電子商取引市場では興味深い状況が発生しています。 総キャッシュフローは増加していますが、売り手の数も増加しています。 これにより、各店舗のシェアが低下し、競合が激化しています。 平均購入サイズ(したがって利益)を増やす1つの方法は、顧客に興味のある追加の製品を提供することです。
この記事では、Cloud Platformに基づいて環境を設定し、基本的な推奨システムをサポートする方法を学習します。基本的な推奨システムは、さらに開発および拡張できます。
ユーザーに推奨事項を選択して提供できる不動産賃貸代理店のWebサイトのソリューションについて説明します。
Google Cloud Platformを初めて使用する場合は、一連のウェビナーをご覧ください
| [1月19日、木曜日、11:00モスクワ時間]
Google Cloud Platform機能の概要
ウェビナーエントリへのリンク [2月3日、金曜日、11:00モスクワ時間] Google Cloud Platformインフラストラクチャサービス
ウェビナーエントリへのリンク [2月17日、金曜日、11:00モスクワ時間] Google Cloud Platformのビッグデータと機械学習ツール
ウェビナーエントリへのリンク [3月2日、木曜日、11:00モスクワ時間] ワークショップ:Google Cloud Platformサービスのチュートリアル
|
ウェビナーリード | |
|---|---|
オレグ・イボニン@GoogleAmsterdam 
クラウドWebソリューションエンジニア Olegは、構成のコストを分析し、Google Cloud Platformに基づくクラウドソリューションのアーキテクチャを計画するためのツールを開発しています。 Olegの開発は、Google Cloud Platform Pricing Calculatorなどの公開されているGCPツールで使用されています | ドミトリー・ノヴァコフスキー@GoogleAmsterdam 
カスタマーエンジニア Dmitryは、Google Cloud Platformのビジネス顧客向けの販売サポートとアーキテクチャソリューションに従事しています。 Dmitryの主な焦点は、インフラストラクチャサービスの分野にあります:Google Compute Engine(GCE)、Google App Engine(GAE)、Google Container Engine(GKE / Kubernetes)。 |
| おそらく、この記事を読んで、Google Cloud Platformでこのシナリオを再作成することをお勧めします。 リンクをクリックすると、GCPサービスを60日間テストするための300ドルを受け取ります |
スクリプト
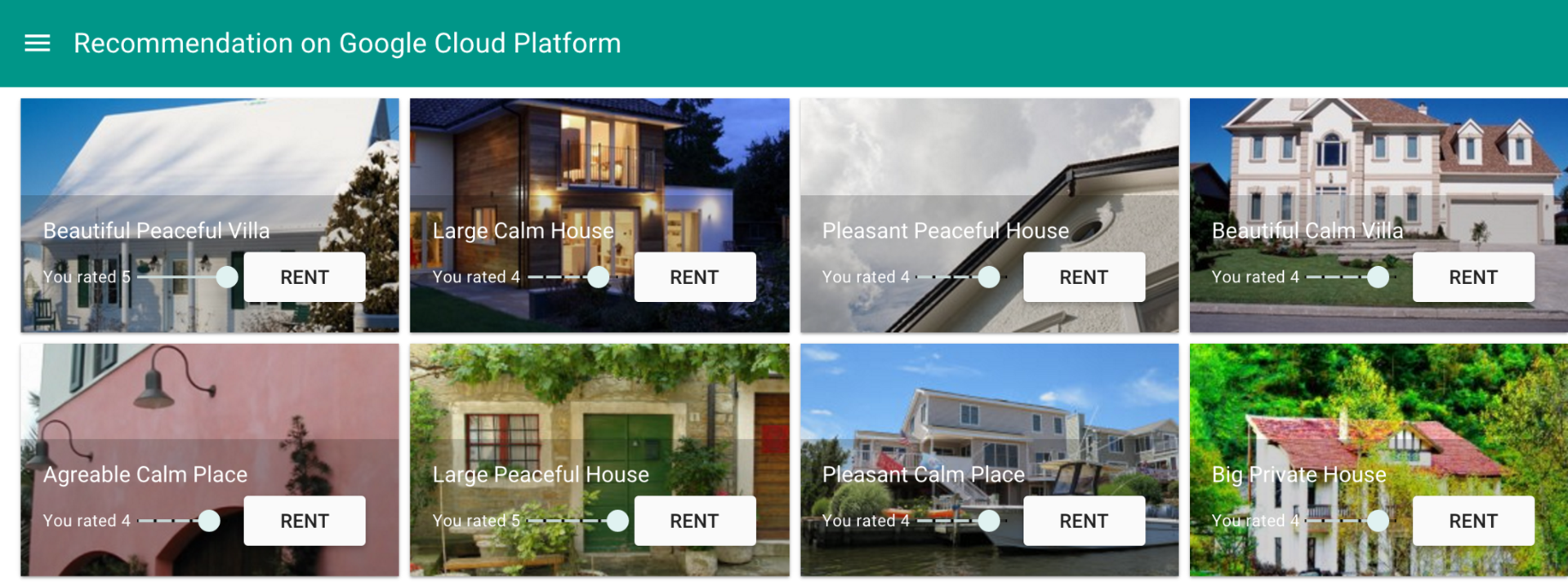
アンナは専用サイトで別荘を探しています。 以前は、彼女はすでにこのサイトから住宅を借りていくつかのレビューを残していたため、システムには彼女の好みに基づいて推奨事項を選択するのに十分なデータがあります。 アンナのプロフィールの推定から判断すると、彼女は通常、アパートではなく家を借りています。 システムは、彼女に同じカテゴリの何かを提供する必要があります。
ソリューションの概要
