パイロットパートでは、タスクについてできる限り詳細に説明しました。 ストーリーは長くて意味のないものであることが判明しました。コードは1行もありませんでした。 しかし、タスクを理解しなければ、最適化を行うことは非常に困難です。 もちろん、一部の手法は、手元のコードのみで適用できます。 たとえば、キャッシュの計算、分岐を減らします。 しかし、私には、タスクを理解しないとできないことがあるようです。 これにより、人と最適化コンパイラが区別されます。 したがって、手動の最適化は依然として大きな役割を果たします。コンパイラにはコードのみがあり、人はタスクを理解しています。 コンパイラは、値「4」が十分にランダムであると判断することはできませんが、人は判断できます。

実生活のPillowライブラリで畳み込み法を使用して画像のサイズ変更操作を最適化することに焦点を当てることを思い出させてください。 数年前に行った変更についてお話します。 しかし、これは単語ごとの繰り返しではありません。最適化はナレーションに都合の良い順序で説明されます。 これらの記事のために、バージョン2.6.2からリポジトリに別のブランチを作成しました。この瞬間から物語が続きます。
テスト中
読むだけでなく、自分で実験したい場合は、 pillow-perfテストパッケージが役立ちます。
# $ sudo apt-get install -y build-essential ccache \ python-dev libjpeg-dev $ git clone -b opt/scalar https://github.com/uploadcare/pillow-simd.git $ git clone --depth 10 https://github.com/python-pillow/pillow-perf.git $ cd ./pillow-simd/ # , $ git checkout bf1df9a # Pillow $ CC="ccache cc" python ./setup.py develop # - $ ../pillow-perf/testsuite/run.py scale -n 3
Pillowは多くのモジュールで構成されており、インクリメンタルにコンパイルする方法がわからないため、ccacheユーティリティを使用して再アセンブリを大幅に高速化します。 Pillow-perfを使用すると、多くの操作をテストできますが、 scale
関心があります。 -n 3
は、操作の開始回数を設定します。 コードは遅いですが、眠りに落ちないように、より小さな数を取ることができます。 起動時のパフォーマンスは次のとおりです。
Scale 2560×1600 RGB image to 320x200 bil 0.08927 s 45.88 Mpx/s to 320x200 bic 0.13073 s 31.33 Mpx/s to 320x200 lzs 0.16436 s 24.92 Mpx/s to 2048x1280 bil 0.40833 s 10.03 Mpx/s to 2048x1280 bic 0.45507 s 9.00 Mpx/s to 2048x1280 lzs 0.52855 s 7.75 Mpx/s to 5478x3424 bil 1.49024 s 2.75 Mpx/s to 5478x3424 bic 1.84503 s 2.22 Mpx/s to 5478x3424 lzs 2.04901 s 2.00 Mpx/s
コミットbf1df9aの結果。
これらの結果は、バージョン2.6の公式ベンチマークで得られた結果とわずかに異なります 。 これにはいくつかの理由があります。
- 公式ベンチマークでは、GCC 5.3で64ビットUbuntu 16.04を使用しています。 GCC 4.8で32ビットUbuntu 14.04を使用します。GCC4.8では、これらの最適化をすべて初めて実行しました。 記事の終わりに、その理由が明らかになります。
- 記事では、最適化に関係しないがパフォーマンスに影響するバグを修正するコミットから話を始めます。
コード構造
興味のあるコードのほとんどは、 ImagingStretch
関数のAntialias.cファイルにあります。 この関数のコードは、3つの部分に分けることができます。
// if (imIn->xsize == imOut->xsize) { // } else { // }
前に言ったように、2つのパスで画像の畳み込みのサイズ変更を行うことができます。最初は画像の幅のみ、2番目は高さ、またはその逆です。 1つの呼び出しのImagingStretch
