DockerとKubernetesの時代にソフトウェア開発の世界はどのように変わりましたか? これらのテクノロジーに基づいて、一度だけアーキテクチャを構築することは可能ですか? すべてをコンテナに「詰め込む」ときに、開発プロセスと統合プロセスを統合することは可能ですか? そのような決定の要件は何ですか? 彼らにはどんな制限がありますか? 彼らは単純な開発者の生活を簡素化しますか、それとも難しくしますか?
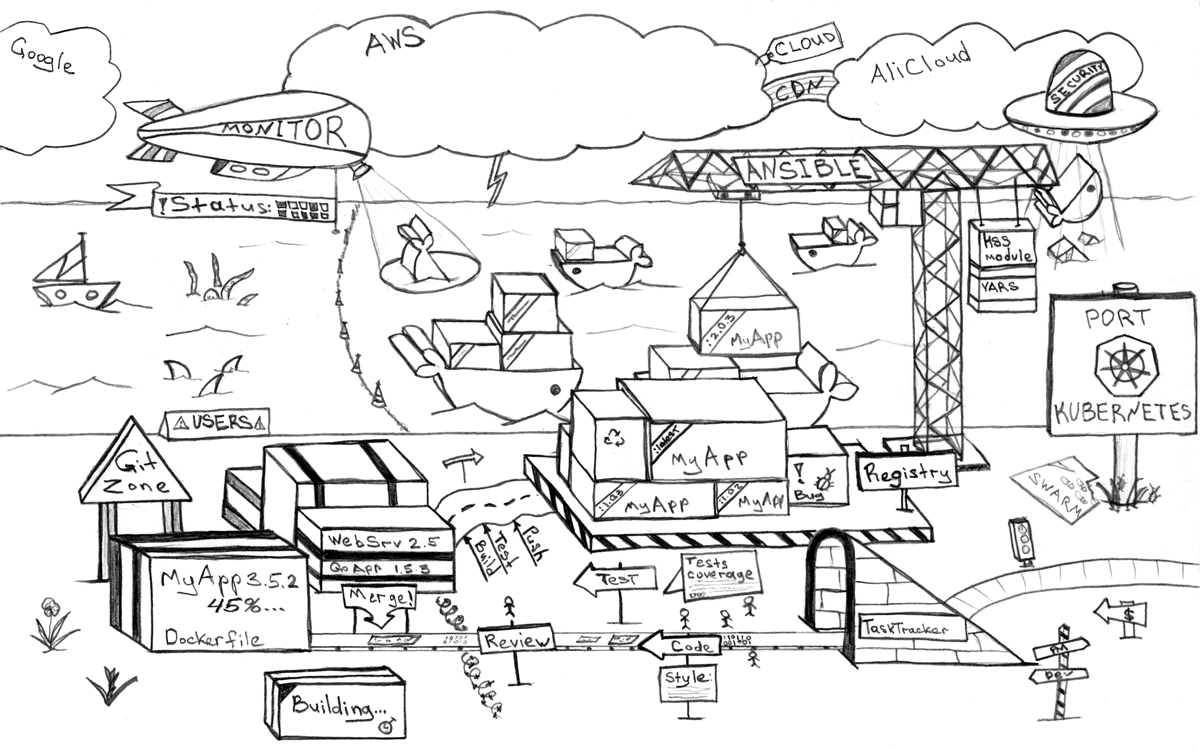
これらの質問だけでなく、これらすべてに答える時が来ました! (本文および元のイラストで)
この記事では、実際の生活から開発プロセスへと円を描くように導き、アーキテクチャを通して、あなたを現実の生活に戻し、これらの各セクターで最も重要な質問に答えます。 また、特定の実装を行うことなく、可能なソリューションの例を示すだけで、アーキテクチャの一部となる多くのコンポーネントと原則の概要を説明します。
記事のタイトルからの質問についての最終的な結論は、あなたを混乱させるだけでなく、他の読者を大いに喜ばせることができます-すべてはあなたの経験、3つの章からの次のストーリーをどのように認識するか、そしておそらくこの日の気分に依存します読んだ後に質問!
目次
実生活から開発プロセスまで
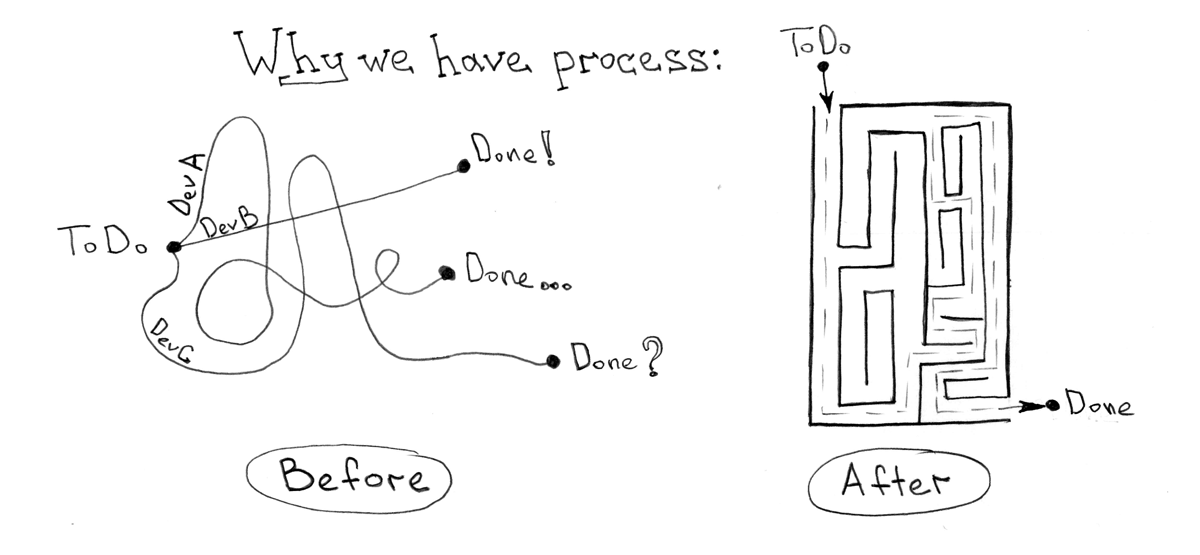
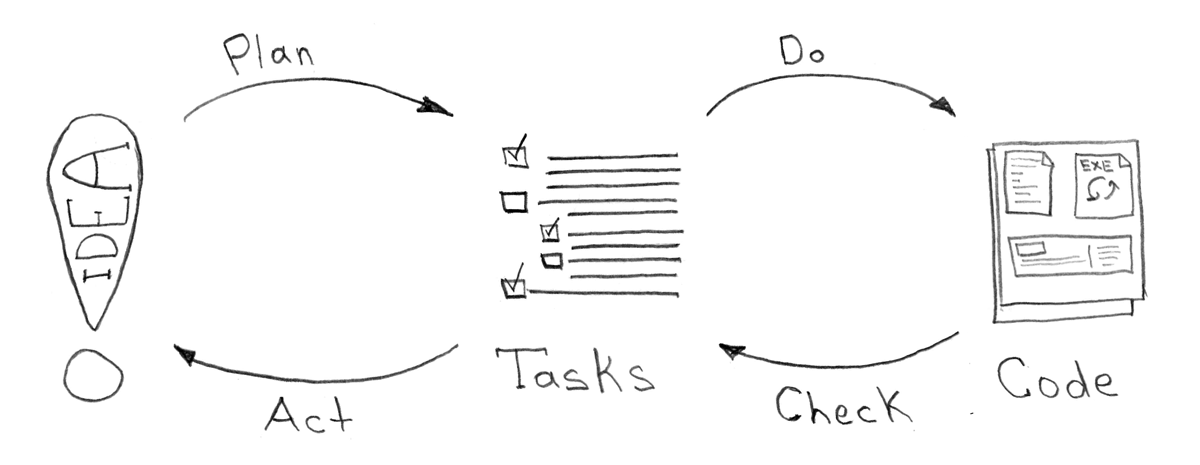
ほとんどの場合、私がこれまで見た、またはインストール/構成することを光栄に思っていたすべての開発プロセスは、実際には1つの単純な目標です-アイデアの誕生から「戦闘」環境への配信までの時間を短縮することケース定数、コードの品質の値。
しかし、悪いアイデアや良いアイデアは絶対に重要ではありません。 悪いアイデアは通常、テストして拒否し、場合によってはすぐに崩壊するために加速されます。 ここで重要なのは、前のバージョンへのロールバックプロセス(この「クレイジーな」アイデアなし)も、プロセスを自動化するロボットの肩にかかっているということです。
継続的な統合と配信は、通常、開発世界のライフラインのように見えます。 何が簡単に見えるでしょうか? アイデアを持って、コードを持って-行こう! 1つの大きな「BUT」がなければ、すべてがうまくいきます。 私の経験が示すように、統合と配信プロセスは、社内で使用されているテクノロジーやビジネスプロセスから切り離して形式化することは非常に困難です。
タスクは明らかに複雑ですが、世界は絶えず素晴らしいアイデアとテクノロジーを生み出し、私たちを(まあ、個人的には...)理想的で理想的なメカニズムに導きます。 これに向けた次のステップは、DockerとKubernetesです。 抽象化のレベルとイデオロギー的アプローチは、タスクの80%が実際に同じ方法で解決できると言う権利を与えてくれます。
もちろん、20%はどこにも行っていません。 しかし、これはまさに、作業と作成が興味深い分野であり、アーキテクチャとプロセスの同じ日常的な問題に対処することではありません。 したがって、「建築の枠組み」に一度集中すると、解決された問題の80%に戻る必要性を(ケースを損なうことなく)忘れることができます。
これは何を意味し、Dockerは開発プロセスの問題をどのように解決しますか?
簡単な開発プロセスを考えてみましょう。ほとんどの場合、これを十分に考慮することを提案します。
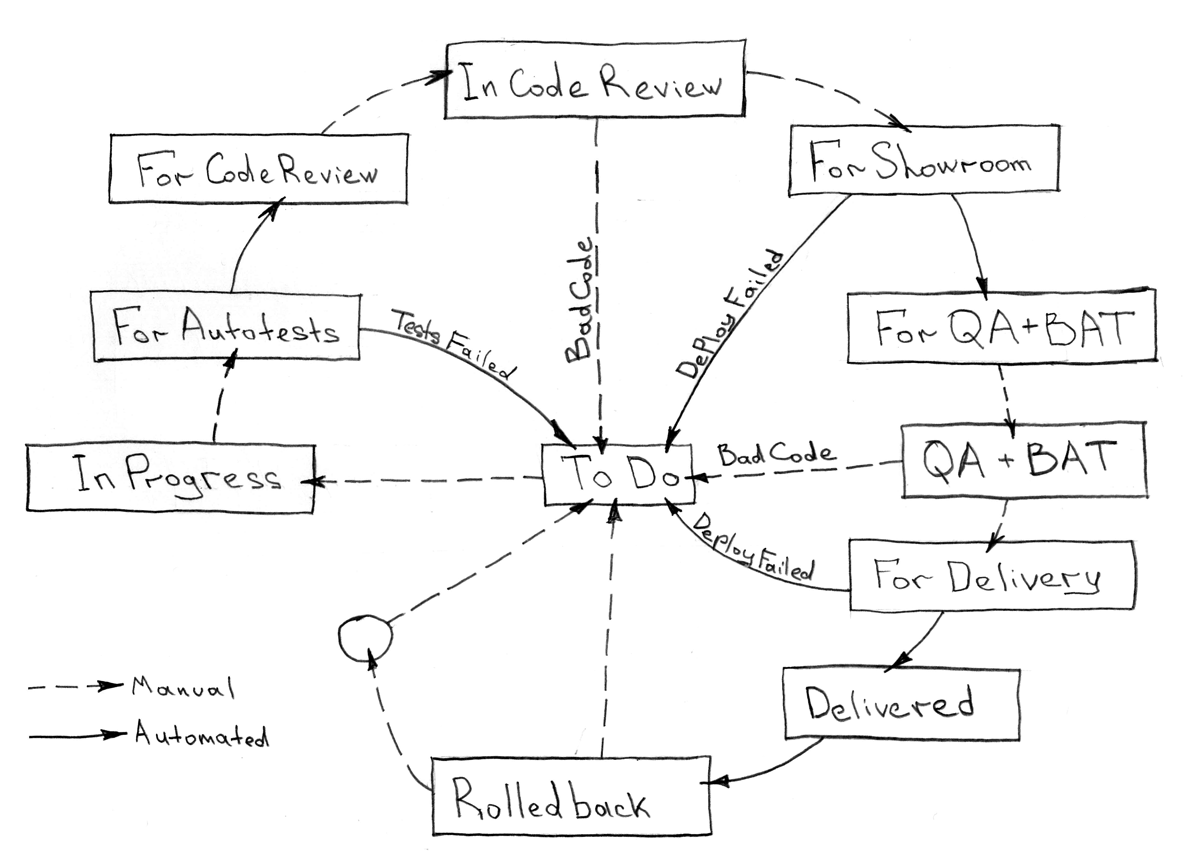
任意のタスクの一連の段階から自動化する必要があるものはすべて、それ自体に統合することができ、時間をかけて適切なアプローチで変更する必要はありません。
開発者環境をインストールする
すべてのプロジェクトにdocker-compose.yml