リアルタイム(サイト上)または事後(電子メール経由)で推奨事項を選択するには、ソースデータが必要です。 それでもユーザーの設定がわからない場合は、ユーザーが選択した提案に基づいて推奨事項を選択できます。 ただし、システムは絶えず学習し、顧客の好みに関するデータを蓄積する必要があります。 十分な情報が収集されると、機械学習システムを使用して関連する推奨事項を分析および選択できるようになります。 さらに、システムは他のユーザーに関する情報を送信したり、時々再トレーニングしたりできます。 この例では、推奨システムはすでに機械学習アルゴリズムを使用するのに十分なデータを蓄積しています。
このようなシステムでのデータ処理は、通常、収集、保管、分析、推奨事項の選択の4段階で実行されます(下図を参照)。

このようなシステムのアーキテクチャは、次のように概略的に表すことができます。

各ステップは、特定の要件に合わせてカスタマイズできます。 システムは次の要素で構成されています。
- フロントエンド すべてのユーザーアクションが記録される、つまりデータが収集されるスケーラブルインターフェイスパーツ。
- 保管 機械学習プラットフォームで使用可能な永続ストレージ。 データの読み込みには、データのインポート、エクスポート、変換など、いくつかの手順が含まれます。
- 機械学習。 収集されたデータの分析と推奨事項の選択が実行される機械学習プラットフォーム。
- 2番目の要素はストレージです。 フロントエンド部分がリアルタイムまたは事後的に使用する別のリポジトリ-推奨事項を提供する必要がある場合に応じて。
コンポーネントの選択
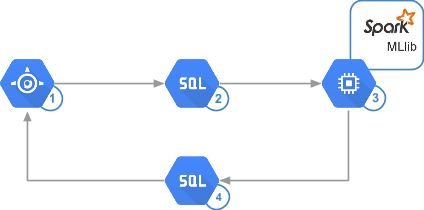
高速で便利、安価で正確なソリューションを得るために、 Google App Engine 、 Google Cloud SQL 、およびGoogle Compute EngineベースのApache Sparkが選択されました。 構成は、bdutilスクリプトを使用して作成されました。
App Engineサービスを使用すると、1秒あたり何万ものリクエストを処理できます。 さらに、管理が容易で、サイトの作成から内部ストレージへのデータの書き込みまで、あらゆるタスクを実行するコードをすばやく記述して実行できます。
Cloud SQLは、ソリューションの作成も簡素化します。 最大208 GBのRAMを搭載した32コアの仮想マシンを展開し、GBあたり毎秒30のI / O操作と数千の同時接続により、オンデマンドで最大10 TBのストレージを増やすことができます。 これは、検討中のシステムおよび他の多くの実際のケースにとって十分すぎるほどです。 さらに、Cloud SQLはSparkからの直接アクセスをサポートしています。
Sparkは、従来のHadoopプロセッサと比較して優れています。具体的なソリューションにもよりますが、パフォーマンスは10〜100倍高くなります。 Spark MLlibライブラリを使用すると、数億の評価を数分で分析し、アルゴリズムをより頻繁に実行して、推奨事項を最新の状態に保つことができます。 Sparkは、よりシンプルなプログラミングモデル、より便利なAPI、およびより汎用的な言語が特徴です。 計算のために、このフレームワークはRAMを最大限に使用して、ディスクアクセスの回数を減らします。 また、I / O操作の数も最小限に抑えられます。 分析インフラストラクチャをホストするこのソリューションでは、Compute Engineが使用されます。 これにより、使用の事実に応じて毎分支払いが行われるため、コストを大幅に削減できます。
