です。 しかし、最初に、前の段落についてお話したいと思います。
オープンアドレス指定とは、ハッシュテーブルがデータストアとして連続配列を使用することを意味します。 これは、各要素が個別のヒープ上にある場合のstd::unordered_map
類似物ではありません。
線形割り当てとは、要素を配列に挿入しようとしていて、現在のスロットがすでにいっぱいになっている場合、次のスロットに移動することを意味します。 いっぱいになっている場合は、次のスロットが使用されます。 この単純なアプローチにはよく知られた欠陥がありますが、セットの最大数を制限することで修正されると思います。
ロビンフッドハッシュとは、線形配置では、各要素をできるだけ理想的な位置に近づけようとすることを意味します。 これは、いくつかの要素を挿入または削除しながら周囲の要素を移動することにより行われます。 原則は次のとおりです。リッチな要素からそれを取得し、貧しい要素に転送します。 これが、ロビンフッドの名前の由来です。 リッチアイテムは、理想的な挿入ポイントの近くでスロットを受け取る要素です。 貧弱な要素は、理想的な挿入ポイントからはほど遠いです。 新しい要素を挿入するとき、理想的な位置からどれだけ離れているかを数えます。 現在の要素よりも遠い場合は、現在の要素の代わりに新しい要素を配置し、その要素の新しい場所を見つけようとします。
スロットの数は素数です。ハッシュテーブルの基になる配列のサイズは素数です。 これは、たとえば、5スロットから11スロット、23スロットから47スロットなどに拡大できることを意味します。 挿入ポイントを見つける必要がある場合は、モジュロ演算子を使用して要素のハッシュ値をスロットに割り当てます。 別のオプションは、配列のサイズを2の累乗に等しくすることです。 以下では、デフォルトで素数を使用する理由と、両方のオプションを使用することが推奨される場合について説明します。
セットの最大数を制限する
基本を理解したので、今度はソリューションを説明しましょう。テーブルが検索するスロットの最大数を制限すると、配列のサイズが大きくなります。
最初は、この量を非常に小さく、たとえば4にすることでした。つまり、挿入するときに、最初に理想的なスロットを試します。うまくいかない場合は、次に、次に、次に、次に、すべてがいっぱいになったら、その後、テーブルを拡大して、要素をもう一度挿入しようとしています。 これは小さなテーブルでうまく機能します。 しかし、大きなテーブルにランダムな値を挿入すると、これらの4つのセットで常に失敗します。テーブルがほとんど空であっても、テーブルのサイズを大きくする必要があります。
最終的に、上限がlog2(n)に等しい場合(nはテーブル内のスロット数)、再割り当ては約2/3がいっぱいになったときにのみ実行されることがわかりました。 これは、ランダムな値を挿入するときです。 そして、連続した値を挿入すると、テーブル全体に記入でき、その場合にのみ再配布されます。
しかし、経験的に見つかった2/3のしきい値にもかかわらず、再配布はテーブルの60%のカバレッジで開始されました。 時折-55%でも。 したがって、テーブルmax_load_factor
を0.5にmax_load_factor
ます。 これは、セット数の制限に達していない場合でも、50%で満たされるとテーブルが増加することを意味します。 実際にサイズを大きくしたときにテーブルの再配布を信頼できるように、これを行いました:1000個の要素を挿入し、それらのいくつかを削除してから、同じ量をもう一度挿入すると、テーブルがそうでないことをほぼ完全に確信できます再配布されました。 正確な統計情報はありませんが、さまざまなサイズの数千のテーブルを作成し、それらを乱数で埋める簡単なテストを実行しました。 合計で数千億の数字を挿入しましたが、負荷係数が0.5未満の再分散が1回だけ発生しました(48%の充填でテーブルが増加しました)。 そのため、このようなメカニズムを信頼できます。予期しないときに、非常に、非常に、非常にまれに再配布します。
一般に、テーブルの増加を制御する必要がない場合max_load_factor
値を自由に高くmax_load_factor
ます。 恐れることなく0.9まで設定:ロビンフッドとセット数の制限の組み合わせにより、すべての操作の高速性が確保されます。 ただし、値1.0を割り当てないでください。挿入を開始すると、テーブルの各要素が最後の残りのスロットを満たすように移動し始める場合があります。 たとえば、最後の空のスロットを除いて、最後のアイテムを配置したいすべてのスロットはすでに使用されています。 次に、要素を挿入したい最初のスロットに要素を挿入しますが、その要素はすでに使用されています。 既存の要素を2番目のスロットに移動し、そこから3番目の要素に移動する必要があります。チェーン上でテーブルの最後まで移動します。 その結果、最初の要素を除くすべての要素が理想的な位置から同じスロットにあるテーブルが得られます。 検索は依然として高速ですが、最後の挿入には時間がかかります。 近くに空きスロットがいくつかある場合、挿入された要素はそれほど多くの隣人を移動しません。
