外部オブザーバーの結果はそれほど印象的ではありませんが、それほど重要ではありません。機械学習の自動化という別の傾向があります。 その急速な発展に関連して、データ科学者が最終的に自動化され、人工知能に取って代わられるかどうかという問題が再び重要になります。
アメリカの調査およびコンサルティング会社Gartnerの推定によると、2020年までに、ビッグデータおよびデータサイエンスの分野のタスクの40%以上が自動化されます。 この見積もりが誇張されていなくても、ビッグデータおよび機械学習の専門家にとって心配することはありません。 この意見は、自動機械学習システムの開発者自身を含むほとんどの専門家によって共有されています。
実際、会社でのアナリストの役割は、彼が使用する高度な分析ツールに関係なく、これらのツールの使用に限定されないということです。 最も一般的なCRISP-DMデータ分析プロジェクト管理方法論によると、データ分析プロジェクトの実装には6つのフェーズが含まれ、各フェーズにはアナリストまたはデータサイエンティストが直接関与しています。
- ビジネス目標を理解する(ビジネス理解)
- データの初期調査(データ理解)
- データ準備
- モデリング
- 評価
- 展開
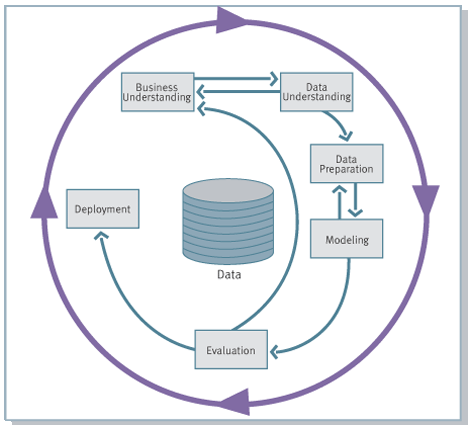
ステップ3と4には、多くのルーチン作業が含まれます。 機械学習を使用して特定のケースを解決するには、常に以下を行う必要があります。
- モデルのハイパーパラメーターを構成します。
- 新しいアルゴリズムを試してください。
- モデルに元の機能のさまざまな表現を追加します(標準化、分散の安定化、単調変換、次元削減、カテゴリ変数のコーディング、既存の機能からの新しい機能の作成など)。
これらの日常的な操作は、データ、アナリスト、またはデータサイエンティストの準備と消去の操作の一部と同様に、自動化の助けを借りて排除できます。 ただし、他のすべてのパート3、4、およびCRISP-DMの残りの手順は保持されるため、アナリストの日常業務のこのような単純化は、この職業に脅威をもたらすことはありません。
機械学習は、視覚化、データの調査、統計的手法および計量経済学的手法に加えて、データサイエンティストのツールの1つにすぎません。 その中でも、完全な自動化は不可能です。 データサイエンティストの高い役割は、新しいアルゴリズムとその組み合わせの開発と応用における非標準の問題を解決することに間違いなく残るでしょう。 自動化されたアルゴリズムは、すべての標準的な組み合わせをソートし、資格のある専門家が基礎としてさらに改善できる基本的なソリューションを生成できます。 ただし、多くの場合、自動アルゴリズムの結果は追加の改善なしで十分であり、直接使用できます。
ビジネスがアナリストの助けなしに自動化された機械学習の結果を使用できるようになることはほとんど期待できません。 いずれにしても、データの準備、結果の解釈、および上記のスキームの他の段階が必要になります。 同時に、今日の多くの企業には、常にデータを操作し、適切な考え方を持つアナリストがおり、主題分野に精通していますが、必要なレベルの機械学習方法を所有していません。 業界企業にとって、需要が増え続けており、多くの場合、供給を上回っている、高い資格を持ち、高給の機械学習の専門家を引き付けることはしばしば困難です。 ここでの解決策は、会社のアナリストが自動機械学習ツールにアクセスできるようにすることです。 これは、自動化によって作成された技術の民主化の効果になります。 将来的には、高度な専門家チームの形成やコンサルティング会社の関与なしに、多くの企業がビッグデータの利点を利用できるようになります。
現在まで、自動機械学習の最も効果的な2つのパッケージを区別できます。 どちらもPythonの機械語ライブラリsklearnを使用しており、積極的に開発されています。
これらの最初のものは、フライブルク大学で開発されたAuto-sklearnライブラリです。 このパッケージは、最近開催された自動機械学習アルゴリズムコンテストのKDNuggetsポータルの勝者であり、 ChaLearn AutoMLチャレンジコンペティションのautoおよびtweakathonタスクでも最高の結果を示しました。 Auto-sklearnは、ベイズ最適化を使用してモデル選択とハイパーパラメーター最適化を自動化し、メタトレーニングを使用してモデルのアンサンブルを構築し、変数コーディングと次元削減の方法を含むデータ前処理を自動化します。 自動sklearnはLinuxでのみ機能し、sklearnライブラリをインストールする必要があります。 ライブラリは分散コンピューティングをサポートしています。 Auto-sklearnは公式のGitHubリポジトリからダウンロードできます 。パッケージのドキュメントはこちらにあります 。 Auto-sklearn分類器を既知のMNISTデータセット(手書きの数字の認識)に適用すると、約1時間かかり、出力で98%以上の精度が得られます。