次の図は、同じシステムアーキテクチャを示していますが、現在は使用されているテクノロジが含まれています。
データ収集
推奨システムは、暗黙的な情報(動作)または明示的な情報(評価とレビュー)に基づいてユーザーデータを収集できます。
すべてのアクションはユーザーの介入なしにログに記録できるため、動作データの収集は非常に簡単です。 このアプローチの欠点は、収集されたデータを分析するのが難しくなることです。たとえば、最も重要なデータを識別することができます。 ログエントリを使用して明示的なアクティビティデータを分析する例は、 ここから入手できます 。
評価とレビューを収集することは、多くのユーザーがそれらを残すことに消極的であるため、より困難です。 ただし、顧客の好みを理解するのに最も役立つのはこのようなデータです。
データ保存
アルゴリズムで使用できるデータが多いほど、推奨事項はより正確になります。 つまり、すぐにビッグデータの操作を開始する必要があります。
使用するストレージのタイプの選択は、推奨データを作成するデータに基づいて異なります。 NoSQLデータベース、SQL、またはオブジェクトストアでもかまいません。 データの量と種類に加えて、実装の容易さ、環境に統合する機能、移行のサポートなどの要因を考慮する必要があります。
スケーラブルな管理されたデータベースは、ユーザーの評価とアクションを保存するのに最適であり、使いやすく、より多くの時間を費やすことができます。 Cloud SQLはこれらの要件を満たすだけでなく、Sparkからデータを簡単にダウンロードできるようにします。
次のコード例は、Cloud SQLテーブルスキーマを示しています。 賃貸物件は「宿泊施設」テーブルに入力され、この物件のユーザー評価は「評価」テーブルに入力されます。
CREATE TABLE Accommodation ( id varchar(255), title varchar(255), location varchar(255), price int, rooms int, rating float, type varchar(255), PRIMARY KEY (ID) ); CREATE TABLE Rating ( userId varchar(255), accoId varchar(255), rating int, PRIMARY KEY(accoId, userId), FOREIGN KEY (accoId) REFERENCES Accommodation(id) );
Sparkは、Hadoop HDFSやCloud Storageなどのさまざまなソースからデータを取得できます。 このソリューションでは、データはJDBCコネクターを使用して Cloud SQLから直接抽出されます 。 Sparkジョブは並行して実行されるため、このコネクターはクラスターのすべてのインスタンスで使用可能でなければなりません。
データ分析
分析を成功させるには、アプリケーションの要件を明確に策定する必要があります。
- 適時性 。 アプリはどれくらい早く推奨事項を作成する必要がありますか?
- データフィルタリング 。 アプリケーションは、ユーザーの好み、他のユーザーの意見、または製品の類似性のみに基づいて推奨事項を作成しますか?
