
2番目のレッスンでは、Pythonでのデータの視覚化に焦点を当てます。 まず、SeabornおよびPlotlyライブラリの主なメソッドを見てから、 最初の記事でおなじみの通信事業者クライアントの流出に関するデータセットを分析し、t-SNEアルゴリズムを使用してn次元空間を覗き込みます。 また、オープンコースの2回目の立ち上げ(2017年9月から11月)の一環として、この記事に基づく講義のビデオ録画もあります。
UPD:現在、コースは英語で、 mlcourse.aiというブランド名で、Medium に関する記事 、Kaggle( Dataset )およびGitHubに関する資料があります 。
これで、記事はかなり長くなります。 準備はいい? 行こう!
この記事の概要
SeabornおよびPlotlyの基本的な方法のデモンストレーション
最初は、いつものように、環境を設定します。必要なすべてのライブラリをインポートし、デフォルトのデフォルト画像表示を設定します。
# Anaconda import warnings warnings.simplefilter('ignore') # jupyter'e %matplotlib inline import seaborn as sns import matplotlib.pyplot as plt # svg %config InlineBackend.figure_format = 'svg' # from pylab import rcParams rcParams['figure.figsize'] = 8, 5 import pandas as pd
その後、 DataFrame
作業するデータをロードします。 例として、 Kaggle Datasetsからビデオゲームの販売データと評価を選択しました。
df = pd.read_csv('../../data/video_games_sales.csv') df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 16719 entries, 0 to 16718 Data columns (total 16 columns): Name 16717 non-null object Platform 16719 non-null object Year_of_Release 16450 non-null float64 Genre 16717 non-null object Publisher 16665 non-null object NA_Sales 16719 non-null float64 EU_Sales 16719 non-null float64 JP_Sales 16719 non-null float64 Other_Sales 16719 non-null float64 Global_Sales 16719 non-null float64 Critic_Score 8137 non-null float64 Critic_Count 8137 non-null float64 User_Score 10015 non-null object User_Count 7590 non-null float64 Developer 10096 non-null object Rating 9950 non-null object dtypes: float64(9), object(7) memory usage: 2.0+ MB
pandas
object
考えるいくつかの兆候object
、明示的にfloat
またはint
キャストされます。
df['User_Score'] = df.User_Score.astype('float64') df['Year_of_Release'] = df.Year_of_Release.astype('int64') df['User_Count'] = df.User_Count.astype('int64') df['Critic_Count'] = df.Critic_Count.astype('int64')
データはすべてのゲームのものではないため、 dropna
メソッドを使用して、ギャップのないレコードのみを残しましょう。
