多くのコアはありません
アトミック操作 (アトミック)、たとえば、 コンペアアンドスワップ (CAS)やフェッチアンドアド (FAA)は、並列プログラミングで広く普及しています。
マルチコアまたはマルチコアアーキテクチャは、デスクトップコンピューター製品とサーバーコンピューター製品の両方、および大規模なデータセンターとスーパーコンピューターに同じようにインストールされます。 設計の例には、Tianhe-2にインストールされたチップに61コアのIntel Xeon Phi、またはCray XE6に展開されたノードあたり32コアのAMD Bulldozerが含まれます。 さらに、チップ上のコアの数は着実に増加しており、数百のコアを持つプロセッサが近い将来に製造されると予測されています。 これらすべてのアーキテクチャの共通機能は、メモリサブシステムの複雑さの増大です。これは、異なる包含ポリシー、異なるキャッシュコヒーレンスプロトコル、およびコアとキャッシュメモリを接続するチップ上のさまざまなネットワークトポロジを備えた複数レベルのキャッシュメモリによって特徴付けられます。
これらのアーキテクチャのほとんどすべてが、並列コードで多数の用途を持つアトミック操作を提供します。 それらの多く( Test-and-Setなど )を使用して、ロックおよびその他の同期メカニズムを実装できます。 Fetch-and-AddやCompare-and-Swapなどの他の機能を使用すると、コードベースのロックよりも強力な進捗保証が可能な、さまざまなロックフリーおよび待機フリーのアルゴリズムとデータ構造を構築できます。 その重要性と広範な使用にもかかわらず、原子操作の実装はこれまで完全には分析されていません。 たとえば、 Compare-and-SwapはFetch-and-Addよりも遅いことが一般的に同意されています。 ただし、これは、 Compare-and-Swapのセマンティクスが「無駄な作業」の概念を導入し、一部のコードのパフォーマンスが低下することを示しているだけです。
比較と交換
CASを思い出してください(Intelプロセッサではcmpxchgコマンドのグループによって実行されます)-CAS操作には、メモリアドレス( V )、予想される古い値( A )、新しい値( B )の3つのオペランドオブジェクトが含まれます。 メモリセルの値が古い期待値( A )と一致する場合、プロセッサはセルのアドレス( V )を原子的に更新します。そうでない場合、変更はコミットされません。 いずれの場合でも、要求時間より前の値が表示されます。 CASメソッドのいくつかのバリエーションは、現在の値自体を表示するのではなく、単に操作が成功したかどうかを示します。 実際、CASは「アドレスVの値はおそらくAです。 その場合は、 Bを同じ場所に配置し、そうでない場合は実行しないでください。ただし、現在の値がどの値であるかを必ず確認してください。
同期にCASを使用する最も自然な方法は、 Aの値をアドレスVの値で読み取り、マルチステップ計算を実行してBの新しい値を取得し、CASメソッドを使用してパラメーターVの値を前の値Aから新しい値Bに置き換えることです この時間中にVが変化しなかった場合、CASはタスクを完了します。 実際、JDK 7で観察されること:
public final int incrementAndGet() { for (;;) { int current = get(); int next = current + 1; if (compareAndSet(current, next)) return next; } } public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); }
メソッド自体-unsafe.compareAndSwapIntはネイティブであり、プロセッサー上でアトミックに実行され、 アセンブラーコードの印刷を有効にすると、アセンブラーは次のようになります。
lock cmpxchg [esi+0xC], ecx
命令は次のように実行されます。第1オペランドで示されたメモリ領域から値が読み取られ、読み取り後のバスロックは解除されません。 次に、メモリアドレスの値が期待される古い値が格納されているeaxレジスタと比較され、等しい場合、プロセッサは第2オペランド(ecxレジスタ)の値を第1オペランドで示されるメモリ領域に書き込みます。 録音が完了すると、バスロックが解除されます。 x86の特徴は、いずれの場合でも書き込みが発生することです。ただし、値が等しくない場合、同じメモリ領域からの読み取り中に取得された値がメモリ領域に入力されるというわずかな例外があります。
したがって、変数をチェックするループで作業を行いますが、これは失敗する可能性があり、チェックを新たに開始する前にすべてループで動作します。
取得と追加
Fetch-and-Addはより簡単に機能し、ループは含まれません(Intelアーキテクチャでは、xaddコマンドグループによって実装されます)。 また、メモリアドレス( V )と値( S )の2つのオペランドオブジェクトが含まれます。これにより、メモリアドレス( V )に格納されている古い値を増やす必要があります。 したがって、FAAは次のように説明できます。指定されたアドレス( V )にある値を取得し、一時的に保存します。 次に、指定されたアドレス( V )に、2オペランドオブジェクト( S )である値だけ増加した、以前に格納された値を入力します。 さらに、上記の操作はすべてアトミックに実行され、ハードウェアレベルで実装されます。
JDK 8では、コードは次のようになります。
public final int incrementAndGet() { return unsafe.getAndAddInt(this, valueOffset, 1) + 1; } public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
「Noo」と言います、「この実装はバージョン7とどう違うのですか?」
ここでは、サイクルはほぼ同じで、すべてが同様の方法で行われます。 ただし、Javaで表示および記述されたコードは、最終的にプロセッサーで実行されません。 ループに関連付けられ、新しい値を設定するコードは、最終的に1つのアセンブラー操作に置き換えられます。
lock xadd [esi+0xC], eax
それぞれ、eaxレジスタには、アドレス[esi + 0xC]に格納されている古い値を増やす必要がある値が格納されます。 繰り返しますが、すべてがアトミックです。 ただし、バージョン8のJDKを使用している場合、このトリックは機能します。そうでない場合、通常のCASが実行されます。
他に何を追加したいですか...