自動機械学習の分野における2番目の主要なソリューションは、 TPOTライブラリです。 前回レビューしたパッケージとの主な違いは次のとおりです。
- ベイズ最適化の代わりに、遺伝的プログラミングが使用されます。モデルでは、ダーウィンの自然選択のようなものが行われます。
- XGBoostツリー上の勾配ブースティングのよく知られたライブラリがサポートされています。
- オペレーティングシステムに制限はありません。
- Auto-sklearnとは異なり、出力のTPOTは、最終的なトレーニング済みモデルだけでなく、実装の準備が整ったPython言語で最適なモデル(パイプライン)を構築するためのすべてのステップのコードも生成します。
プリセットなしの同じMNISTデータセットのTPOT精度は98.4%です。

上記のパッケージは、Python言語とそのライブラリとともに使用されます。これは、一部のアナリストや他の専門家の専門家にとって障害となる可能性があります。 Amazon Machine LearningやBigMLなどの最大規模のクラウドサービスの一部は、誰にとっても機械学習をさらに手頃な価格にしようとしています。 このようなサービスのユーザーは、機械学習アルゴリズムとデータ前処理の知識を必要としません。モデルを構築するプロセスで必要なすべてのヒント、説明、視覚化を受け取ります。 このようなクラウドサービスは、特定の企業には存在しない可能性のある大量のデータを格納および処理するための、既に展開され、すぐに使用できるインフラストラクチャを提供します。 ただし、その欠点は、使用されるアルゴリズムと最適化方法のセットが限られていることです。 たとえば、BigMLは決定木に焦点を当てており、Amazon Machine Learningは確率的勾配降下に基づく分類子のみを使用します。 このようなクラウドサービスは、あらゆる状況で可能な限り最高のモデルを取得するのではなく、標準タスクに対してかなり優れたソリューションを構築するように設計されています。
上記で説明したPythonライブラリと機能が似ている、より高度なクラウドベースの自動機械学習サービスがあります。 その中でも、 DataRobotサービスは特に際立っています。 Pythonの自動機械学習ライブラリに対する利点は、直感的なWebインターフェース、R、sklearn、Spark、XGBoost、H20、ThensorFlow、Vowpal Wabbit、およびその他のシステムの最高のアルゴリズムを1つのモデルに組み合わせることができ、データ分析と処理に必要なインフラストラクチャを提供することです、モデルの構築段階と最終結果の視覚化。 DataRobotは、テキストの統計処理を自動的に実行し、変数のタイプを自動的に決定し、必要に応じてそれらをエンコードし、必要な変換を適用し、新しい機能を自動的に構築し、ハイパーパラメーターを選択するためのインテリジェントな方法を使用し、幅広い利用可能なメトリックを使用してモデルのパフォーマンスを評価します 並列計算がサポートされており、モデルのトレーニングとアプリケーションの速度が向上します。システムには、構築されたモデルの迅速かつ簡単な実装のためのツールがあります。
DataRobotサービスは最も普遍的であり、それに加えて、特定の分野で機械学習を自動化および民主化するために多くのクラウドサービスが開発されています。 たとえば、 ThingWorx Analyticsシステムは、主に機器の動作を追跡し、故障を予測し、その動作を最適化するために、モノのインターネットの分野で機械学習を自動化するように設計されています。ContextRelevantは、サイバーセキュリティおよび不正防止の分野で自動化されたソリューションを提供します。
データサイエンティストの職業の未来はまだ曖昧であり、専門家の判断の対象となります。 しかし、自動化された機械学習の結果を今すぐ使用することを誰も気にしません。 自動機械学習は、現在の職場で機械学習の適用を開始するための簡単なステップです。また、既にデータ科学者として働いている場合は、日々の責任を大幅に簡素化します。
機械学習とデータ分析の分野の専門家に対する需要は常に高まっており、技術の民主化につながる機械学習の自動化は、その使用を拡大するだけです。 今日、ほとんどの人がUcozなどのサイトビルダーを使用して美しいサイトを作成できます。 ただし、そのようなデザイナーが存在しなかった当時からのWebデザイナーと開発者への需要は完全には落ちていませんが、逆に、何度も増加しています。 利用可能なWeb開発ツールの範囲が大幅に充実し、ツール自体がより複雑で機能的になりました。 データ分析がウェブサイトを作成するのと同じくらい企業にとってアクセスしやすくなると仮定すると、この分野の高級専門家に対する需要は数年後にどのようになるか想像できます。
3月16日に「ビッグデータスペシャリスト」 プログラムが開始されますので、お会いできてうれしいです。