df = df.dropna() print(df.shape)
(6825, 16)
テーブルには6825個のオブジェクトがあり、16個のサインがあります。 head
メソッドを使用して最初のいくつかのエントリを見て、すべてが正しく解析されることを確認しましょう。 便宜上、将来使用する標識のみを残しました。
useful_cols = ['Name', 'Platform', 'Year_of_Release', 'Genre', 'Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count', 'Rating' ] df[useful_cols].head()

seaborn
およびplotly
のメソッドに移る前に、 seaborn
からデータを視覚化する最も簡単で便利な方法について説明しpandas DataFrame
関数を使用しplot
。
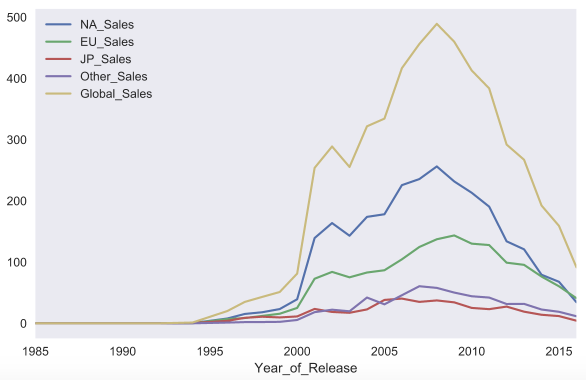
たとえば、年に応じてさまざまな国でビデオゲームの販売スケジュールを作成します。 最初に、必要な列のみをフィルターで除外し、年DataFrame
の総売上を計算し、結果のDataFrame
パラメーターなしでplot
関数を呼び出します。
sales_df = df[[x for x in df.columns if 'Sales' in x] + ['Year_of_Release']] sales_df.groupby('Year_of_Release').sum().plot()
pandas
のplot
関数の実装は、 matplotlib
ライブラリに基づいています。
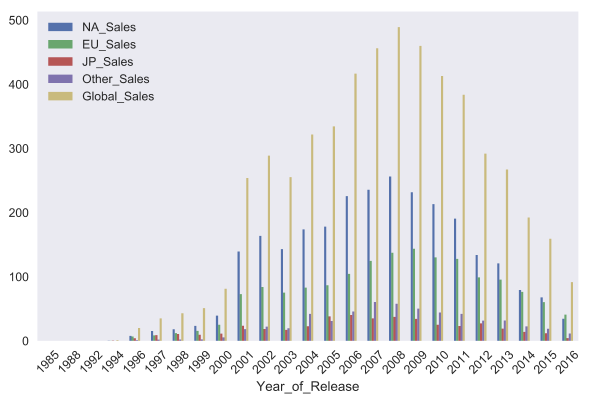
kind
パラメーターを使用して、チャートのタイプをbar chart
などに変更できbar chart
。 Matplotlib
は、非常に柔軟なグラフィックのカスタマイズを可能にします。 グラフでは、ほとんど何でも変更できますが、ドキュメントをざっと調べて必要なパラメーターを見つける必要があります。 たとえば、 rot
パラメーターは、 x
軸に対するラベルの勾配を担当します。
sales_df.groupby('Year_of_Release').sum().plot(kind='bar', rot=45)
シーボーン
それでは、 seaborn
ライブラリーに移りましょう。 Seaborn
は、本質的にmatplotlib
ライブラリに基づいた高レベルAPIです。 Seaborn
は、より適切なデフォルトのチャート設定が含まれています。 また、ライブラリには、 matplotlib
では多くのコードを必要とする非常に複雑なタイプの視覚化があります。
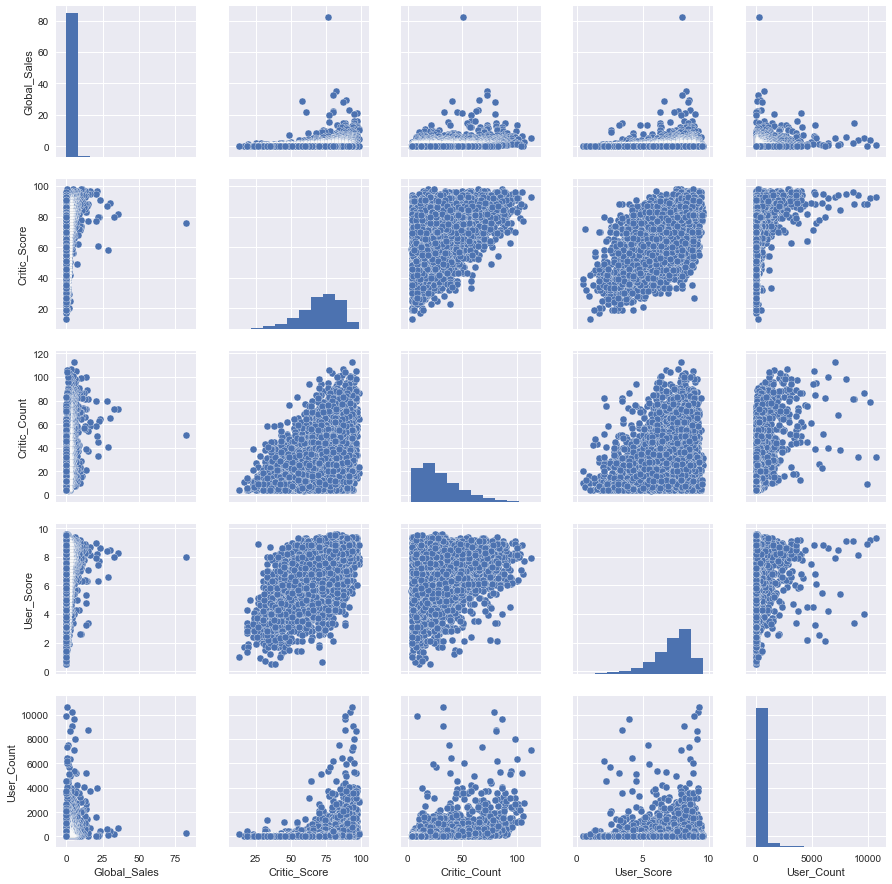
最初のそのような「複雑な」タイプのグラフpair plot
( scatter plot matrix
)をscatter plot matrix
ましょう。 この視覚化は、さまざまな機能がどのように関連しているかを1つの図で見るのに役立ちます。
cols = ['Global_Sales', 'Critic_Score', 'Critic_Count', 'User_Score', 'User_Count'] sns_plot = sns.pairplot(df[cols]) sns_plot.savefig('pairplot.png')
ご覧のとおり、属性の分布のヒストグラムはグラフマトリックスの対角線上にあります。 残りのグラフは、対応する記号のペアの通常のscatter plots
です。
グラフをファイルに保存するには、 savefig
メソッドを使用します。
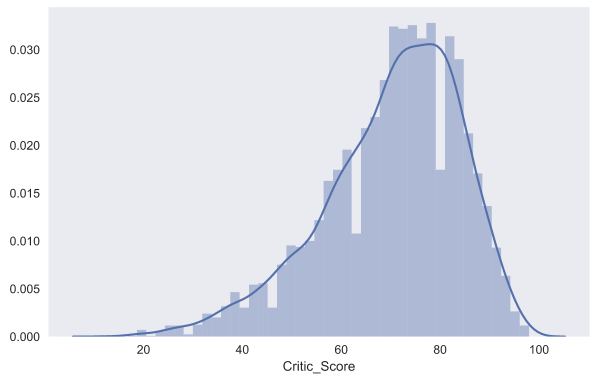
seaborn
、 dist plot
分布を構築することもできます。 例として、批評家の評価Critic_Score
分布を見てみましょう。 デフォルトでは、グラフにはヒストグラムとカーネル密度の推定が表示されます。
sns.distplot(df.Critic_Score)
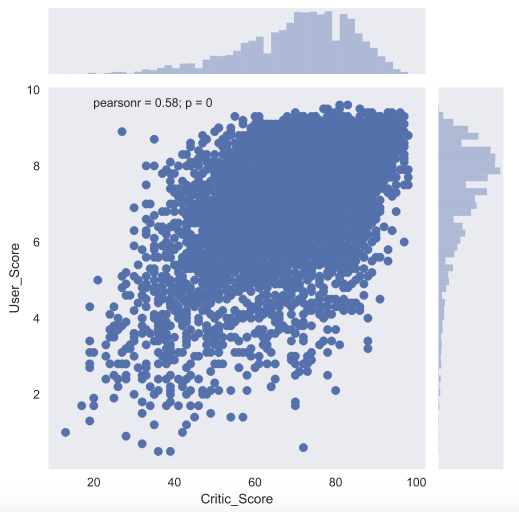