関数は、どちらか一方だけを実行できます。 ここでは、各サイズ変更中に実際に2回呼び出されることがわかります 。 この関数は、一般的なプロローグを実行し、パラメーターに応じて、この操作またはその操作を実行します。 反復コード(この場合はプロローグ)を削除するためのかなり珍しいアプローチ。
内部では、両方のパスはほぼ同じように見え、処理の方向が変わるように調整されています。 簡潔にするために、1つだけを示します。
for (yy = 0; yy < imOut->ysize; yy++) { // if (imIn->image8) { // 8 } else { switch(imIn->type) { case IMAGING_TYPE_UINT8: // 8 case IMAGING_TYPE_INT32: // 32 case IMAGING_TYPE_FLOAT32: // float } }
Pillowでサポートされるいくつかのピクセル表現形式に分岐しています:シングルチャンネル8ビット(グレースケール)、マルチチャンネル8ビット(RGB、RGBA、LA、CMYK、その他)、シングルチャンネル32ビット、フロート。 これが最も一般的な画像形式であるため、いくつかの8ビットチャネルのループの本体に興味があります。
最適化1:キャッシュを効果的に使用する
上記で2つのパスは似ていると述べましたが、それらの間には明らかな違いがあります。 垂直通路を見てください:
for (yy = 0; yy < imOut->ysize; yy++) { // for (xx = 0; xx < imOut->xsize*4; xx++) { // // imOut->image8[yy][xx] } }
水平通路:
for (xx = 0; xx < imOut->xsize; xx++) { // for (yy = 0; yy < imOut->ysize; yy++) { // // imOut->image8[yy][xx] } }
最終画像の列は、内側のループの垂直方向の通路と、水平方向の行を繰り返します。 水平パスは、プロセッサキャッシュにとって重大な問題です。 内側のループの各ステップで、以下の1行にアクセスします。これは、前のステップで必要な値とは異なるメモリからの値が要求されることを意味します。 畳み込みサイズが小さい場合、これは良くありません。 実際、最新のプロセッサでは、プロセッサがRAMから要求できるキャッシュラインは常に64バイトです。 つまり、畳み込みに関係するピクセルが16ピクセル未満の場合、データの一部がRAMからキャッシュに浪費されます。 ここで、サイクルが逆になり、次のピクセルがラインの下で崩壊せず、同じラインの次のピクセルが崩壊することを想像してください。 その後、必要なピクセルのほとんどが既にキャッシュにあります。
このようなコードの編成の2番目のマイナス要因は、畳み込みの長い行(つまり、大幅な減少)で現れます。 実際には、隣接する畳み込みでは、元のピクセルが非常に大きく交差するため、このデータがキャッシュに残っていればいいでしょう。 しかし、上から下に移動すると、古い畳み込みのデータは、新しい畳み込みのデータによって徐々にキャッシュから追い出され始めます。 その結果、完全な内部ループが通過し、次の外部ステップが開始されると、キャッシュに上部の行が表示されなくなり、すべて下部の行に置き換わります。再びメモリから取得する必要があります。 そして、下位のものになると、キャッシュ内のすべてがすでに上位のものに置き換えられています。 サイクルが判明し、その結果、キャッシュに必要なデータが含まれなくなります。
なぜ迂回はそうなのですか? 上記の擬似コードでは、両方の場合の2行目が畳み込みの係数の計算であることがわかります。 垂直方向の通過の場合、係数は最終画像の行( yy
値)のみに依存し、水平方向の通過の場合は現在の列( xx
値)に依存します。 つまり、水平の通路では、単純に2つのサイクルを交換することはできません。係数の計算は、xxサイクル内にある必要があります。 内部ループ内の係数のカウントを開始すると、すべてのパフォーマンスが低下します。 特に、三角関数があるLanczosフィルターを使用して係数を計算する場合。
各ステップで係数を計算することはできませんが、それでも1列のすべてのピクセルで同じです。 そのため、すべての列についてすべての係数を事前に計算でき、内側のループではすでに計算されています。 やってみましょう。
コードには、係数用のメモリ割り当てがあります。