max_load_factorを 、セット数の制限に決して達しないほど低い値に設定した場合、なぜ何も制限しないのですか? この制限のおかげで、微妙な最適化を実装できます。テーブルを再キャッシュして、1000スロットを取得するとしましょう。 私の場合、テーブルは1009になります。これは最も近い素数です。 1009の2進対数は10に丸められるため、セットの数を10に制限します。 ここで、トリックを適用します。1009スロットの配列の代わりに、1019の配列を作成します。しかし、他のすべてのハッシュ操作では、1009スロットしかないと仮定します。 ここで、2つの要素がインデックス1008でハッシュされる場合、最後に移動してインデックス1009に挿入できます。インデックスの範囲をチェックする(境界チェック)必要はありません。セットの数の制限により、インデックス1018を超えることはできません。最後のスロットに入れたい要素が11個ある場合、テーブルが増加し、これらすべての要素が異なるスロットにキャッシュされます。 境界チェックがないため、コンパクトな内部ループが発生します。 検索機能は次のようになります。
iterator find(const FindKey & key) { size_t index = hash_policy.index_for_hash(hash_object(key)); EntryPointer it = entries + index; for (int8_t distance = 0;; ++distance, ++it) { if (it->distance_from_desired < distance) return end(); else if (compares_equal(key, it->value)) return { it }; } }
これは基本的に線形検索です。 コードは完全にアセンブラーに変換されます。 このアプローチは、次の2つの理由で単純な線形配置よりも優れています。
- インデックス変更の範囲の検証はありません。 空のスロットの
distance_from_desired
値は-1であるため、これは別の要素を見つけることに似ています。 - ループでは、log2(n)回以上の反復は実行されません。 通常、ハッシュテーブルで検索する場合、最悪の時間の複雑度はO(n)です。 私のテーブルでは-O(log n)。 これは大きな違いです。 特に、線形配置では、要素がグループ化されやすいため、最悪のケースが望ましいことを考慮してください。
私のメモリオーバーヘッドは要素ごとに1バイトです。 distance_from_desired
をint8_t
に格納しint8_t
。 つまり、挿入された要素のタイプ(タイプのアラインメント)を位置合わせするときに、1バイトが埋め込まれます。 したがって、整数値を挿入すると、1バイトがさらに3バイトのパディングを受け取り、その結果、各要素の4バイトのオーバーヘッドが解放されます。 ポインターを挿入すると、パディングはすでに7バイトになり、8バイトのオーバーヘッドが発生します。 この問題を解決するために、メモリ使用スキームを変更するオプションを検討していますが、その場合、検索ごとに1つではなく2つのキャッシュミスが発生することを恐れています。 したがって、メモリオーバーヘッドは、要素ごとに1バイト+パディングです。 また、デフォルトのmax_load_factor
値が0.5の場合、テーブルは25〜50%しか満たされないため、総オーバーヘッドはさらに大きくなります。 メモリを節約するために、恐れることなくmax_load_factor
を0.9に増やすことができますが、これは速度のわずかな低下につながることを思い出させてください。
検索パフォーマンス
ハッシュテーブルのパフォーマンスを調べるのは簡単ではありません。 少なくとも、このような状況では速度を測定する必要があります。
- テーブル内のアイテムを検索します。
- テーブルにないアイテムを検索します。
- 乱数のグループを挿入します。
-
reserve()
呼び出した後、乱数のグループを挿入します。 - アイテムの削除。