を含める必要があります。 開発者は、ローカルマシンでアプリケーション/サービスを実行するためにどのように、何をする必要があるかを考える必要性から簡単に救います。 単純なdocker-compose up
を使用すると、このアプリケーションですべての依存関係を有効にし、データベースにフィクスチャを入力し、コンテナ内のローカルコードを接続し、オンザフライでコンパイルするためにコードをスヌーピングし、最終的に期待されるポートに応答する必要があります。
新しいサービスの作成について話している場合、開発者は、開始方法、コミットする場所、または選択するフレームワークについて質問しないでください。 これらはすべて、標準の指示で事前に説明し、 frontend
、 backend
、 worker
その他のタイプのさまざまなケースのサービステンプレートで指示する必要があります。
自動テスト
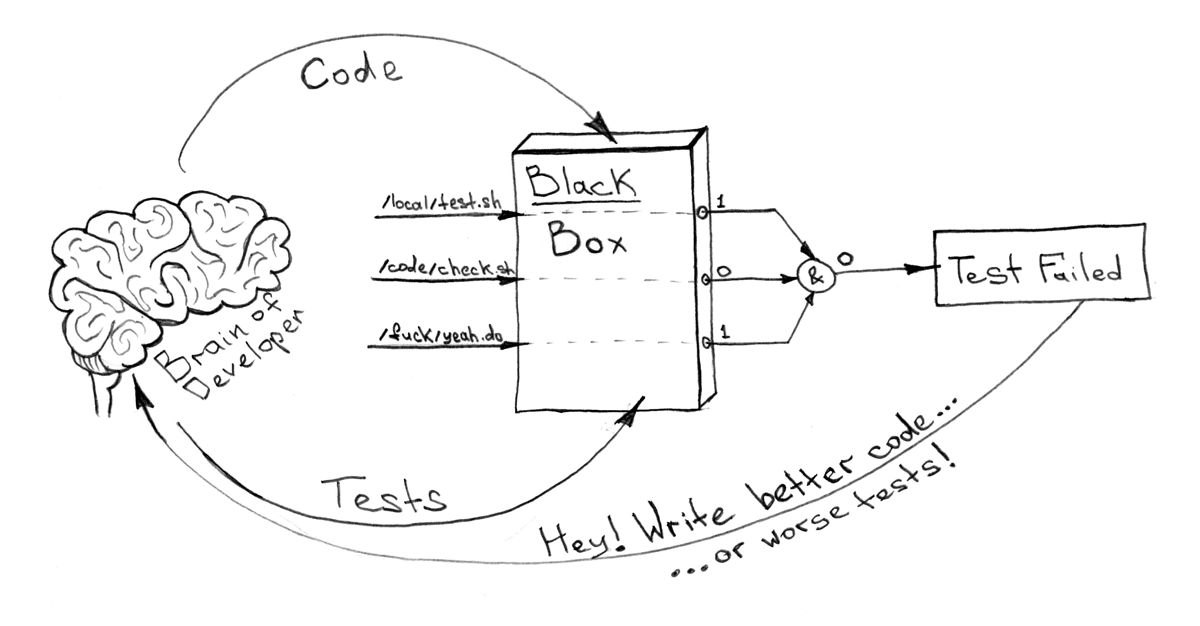
「ブラックボックス」( 後でコンテナを呼び出す理由)について知りたいのは、内部のすべてが大丈夫ということだけです。 はいまたはいいえ。 1または0。コンテナ内で実行する必要があるコマンドの数が限られている場合、および依存関係を記述するdocker-compose.yml
を使用すると、特に実装の詳細に入らずに簡単に自動化および統合できます。
たとえば、 このように !
ここで、テストとは、ユニットだけでなく、機能だけでなく、機能、統合、コードスタイルのテストと複製、古い依存関係の確認、使用されているパッケージのライセンスの破損など、その他のテストを意味します。 強調点は、これらすべてをDockerイメージ内にカプセル化する必要があるという事実です。
配送システム
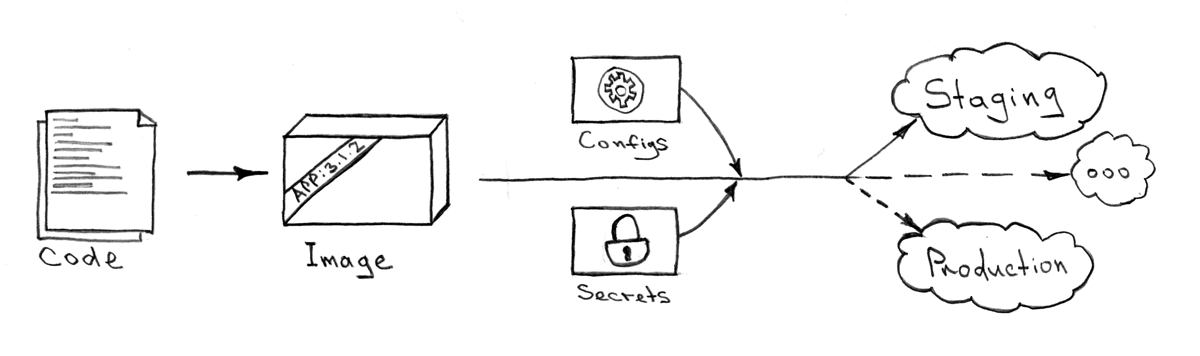
いつどこで頭脳をインストールするかは問題ではありません。 結果は、インストールプロセスとまったく同じで、常に同じである必要があります。 エコシステム全体のどの部分でも、どのgitリポジトリからでも違いはありません。 ここでのdem等性は最も重要な要素です。 設定する必要があるのは、インストールを制御する変数だけです。
この問題を解決するのに最も効果的と思われるアルゴリズム:
- すべての
Dockerfile
から画像を収集します(たとえば、 このように ) - メタプロジェクトを使用して、 Kube APIを使用してこれらの画像をKubernetesに配信します 。 通常、配信を開始するには、いくつかの入力パラメーターが必要です。
- Kube APIエンドポイント
- 秘密のリソース-通常、異なるコンテキスト(ローカル/ショールーム/ステージング/プロダクション)によって異なります
- 計算用のシステム名とこれらのシステムのDockerイメージタグ(前の手順で取得)
すべてのシステムとサービスに対する単一のメタプロジェクト(エコシステムの構造と変更の配信方法を説明するプロジェクト)として、 このモジュールでAnsibleplaybook
を使用してKubeAPIと統合することを好みます。 ただし、洗練された自動化には他の多くのオプションがあります-少し低めにしましょう。 忘れてはならない唯一のことは、アーキテクチャを管理するための中央集中型の方法です。 これにより、すべてのサービス/システムを便利かつ均一に管理し、同様の機能を実行するテクノロジーやシステムから今後の動物園の兆候を取り除くのを止めることができます。
通常、環境のインストールは次の場所で必要です。
- 「ShowRoom」-いくつかの手動チェックまたはシステムのデバッグ用
- 「ステージング」-ほとんどの戦闘環境および外部システムとの統合(通常は
ShowRoom
とは異なり、DMZにあります) - 「生産」-エンドユーザーの実際の環境
統合と配信の継続性