適時性
最初に決定することは、ユーザーがどれだけ早く推奨事項を受け取るかです。 すぐに、サイトを表示したとき、または後で、メールで? 最初のケースでは、もちろん、分析はより効率的でなければなりません。
- リアルタイム分析には、作成時のデータの処理が含まれます。 このタイプのシステムでは、原則として、イベントフローを処理および分析できるツールが使用されます。 この場合の推奨事項はすぐに作成されます。
- バッチ分析には、定期的なデータ処理が含まれます。 このアプローチは、実際の結果を得るために十分なデータを収集する必要がある場合、たとえば1日あたりの販売量を調べる場合に適しています。 この場合の推奨事項は事後的に開発され、電子メール形式で提供されます。
- ほぼリアルタイムの分析では、数分または数秒ごとに分析データを更新します。 このアプローチにより、1つのユーザーセッション内で推奨事項を提供できます。
任意のカテゴリの適時性を選択できますが、オンライン販売の場合、トラフィックの量と処理されるデータのタイプに応じて、バッチ分析とほぼリアルタイムの分析のクロスが最適です。 分析プラットフォームは、データベースと直接連携することも、永続ストレージに定期的に保存されるダンプと連携することもできます。
データフィルタリング
フィルタリングは、推奨システムの重要なコンポーネントです。 フィルタリングの主なアプローチは次のとおりです。
- 推奨事項が属性、つまりユーザーが表示または評価する商品との類似性によって選択される場合のコンテンツ。
- クラスター、互いにうまく組み合わされた商品が選択されたとき。 ただし、他のユーザーの意見や行動は考慮されません。
- 好みが似ているユーザーが表示または選択する製品が選択された場合の共同作業。
Cloud Platformは3つのタイプすべてをサポートしていますが、このソリューションでは、Apache Sparkに基づく協調フィルタリングアルゴリズムが選択されました。 コンテンツとクラスターフィルタリングの詳細については、 付録を参照してください。
協調フィルタリングにより、製品の属性から抽象化し、ユーザーの好みを考慮した予測を行うことができます。 このアプローチは、同じ製品を好む2人のユーザーの嗜好が同じままであるという前提に基づいています。
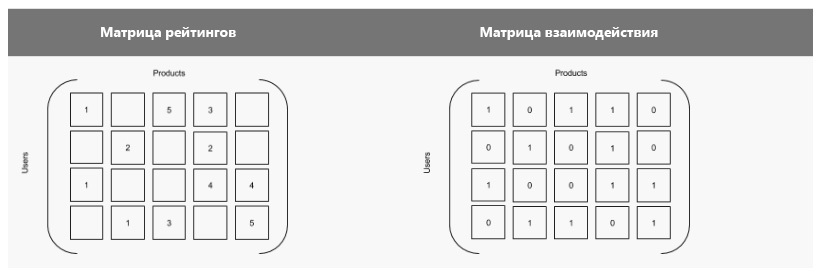
評価とアクションに関するデータはマトリックスのセットとして、製品とユーザーは数量として提示できます。 システムはマトリックス内の欠落セルを埋め、製品に対するユーザーの態度を予測しようとします。 以下は、1つのマトリックスの2つのオプションです。最初のオプションは、既存の推定値を示しています。 2番目では、それらは単一性で示され、欠落した評価はゼロで示されます。 つまり、2番目のオプションは真理値表であり、ユニットはユーザーと製品との対話を示します。
協調フィルタリングでは、主に2つの方法が使用されます。
- anamnestic-システムは製品またはユーザー間の一致を計算します。
- モデル -システムは、ユーザーが製品を評価する方法と実行するアクションを記述するモデルに基づいて動作します。
このソリューションでは、ユーザー評価に基づくモデル手法が使用されます。
このソリューションに必要なすべての分析ツールは、SparkのPythonプログラミングインターフェイスであるPySparkで利用できます。 ScalaとJavaは追加の機会を提供します。 Sparkのドキュメントを参照してください。
モデルトレーニング
Spark MLlibは、ALS(Alternating Least Squares)アルゴリズムを使用してモデルをトレーニングします。 変位と分散の最適な比率を実現するには、次のパラメーターの値を調整する必要があります。
- ランク -ユーザーが評価する際にガイドされた、私たちにとって未知の要因の数。 特に、これには年齢、性別、場所が含まれます。 ある程度、ランクが高いほど、推奨の精度は高くなります。 このパラメーターの最小値は5です。 推奨の品質の差が減少し始めるまで(または十分なメモリとプロセッサの電力が得られるまで)、5ずつ増分します。