そして、これらの状況のそれぞれは、異なるサイズの異なるキーと値で追い払われる必要があります。 キーとして、整数値または文字列値を使用し、値のタイプは4、32、および1024です。文字列では、ほとんどすべてのハッシュテーブルで同じハッシュ関数と比較演算子のオーバーヘッドを測定するため、整数値を好みます。
テーブルに要素がある場合とない場合の両方で検索をテストする必要があります。これらの場合、パフォーマンスが劇的に変化する可能性があるためです。 たとえば、 google::dense_hash_map
(乱数ではなく)にgoogle::dense_hash_map
すべての数値を挿入し、不足している要素を検索すると、困難な状況に直面しました。 予想外に、ハッシュテーブルは通常よりも500倍遅くなります。 これは極端なケースです-2の累乗を使用してテーブルのサイズを設定します。 おそらく、乱数と連続したものを使用して測定を実行する必要がありましたが、多すぎるとグラフが判明しました。 したがって、私は自分自身を乱数のみに制限し、特定のパターンによるパフォーマンスで失敗する状況の発生を排除します。
最初のグラフは、表に存在する要素の検索です。
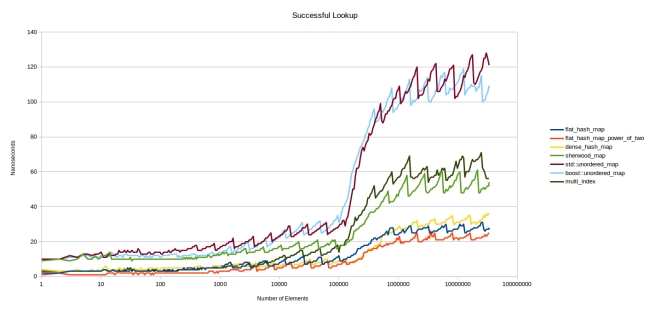
グラフは非常にタイトです。 flat_hash_map
は私の新しいハッシュテーブルです。 flat_hash_map_power_of_two
は同じテーブルですが、配列のサイズは素数ではなく2のべき乗で決まります。 ご覧のとおり、2番目のオプションははるかに高速です。その理由については後で説明します。 dense_hash_map
はgoogle::dense_hash_map
で、私が見つけた最速のハッシュテーブルです。 sherwood_map
は、「高速ハッシュテーブルを作成しました」の古いテーブルです。 私の恥ずかしいことに、それは平凡な結果を示しました... std::unordered_map
およびboost::unordered_map
すべては名前から明らかです。 multi_index
はboost::multi_index
です。
このグラフについて少し説明します。 Y軸-1つの要素の検索に費やされたナノ秒数。 Google Benchmarkを使用しました。これは、 table.find()
関数table.find()
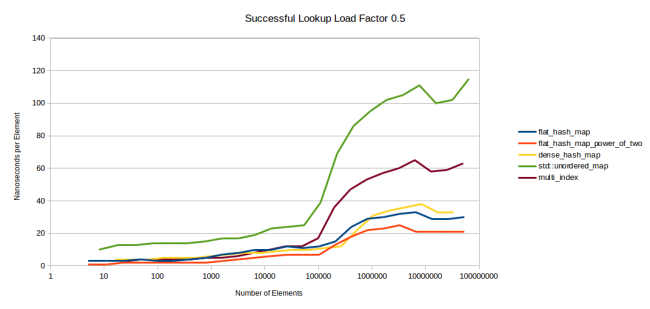
呼び出し、それができた回数をカウントします。 反復の合計期間はその数で除算され、ナノ秒が取得されます。 必要なすべてのキーがテーブルに存在します。 X軸については、パフォーマンスの変化をよく表しているため、対数目盛を使用しました。 さらに、このようなスケールでは、さまざまなサイズのテーブルのパフォーマンスを評価できます。小さなテーブルに関心がある場合は、グラフの左側を見てください。
すぐに目立つギザギザのチャート。 実際には、すべてのテーブルのパフォーマンスは、現在の負荷係数、つまり充填の程度に応じて異なります。 25%の場合、検索は50%の場合よりも高速になります。テーブルがいっぱいになるほど、ハッシュの衝突が発生します。 検索のコストが上昇し、ある時点でテーブルが満杯であると判断し、再配布する時が来たため、再び検索が高速になります。
これは、各テーブルのデューティサイクルをプロットすると明らかです。 また、 max_load_factor
が0.5の場合に下のグラフが取得され、 max_load_factor
場合に上のグラフが取得されたことがすぐにわかります。 問題はすぐに発生します:上のグラフのテーブルは、同じ値(0.5)を持つ下のグラフよりも高速ですか? であろうが、非常にわずか。 次に、この状況をより完全に検討します。 グラフは、表が再配布されたばかりで、フィルファクターが0.5をわずかに超える場合、上部のグラフの下部ポイントは、フィルファクターが0.5に近づくという事実により、再配布の直前の下部のグラフの上部ポイントよりもはるかに高い位置にあることを示しています。
また、左側では、すべてのグラフが比較的平坦であることがわかります。 その理由は、テーブルが完全にキャッシュされているためです。 データがL3キャッシュに収まらなくなった場合にのみ、グラフは著しく分岐します。 これは大きな問題だと思います。 私の意見では、グラフの右側は左側よりもはるかに正確に状況を反映しています。目的のアイテムが既にキャッシュにある場合にのみ左側と同様の結果が得られます。
そのため、キャッシュにないテーブルの速度を示すテストを思いついた。 L3に収まらないほど多くのテーブルを作成し、検索するアイテムごとに異なるテーブルを使用しました。 各8バイトの32個の要素を含むテーブルの速度を測定するとします。 私のL3キャッシュのサイズは6 MBなので、そのようなテーブルの約25,000が収まります。 キャッシュにテーブルがないことを確認するために、75,000個のマージンでテーブルを作成しました。 そして、各検索は別々のテーブルで実行されました。