2つの数値記号の関係を詳しく見るために、 joint plot
もありjoint plot
これはscatter plot
とhistogram
ハイブリッドです。 Critic_Score
評論家のCritic_Score
とUser_Score
ユーザーの評価がどのようにCritic_Score
しているか見てみましょう。
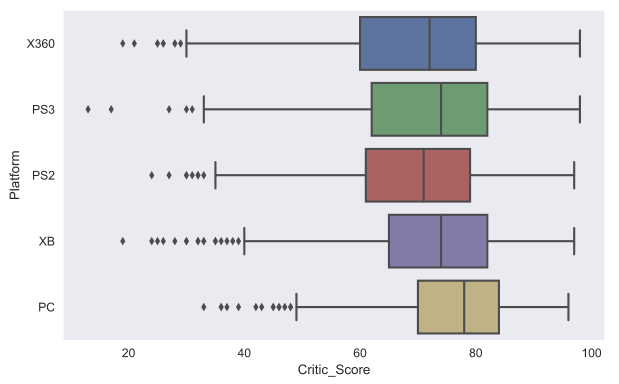
別の便利な種類のチャートはbox plot
です。 上位5大ゲームプラットフォームの批評家のゲーム評価を比較しましょう。
top_platforms = df.Platform.value_counts().sort_values(ascending = False).head(5).index.values sns.boxplot(y="Platform", x="Critic_Score", data=df[df.Platform.isin(top_platforms)], orient="h")
box plot
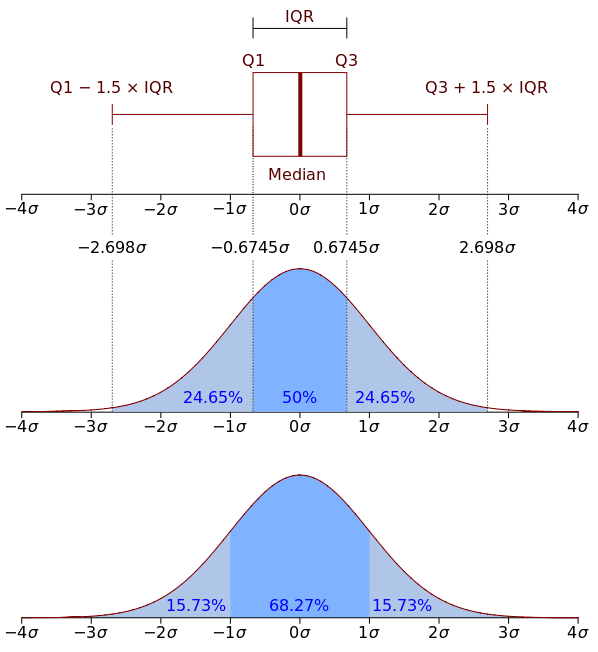
理解方法についてもう少し詳しく説明する価値があると思いbox plot
。 Box plot
は、ボックス( box plot
と呼ばれる理由)、アンテナ、ポイントで構成されます。 ボックスには、分布の四分位範囲、つまりそれぞれ25%( Q1
)および75%( Q3
)パーセンタイルが表示されます。 ボックス内のダッシュは、分布の中央値を示します。
ボックスが整理されたら、口ひげに移りましょう。 ひげは、外れ値を除く点の散布全体、つまり、間隔(Q1 - 1.5*IQR, Q3 + 1.5*IQR)
に入る最小値と最大値を表します。ここで、 IQR = Q3 - Q1
は四分位範囲です。 グラフ上のドットはoutliers
示します-グラフの口ひげで指定された値の範囲に収まらない値。
理解するために、一度見たほうが良いので、ここにウィキペディアの写真もあります:
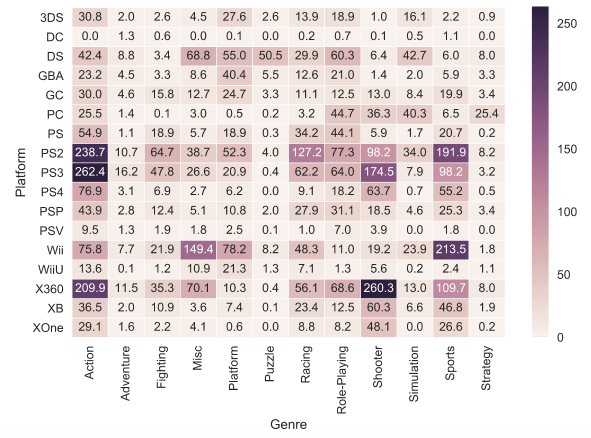
また、別のタイプのグラフ(この記事で検討する最後のグラフ)はheat map
です。 Heat map
使用すると、2つのカテゴリに応じた数値特性の分布を確認できます。 ジャンルとゲームプラットフォーム別にゲームの総売上を視覚化します。
platform_genre_sales = df.pivot_table( index='Platform', columns='Genre', values='Global_Sales', aggfunc=sum).fillna(0).applymap(float) sns.heatmap(platform_genre_sales, annot=True, fmt=".1f", linewidths=.5)
プロットリー
matplotlib
ライブラリに基づいて視覚化を検討しました。 ただし、これはpython
でグラフを作成するための唯一のオプションではありません。 また、 plotly
ライブラリについてもplotly
しましょう。 Plotly
は、javascriptコードを掘り下げることなくjupyter.notebook'eでインタラクティブなグラフィックを構築できるオープンソースライブラリです。
インタラクティブグラフの利点は、マウスをポイントしたときに正確な数値を表示したり、視覚化で重要でないシリーズを非表示にしたり、グラフの特定のセクションを拡大したりできることです。
作業を開始する前に、必要なすべてのモジュールをインポートし、 init_notebook_mode
を使用してinit_notebook_mode
を初期化します。
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot import plotly import plotly.graph_objs as go init_notebook_mode(connected=True)
まず、リリースされたゲームの数とその年ごとの売り上げのダイナミクスを含むline plot
を作成します。