「ブラックボックス」-Dockerイメージをテストする統一された方法があるため、このようなテストによって得られた結果により、 feature-branch
ブランチをgitリポジトリのupstream
またはmaster
ブランチに問題upstream
シームレスに統合できることを考慮する必要があります。
このアプローチの唯一の障害は、統合と配信を行う必要がある順序です。 また、リリースがない場合、多くの並列feature-branch
備えた1つのシステムで「競合状態」を防止する方法についての質問が急に発生しfeature-branch
。
次のプロセスは、競合モードがない場合に開始する必要があります。そうしないと、「競合状態」によって休息が取れなくなります。
-
feature-branch
をupstream
にアップグレードしようとしています(git rebase/merge
) -
Dockerfile-
収集 - 収集されたすべての画像のテスト
- 開始し、ステップ2からの画像を含む必要なシステムの配信が完了するまで待ちます
- 前のステップが中断した場合、または外部要因により、エコシステムを前の状態にロールバックした場合
-
upstream
feature-branch
をマージし、リポジトリに送信します
どんな失敗でも、どのステップでも、配信プロセスを中断し、開発者にタスクを返して問題を解決する必要があります。「合格しない」テストであれ、ブランチのマージの問題であれ。
同じレシピは、複数のリポジトリを操作できることを意味します。 これを行うには、すべてのリポジトリに対してアルゴリズムステップの順序でプロセス全体を実行する必要があります。各リポジトリを個別に繰り返し反復するのではなく、
さらに、Kubernetesを使用すると、さまざまなABテストおよび問題分析のために更新を部分的に展開できます。 これは、内部手段と、サービス(アクセスポイント)の分離および直接的なアプリケーションによって実現されます。 問題と可能なロールバックを分析するために、コンポーネントの新しいバージョンと古いバージョンを適切な比率で常にバランスさせることができます。
ロールバックシステム
すべての展開は可逆的である必要があります-これは、アーキテクチャフレームワークに提示される必須要件です。 これには、多くの明白で微妙ではないシステム開発が伴います。
最も重要なもののいくつかを次に示します。
- サービスは、環境を正確にカスタマイズできるだけでなく、変更をロールバックできる必要があります。 例:データベースの移行、RabbitMQのスキーマなど。
- 環境をロールバックできない場合は、多態性であり、古いバージョンと新しいバージョンの両方のコードをサポートする必要があります。 例:データベースの移行は、いくつかの世代のサービスの古いバージョンの動作を中断させないようにする必要があります(通常は2世代または3世代で十分です)。
- サービス更新の下位互換性。 通常、API互換性、メッセージ形式などです。
Kubernetesクラスターの状態のロールバックは非常に簡単です(kubectl rollout undo deployment/some-deployment
とkubernetesは以前の「スナップショット」を復元します)が、メタプロジェクトにはこれに関する情報も含まれている必要があります。 より複雑な配信ロールバックアルゴリズムは非常に推奨されませんが、必要な場合もあります。
このメカニズムが開始される原因:
- リリース後のアプリケーションエラーの割合が高い
- 主要な監視ポイントからの信号
-
smoke
テストの失敗 - 手動モード-人間の決定
情報セキュリティと監査
外部および内部の脅威からエコシステムの100%のセキュリティを「作成」する個別のプロセスを選択することは不可能ですが、アーキテクチャフレームワークは、各レベルおよびすべてのサブシステムで企業の標準およびセキュリティポリシーを考慮して実装する必要があることに注意してください。