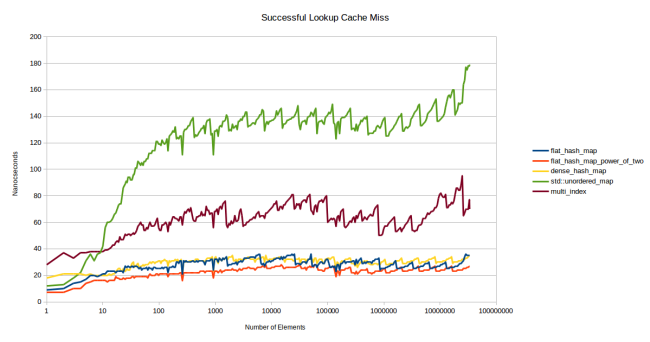
いくつかの行が情報価値がないため削除しました。 boost::unordered_map
とstd::unordered_map
は通常同じパフォーマンスを示し、古い遅いsherwood_map
テーブルは誰も気にしません。 現在、次のものがあります: std::unordered_map
ノードに基づく通常のコンテナとしてのstd::unordered_map
(ノードベースのコンテナ)、 boost::multi_index
に基づくノードに基づくクイックコンテナ( std::unordered_map
はそれほど速くはないはずです)、 google::dense_hash_map
素早いオープンアドレシングコンテナとしてのgoogle::dense_hash_map
と2つのバージョンの2つの累乗に基づく新しいコンテナ。
新しいベンチマークでは、グラフィックスはすぐに大きく変化し始めました。 最初のベンチマークのグラフに表示されたパターンは、10個の要素から始まる2番目のベンチマークのグラフの非常に早い段階で顕著になりました。 印象的:すべてのテーブルは、非常に広範囲の要素数で安定したパフォーマンスを発揮します。
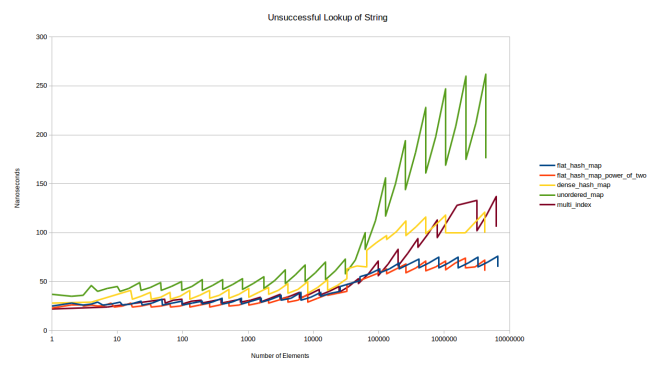
検索が失敗した場合のグラフ、つまり、テーブルにないアイテムの検索を見てみましょう。
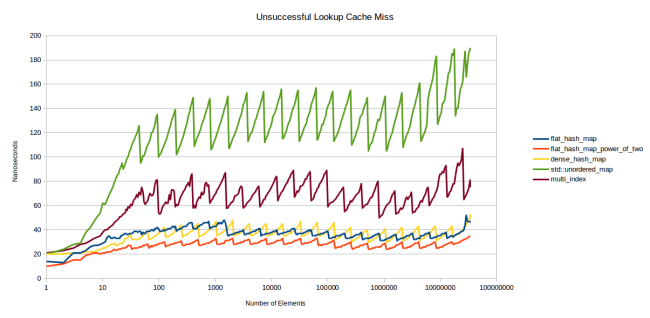
セレーションはさらに顕著で、フィルファクターが重要な役割を果たします。 テーブルがいっぱいになるほど、システムは要素が欠落していると判断する前に多くの要素を見る必要があります。 しかし、私はテーブルの結果が本当に好きです。セットの数を制限することはうまくいくようです。 私のテーブルは、他のテーブルよりも安定したパフォーマンスを示しています。
これらのグラフは、私の新しいテーブルが大きな前進であることを確信させました。 赤い線は、 dense_hash_map: max_load_factor 0,5
と同じ方法で構成されたテーブルの動作を示し、2のべき乗のサイズを決定する選択により、 dense_hash_map: max_load_factor 0,5
ビットだけでハッシュをスロットに入れることができます。 唯一の大きな違い:私のテーブルは、各スロットのストレージ(およびパディング)に余分なバイトを使用します。 dense_hash_map
、 dense_hash_map
よりも少し多くのメモリを消費します。
同時に、素数を使用してテーブルのサイズを決定する場合でも、テーブルの速度は劣りません。 これについて詳しく説明しましょう。
素数または2のべき乗
テーブル内のアイテムを見つけるには、3つの高価なステップがあります。
- キーハッシュ。
- スロットにキーを配置します。
- このスロットのメモリを取得します。
ステージ1は、キーが整数である場合、安価である可能性がありますsize_t
スローするだけです。 しかし、文字列などの他のタイプのキーでは、ステージはより高価になります。
ステージ2は、モジュロ整数です。
ステージ3-ポインターの参照解除。 std::unordered_map
場合std::unordered_map
これは複数のポインターの逆参照です。
ハッシュが遅すぎない場合は、ステージ3が最も費用がかかるようです。 ただし、1回の検索でキャッシュミスがない場合、2番目の段階が最も費用がかかる可能性が高くなります。 整数モジュロは、強力なハードウェアでもゆっくりと処理されます。 Intelによると 、これには80〜95サイクルが必要です。
これが、本当に高速なハッシュテーブルが通常2のべき乗を使用して配列のサイズを決定する主な理由です。 なぜなら、1サイクルで実行できる最上位ビットを削除するだけで十分だからです。
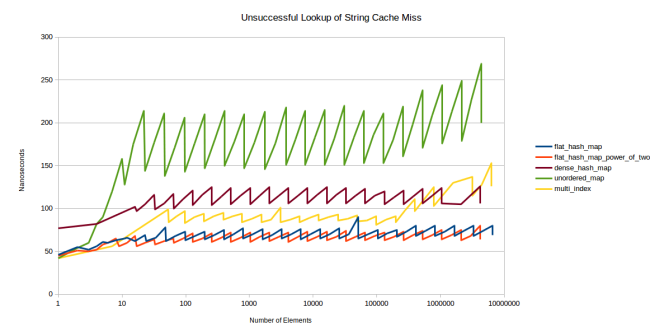
しかし、2のべき乗には大きな欠点があります。2のべき乗を使用すると、多くの入力パターンが多数のハッシュ衝突を引き起こします。 2番目のベンチマークのグラフを次に示しますが、今回は乱数を使用しませんでした。
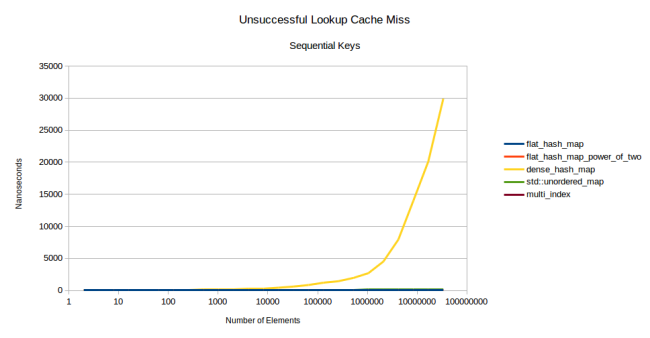
はい、そうです: google::dense_hash_map