k = malloc(kmax * sizeof(float));
ここで、このような配列の配列が必要です。 しかし、単純化することは可能です-平らなメモリを割り当てて、2次元のアドレス指定をエミュレートします。
kk = malloc(imOut->xsize * kmax * sizeof(float));
また、 xmin
とxmax
をxxに依存するどこかに格納する必要があります。 それらの下で、再計算しないように配列も作成します。
xbounds = malloc(imOut->xsize * 2 * sizeof(float));
また、ループ内でww
値が使用されます。これは、畳み込み値を正規化するために必要です。 ww = 1 / ∑k [x]。 あなたはそれを全く保存することはできず、畳み込みの結果ではなく、係数自体を正規化します。 つまり、係数を計算した後、もう一度係数を調べて合計で割る必要があります。その結果、すべての係数の合計は1になります。
k = &kk[xx * kmax]; for (x = (int) xmin; x < (int) xmax; x++) { float w = filterp->filter((x - center + 0.5) * ss); k[x - (int) xmin] = w; ww = ww + w; } for (x = (int) xmin; x < (int) xmax; x++) { k[x - (int) xmin] /= ww; }
これで、最終的に90°の走査でピクセルを拡張できます。
// for (yy = 0; yy < imOut->ysize; yy++) { for (xx = 0; xx < imOut->xsize; xx++) { k = &kk[xx * kmax]; xmin = xbounds[xx * 2 + 0]; xmax = xbounds[xx * 2 + 1]; // // imOut->image8[yy][xx] } }
Scale 2560×1600 RGB image to 320x200 bil 0.04759 s 86.08 Mpx/s 87.6 % to 320x200 bic 0.08970 s 45.66 Mpx/s 45.7 % to 320x200 lzs 0.11604 s 35.30 Mpx/s 41.6 % to 2048x1280 bil 0.24501 s 16.72 Mpx/s 66.7 % to 2048x1280 bic 0.30398 s 13.47 Mpx/s 49.7 % to 2048x1280 lzs 0.37300 s 10.98 Mpx/s 41.7 % to 5478x3424 bil 1.06362 s 3.85 Mpx/s 40.1 % to 5478x3424 bic 1.32330 s 3.10 Mpx/s 39.4 % to 5478x3424 lzs 1.56232 s 2.62 Mpx/s 31.2 %
コミットd35755cの結果。
4列目は前のオプションと比較した加速を示し、表の下にはコミットへのリンクがあり、そこで行われた変更が明確に表示されます。
最適化2:出力制限
コードでは、いくつかの場所に次の構造があります。
if (ss < 0.5) imOut->image[yy][xx*4+b] = (UINT8) 0; else if (ss >= 255.0) imOut->image[yy][xx*4+b] = (UINT8) 255; else imOut->image[yy][xx*4+b] = (UINT8) ss;
これは、計算結果が8ビットを超える場合、[0、255]内のピクセル値の制限です。 実際、すべての正の畳み込み係数の合計は1より大きくなり、すべての負の畳み込み係数の合計はゼロより小さくなります。 そのため、特定のソースイメージでは、オーバーフローが発生する可能性があります。 このオーバーフローは、輝度の突然の変化を補正した結果であり、エラーではありません。
コードを見てください。 1つの入力変数ss
と1つの出力imOut->image[yy]
、その値は複数の場所に割り当てられます。 悪いことは、浮動小数点数が比較されることです。 すべてを整数に変換してから比較する方が高速です。最終的には結果全体が必要だからです。 合計で、この関数を取得します。
static inline UINT8 clip8(float in) { int out = (int) in; if (out >= 255) return 255; if (out <= 0) return 0; return (UINT8) out; }