# years_df = df.groupby('Year_of_Release')[['Global_Sales']].sum().join( df.groupby('Year_of_Release')[['Name']].count() ) years_df.columns = ['Global_Sales', 'Number_of_Games'] # trace0 = go.Scatter( x=years_df.index, y=years_df.Global_Sales, name='Global Sales' ) # trace1 = go.Scatter( x=years_df.index, y=years_df.Number_of_Games, name='Number of games released' ) # title layout data = [trace0, trace1] layout = {'title': 'Statistics of video games'} # c Figure fig = go.Figure(data=data, layout=layout) iplot(fig, show_link=False)
plotly
は、 Figure
オブジェクトの視覚化が構築されます。これは、データ(ライブラリ内でtraces
と呼ばれる行の配列)と、 layout
オブジェクトが担当するデザイン/スタイルで構成されlayout
。 単純な場合、 iplot
関数をiplot
配列からのみ呼び出すことができます。
show_link
パラメーターshow_link
、チャート上のplot.lyオンラインプラットフォームへのリンクを担当します。 通常、この機能は必要ないため、偶発的なクリックを防ぐために非表示にすることを好みます。
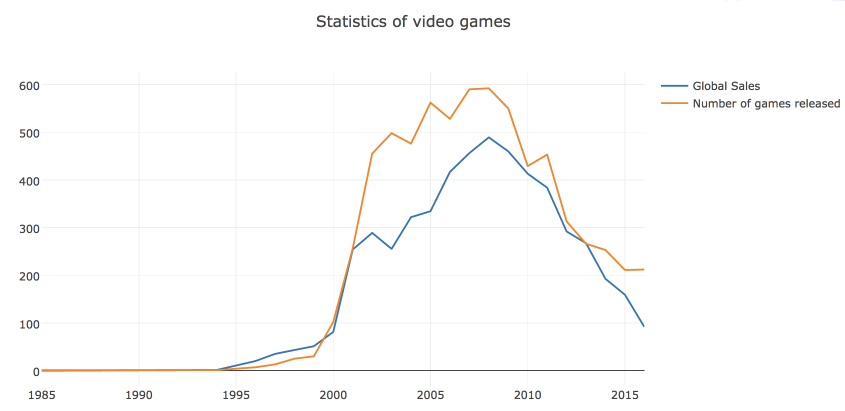
チャートをすぐにhtmlファイルとして保存できます。
plotly.offline.plot(fig, filename='years_stats.html', show_link=False)
また、リリースされたゲームの数と総収益によって計算されたゲームプラットフォームの市場シェアも見てみましょう。 これを行うには、 bar chart
作成しbar chart
。
# platforms_df = df.groupby('Platform')[['Global_Sales']].sum().join( df.groupby('Platform')[['Name']].count() ) platforms_df.columns = ['Global_Sales', 'Number_of_Games'] platforms_df.sort_values('Global_Sales', ascending=False, inplace=True) # traces trace0 = go.Bar( x=platforms_df.index, y=platforms_df.Global_Sales, name='Global Sales' ) trace1 = go.Bar( x=platforms_df.index, y=platforms_df.Number_of_Games, name='Number of games released' ) # title x layout data = [trace0, trace1] layout = {'title': 'Share of platforms', 'xaxis': {'title': 'platform'}} # Figure fig = go.Figure(data=data, layout=layout) iplot(fig, show_link=False)
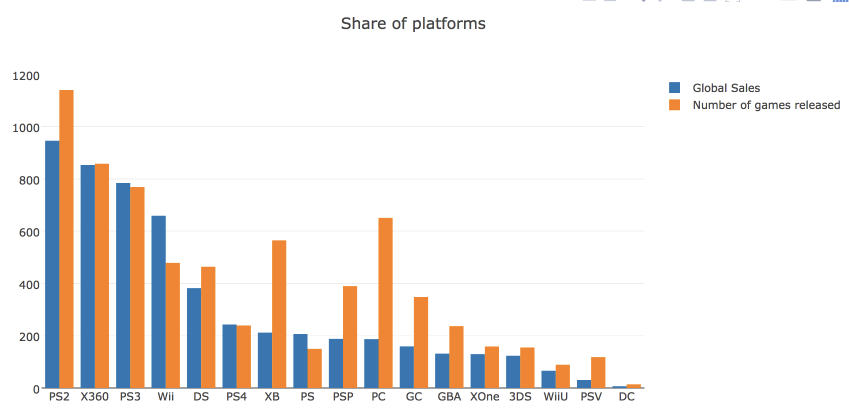
plotly
、 box plot
も作成できbox plot
。 ゲームのジャンルに応じた批評家の評価の分布を考慮してください。
# Box trace data = [] for genre in df.Genre.unique(): data.append( go.Box(y=df[df.Genre==genre].Critic_Score, name=genre) ) # iplot(data, show_link = False)
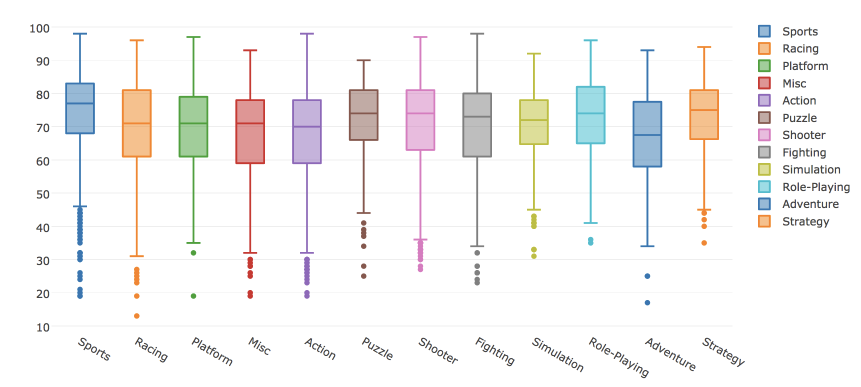