- ラムダは、 再トレーニングを回避する正則化パラメーターです。つまり、大きな分散と小さなバイアスのある状況です。 分散は、特定のポイントの理論的に正しい値に関して(数回のパスの後)行われた予測のばらつきです。 オフセット-真の値からの予測の距離。 再トレーニングは、モデルが既知のノイズレベルのトレーニングデータで適切に機能する場合に観察されますが、実際には不十分な結果を示します。 ラムダが大きいほど、再トレーニングは少なくなりますが、バイアスは高くなります。 テストには、0.01、1、および10の値をお勧めします。
この図は、さまざまな分散および変位比を示しています。 ターゲットの中心は、アルゴリズムを使用して予測する値です。

- 反復 -トレーニングパスの数。 この例では、「ランク」パラメーターと「ラムダ」パラメーターのさまざまな組み合わせに対して、5、10、および20回の反復を実行する必要があります。
以下は、SparkでALSトレーニングモデルを実行するサンプルコードです。
from pyspark.mllib.recommendation import ALS model = ALS.train(training, rank = 10, iterations = 5, lambda_=0.01)
モデル選択
ALSアルゴリズムに基づく協調フィルタリングでは、3つのデータセットが使用されます。
- トレーニングセットには、既知の値を持つデータが含まれています。 これが理想的な結果です。 このソリューションでは、このサンプルにはユーザー評価が含まれています。
- テストセットには、パラメーターの最適な組み合わせを取得し、最適なモデルを選択するためにトレーニングセットを調整できるデータが含まれています。
- テストサンプルには、最適なモデルの動作を確認できるデータが含まれています。 これは、実際の分析と同等です。
最適なモデルを選択するには、計算されたモデル、テストサンプル、およびそのサイズを基礎として、二乗平均平方根誤差(RMSE)を計算する必要があります。 RMSEが小さいほど、モデルの精度は高くなります。
勧告の結論
分析結果の出力を高速化するには、それらをデータベースにロードして、オンデマンドでクエリを実行できるようにする必要があります。 これにはCloud SQLが最適です。 Spark 1.4を使用すると、PySparkからデータベースに分析結果を直接書き込むことができます。
推奨表の概要は次のとおりです。
CREATE TABLE Recommendation ( userId varchar(255), accoId varchar(255), prediction float, PRIMARY KEY(userId, accoId), FOREIGN KEY (accoId) REFERENCES Accommodation(id) );
コード分析
次に、トレーニングモデルのコードを検討します。
Cloud SQLからデータを取得する
Spark SQLコンテキストを使用すると、JDBCコネクタを介してCloud SQLインスタンスに簡単に接続できます。 データはDataFrame形式でロードされます。
pyspark / app_collaborative.py
jdbcDriver = 'com.mysql.jdbc.Driver' jdbcUrl = 'jdbc:mysql://%s:3306/%s?user=%s&password=%s' % (CLOUDSQL_INSTANCE_IP, CLOUDSQL_DB_NAME, CLOUDSQL_USER, CLOUDSQL_PWD) dfAccos = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_ITEMS) dfRates = sqlContext.load(source='jdbc', driver=jdbcDriver, url=jdbcUrl, dbtable=TABLE_RATINGS)
DataFrameをRDDに変換し、データセットを作成します
SparkはRDD(Resilient Distributed Dataset)の概念に基づいています。これは、要素を並行して操作できる抽象化です。 RDDは、永続ストレージに基づく読み取り専用のデータコレクションです。 このようなコレクションはメモリ内で分析できるため、反復処理が可能です。