使用法:
imOut->image[yy][xx*4+b] = clip8(ss);
これにより、パフォーマンスは向上しますが、わずかではありますが。
Scale 2560×1600 RGB image to 320x200 bil 0.04644 s 88.20 Mpx/s 2.5 % to 320x200 bic 0.08157 s 50.21 Mpx/s 10.0 % to 320x200 lzs 0.11131 s 36.80 Mpx/s 4.2 % to 2048x1280 bil 0.22348 s 18.33 Mpx/s 9.6 % to 2048x1280 bic 0.28599 s 14.32 Mpx/s 6.3 % to 2048x1280 lzs 0.35462 s 11.55 Mpx/s 5.2 % to 5478x3424 bil 0.94587 s 4.33 Mpx/s 12.4 % to 5478x3424 bic 1.18599 s 3.45 Mpx/s 11.6 % to 5478x3424 lzs 1.45088 s 2.82 Mpx/s 7.7 %
コミット54d3b9dの結果。
ご覧のとおり、この最適化は、ウィンドウが小さく、出力解像度が高いフィルターに大きな効果をもたらしました(唯一の例外は320x200バイリニアですが、理由は言えません)。 実際、フィルターウィンドウが小さく、最終的な解像度が大きいほど、最適化した値のクリッピングによるパフォーマンスへの寄与が大きくなります。
最適化3:反復回数が一定のループを回す
再び水平方向のステップをよく見ると、最大4つのネストされたサイクルをカウントできます。
for (yy = 0; yy < imOut->ysize; yy++) { // ... for (xx = 0; xx < imOut->xsize; xx++) { // ... for (b = 0; b < imIn->bands; b++) { // ... for (x = (int) xmin; x < (int) xmax; x++) { ss = ss + (UINT8) imIn->image[yy][x*4+b] * k[x - (int) xmin]; } } } }
出力画像の各行と各列が繰り返され(つまり、各ピクセル)、元の画像の折りたたまれる各ピクセルが内部で繰り返されます。 しかし、 b
とは何ですか? b
は画像チャンネルの繰り返しです。 明らかに、チャンネルの数は関数全体で変化せず、4を超えることはありません(画像がPillowに保存される方法のため)。 したがって、考えられるケースは4つだけです。 また、シングルチャネルの8ビット画像が異なる方法で保存されるという事実を考えると、3つのケースがあります。 したがって、2つ、3つ、および4つのチャネルに対して、3つの別々の内部サイクルを作成できます。 そして、適切な数のチャネルに分岐します。 あまりスペースをとらないように、3チャンネルの場合のコードのみを示します。
for (xx = 0; xx < imOut->xsize; xx++) { if (imIn->bands == 4) { // 4 } else if (imIn->bands == 3) { ss0 = 0.0; ss1 = 0.0; ss2 = 0.0; for (x = (int) xmin; x < (int) xmax; x++) { ss0 = ss0 + (UINT8) imIn->image[yy][x*4+0] * k[x - (int) xmin]; ss1 = ss1 + (UINT8) imIn->image[yy][x*4+1] * k[x - (int) xmin]; ss2 = ss2 + (UINT8) imIn->image[yy][x*4+2] * k[x - (int) xmin]; } ss0 = ss0 * ww + 0.5; ss1 = ss1 * ww + 0.5; ss2 = ss2 * ww + 0.5; imOut->image[yy][xx*4+0] = clip8(ss0); imOut->image[yy][xx*4+1] = clip8(ss1); imOut->image[yy][xx*4+2] = clip8(ss2); } else { // } }
xxループまで、そこで停止してブランチを1レベル上に移動することはできません。