plotly
を使用すると、他の種類の視覚化を構築できます。 グラフはデフォルトの設定でかなりいいです。 ただし、ライブラリを使用すると、色、フォント、署名、注釈など、さまざまな視覚化オプションを柔軟に構成できます。
視覚データ分析の例
テレコムオペレータークライアントの流出に関する最初の記事で私たちがよく知っているDataFrame
読み込みます。
df = pd.read_csv('../../data/telecom_churn.csv')
すべてが正常と見なされたかどうかを確認しましょう-最初の5行を見てみましょう( head
メソッド)。
df.head()

行(クライアント)と列(特性)の数:
df.shape
(3333, 20)
兆候を見て、それらのいずれにもギャップがないことを確認しましょう-どこでも3333エントリ。
df.info()
<class 'pandas.core.frame.DataFrame'> RangeIndex: 3333 entries, 0 to 3332 Data columns (total 20 columns): State 3333 non-null object Account length 3333 non-null int64 Area code 3333 non-null int64 International plan 3333 non-null object Voice mail plan 3333 non-null object Number vmail messages 3333 non-null int64 Total day minutes 3333 non-null float64 Total day calls 3333 non-null int64 Total day charge 3333 non-null float64 Total eve minutes 3333 non-null float64 Total eve calls 3333 non-null int64 Total eve charge 3333 non-null float64 Total night minutes 3333 non-null float64 Total night calls 3333 non-null int64 Total night charge 3333 non-null float64 Total intl minutes 3333 non-null float64 Total intl calls 3333 non-null int64 Total intl charge 3333 non-null float64 Customer service calls 3333 non-null int64 Churn 3333 non-null bool dtypes: bool(1), float64(8), int64(8), object(3) memory usage: 498.1+ KB
| 役職 | 説明 | 種類 |
|---|---|---|
| 都道府県 | 州の手紙コード | カテゴリー |
| アカウントの長さ | 会社が顧客にサービスを提供している期間 | 定量的 |
| 市外局番 | 電話番号のプレフィックス | 定量的 |
| 国際計画 | 国際ローミング(接続済み/未接続) | バイナリ |
| ボイスメールプラン | ボイスメール(接続済み/未接続) | バイナリ |
| vmailメッセージの数 | 音声メッセージの数 | 定量的 |
| 総日分 | 日中の会話の合計時間 | 定量的 |
| 合計日通話 | 日中の通話の総数 | 定量的 |
| 合計日料金 | 日中のサービスの支払い総額 | 定量的 |
| 合計前夜 | 夕方の合計会話時間 | 定量的 |
| 総通話数 | 合計夜の呼び出し | 定量的 |
| 前夜料金 | 夜の合計サービス料 | 定量的 |
| 総夜数 | 夜の会話の合計時間 | 定量的 |
| 合計夜間通話 | 夜の合計通話数 | 定量的 |
| 合計宿泊料金 | 夜のサービスの合計支払い額 | 定量的 |