覚えているように、最適なモデルを選択するには、データセットを3つのサンプルに分割する必要があります。 次のコードでは、重複しない値をランダムに60/20/20の割合で分離する補助関数を使用しています。
pyspark / app_collaborative.py
rddTraining, rddValidating, rddTesting = dfRates.rdd.randomSplit([6,2,2])
ご注意 Ratingテーブルの列は、accoId、userId、ratingの順序で配置する必要があります。 これは、ALSアルゴリズムが特定の製品/ユーザーのペアに基づいて予測を行うという事実によるものです。 順序が狂っている場合は、RDDのマップ機能を使用してデータベースを変更するか、列を並べ替えることができます。
トレーニングモデルのパラメーターの選択
すでに述べたように、ALSメソッドでは、最適なモデルを最終的に取得できるように、ランク、正則化、および反復を調整することがタスクです。 システムにはすでにユーザーの評価があるため、トレイン機能の結果をテスト選択と比較する必要があります。 トレーニングサンプルがユーザーの好みを考慮に入れていることを確認する必要があります。
pyspark / find_model_collaborative.py
for cRank, cRegul, cIter in itertools.product(ranks, reguls, iters): model = ALS.train(rddTraining, cRank, cIter, float(cRegul)) dist = howFarAreWe(model, rddValidating, nbValidating) if dist < finalDist: print("Best so far:%f" % dist) finalModel = model finalRank = cRank finalRegul = cRegul finalIter = cIter finalDist = dist
ご注意 howFarAreWe関数は、モデルを使用して、製品/ユーザーのペアのみに基づいてテストセットの推定値を予測します。
pyspark / find_model_collaborative.py
def howFarAreWe(model, against, sizeAgainst): # Ignore the rating column againstNoRatings = against.map(lambda x: (int(x[0]), int(x[1])) ) # Keep the rating to compare against againstWiRatings = against.map(lambda x: ((int(x[0]),int(x[1])), int(x[2])) ) # Make a prediction and map it for later comparison # The map has to be ((user,product), rating) not ((product,user), rating) predictions = model.predictAll(againstNoRatings).map(lambda p: ( (p[0],p[1]), p[2]) ) # Returns the pairs (prediction, rating) predictionsAndRatings = predictions.join(againstWiRatings).values() # Returns the variance return sqrt(predictionsAndRatings.map(lambda s: (s[0] - s[1]) ** 2).reduce(add) / float(sizeAgainst))
ユーザーにとって最も正確な予測の計算
最適なモデルを選択すると、同様の趣味を持つ他のユーザーの好みに基づいて、ユーザーが何に興味を持つかを予測する可能性が非常に高くなります。 以下は、前述のマトリックス図です。
pyspark / app_collaborative.py
