
特定の構成を考慮しない設定でバックアップジョブを開始する
バックアップ計画の欠如とバックアップストレージ特性の評価は、最も一般的な「最悪の慣行」です。 多くのユーザーは、製品ウィザードの[次へ]ボタンをクリックするだけで、標準設定でバックアップ製品をインストールします。 さらに、多くは、インフラストラクチャの詳細、古いコピーを削除するためのポリシー、およびその他の重要な側面を考慮せずに、バックアップジョブのデフォルト設定のままにします。 その結果、タスクの開始時および完了時、リポジトリの早期満杯時にエラーが発生し、その結果、テクニカルサポートサービスとの快適で時間のかかるコミュニケーションが発生します。
そして、どのように正しいですか? 例としてVeeam製品を使用する:このようなシナリオを回避するには、Veeam Backup&Replicationをインストールする前に、たとえばインフラストラクチャの動作を監視およびレポートするツールであるVeeam ONEを使用することをお勧めします。 そのため、 VM Configuration Assessmentレポートを開くと、仮想マシンがバックアップの準備ができているかどうか、また準備ができていない場合は、その理由を確認できます。 VM変更率推定レポート(VM変更頻度の推定)は、仮想マシンブロックの変更に関する統計に基づいており、必要なリポジトリサイズを正しく計算できます。

計画に役立つレポートの詳細については、 こちらをご覧ください 。
オンラインリカバリポイントサイズ計算機である Veeamの別のツールも、バックアップ環境の計画に役立ちます。
すべてのタスクをチェーンする
いずれかのエラーが原因ですべてのバックアップジョブを埋めたいですか? 次に、それらを従属タスクのチェーンに結合して、1つのタスクが完了するとすぐに別のタスクが開始されるようにします。 この場合、バックアップウィンドウの増加、タスクの開始の遅延、その他の不快な結果を受け取ることが保証されます。
そして、どのように正しいですか? 実際、特定の場合にのみタスクを結合する必要があります。 たとえば、2つのアプリケーションを同時にバックアップしたくない場合は、他のアプリケーションのバックアップが完了した後にのみ、一方のバックアップの開始を構成できます。 Veeamの場合、リソースを計画するために製品を委託する方が適切です。 Veeam Backup&Replicationスケジューラーは、「スマートアルゴリズム」を使用してインフラストラクチャコンポーネントの負荷を分散し、最適なデータ転送モードを選択し、リポジトリへのチャネル帯域幅の確立された制限内で動作することにより、複数のタスクを同時に実行してバックアップウィンドウを最適化できます。
バックアップを検証しない
人生の経験から、多くの企業はバックアップのテストを「保存」しています。 これは、手動によるバックアップからのシステムの復元をテストする本格的なプロセスは非常に時間がかかる操作であるため、リカバリフェーズで発生する可能性のある問題に関する認識不足と経済的要因によるものである可能性があります。 障害が発生した場合、特定の時間に重要なデータが復元されないか、さらに悪いことに、部分的または完全に失われる可能性があるため、このような状況にはマイナスの結果が伴います。
1998年にピクサースタジオの実際のケースで何が起こったのか、漫画「トイストーリー2」のすべての作業材料がほとんど失われたとき、あなたは私たちの投稿で「 ピクサーのケースまたはテストバックアップの重要性についてもう一度 」を読むことができます。
