
cs.betlabs.ruへの訪問者に出会うのは、Steve Jobsによるこの引用であり、学生が自宅や研究室の課題にもっと熱心に取り組むよう動機付けようとする試みと考えることができます。 残念ながら、教師からの動機が生徒の成績に与える影響を定量化するための指標はありません。 さらに、研究グループの競争環境は、全体的なパフォーマンス指標においてはるかに重要な要素であると考えています。 さて、これは単なる仮説であり、その検証は私の科学的興味の分野にはありません。
背景
私は、他の大学院生と同様に、大学での教育にカリキュラムから100時間を費やす必要があります。 具体的には、 ビジネス情報学の 1年生のために、 C#の 「コンピューターサイエンスとアルゴリズム化の基礎」および「オブジェクト指向プログラミング」コースで実験室クラスを実施するという課題に直面しました。 大多数の学生が、現在および将来のアクティビティでプログラミングを絶対に必要としないと信じているという事実に注意することが重要です。
初年度
教育の最初の年と最初の学期に、私は2つの研究グループを持ち、合計58人でした。 タスク:テストを実施し、個々の宿題をチェックし、学期の仕事のために5点スケールでマークを設定します。 私が付けたマークは最終的なものではなく、最終的なマークは講師の試験で決定されます。
負荷は大きく、多くのことをする必要があったので、学生からは、この科目を人生で必要としないというコメントを頻繁に聞きました。 私は認知能力を訓練する必要性について説明的な議論を頻繁に開催しました。プログラミングは脳を全身的で同時に創造的な思考に備えるための優れたツールです。 私の言葉はほとんどの人の心に響いたとは思いませんが、多くの学生がプログラミングを考え、自分自身に役立つと思ったようです。
ソフトウェアとサービス
- リモートコントロールの結果とテスト結果の記録を保持するためのGoogleスプレッドシート
- テスト記録の記録とフィードバックの収集のためのGoogleフォーム
- BitLy.comリンク削減サービス
DZの制御と配信はどうでしたか
私は実験室のクラスを実施するプロセスにしか精通していないので、講師が推奨したとおりにしました。 コントロールは紙に書かれていました。 実験室の仕事はいつも宿題をチェックするために行ってきました。 プログラムの動作を「目で」確認しました。
まとめ
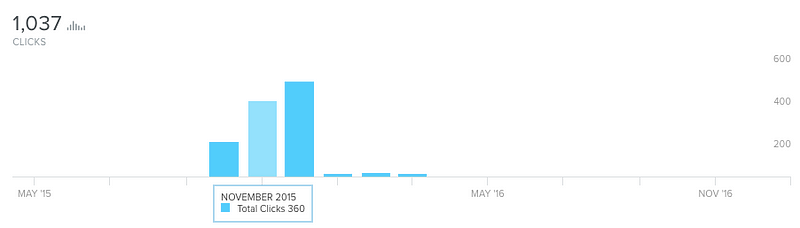
宿題を完了するためのタスクのリストがあるページにアクセスする統計。 秋学期には、学生は積極的に11月中旬に勉強を始めます。
学期の終わりに、科目のコースと有用性に関する古典的な質問について匿名の調査を実施しました。 アイテムの有用性は平均で3.76と評価され、被験者の魅力は5段階で3.95でした。
ほとんどの場合、試験の結果と予測した点数は一致しました( 精度90% )。 グループの1つは、外部ストリーム全体の他のトレーニンググループの中で最高の結果を示すことができました。 私の意見では、要因の1つはグループで形成された競争環境である可能性があります。 私は両方のグループの学生の試験結果を比較しました。平均と中央値はそれぞれほぼ同じであり、試験の学業成績は5つで著しく異なります。
二年目
生産性と自動化の時間です!