if (imIn->bands == 4) { for (xx = 0; xx < imOut->xsize; xx++) { // 4 } } else if (imIn->bands == 3) { for (xx = 0; xx < imOut->xsize; xx++) { // 3 } } else { for (xx = 0; xx < imOut->xsize; xx++) { // } }
Scale 2560×1600 RGB image to 320x200 bil 0.03885 s 105.43 Mpx/s 19.5 % to 320x200 bic 0.05923 s 69.15 Mpx/s 37.7 % to 320x200 lzs 0.09176 s 44.64 Mpx/s 21.3 % to 2048x1280 bil 0.19679 s 20.81 Mpx/s 13.6 % to 2048x1280 bic 0.24257 s 16.89 Mpx/s 17.9 % to 2048x1280 lzs 0.30501 s 13.43 Mpx/s 16.3 % to 5478x3424 bil 0.88552 s 4.63 Mpx/s 6.8 % to 5478x3424 bic 1.08753 s 3.77 Mpx/s 9.1 % to 5478x3424 lzs 1.32788 s 3.08 Mpx/s 9.3 %
コミット95a9e30の結果。
同様のことが垂直通路についても可能です。 現在、そのようなコードがあります:
for (xx = 0; xx < imOut->xsize*4; xx++) { /* FIXME: skip over unused pixels */ ss = 0.0; for (y = (int) ymin; y < (int) ymax; y++) ss = ss + (UINT8) imIn->image[y][xx] * k[y-(int) ymin]; ss = ss * ww + 0.5; imOut->image[yy][xx] = clip8(ss); }
チャネルに個別の反復はありません。代わりに、 xx
は幅に4を掛けて反復します。つまり、 xx
は画像内の数に関係なく各チャネルを通過します。 コメントのFIXMEは、これを修正する必要があるとだけ言っています。 同じ方法で修正されます-元の画像の異なる数のチャンネルのコードを分岐することによって。 ここではコードを提供しません。コミットへのリンクは以下にあります。
Scale 2560×1600 RGB image to 320x200 bil 0.03336 s 122.80 Mpx/s 16.5 % to 320x200 bic 0.05439 s 75.31 Mpx/s 8.9 % to 320x200 lzs 0.08317 s 49.25 Mpx/s 10.3 % to 2048x1280 bil 0.16310 s 25.11 Mpx/s 20.7 % to 2048x1280 bic 0.19669 s 20.82 Mpx/s 23.3 % to 2048x1280 lzs 0.24614 s 16.64 Mpx/s 23.9 % to 5478x3424 bil 0.65588 s 6.25 Mpx/s 35.0 % to 5478x3424 bic 0.80276 s 5.10 Mpx/s 35.5 % to 5478x3424 lzs 0.96007 s 4.27 Mpx/s 38.3 %
コミットf227c35の結果。
ご覧のように、水平方向の通路はパフォーマンスを向上させて写真を縮小し、垂直方向の通路はパフォーマンスを向上させました。
最適化4:整数カウンター
for (y = (int) ymin; y < (int) ymax; y++) { ss0 = ss0 + (UINT8) imIn->image[y][xx*4+0] * k[y-(int) ymin]; ss1 = ss1 + (UINT8) imIn->image[y][xx*4+1] * k[y-(int) ymin]; ss2 = ss2 + (UINT8) imIn->image[y][xx*4+2] * k[y-(int) ymin]; }
最も内側のループを見ると、変数ymax
およびymax
floatとして宣言ymax
ているが、各ステップで整数にymax
ていることがわかります。 さらに、ループの外側では、 floor
関数とceil
関数を使用して値を割り当てます。 つまり、実際には整数は常に変数に格納されますが、何らかの理由で整数として浮動小数点として宣言されます。 xmin