| 合計国際分 | 国際通話の合計時間 | 定量的 |
| 合計国際電話 | 合計国際電話 | 定量的 |
| 合計料金 | 国際通話料金の合計 | 定量的 |
| カスタマーサービスコール | サービスセンターへの呼び出し回数 | 定量的 |
ターゲット変数: チャーン -流出の兆候、バイナリ(1-クライアントの損失、つまり流出)。 次に、この機能を残りから予測するモデルを構築します。これがターゲットと呼ばれる理由です。
ターゲットクラスの分布、つまり顧客の流出を見てみましょう。
df['Churn'].value_counts()
False 2850 True 483 Name: Churn, dtype: int64
df['Churn'].value_counts().plot(kind='bar', label='Churn') plt.legend() plt.title(' ');
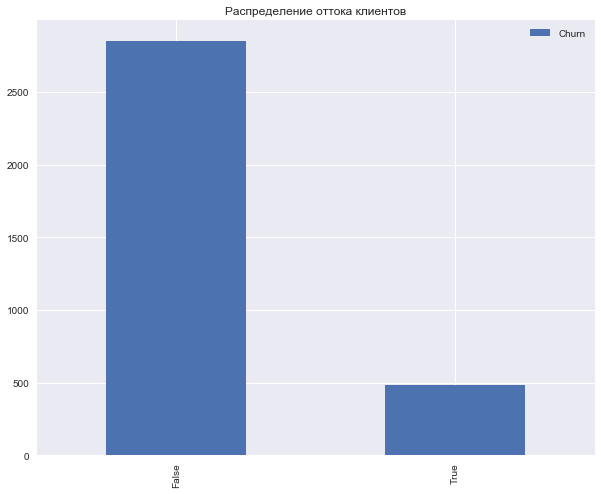
次のグループのサインを区別します( チャーンを除くすべて)。
- バイナリ: 国際プラン 、 ボイスメールプラン
- カテゴリ: 状態
- 順序: カスタマーサービスの呼び出し
- 定量的:全員
量的形質の相関関係を見てみましょう。 色付きの相関行列は、 総日料金などの兆候が話された分( 総日分 )によって考慮されることを示しています。 つまり、4つの標識は捨てることができますが、有用な情報は伝達されません。
corr_matrix = df.drop(['State', 'International plan', 'Voice mail plan', 'Area code'], axis=1).corr()
sns.heatmap(corr_matrix);
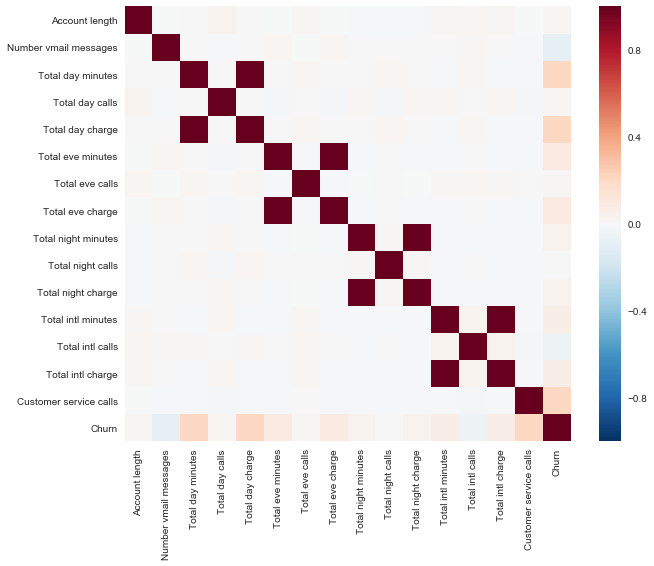
次に、関心のあるすべての量的特性の分布を見てみましょう。 バイナリ/カテゴリ/順序の記号を個別に見ていきます。
features = list(set(df.columns) - set(['State', 'International plan', 'Voice mail plan', 'Area code', 'Total day charge', 'Total eve charge', 'Total night charge', 'Total intl charge', 'Churn'])) df[features].hist(figsize=(20,12));

ほとんどのサインは正常に分布していることがわかります。 例外は、カスタマーサービスセンターへのコールの数(ここではポアソン分布の方が適しています)およびボイスメッセージの数 ( 番号vmailメッセージ 、ゼロでピーク、つまりボイスメールがない人)です。 国際電話の数の分布( Total intl calls )も偏っています。
標識の分布が主な対角線上に描かれ、標識のペアの散布図が主な対角線の外側に描かれるような画像を構築することは依然として有用です。 これにより、いくつかの結論に至ることがありますが、この場合、驚くことなくすべてがほぼ明確です。
sns.pairplot(df[features + ['Churn']], hue='Churn');

次に、兆候がどのようにターゲットに関連付けられているかを確認します-流出。
忠実な顧客と去った顧客の間の2つのグループでの量的属性の分布の統計を記述する箱ひげ図を作成しましょう。
fig, axes = plt.subplots(nrows=3, ncols=4, figsize=(16, 10)) for idx, feat in enumerate(features): sns.boxplot(x='Churn', y=feat, data=df, ax=axes[idx / 4, idx % 4]) axes[idx / 4, idx % 4].legend() axes[idx / 4, idx % 4].set_xlabel('Churn') axes[idx / 4, idx % 4].set_ylabel(feat);