タスクは同じで、学生は新入生でしたが、今回は、試験の最終点ではなく、魅力、わかりやすさ、有用性の点でKPIを上げることにしました。 私の生徒はまだ昨日の小学生です。彼らのほとんどはコンピューターサイエンスの試験に合格しませんでした。一般的に、彼らはプログラミングの絶対的なゼロでした。 ハーバードCS50コースに少し触発され、私はルーチンを自動化して、学生の質問とコース教材の詳細な説明のための時間を空けるべきだと決めました。
ソフトウェアとサービス
- ラボからのメモとスクイーズのためのDropbox Paper
- コントロールと宿題の自動検証のためのHackerRank
- リモートコントロールの結果とテスト結果の記録を保持するためのGoogleスプレッドシート
- テスト記録の記録とフィードバックの収集のためのGoogleフォーム
- Trelloの学生が質問に私のメールに手紙を送る
ToDoボードで自動的にカードになります
DZの制御と配信はどうでしたか
タスクの検証を自動化したいという思いから、学生のgitの使い方を学ばなければならないという考えに至りました。 基本的に、既製のほぼ完璧なボックスソリューションが必要でした。 このソリューションはHackerRankサービスでした。 このサービス+ aaa (公式APIを使用して私が作成した追加機能)を使用すると、タスクを自動的にチェックし、削除された作品を見ることができました(盗作検出器)。 タスクの準備とテストの作成には時間がかかりますが、必要なのは一度だけです。 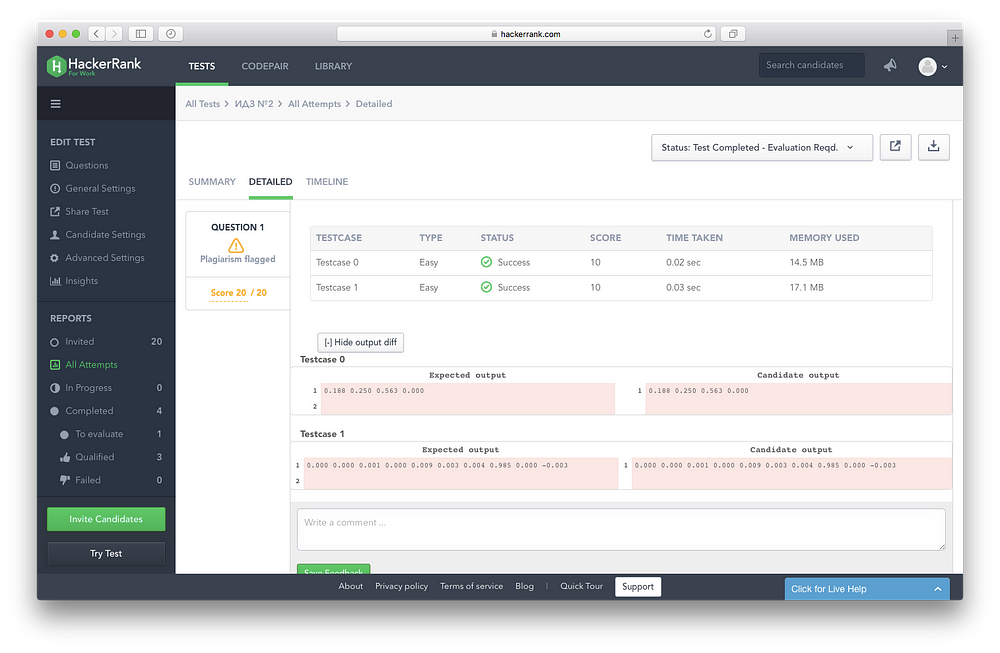 誰かが見落としたようで、恥ずかしがり屋ではありません:(
誰かが見落としたようで、恥ずかしがり屋ではありません:(
学期マークの設定
この部分について詳しく説明したいと思います。 複雑な用語を使用せず、すべてを指で説明することを約束します。
まず、生徒の成績を評価する際の教師の主観性を排除したかった。 第二に、誰がマークしているのか、ファイナルの数え方、スケールはどうあるべきかなどを考えないでください。 第三に、学期の成績を設定する要因として、学生のほぼすべての「くしゃみ」(出席、教室での活動など)を考慮します。
どのようなデータを収集しましたか?