とxmax
についてxmin
同じことがxmax
ます。 交換して測定します。
Scale 2560×1600 RGB image to 320x200 bil 0.03009 s 136.10 Mpx/s 10.9 % to 320x200 bic 0.05187 s 78.97 Mpx/s 4.9 % to 320x200 lzs 0.08113 s 50.49 Mpx/s 2.5 % to 2048x1280 bil 0.14017 s 29.22 Mpx/s 16.4 % to 2048x1280 bic 0.17750 s 23.08 Mpx/s 10.8 % to 2048x1280 lzs 0.22597 s 18.13 Mpx/s 8.9 % to 5478x3424 bil 0.58726 s 6.97 Mpx/s 11.7 % to 5478x3424 bic 0.74648 s 5.49 Mpx/s 7.5 % to 5478x3424 lzs 0.90867 s 4.51 Mpx/s 5.7 %
コミット57e8925の結果。
最終行為とボス
私は認める、私は結果に非常に満足していた。 コードを平均2.5倍オーバークロックできました。 さらに、この高速化を実現するために、ライブラリユーザーは追加の機器をインストールする必要がなく、以前と同じように同じプロセッサの同じコアでサイズ変更が実行されます。 必要なのは、Pillowのバージョンをバージョン2.7にアップグレードすることだけでした。
しかし、リリース2.7以前にはまだ時間があり、動作するはずのサーバーで新しいコードをチェックするのに焦りました。 コードを移植し、コンパイルしましたが、最初は何かを台無しにしたと思いました。
Scale 2560×1600 RGB image 320x200 bil 0.08056 s 50.84 Mpx/s 320x200 bic 0.16054 s 25.51 Mpx/s 320x200 lzs 0.24116 s 16.98 Mpx/s 2048x1280 bil 0.18300 s 22.38 Mpx/s 2048x1280 bic 0.31103 s 13.17 Mpx/s 2048x1280 lzs 0.43999 s 9.31 Mpx/s 5478x3424 bil 0.75046 s 5.46 Mpx/s 5478x3424 bic 1.22468 s 3.34 Mpx/s 5478x3424 lzs 1.70451 s 2.40 Mpx/s
コミット57e8925の結果。 別のマシンで受信され、比較には関与しません。
黙って? 結果は、最適化前とほとんど同じです。 すべてを10回チェックし、適切なコードが機能することを確認するために印刷しました。 それは枕や環境からの副作用ではなく、30行の最小限の例でも違いが再現されました。 Stack Overflowについて質問したところ、最終的に明らかなパターンを見つけることができました。64ビットプラットフォーム用のGCCでコンパイルされた場合、コードはゆっくり実行されました。 そして、それはまさにローカルUbuntaとサーバーの違いでした:ローカルには32ビットがありました。
さて、Muruの栄光、私はクレイジーではありません。これはコンパイラの本当のバグです。 さらに、バグはGCC 4.9で修正されましたが、GCC 4.8はUbuntu 14.04 LTSに含まれていました。これは当時関連がありました。つまり、ほとんどの場合、ライブラリのほとんどのユーザーによってインストールされました。 これを無視することは不可能でした。最適化は、それが作られた生産物を含め、大多数の人にとってうまくいかない場合は良いことです。 SOの質問を更新し、Twitterで叫びました。 V8エンジンと最適化の天才の開発者の1人であるVyacheslav Egorovが彼のもとに来て、問題の根底にたどり着き、解決策を見つけました。
問題の本質を理解するには、プロセッサの歴史と現在のアーキテクチャを詳しく調べる必要があります。 昔々、x86プロセッサは浮動小数点数を扱う方法を知らなかったため、x87命令のセットを備えたコプロセッサが発明されました。 彼は中央処理装置と同じスレッドから命令を実行しましたが、マザーボードに別のデバイスとしてインストールされました。 すぐに、コプロセッサーは中央のコンピューターに組み込まれ始め、物理的には1つのデバイスになりました。 どれくらい短いか、一連のSSE(ストリーミングSIMD拡張命令)命令が3番目のPentiumに登場しました。 ところで、SIMD命令については、一連の記事の第2部になります。 その名前にもかかわらず、SSEには浮動小数点数を操作するためのSIMDコマンドだけでなく、スカラー計算用の同等のコマンドも含まれていました。 つまり、SSEにはx87セットを複製する一連の命令が含まれていましたが、エンコード方法が異なり、動作がわずかに異なります。