# Build our model with the best found values # Rating, Rank, Iteration, Regulation model = ALS.train(rddTraining, BEST_RANK, BEST_ITERATION, BEST_REGULATION) # Calculate all predictions predictions = model.predictAll(pairsPotential).map(lambda p: (str(p[0]), str(p[1]), float(p[2]))) # Take the top 5 ones topPredictions = predictions.takeOrdered(5, key=lambda x: -x[2]) print(topPredictions) schema = StructType([StructField("userId", StringType(), True), StructField("accoId", StringType(), True), StructField("prediction", FloatType(), True)]) dfToSave = sqlContext.createDataFrame(topPredictions, schema) dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
最も正確な予測を保存する
すべての予測のリストを受け取った後、最初の10個の予測をCloud SQLに保存する必要があります。これにより、たとえばサイトに入るときにシステムがユーザーに推奨を発行し始めます
pyspark / app_collaborative.py
dfToSave = sqlContext.createDataFrame(topPredictions, schema) dfToSave.write.jdbc(url=jdbcUrl, table=TABLE_RECOMMENDATIONS, mode='overwrite')
ソリューションの発売
個々のユーザー向けの推奨事項を開発および表示できるソリューションを起動するための段階的な手順は、 GitHubで入手できます 。
SQLクエリコードの最後のフラグメントは、データベースから最も関連性の高い推奨事項を受け取り、Annaの開始ページに表示します。
Cloud PlatformコンソールまたはMySQLクライアントでこのクエリを実行した結果の例:

このクエリの結果をサイトのスタートページに追加して、ユーザーの関心を高め、コンバージョンレベルを高めることができます。
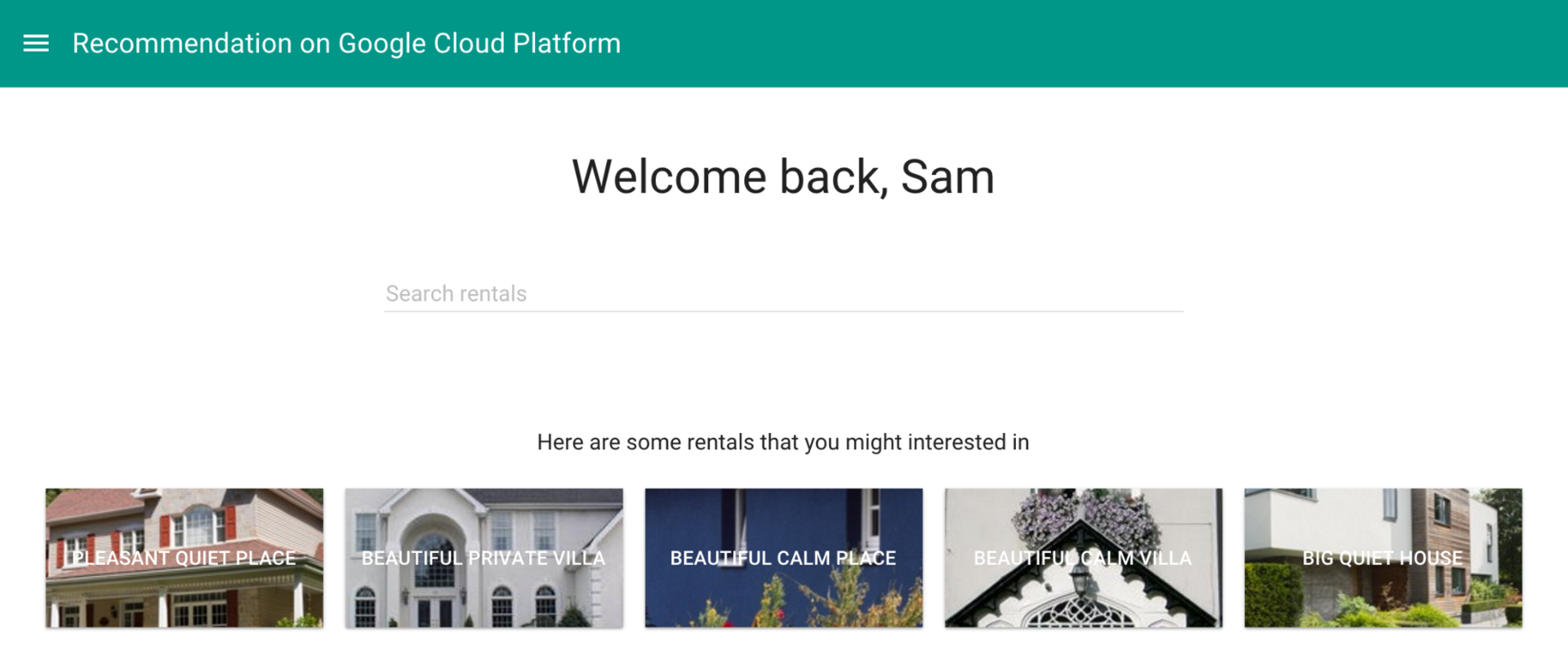
アンナに関する利用可能な情報が記述されたシナリオに基づいて、システムはアンナに興味がある提案を選択しました。
タスク監視
bdutil構成での監視
以前にSSH経由で親インスタンスに接続しました。 Sparkには、Webインターフェースを介して進行中のタスクを監視できる管理コンソールがあります。
デフォルトでは、ポート8080からコンソールにアクセスできます。インスタンスごとにこのポートへのアクセスを開く必要があります。 ファイアウォールルールを追加する手順については、 こちらをご覧ください 。 コンソールを開くには、ブラウザのアドレスバーにインスタンスの外部IPアドレスを入力します (たとえば、 1.2.3.4 :8080)。 下のスクリーンショットのSparkコンソールには、作業ノード、実行中のアプリケーション、完了したアプリケーションに関する情報を含む3つのセクションがあります。

Sparkコンソール
Cloud Dataprocでの監視
出力とWebインターフェースの詳細については、Cloud Dataprocのドキュメントを参照してください。
ガイド
セットアップ手順とサンプルソースコードを含む完全なガイドは、GitHubで入手できます 。
アプリ
クロスフィルタリング
上記の例から、協調フィルタリングに基づいて推奨事項を選択するための効果的でスケーラブルなソリューションを作成する方法を学びました。 推奨事項をさらに正確にするために、他の方法を使用して結果をフィルタリングできます。 これは、コンテンツフィルタリングとクラスターフィルタリングの2つの主要なフィルタリングタイプになります。 これらのアプローチの組み合わせにより、ユーザーはより良い推奨事項を提供できます。
コンテンツフィルタリング