そして、どのように正しいですか? バックアップからのリカバリのテストは定期的に行う必要があります。 バックアップ自体の整合性テストと、バックアップ からのリカバリの テストを区別する必要があります 。 最初のケースでは、コピーの整合性をデータブロックのチェックサムに対してのみチェックします。 2番目の方法では、特定のシミュレートされた単一の障害のシナリオまたは生産的なネットワークの本格的な「大惨事」を反映したテストを実施します。 最終的には障害が発生した場合の実際のデータ回復に関心があり、バックアップ自体の整合性が損なわれていなくても、復元が失敗する可能性があるため、最初の操作だけでなく2番目の操作も非常に重要です。
回復の失敗には多くの理由が考えられますが、そのうちのいくつかを挙げます。
- システムを復元するとき、バックアップ製品が自動的に実行しない追加の手順が必要になる場合があります(復元されるシステムと対話するリモートサービスの再構成など)。
- 管理者の新しいラップトップからバックアップリポジトリへのアクセスが拒否される可能性があります(これがこのようなアクセスの最初の試みであるためです-これには余分な時間がかかります)。
- チャネルの低帯域幅は、オフサイトのリカバリプロセスを「中断」します(バックアップを別のオフィスからプルアップする必要がある場合)。
- 過去6か月間の毎日のバックアップのサイズが絶えず増加していることが判明しました(ほぼすべてのソースシステムのサイズが絶えず増加しています)-ある時点でテープに収まらず、エラーは気付かれませんでした(上記のPixarの例)
- 古いバックアップは新しいハードウェアに復元されない場合があります。
- リカバリ中に、すべてのファイルまたはマシンがバックアップジョブ領域に落ちたわけではないことが判明する場合があります。
これらの問題はどのように解決できますか? たとえば、Veeam SureBackupテクノロジーを使用すると、バックアップから仮想マシンを自動的にテストし、復元できることを確認できます。 SureBackupタスク(投稿「SureBackup-バックアップからデータを復元する可能性を自動的に確認する」を参照)は、隔離された仮想ラボで、依存関係(最初にドメインコントローラー、次にExchangeサーバーなど)を考慮してすべてのマシンを自動的に起動し、操作性をチェックします(ユーザーが作成したスクリプトの使用を含む)、関連レポートを電子メールで送信します。
インスタントVMリカバリプロセスを完了しないでください
そして最後に、特にVeeamに関する今日のトピックに関する最悪のアドバイスは、 インスタントVMリカバリを使用して仮想マシンを起動し、それを忘れることです。 完全に忘れてください。 この場合、大量の問題が保証されます。 リポジトリからマシンを直接実行すると、リカバリポイントがブロックされるため、他のタスク(SureBackupやBackupCopyなど)は開始されません。 これは、マシンがバックアップファイルから読み取りモードで直接起動するためです。つまり、ファイル自体に変更を書き込むことはありません。 これにより、VeeamバックアップサーバーのC:ドライブに別のファイルが作成されます。マシンを少なくとも数日間実行したままにすると、信じられないほどのサイズになります。
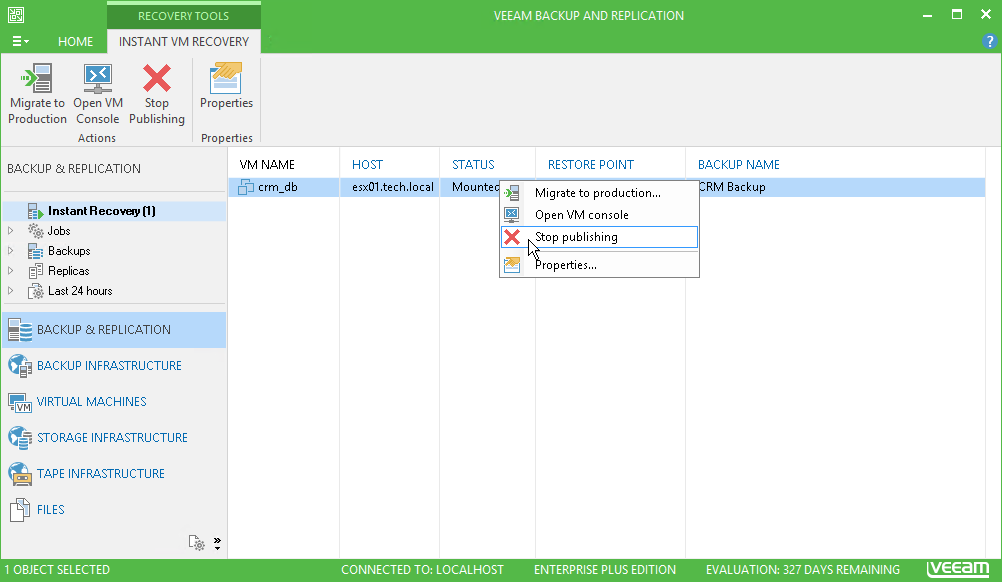
そして、どのように正しいですか? これを回避するには、インスタントVMリカバリの完了後、すぐにマシンを本番環境に転送してください。 このプロセスの詳細については、Veeam ユーザーガイドを参照してください。
おわりに
この記事が時間とお金を節約し、説明されている問題から頭痛を和らげることを願っています。 「最悪の慣行」のリストに追加するものはありますか? その後、コメントで共有してください!
結論として、使用する製品にかかわらず、バックアップのベストプラクティスに関するベストポストへのリンクを引用します。