次に、提案されたソリューションの3つのレベルすべてをより詳細に検討します。モニタリングとアラートについても説明します。これらは、横断的であり、システムの整合性の観点から基本的な重要性を持ちます。
Kubernetesには、 アクセス権 、 ネットワークポリシー 、 イベント監査、および情報セキュリティに関連するその他の強力なツールを区切るための非常に優れた組み込みメカニズムのセットがあります 。 適切な忍耐力を使用すると、単一の攻撃またはデータリークが成功して終了するのに耐え、防止できる優れた防御境界線を構築できます。
プロセスからアーキテクチャーまで
開発プロセスと構築しようとしている環境とのこの緊密な関係は、あなたに安心を与えるべきではありません。 情報システムのアーキテクチャに関する従来の要件(柔軟性、スケーラビリティ、可用性、信頼性、脅威に対するセキュリティなど)、開発プロセスおよび配信プロセスとの良好な統合の要求に加えて、このようなアーキテクチャの価値を高めます。
開発プロセスとエコシステムの密接な統合により、DevOps( Dev elopment Op eration s )などの概念が長い間生まれています。これは、インフラストラクチャの完全な自動化と最適化への道のりの論理的なステップです。 ただし、適切に設計されたアーキテクチャとプラットフォームの高品質のサブシステムを使用すると、DevOpsタスクを最小限に抑える必要があります。
マイクロサービスアーキテクチャ
私は、サービス指向アーキテクチャー( SOA )の利点の詳細、およびこれらのサービスがなぜマイクロである必要があるのかについて説明する必要はないと考えています 。 DockerとKubernetesを使用することに決めた場合、この世界では巨大なモノリスになることは非常に難しく、イデオロギー的に間違っていることを理解する(そして受け入れる)必要があります。
単一のプロセスを実行し、永続性で厳密に動作するように設計されたDockerは、DDD(ドメイン駆動開発)の観点から考えることを余儀なくされ、パッケージ化されたコードをアクセス用の発信ポートを持つブラックボックスとして扱います。
必須のエコシステムコンポーネントとソリューション
可用性と信頼性を向上させたシステムの設計の実践から、マイクロサービスの運用に実際に必要ないくつかのコンポーネントを選び出します。
すべてのコンポーネントとその説明は、Kubernetes環境のコンテキスト(アプローチとアーキテクチャの観点から重要です)で以下に示されているという事実にもかかわらず、このリストを他のプラットフォームのチェックリストとして参照できます。
(私のように)以下で説明するサービスサービスを通常のKubernetesサービスとして管理する方が良いという結論に達した場合、推奨事項は、別個のクラスターまたはこのための「実動」とは異なるクラスターを持つことです。 たとえば、「ステージング」クラスターを使用できます。これにより、「戦闘」環境は安定していませんが、イメージ、コード、または監視のソースが必要な状況から保護できます。 つまり、この方法で「鶏と卵」の問題を解決します
アイデンティティサービス
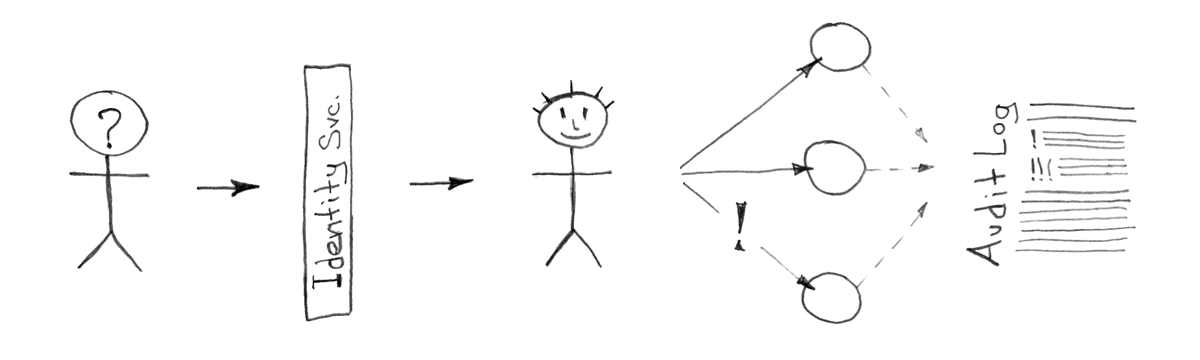
通常は、アクセス、サーバーへのアクセス、仮想マシン、アプリケーション、オフィスのメールなどから始まります。 最大規模の企業プラットフォーム(IBM、Google、Microsoftなど)のクライアントである(またはなりたい)場合、これらのベンダーの適切なサービスによってこの問題が解決される可能性が高いです。 しかし、これがあなたのやり方ではなく、自分だけのソリューションを自分で管理し、できれば予算内で手頃な価格にしたい場合はどうでしょうか?