は成層圏に入りました。 これを行うには、彼女に一連の数字[0、1、2、...、n-2、n-1]を順番に与えるだけで十分でした。 これを行って、テーブルにないキーを探すと、検索は非常に遅くなります。 キーがあれば、すべてがうまくいき、すぐに動作します。 この場合、成功した検索と失敗した検索の生産性の差は数千倍に達する可能性があります。
2のべき乗による問題の別の例:Rustの標準ハッシュテーブルは、あるテーブルから別のテーブルにキーを挿入するときに2次的な動作を示し始めました。 したがって、2の累乗を使用すると、不快な驚きにつながる可能性があります。
偶然、私のテーブルはセットの数を制限することでこれらの問題をすべて避けました。 不必要な再配布さえありませんでした。 しかし、これは、私のテーブルが2の累乗を使用することの副作用に対して無敵であることを意味しません。 たとえば、どういうわけか、このようなテーブルにポインターを挿入すると、一部のスロットが常に空であるという事実に出会いました。 , 16- , -, reinterpret_casted size_t
. - . -.
, -, . : -. , . , , . ( ).
? , , , . , , 32 , 16- ( 16). : 0 16. 32 16, . , . , 37 , 16 37 .
? boost::multi_index
: (compile time constant). . , . . - , :
switch(prime_index) { case 0: return 0llu; case 1: return hash % 2llu; case 2: return hash % 3llu; case 3: return hash % 5llu; case 4: return hash % 7llu; case 5: return hash % 11llu; case 6: return hash % 13llu; case 7: return hash % 17llu; case 8: return hash % 23llu; case 9: return hash % 29llu; case 10: return hash % 37llu; case 11: return hash % 47llu; case 12: return hash % 59llu; // // ... // case 185: return hash % 14480561146010017169llu; case 186: return hash % 18446744073709551557llu; }
— . それはどうですか? , . , , . , .
: , -, . , . , std::map
. , , . , .
. - , . ? , - -, , . - . , , dense_hash_map
, , , .
, . : , , , . . -, , . , - , , std::hash
-, (stateful), . , , , .
, , , - , . . typedef
hash_policy
-. , .
, typedef
-:
struct CustomHashFunction { size_t operator()(const YourStruct & foo) { // - } typedef ska::power_of_two_hash_policy hash_policy; }; // : ska::flat_hash_map<YourStruct, int, CustomHashFunction> your_hash_map;
- hash_policy
ska::power_of_two_hash_policy
. flat_hash_map
. std::hash
, power_of_two_std_hash
, std::hash
, power_of_two_hash_policy
:
ska::flat_hash_map<K, V, ska::power_of_two_std_hash<K>> your_hash_map;
-, , .
. , . , N , . reserve()
:
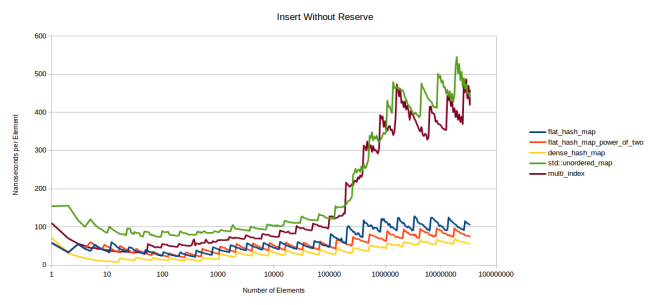
, . , . , .
, , L3. , , , — .
google::dense_hash_map
, . , dense_hash_map
. . Robin Hood , « ». . , .
, , reserve()
:
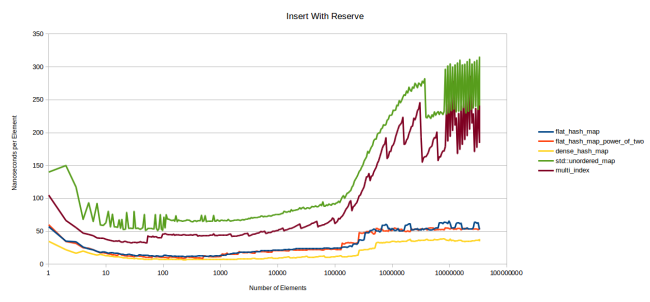
, . , . , malloc (Linux gcc). , .
