 2016年12月、友人と私は新しいプロジェクトに取り組み始めました。ドキュメントのコレクションインデックス検索システムです。 このシステムは、全文検索のメインエンジンとして使用するElasticSearch(以降-ES)を中心に構築されています。
2016年12月、友人と私は新しいプロジェクトに取り組み始めました。ドキュメントのコレクションインデックス検索システムです。 このシステムは、全文検索のメインエンジンとして使用するElasticSearch(以降-ES)を中心に構築されています。
ESに関する一連の記事で、プロジェクトの作業中に取得した貴重なデータを読者と共有したいと考えています。 検索エンジンの基礎から始めましょう-検索結果の強調表示(以下、強調表示と呼びます)。
検索結果の適切な強調表示は、おそらくユーザーにとっての検索エンジンの有効性にとって最も重要な基準です。 まず、検索結果にドキュメントを含めるロジックが表示され、次に、見つかったテキストのブロックを強調表示することで、見つかったヒットのコンテキストをすばやく評価できます。
検索エンジンの重要な要件の1つは、大きなファイル(100 MB以上)を迅速かつ効率的に処理できることでした。 この記事では、大きなドキュメントフィールドを強調表示するときにESから高いパフォーマンスを実現する方法を説明します。
以下のスクリーンショットは、プロジェクトの検索結果の強調表示がどのように機能するかを示しています。
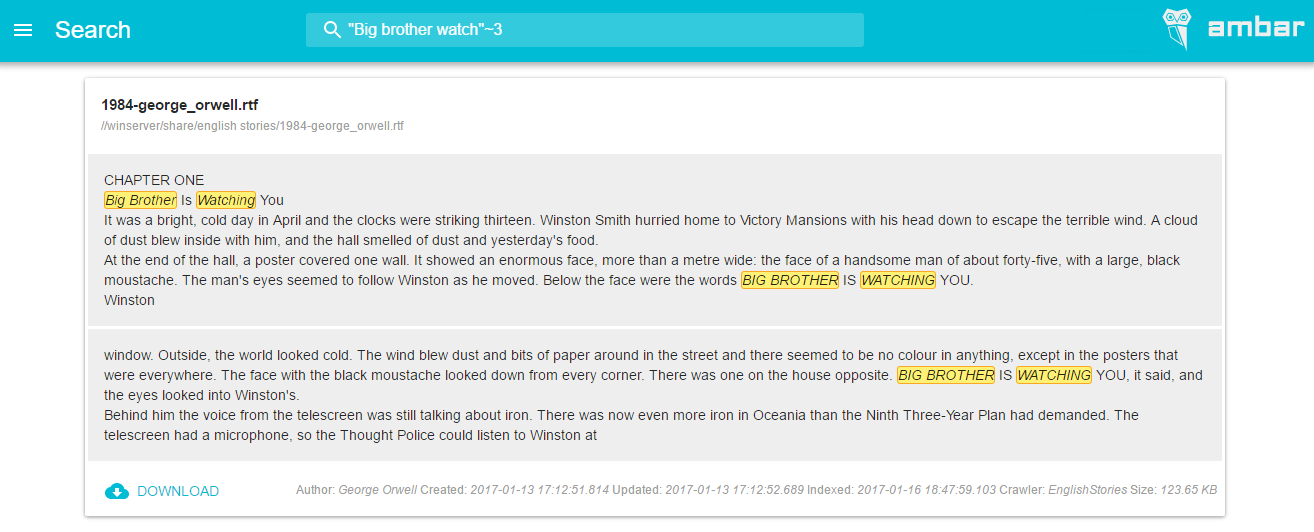
最初のステップまたは問題
そのため、ESを使用して、メタデータと解析されたファイルコンテンツを保存および検索します。 ESに保存するドキュメントの例:
{ sha256: "1a4ad2c5469090928a318a4d9e4f3b21cf1451c7fdc602480e48678282ced02c", meta: [ { id: "21264f64460498d2d3a7ab4e1d8550e4b58c0469744005cd226d431d7a5828d0", short_name: "quarter.pdf", full_name: "//winserver/store/reports/quarter.pdf", source_id: "crReports", extension: ".pdf", created_datetime: "2017-01-14 14:49:36.788", updated_datetime: "2017-01-14 14:49:37.140", extra: [], indexed_datetime: "2017-01-16 18:32:03.712" } ], content: { size: 112387192, /* 100 Mb */ indexed_datetime: "2017-01-16 18:32:33.321", author: "John Smith", processed_datetime: "2017-01-16 18:32:33.321", length: "", language: "", state: "processed", title: "Quarter Report (Q4Y2016)", type: "application/pdf", text: ".... ...." } }
ご想像のとおり、これは100 MBを少し超えるサイズの財務レポートを含むpdfファイルの解析済みコンテンツです。 content.text
フィールドを意図的に短くしましたcontent.text
その長さが約100 MBであることは明らかです。
簡単な実験を行ってみましょう。これらのドキュメントを1000個取得し、特別なインデックス設定やES自体を使用せずに、ESでインデックスを作成します。 これらのドキュメントの検索とハイライトがどのくらい速く機能するかを見てみましょう。
結果:
-
match_phrase
フィールドでmatch_phrase
を検索:5〜30秒。 - 各ドキュメントの