このリストは、必要なオプションを決定し、インストールとメンテナンスの人件費を理解するのに役立ちます。 この選択は、会社のセキュリティポリシーと無条件に一貫し、(情報)セキュリティサービスによって承認される必要があります。
自動サーバープロビジョニング
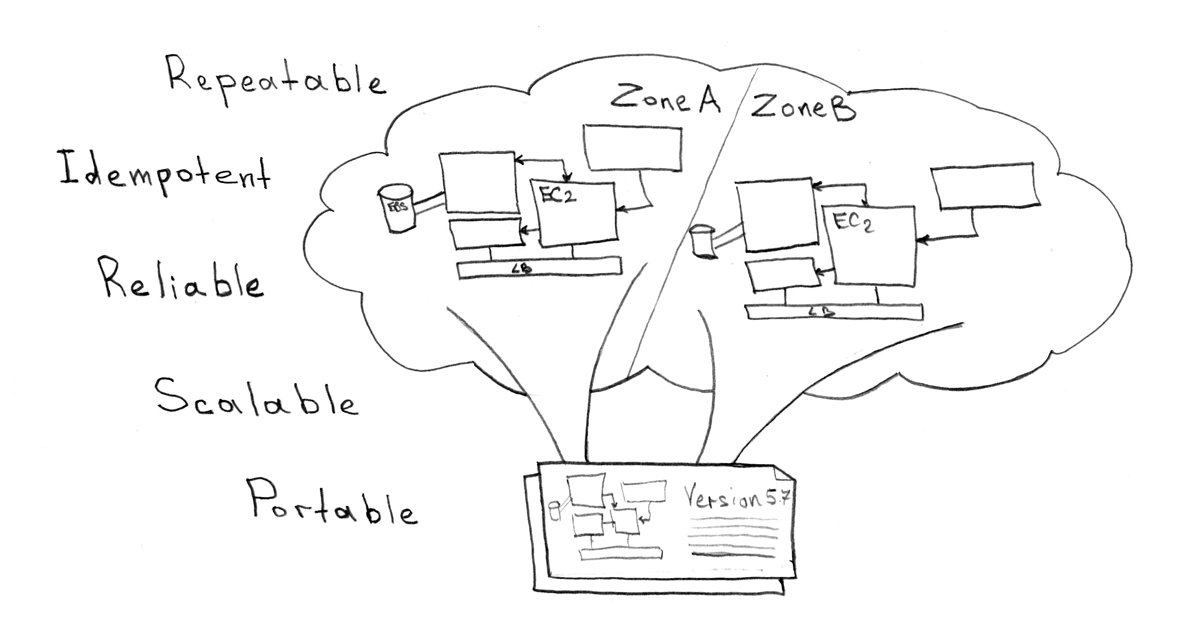
Kubernetesが必要とする物理マシン/クラウドVM(docker、kubelet、kubeプロキシ、etcdクラスター)のコンポーネント数は非常に少ないにもかかわらず、新しいマシンの追加とクラスター管理を自動化する必要があります。 これを簡単かつ簡単に行う方法のいくつかのオプション:
- KOPS-このツールを使用すると、AWSまたはGCEの2つのクラウドプロバイダーのいずれかにクラスターをインストールできます
- Teraform-一般に、あらゆる環境のインフラストラクチャを管理し、IAC(インフラストラクチャコード、インフラストラクチャをコードとして)のイデオロギーに従うことができます。
- Ansibleはさらに幅広いアプリケーション向けのツールであり、あらゆる種類の自動化に使用されます。
上記の提案リストから-システムの配信のセクションでは、後者のオプション( Kubernetesとの統合用の小さなモジュールを使用)を好むことに注意してください。一般に、あらゆる種類の自動化を実行します。 ただし、たとえばKubernetes用の Teraformとそのモジュールの使用を妨げるものはありません。 KOPSは「ベアメタル」の作業には完全に適用できませんが、私の意見では、AWS / GCEを使用するのに最適なツールです。
Gitリポジトリとタスクトラッカー
開発者やその他の関連する役割の完全な仕事のために、コラボレーション、コードストレージの議論のための場所が必要であると言う必要はありません。 これに最適なサービスについての質問に答えるのは難しいですが、トラッカートラッカーは、古典的には無料のredmineまたは有料のJiraと無料の古い学校のgerritまたは有料のbitbucketです
共同企業作業のための最も一貫性のある、しかし商用の2つのスタック、 AtlassianとJetbrainsに注意する価値があります。 それらの1つを完全に使用することも、ソリューション内のさまざまなコンポーネントを組み合わせることができます。
トラッカーとリポジトリを使用して最大の効果を得るには、これら2つのエンティティを機能させて統合するための戦略に留意する必要があります。 そのため、たとえば、コードと関連タスクの整合性を確保するためのいくつかのヒント(もちろん、戦略を選択できます):
- リモートリポジトリにプッシュする機能は、タスク番号(
TASK-1
/feature-34
)を持つブランチにのみ存在する必要があります - 対応するタスクが「進行中」などのステータスにない場合、すべてのブランチはブロックされ、更新に使用できません。
- ブランチは、一定数の肯定的なコードレビューの後のみ、マージに使用できる必要があります。
- 自動化を目的とするステップは、開発者が直接アクセスできないようにする必要があります。
-
master
ブランチは、特権のある開発者のみが直接変更できるようにする必要があります-他のすべてはロボットの「オートメーション」のみが利用できます - 対応するタスクが「配信用」などのステータス以外の場合、ブランチはマージに使用できません
Dockerレジストリ
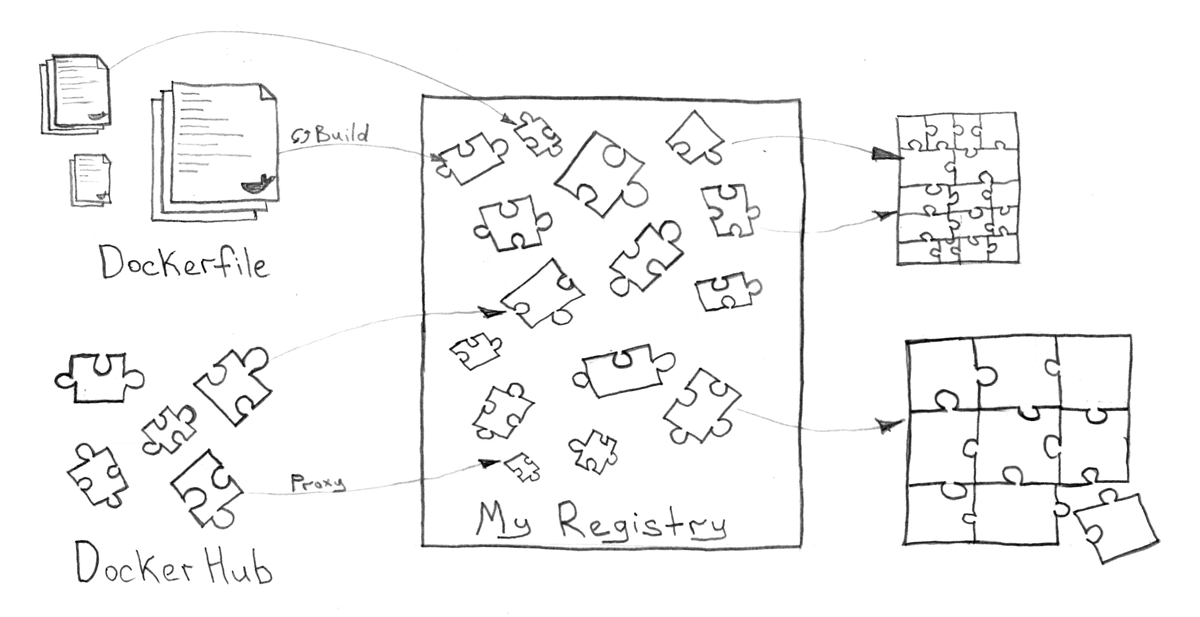
Docker
管理機能は、サービスの保存と配信にとって非常に重要であるため、個別に識別する必要があります。 これに加えて、そのようなシステムは、ユーザー、グループ、およびアクセスの操作をサポートし、古い不要なイメージを削除し、GUIと安らかなAPIを提供する必要があります。