, - , reserve
. , , google::dense_hash_map
.
, . N . N:
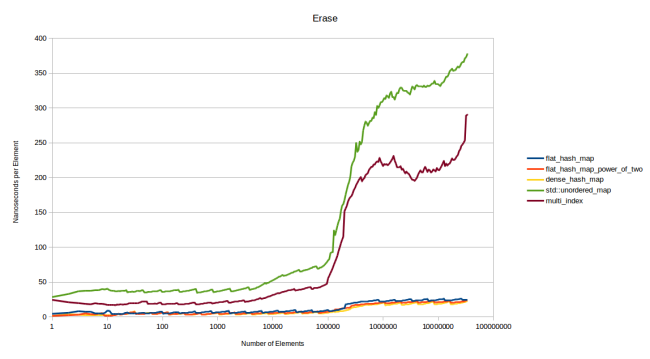
, . 23 , dense_hash_map
— 20. .
: dense_hash_map
, «» (tombstone). , . «» (quadratic probing), google::dense_hash_map
: , . Robin Hood , : , . , . . «», . .
, «», . dense_hash_map
. , , : :
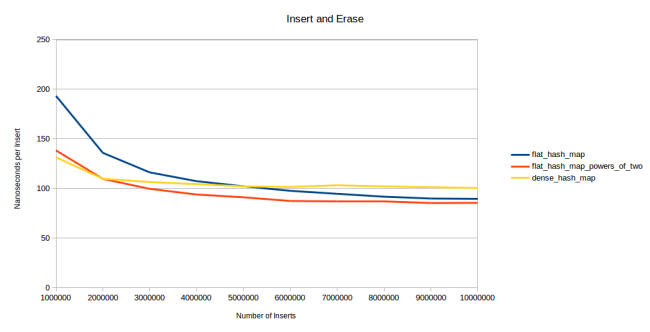
. -, , . . , : 1, 2, 3 4. «, , » : 1, 3, 1, 2, 4, 4, 4, 1, 2, 3, 3, 2. , , . . — . — , ( ). — , , , , . . などなど。
dense_hash_map
, . , — . 6 . , , . , 500 . . --, . , dense_hash_map
«», . dense_hash_map
:
, dense_hash_map
, «». . Robin Hood : , . , .
max_load_factor()
, std::unordered_map
boost::multi_index
max_load_factor, 1,0, google::dense_hash_map
0,5. max_load_factor
? , ( ), max_load_factor
0,5. .
, max_load_factor
0,5, , , . , , . , , - , max_load_factor
.
flat_hash_map
dense_hash_map
, . , dense_hash_map
, : L3, flat_hash_map
.
boost::multi_index
std::unordered_map
, max_load_factor
1,0, flat_hash_map
dense_hash_map
, max_load_factor
— 0,5. , flat- .
, , . , -, . , max_load_factor
. , , - . — . : .
(map from int to int). . — :

, . . , . , - . :
: , google::dense_hash_map
, boost::multi_index
. : dense_hash_map
, , , «». , , std::string(1, 0)
std::string(1, 255)
. , , , . .
, . , . , . :
, dense_hash_map
( ). .
. (map from int to int), 32- ? 1024- ? 12 ([, 32-, 1024-] × [, ] × [ , ]), , : , . : 1024- :
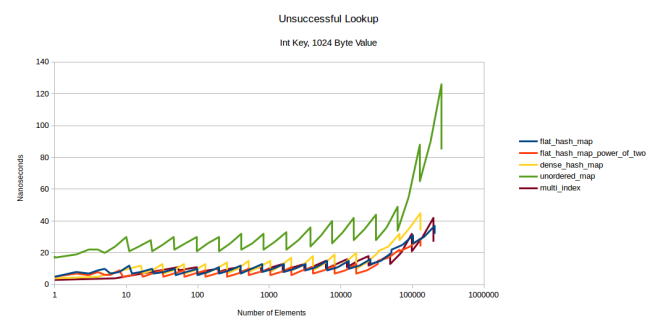
, 1024- multi_index
flat-. , , - prefetcher . , 1024 .
, : . flat- . max_load_factor
0,5, . : , , . , — . , (prefetch) .