- 出席:特定の日にあった/なかった-バイナリ記号
- 教室で働く:特定の問題を解決するために、特定のスコア-数値
サイン - テストの結果-数値記号
- 宿題の結果-数字
これらはすべて1つのテーブルにマージされ、スケーリングされてK-Meansアルゴリズムによって入力に供給されます。その結果は、学生と彼が属するクラスターの間でマッピングされます(マーク2、3、4、5)。
「より客観的」と思われるため、コンピュータにセットを4つのサブセットに分割するように依頼します。
import pandas as pd import numpy as np from sklearn.cluster import KMeans from sklearn import preprocessing from sklearn.decomposition import PCA # Learn clu = KMeans(n_clusters=4, random_state=240) clu.fit(processed_data) # Clusters labels = pd.DataFrame(clu.labels_) # Reduce space dimension pca = PCA(n_components=3) pca.fit(processed_data) pca_processed_data = pca.transform(processed_data)
機械学習の最も単純な方法を使用すると、複雑な準備は必要ありません
これは、属性の3次元空間でマークとクラスターがどのように見えるかです。 間違いなく誰かが2つと自動を置く必要があります:)
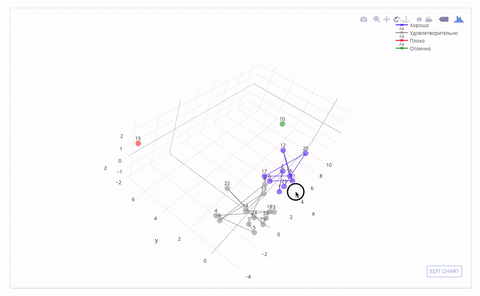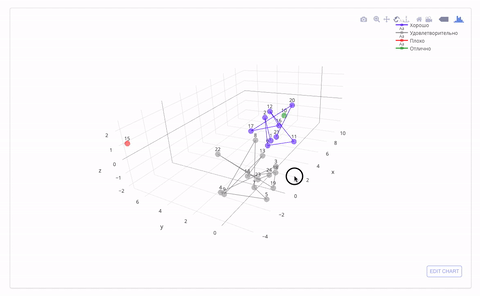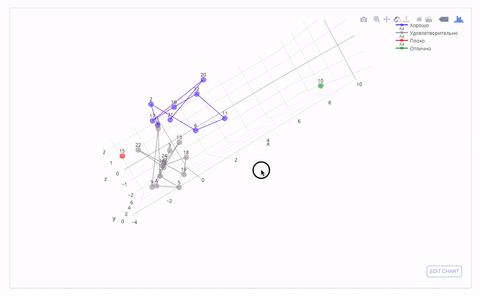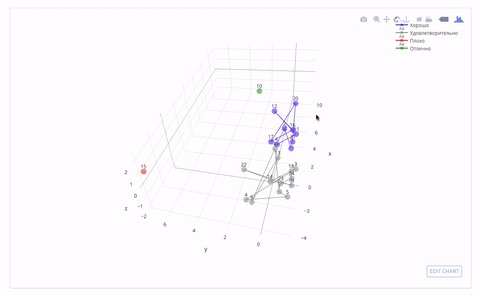
パフォーマンスによる生徒のクラスタリング(KMeans)
一見したところ、得られたマークは、特定の生徒の成績に関する私の考えと一致しています。 このアプローチがどこにでも適用され、トレーニングサンプルのデータが収集されると、トレーニングの最初の月(仮説)の学業成績によって学期の終わりにマークを予測することが可能になります。 したがって、これにより、「問題のある」生徒を特定し、教材をさらに明確にする助けを提供する時間ができます。
結論の代わりに
ラボでは、材料の説明と問題の解決に専念しています。 これが確立されたKPIの増加を示すかどうかは未解決の問題です。
上記の教育目的のHackerRankサービスは、非常に重要で便利な機能がないため、あまり便利なツールではありません。 この古典的な市場調査によれば→顧客開発→MVP→事前シード→シード
...まあ、あなたは知っています。