クラウドソリューション( hub.docker.comなど )と、Kubernetesクラスター自体の内部にもインストールできるプライベートサービスの両方を使用できます。 これに対するかなり興味深いサービスは、Docker Registryの企業ソリューションとして位置付けられているVmware Harborです。 最悪の場合、複雑なシステムを実際に必要とせず、単に画像を保存したい場合は、通常のDocker Registryで対応できます。
CI / CDサービスおよびサービス提供システム
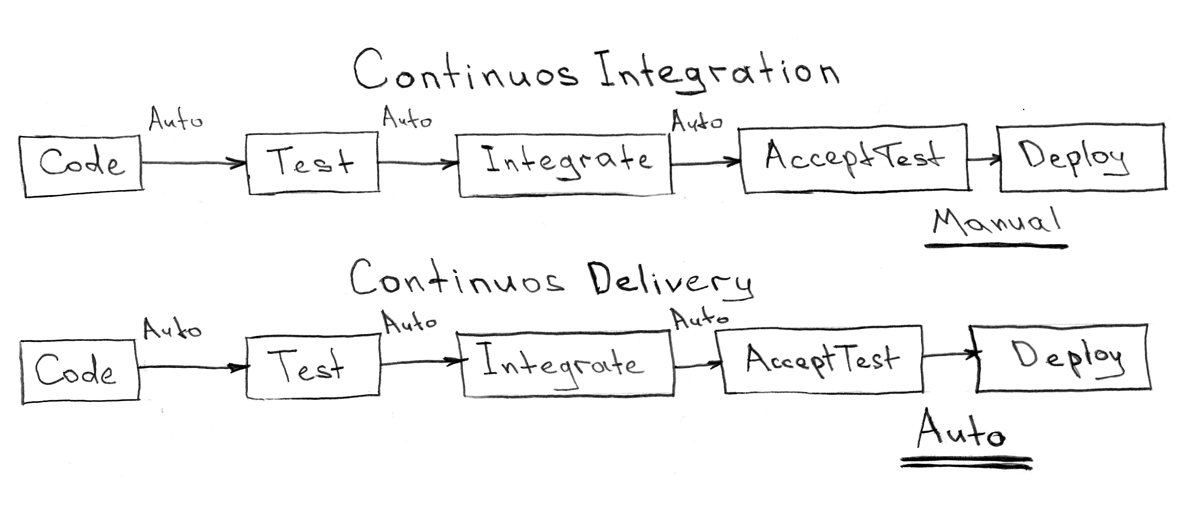
以前に説明したすべてのコンポーネント(gitリポジトリ、タスクトラッカー、Ansible Playbookを使用したメタプロジェクト、外部依存関係)は、個別に一時停止して存在することはできません。 この真空は、継続的な統合および配信サービスによって満たされる必要があります。
CI-継続的インテグレーション-継続的インテグレーション
CD-継続的デリバリー-継続的デリバリー
サービスは非常にシンプルで、システムの配信または構成の方法に関連するロジックを持たないものでなければなりません。 CI / CDサービスは、外界からのイベント(gitリポジトリの変更、タスクトラッカーのタスク移行)に応答し、メタプロジェクトで説明されているアクションを起動するだけです。 これは、すべてのリポジトリのコントロールポイントであり、それらを管理するツールでもあります(ブランチのマージ、 upstream/master
からの更新)。
歴史的には、Jetbrains- TeamCityの非常に強力であると同時に非常にシンプルなツールを使用することに慣れていますが、たとえば無料のJenkinsを使用することに決めた場合、問題は発生しません。
上記に基づいて、実際、このスキーム全体では、統合サービスが開始する必要がある主なプロセスは4つだけであり、1つの補助的なプロセスしかありません。
- サービスの自動テスト-通常、ブランチの状態を変更するか、「Atesting Autotests」などのステータスの開始により、単一のリポジトリに対して
- サービス配信-通常、QA環境と「本番」環境のそれぞれの「ショールーム待機中」、「配信待機中」のステータス発生時に、多数のサービス(およびリポジトリ)のメタプロジェクトから
- ロールバック-通常、1つのサービスの特定の部分または失敗した配信プロセスからの外部イベントまたはトリガーの発生時にサービス全体のメタプロジェクトから
- サービスの削除-環境が不要になった
In QA
のステータスの後、単一のテスト環境(showroom
)からエコシステム全体を完全に削除するために必要 - イメージアセンブリ(補助プロセス)
Docker
イメージを収集してDockerレジストリに送信する必要がある場合、サービス配信のプロセスと独立したプロセスの両方で使用できます。多くの場合、広く使用されているイメージ(データベース、一般サービス、頻繁に変更されるサービス)
ログ収集および処理システム

Dockerコンテナがログを使用できるようにする唯一の方法は、このコンテナ自体で実行されているルートプロセスのSTDOUTまたはSTDERRにログを書き込むことです。 実際、サービス開発者にとって、このデータで次に何が起こるかは問題ではありません。主なことは、必要なときに、できれば過去の予測可能な時点まで利用できることです。 これらの期待を満たすためのすべての責任は、Kubernetesとエコシステムをサポートする人々にかかっています。
公式ドキュメントでは、ログを操作するための基本的で一般的に悪くない戦略の説明を見つけることができます。これは、膨大な量のテキストデータを集約して保存するための適切なサービスを選択するのに役立ちます。
, fluentd , , Elasticsearch . , , , .
Elasticsearch , Docker .
Tracing

, "" " , ?!". , , , -, — , .
Opentracing Zipkin . , , , .
, "Trace Id" , , .., , .