ただし、コンパイラーは浮動小数点計算用のSSEコードを生成することを急いでいませんでしたが、古いx87スイートを引き続き使用しました。 結局のところ、昔から組み込まれているx87とは異なり、プロセッサのSSEを保証する人はいませんでした。 64ビットプロセッサモードの登場により、すべてが変わりました。 64ビットモードでは、SSE2命令のセットが必須になりました。 つまり、x86用の64ビットプログラムを作成している場合、少なくともSSE2命令を使用できます。 これは、コンパイラが64ビットモードで浮動小数点計算用のSSE命令を生成するときに使用するものです。 これはベクトル化とは何の関係もないことを思い出させてください;私たちは通常のスカラー計算について話しています。
これがまさに私たちのケースで起こることです。32ビットモードと64ビットモードでは異なる命令セットが使用されます。 しかし、これまでのところ、これは、最新のSSEコードが従来のx87スイートよりも数倍遅い理由を説明していません。 この現象を説明するには、プロセッサが命令を実行する方法を正確に把握する必要があります。
むかしむかし、プロセッサーは本当に指示に従いました。 彼らは命令を取り、それを解読し、完全に実行し、結果を言われたところに置きました。 プロセッサはかなり馬鹿だった。 最新のプロセッサは、はるかにスマートで複雑であり、数十の異なるサブシステムで構成されています。 並列処理を行わない1つのコアでも、プロセッサは1クロックサイクルで一度に複数の命令を実行します。 さまざまな段階で発生します。一部の命令はまだデコード中、一部はキャッシュからのリクエスト、一部は算術ブロックに転送されます。 各プロセッササブシステムは、独自の部分に関与しています。 これはコンベアと呼ばれます。

図では、異なるサブシステムが異なる色で示されています。 コマンドの実行には4〜5クロックサイクルが必要ですが、パイプラインのおかげで、各クロックサイクルで1つの新しいコマンドが選択され、1つのコマンドが実行を完了します。
コンベアはより効率的に動作し、より均一に充填され、アイドル状態のサブシステムが少なくなります。 プロセッサには、パイプラインの最適な充填を計画するサブシステムもあります。命令をスワップし、1つの命令を複数に分割し、複数を1つに結合します。
, — . - , .
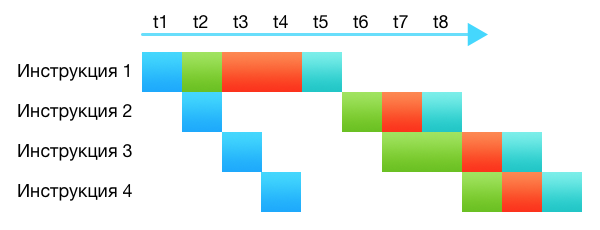
, 2 1. . .
Instruction: cvtsi2ss xmm, r32 dst[31:0] := Convert_Int32_To_FP32(b[31:0]) dst[127:32] := a[127:32]
32 . , dst
- a
, , xmm , dst
a
— , 96 , . . , , , . , 32- float. , , . .
, . cvtsi2ss
, xorps
. . , , , , xorps
+ cvtsi2ss
- :
dst[31:0] := Convert_Int32_To_FP32(b[31:0]) dst[127:32] := 0
, GCC 4.8 , , . , , , . 64- .
Scale 2560×1600 RGB image 320x200 bil 0.02447 s 167.42 Mpx/s 320x200 bic 0.04624 s 88.58 Mpx/s 320x200 lzs 0.07142 s 57.35 Mpx/s 2048x1280 bil 0.08656 s 47.32 Mpx/s 2048x1280 bic 0.12079 s 33.91 Mpx/s 2048x1280 lzs 0.16484 s 24.85 Mpx/s 5478x3424 bil 0.38566 s 10.62 Mpx/s 5478x3424 bic 0.52408 s 7.82 Mpx/s 5478x3424 lzs 0.65726 s 6.23 Mpx/s
81fc88e . .
, , . , , , . ImageMagick : 64- , GCC 4.9 40% . , SSE.
: 2, SIMD