(size of the type), . 32- :
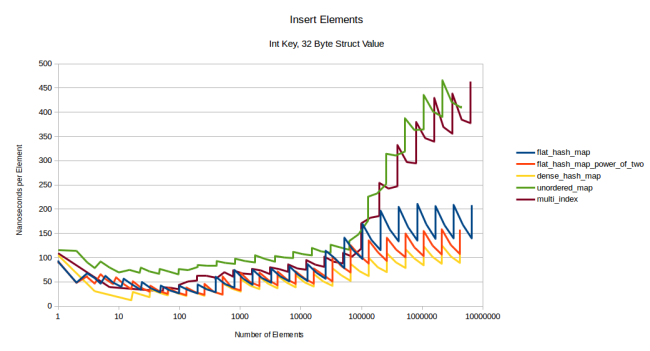
, flat-, : , . , boost::multi_index
. , 1024- :
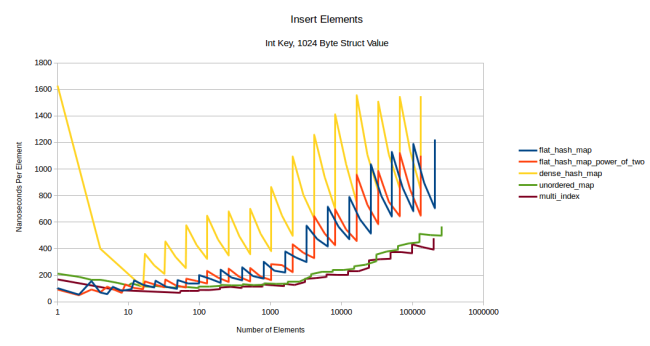
: flat- , , . .
: dense_hash_map
( ). , 32 - (default constructed value type). - — 1024 , 32 . , , .
dense_hash_map
. , , -, - , , .
, , , reserve()
. , , , reserve()
:
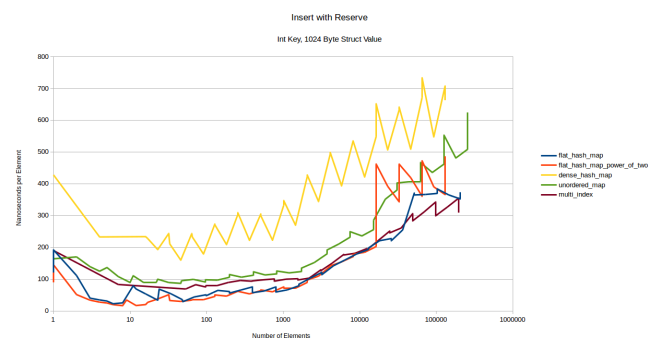
, - boost::multi_index
. dense_hash_map
, , , - , «» / . , , «» , 1024 ? , .
, : 16 385 . 16 384 . 1028 , , 16 , . , - . , , . , , : , clear_page_c_e
. , , clear_page_c_e
. - . , .
, . . , .
:
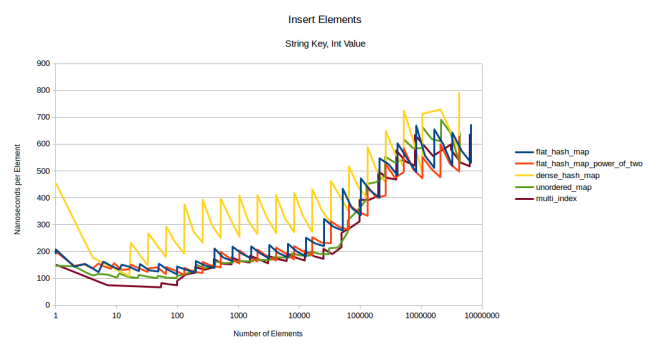
dense_hash_map
. , ( Ubuntu 16.04) , .
, . . reserve()
:
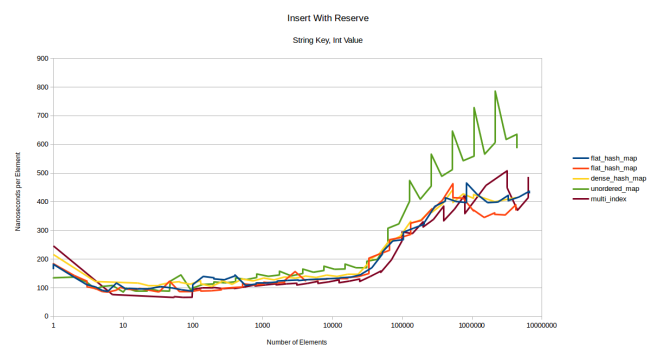
, , . , . : , , - , . - :

dense_hash_map
- . . , flat_hash_map_power_of_two
16 385 - clear_page_c_e
.
: - , , reserve()
. , .
. : 4, 32 1024 . 4- . 32 , . 1024 :
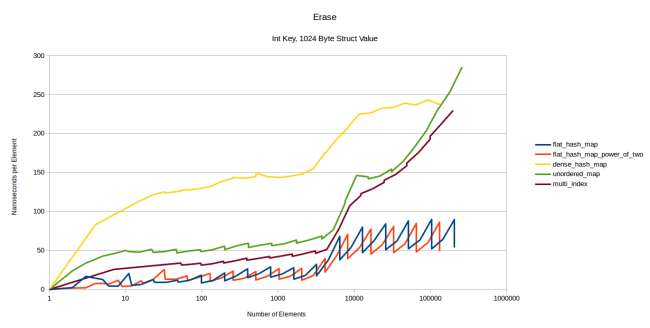
dense_hash_map
. : , no-op , dense_hash_map
«» /, , 1024 .
: flat_hash_map
. , , . , , flat_hash_map
, , 1028 .