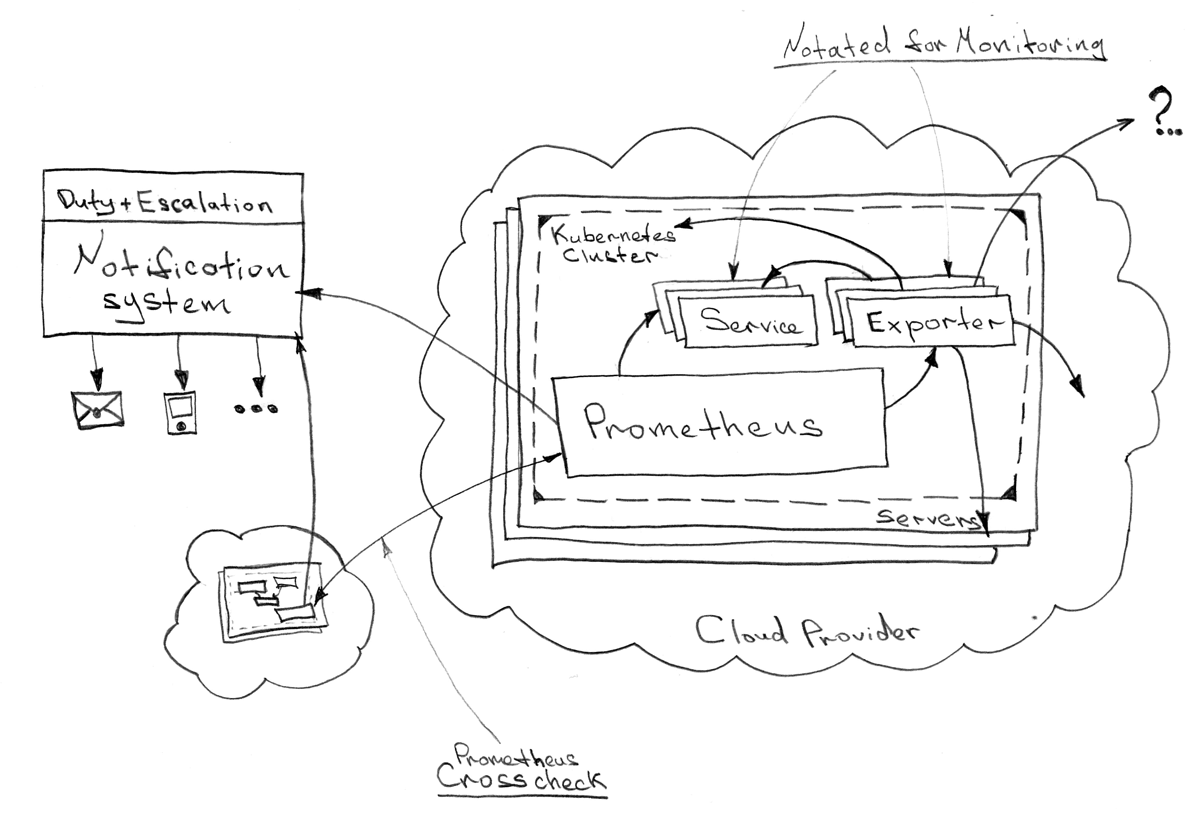
Prometheus - Kubernetes " " . Kubernetes , .
, , , , . ( ) ( "staging" ). "-" .
, , , :
- :
- (i/o, )
- (CPU, RAM, LA)
- :
- (kubelet, kubeAPI, DNS, etcd, ..)
-
pod
-
- :
- API
- HTTP API
-
worker
- - ( , , , ..)
- HTTP
- - ( )
, , email, SMS .
OpsGenie c alertmanager
- Prometheus.
OpsGenie , , , . . , /: — Infra+Devops, — Devops, — .
API Single Sign-on
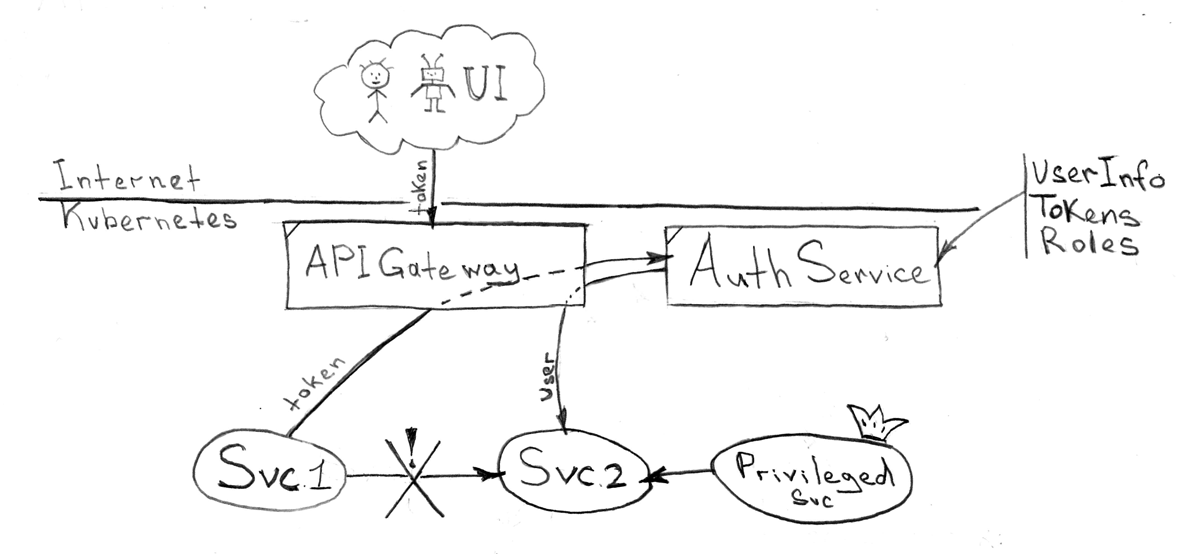
, , (, "Identity ", - ), , , API . , "Identity ", .
, . , . "" , HTTP .
API , - — . : UI , - . ( ), , UI . UI ( TTL) ( TTL)
, API :
- ( )
- c Single Sign-on :
- HTTP (ID, , )
- (/) Single Sign-on
- HTTP
- API (, Swagger json/yaml )
- URI
(Event Bus) (Enterprise Integration/Service Bus)
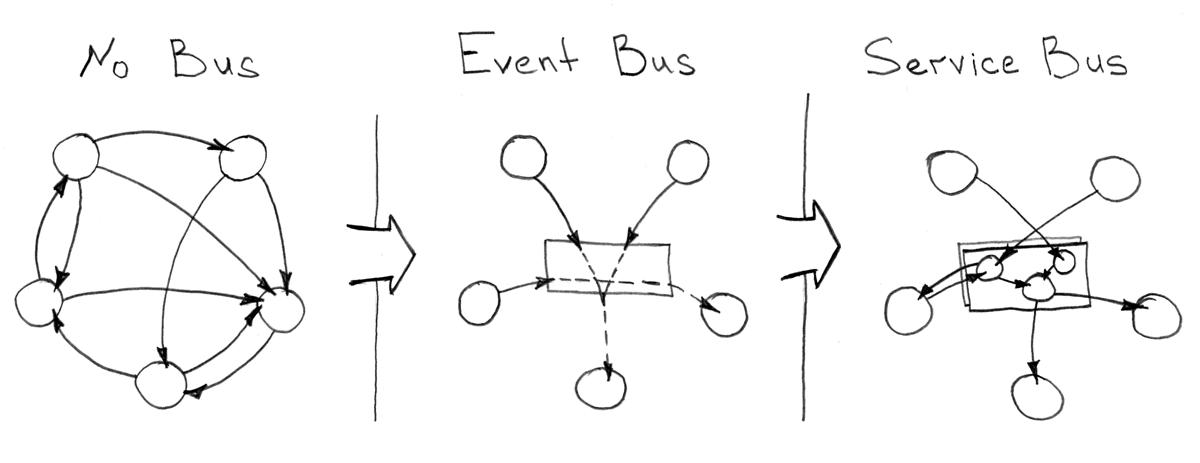
, -, . , , . , , - .