一見すると、「 合計日数」 、「 カスタマーサービスコール」 、および「 vmailメッセージの数」の兆候が最も大きく異なります 。 続いて、ランダムフォレスト(または勾配ブースティング)を使用して分類問題の特徴の重要性を判断する方法を学習します。最初の2つは流出を予測するための非常に重要な特徴であることがわかります。
忠実な/出発した人の間で日中に話された分数の分布で写真を別々に見てみましょう。 左側には私たちにとって馴染みのある箱ひげ図があり、右側には2つのグループの数値記号の分布の平滑化されたヒストグラムがあります(きれいな画像ではなく、箱ひげ図からすべてがはっきりしています)。
興味深い観察:平均して、去った顧客はコミュニケーションをより多く使用します。 おそらく彼らは関税に不満を抱いており、流出と戦うための対策の1つは関税率(モバイル通信のコスト)を下げることでしょう。 しかし、このような措置が本当に正当化されるかどうか、企業は追加の経済分析を行う必要があります。
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) sns.boxplot(x='Churn', y='Total day minutes', data=df, ax=axes[0]); sns.violinplot(x='Churn', y='Total day minutes', data=df, ax=axes[1]);

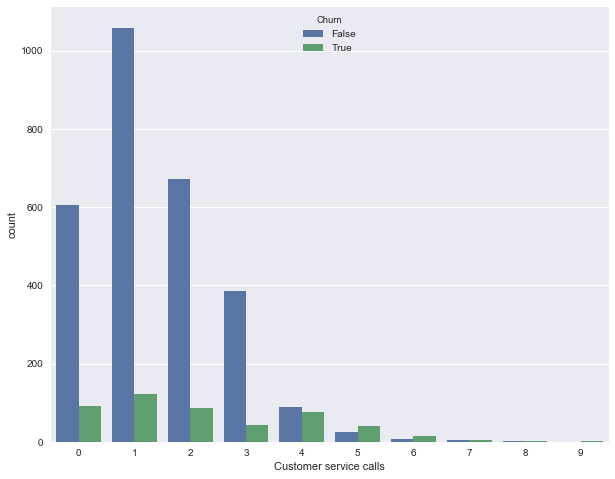
次に、サービスセンターへの呼び出し数の分布を示します(最初の記事でそのような図を作成しました)。 属性の一意の値は多くありません(属性は量的整数または順序と見なすことができます) countplot
を使用して分布をより明確に表します。 観察:流出の割合は、サービスセンターへの4回の呼び出しから大きく増加します。
sns.countplot(x='Customer service calls', hue='Churn', data=df);
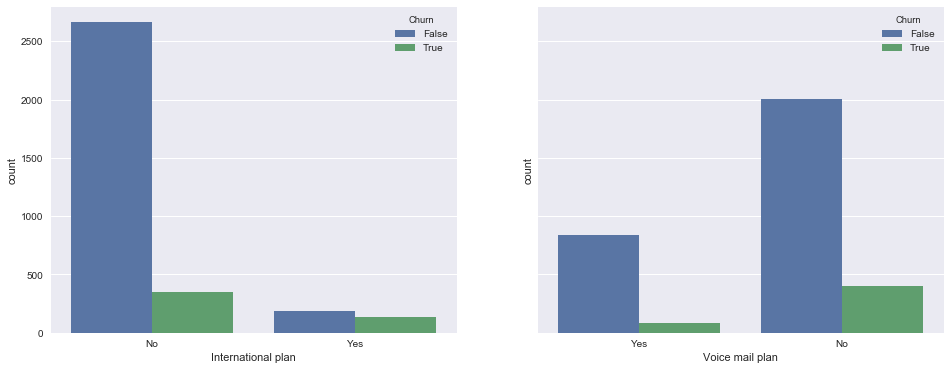
ここで、 国際計画およびボイスメール計画のバイナリサインと流出との関係を見てみましょう。 観察 :ローミングが接続されている場合、流出率ははるかに高くなります。 国際ローミングは強力な兆候です。 これは、ボイスメールには当てはまりません。
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) sns.countplot(x='International plan', hue='Churn', data=df, ax=axes[0]); sns.countplot(x='Voice mail plan', hue='Churn', data=df, ax=axes[1]);
最後に、カテゴリ属性Stateがどのように流出に関連付けられているかを見てみましょう。 ユニークな州の数は非常に多いため、彼と一緒に仕事をするのはそれほど快適ではありません-51。最初にサマリープレートを作成するか、各州の流出の割合を計算できます。 ただし、各州のデータは個別に十分ではないため(各州には3〜17人の出発顧客しかありません)、したがって、おそらく再訓練のリスクがあるため、 State属性を分類モデルに追加すべきではありません(ただし、 クロス検証についてはこれをチェックします、ご期待ください!)。
各状態の流出率:
df.groupby(['State'])['Churn'].agg([np.mean]).sort_values(by='mean', ascending=False).T


ニュージャージー州とカリフォルニア州では流出の割合が25%を超えていますが、ハワイとアラスカでは5%未満であることがわかります。 しかし、これらの結論はあまりにも控えめな統計に基づいており、おそらくこれらは利用可能なデータの特徴にすぎません(ここでは、MatthewsとCramerの相関関係に関する仮説を確認できますが、これはこの記事の範囲外です)。
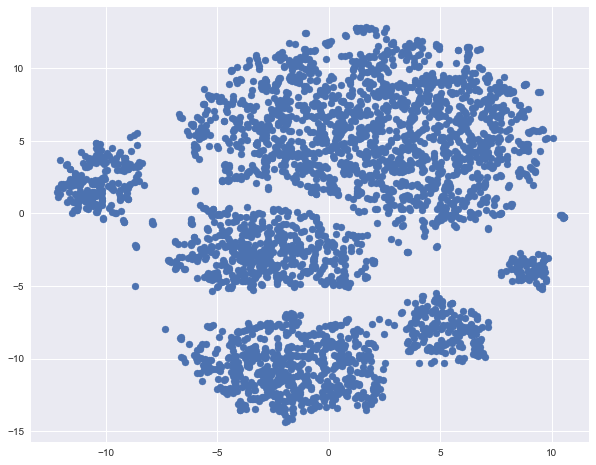
t-SNEを使用したn次元空間の覗き見