, . :
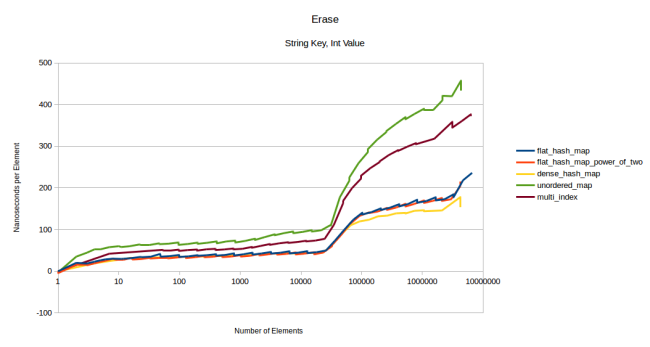
1024 , .
— «, , » . 10 ., 10 . 10 . . - 32 :
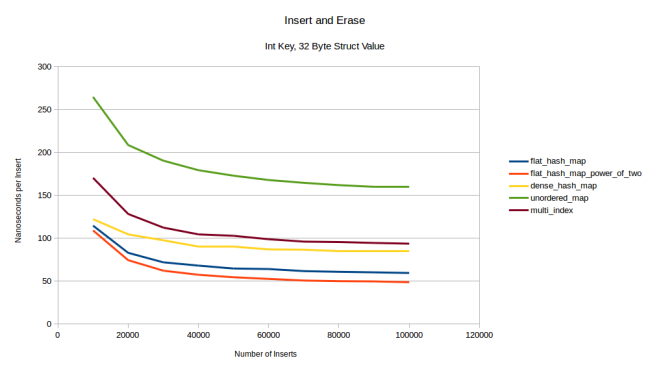
flat_hash_map
dense_hash_map
. .
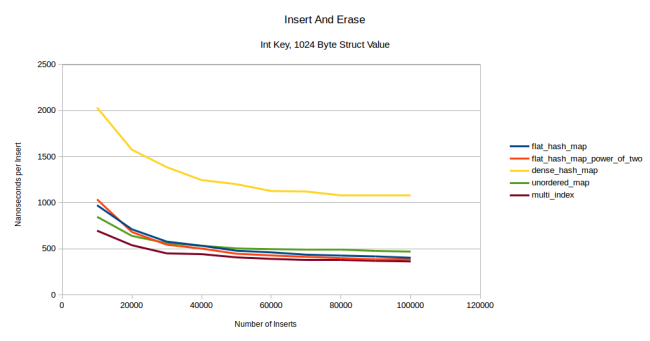
- dense_hash_map
. , . , reserve()
, . flat- , — . , unordered_map
- , , multi_index
. , multi_index
:
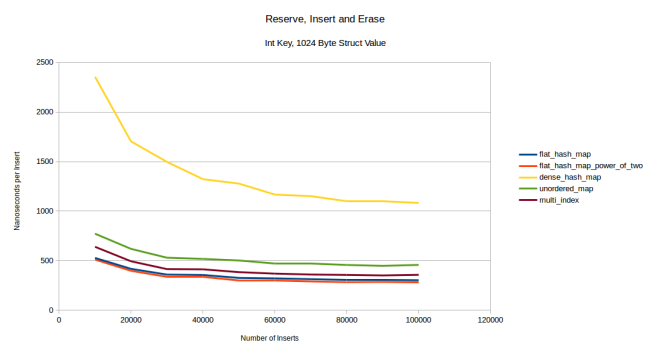
, , 1028 . , : . , , multi_index
:
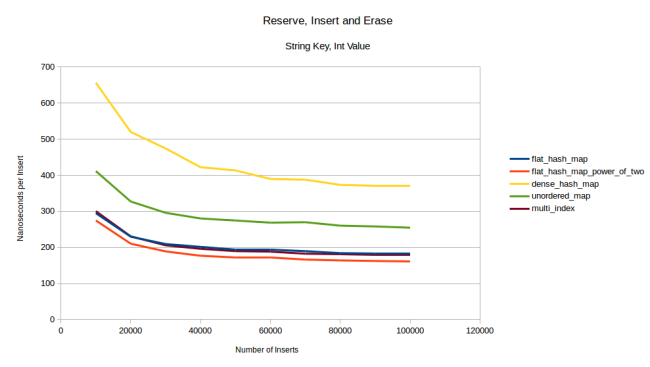
. 32- - . - 1024 , , , , .
, , - . , . . : , , , . . , , :
- , .
- . .
- , , . flat-. flat- .
- , . - .
-
google::dense_hash_map
. -
boost::multi_index
— -. . - , - , , -, .
例外
, , -, (equality function) . (move constructor) . , . , .
Github . Boost-. ska::flat_hash_map
ska::flat_hash_set
. , std::unordered_map
std::unordered_set
.
, . , ska::power_of_two_hash_policy.
, max_load_factor
0,5. 0,9. , . , 70 %, . , max_load_factor
, .
まとめ
, -. . — . log2(n), O(log(n)) O(n). . Robin Hood .
- Boost- hash_map hash_set. !