, : RabbitMQ , Kafka , ActiveMQ . , CAP - .
, , , " ", , "Dumb pipe — Smart Consumer" , .
"Enterprise Integration/Service Bus" , - . , :
- /
- ,
- ( )
, Apache ServiceMix , .
Stateful
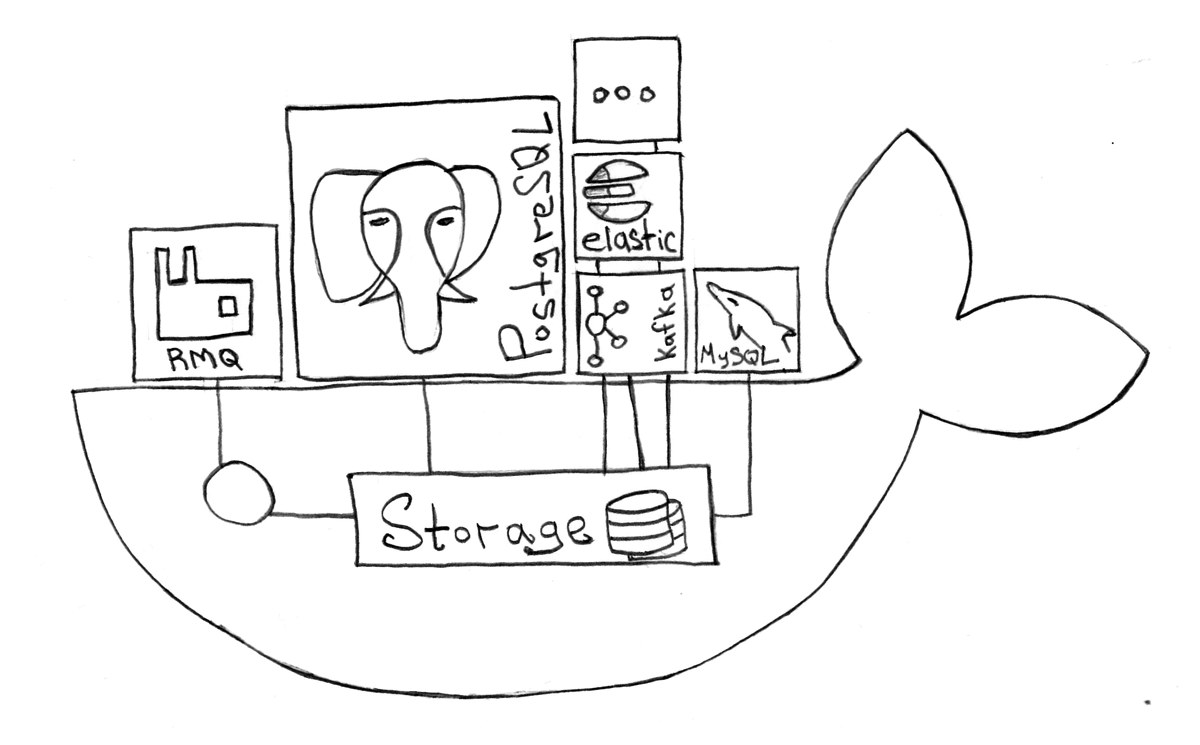
Docker, Kubernetes, , . , "" - … , "" "", , , Docker .
, , Kubernetes .
, Stateful , "":
- — PostDock Postgresql Docker
- / — RabbitMQ ,
cluster_formation
- — redis
- — Elasticsearch , ,
- — (ftp, sftp ..)
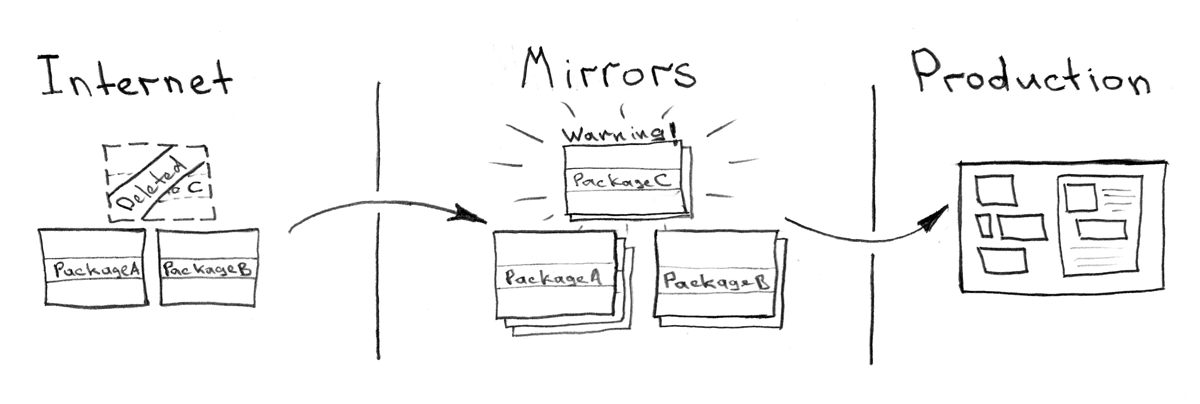
, , . , , — " ". : Docker , rpm , , python/go/js/php .
. , , " private dependency mirror for ... "
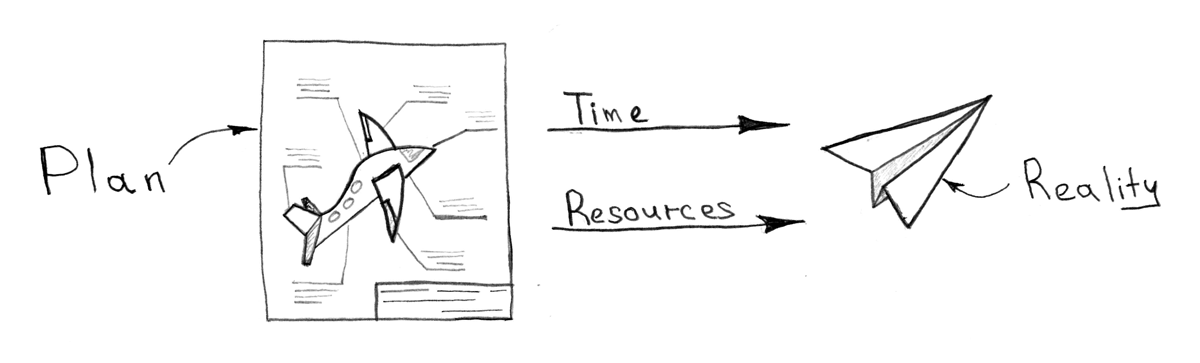
, , . : (1-5 ), — (5-10 ), — (10-20 ), .
, - , , , , , , .
, , . , . .
, . — , , .. , , , ( ), , " ", , !
" ?"…
— , - , , !