content.text
フィールドの強調表示:10秒以上。
このパフォーマンスは良くありません。 ユーザーは、数十秒後にではなく、即座に結果を確認することを期待しています(<200 ms)。 ハイライトの形成が遅いという問題を解決する方法を考えてみましょう。 大きなファイルでのクイック検索の問題については、シリーズの次の記事で検討します。
強調表示アルゴリズムの選択
ESには、3種類の蛍光ペンを使用する機能があります。 公式マニュアルを参照してください。
読むのが面倒な人のために、指で:
- プレーン -デフォルトオプション、最も遅く、しかし最高の品質(ESによれば、Lucene検索アルゴリズムをほぼ100%反映し、これは本当です)、ハイライトを形成するために、メモリ内のドキュメント全体をアンロードし、それを再分析します。
- 投稿はより高速な蛍光ペンであり、オファーのフィールドを打ち負かし、ドキュメント全体ではなく、トークンが見つかったオファーを引き出し 、 BM25アルゴリズムに従ってランク付けします。 これらの同じオファーのポジションでインデックスを強化する必要があります。
- Fast Vector Highlighting(FVH) -特に大きなドキュメントの場合、最速の蛍光ペンとして配置されます。 ソースドキュメント内のすべてのトークンの位置に関するデータでインデックスを強化する必要があります。これにより、ドキュメントのサイズに関係なく、ほぼ一定の時間ハイライトが形成されます。
上記のように、デフォルトでは、ESはプレーンハイライターを使用します。 したがって、ハイライトを形成するたびに、ESは100メガバイトのテキストをすべてメモリにアンロードし、このため、非常にゆっくりと要求に応答します。 プレーンハイライターを放棄し、投稿とFVHをテストすることにしました。 その結果、いくつかの理由でFVHを選択しました。
- 平均で100 MBのFVHドキュメントには約10〜20ミリ秒のハイライトがあり、ポスティングはこれに約1秒を費やします。
- 投稿によってテキストが常に正しく文章に分割されるとは限らないため、受信したハイライトのサイズが頻繁にジャンプします(50ワード、または300ワードを返すことがあります)。 FVHでは、そのような問題は認められませんでした。 ヒットの両側で指定された数のトークンを返します
- 位置に関係なく蛍光ペンを投稿するため、この場合のフレーズの強調表示は正しく機能しません。 たとえば、
simple_string_query
"Ivanov Ivan"〜5は、「Ivanov」と「Ivan」の2つのトークンが互いに5トークン以下の距離にある場合だけでなく、特定のドキュメントフィールド内の「Ivanov」または「Ivan」の他のすべてのトークンも強調表示します。 「ivans」と「ivan」のmatch
求める単純なリクエストのように
高速ベクターハイライターの落とし穴
FVHを使用するプロセスで、次の問題に気付きましたmatch_phrase
検索クエリ「Ivanov Ivan」は「Ivanov Ivan」および「Ivan Ivanov」の出現を検出しますが、FVHはリクエストで指定された順序でヒットのみを強調表示します。 このニュアンスはどのESマニュアルにも記載されていませんが、私たちの意見では、このエラーはFVHがmatch_phrase
リクエストのトークンの位置を考慮するという事実の結果として発生します。 ラウンドアバウトの方法で問題を解決しました-フレーズ内のトークンの可能な位置がすべてソートされるリクエストにhighlight_query
フィールドを追加しhighlight_query
。 これは、パフォーマンスを適切なレベルに維持しながら、すべてのハイライトを取得できる唯一の方法です。
まとめ
大きなESドキュメントを強調表示することは、非常に迅速に行うことができます。 インデックスを適切に構成し、蛍光ペンの機能を考慮することが重要です。 あなたが同様の問題を解決し、あなたが考えるように、よりエレガントな解決策を見つけたなら、コメントでそれを教えてください。