同じ流出データのt-SNE表現を作成します。 メソッドの名前は複雑です-t分布のStohastic Neighbor Embedding、数学もクールです(そして、私たちはそれには入りませんが、 これは D.ヒントンとJMLRの大学院生によるオリジナルの記事です)。多次元の特徴空間から平面まで(または3Dですが、ほとんどの場合2Dが選択されます)、平面上で互いに離れているポイントも遠くにあり、近いポイントも近くに表示されます。 つまり、近傍埋め込みは、近傍が保存されているデータの新しい表現の一種の検索です。
いくつかの詳細:状態と流出の兆候をpd.factorize
ます。バイナリのYes / No兆候は数字に変換されます( pd.factorize
)。 また、選択をスケーリングする必要があります-各フィーチャから平均を減算し、標準偏差で除算します。これはStandardScaler
によって行われます。
from sklearn.manifold import TSNE from sklearn.preprocessing import StandardScaler
# , X = df.drop(['Churn', 'State'], axis=1) X['International plan'] = pd.factorize(X['International plan'])[0] X['Voice mail plan'] = pd.factorize(X['Voice mail plan'])[0] scaler = StandardScaler() X_scaled = scaler.fit_transform(X)
%%time tsne = TSNE(random_state=17) tsne_representation = tsne.fit_transform(X_scaled)
CPU times: user 20 s, sys: 2.41 s, total: 22.4 s Wall time: 21.9 s
plt.scatter(tsne_representation[:, 0], tsne_representation[:, 1]);
結果の流出データのt-SNE表現を色付けします(青-忠実、オレンジ-出発した顧客)。
plt.scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['Churn'].map({0: 'blue', 1: 'orange'}));

出発した顧客は、属性空間の一部の領域で主に「グループ化」されていることがわかります。
画像をよりよく理解するために、ローミングとボイスメールなど、バイナリ記号の残りの部分で色を付けることもできます。 青い領域は、このバイナリ機能を持つオブジェクトに対応しています。
_, axes = plt.subplots(1, 2, sharey=True, figsize=(16,6)) axes[0].scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['International plan'].map({'Yes': 'blue', 'No': 'orange'})); axes[1].scatter(tsne_representation[:, 0], tsne_representation[:, 1], c=df['Voice mail plan'].map({'Yes': 'blue', 'No': 'orange'})); axes[0].set_title('International plan'); axes[1].set_title('Voice mail plan');
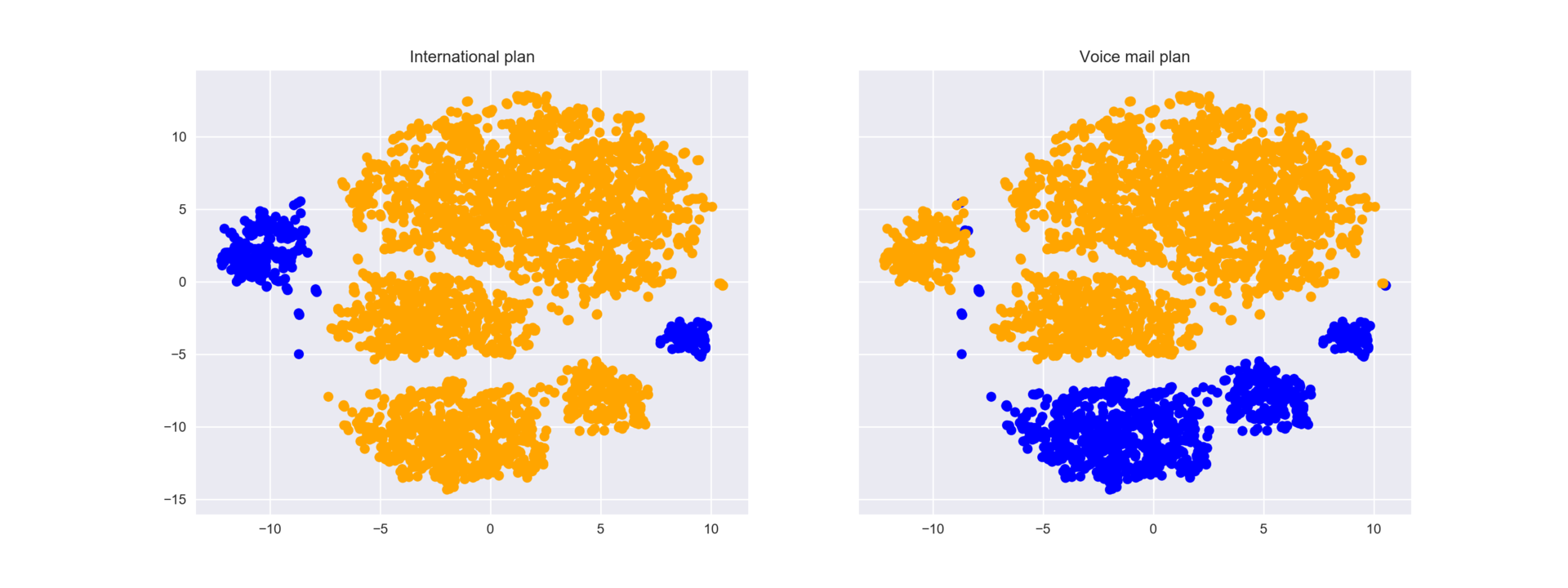
たとえば、ローミングがオフになっているがボイスメールがない状態で、多くの退去した顧客が左の人々の集まりにグループ化されていることは明らかです。
最後に、t-SNEの欠点に注意します(はい、別の記事を書くことをお勧めします)。
- 計算の複雑さ。
sklearn
, Multicore-TSNE ; -
random seed
, . t-SNE. – . - , .


№ 2
– . - ( ).
- – Medium story
- ,
seaborn
-
plotly
: , - ,
plotly
python . c , , drop-down menu.
yorko ( ).