このタイプのフィルタリングにより、属性と少数のユーザー評価を持つオブジェクトの推奨事項を選択できます。 オブジェクトの類似性は、その属性に基づいて決定されます。 ユーザーベースが大きい場合でも、処理される属性の数は許容レベルのままです。
コンテンツフィルタリングを追加するには、ディレクトリ内のオブジェクトに対して他のユーザーが設定した既存の評価を使用できます。 これらの評価に基づいて、ユーザーが表示している製品に最も近い製品が選択されます。
原則として、2つの製品の類似性を決定するために、Otiai係数が最初に計算され、次に最も近いものが検索されます。


結果は0〜1の範囲の数値になります。1に近いほど、商品の類似性は高くなります。

次のマトリックスを検討してください。

P1とP2の類似性は、次の式を使用して計算されます。
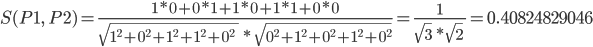
コンテンツフィルタリングシステムは、さまざまなツールを使用して作成できます。 以下に2つの例を示します。
- ペアワイズ類似法を使用して、Twitterで推奨事項を選択します 。 MLlibに追加されたScala CosineSimilarities機能は、Spark環境で実行できます。
- Mahoutライブラリー 。 MLlibアルゴリズムの1つを置換または拡張するには、bdutil構成にMahoutをインストールします。 現在の構成にMahoutを追加するには、GitHubプロジェクトのクローンを作成します。
git clone https://github.com/apache/mahout.git mahout export MAHOUT_HOME=/path/to/mahout export MAHOUT_LOCAL=false #For cluster operation export SPARK_HOME=/path/to/spark export MASTER=spark://hadoop-m:7077 #Found in Spark console
ご注意 Mahoutライブラリを使用するには、Mavenが必要です。
クラスタリング
検索コンテキストを理解し、ユーザーが表示している製品を特定することが重要です。 異なる状況では、同じ人が完全に異なる製品を探すことができますが、必ずしも自分ではありません。 そのため、ユーザーが表示している製品と似ている製品を知る必要があります。 k-meansクラスタリングを使用する場合、システムは、主要な属性に基づいて類似のオブジェクトをセグメントに結合します。
現在、ロンドンで家を探しているユーザーは、オークランドの住宅に興味を持つ可能性が低いため、この例では、システムはそのようなオファーを除外する必要があります。
from pyspark.mllib.clustering import KMeans, KMeansModel clusters = KMeans.train(parsedData, 2, maxIterations=10, runs=10, initializationMode="random")
結果を改善するには?
推奨事項をさらに正確にするために、分析では、注文の履歴やサポート要求、人口統計情報(年齢、場所、性別など)などの追加要因を考慮することができます。 多くの場合、このデータは顧客関係管理(CRM)またはビジネスリソースプランニング(ERP)システムに既に保存されています。
また、外部要因がユーザーの決定に影響を与える可能性があることに注意する必要があります。 レクリエーションの場所を選択するとき、多くの顧客、特に小さな子供を持つ家族は、生態学的に清潔な地域を探しています。 この例では、 BreezometerなどのサードパーティAPIをCloud Platformベースの推奨システムに統合すると、競争上の優位性をさらに得ることができます。
Softline-Google Cloud Premierパートナー
Softlineは、ロシアおよびCIS諸国で最大の企業サービスプロバイダーであり、GoogleおよびGoogle Cloud Premierパートナーのステータスを持つ唯一のパートナーです。 同社は長年にわたり、エンタープライズセグメントの年間最優秀パートナー、SMBセグメントのEMEA地域の年間最優秀パートナーとして認められました。

|