ここで、MESIプロトコルがここで言及されていることに注意してください。これは、非常に優れた一連の記事で読むことができます: ロックフリーデータ構造。 基本:記憶の壁はどこから来たのですか?
英語からの翻訳を明確にしてくれたkmu1990に感謝します。
- CASは「楽観的な」アルゴリズムであり、操作の失敗を許可しますが、FAAは許可しません。 FAAには、リモートの介入による脆弱性の形での明確な抜け穴がないため、ループを再試行する必要はありません。
- システムがsnoop-baseまたは「盗聴」によるコヒーレンスの最も一般的な実装を使用していると仮定して、標準のCASアプローチを使用する場合、これによりread-to-shareトランザクションがメインキャッシュラインまたは状態Eを取得できます。実際、キャッシュラインをM(変更済み)状態にします。これには、追加のトランザクションが必要になる場合があります。 したがって、最悪の場合、標準のCASアプローチではバスを2つのトランザクションにさらすことができますが、Fetch-And-Addの実装では、ラインを直接M状態に転送しようとします。 このプロセスでは、ベアCASを取得しようとするため、値を推測し、プリロードせずに短いパスを取得できます。 さらに、これは、M状態で調整された操作とターゲットライン調査を実行するための複雑なプロセッサ実装で可能です。 最後に、場合によっては、更新トランザクションを回避するために、操作を実行する前に、プリフェッチ書き込み(PREFETCHW)ステートメントを正常に挿入できます。 ただし、このアプローチは、場合によっては害よりも害を及ぼす可能性があるため、特に注意して適用する必要があります。 これらすべてを考慮すると、FAAには可能な限り利点があります。 言い換えると(jcmvbkbcへのヒントのおかげです)-CASを作成するために、メモリから古い値をロードする必要があります。これにより、2つのメモリアクセスが与えられ、xaddを作成するために古い値をロードする必要はなく、1つのメモリアクセスのみが必要です。
- CASループを使用して変数をインクリメント(たとえばインクリメント)しようとしているとします。 CASが頻繁にオフになり始めると、ループを終了する分岐(通常、不在または軽負荷で発生する)が、ループに留まることを予測する誤ったパスを予測し始めることがあります。 したがって、CASが最終的に目標に到達すると、ループを終了しようとしたときに分岐の予測ミスをキャッチします。 これは、ディープパイプラインプロセッサでは苦痛を伴い、大量の異常な(異常な実行)マシン仕様につながる可能性があります。 通常、このコードが速度の低下を引き起こすことは望ましくありません。 上記に関連して、CASが頻繁に失敗し始めると、分岐が制御がループ内に留まることを予測し始め、予測の成功によりループが高速に実行されます。 原則として、ループのバックオフが必要です。 また、軽度の障害でまれな障害が発生した場合、ブランチの予測ミスは潜在的な暗黙のバックオフとして機能します。 しかし、負荷が高くなると、分岐の予測ミスから生じるバックオフの利点が失われます。 FAAにはサイクルも問題もありません。
テスト
そして最後に、JDK 7および8のアトミックインクリメントの動作を示す簡単なテストを作成しました。
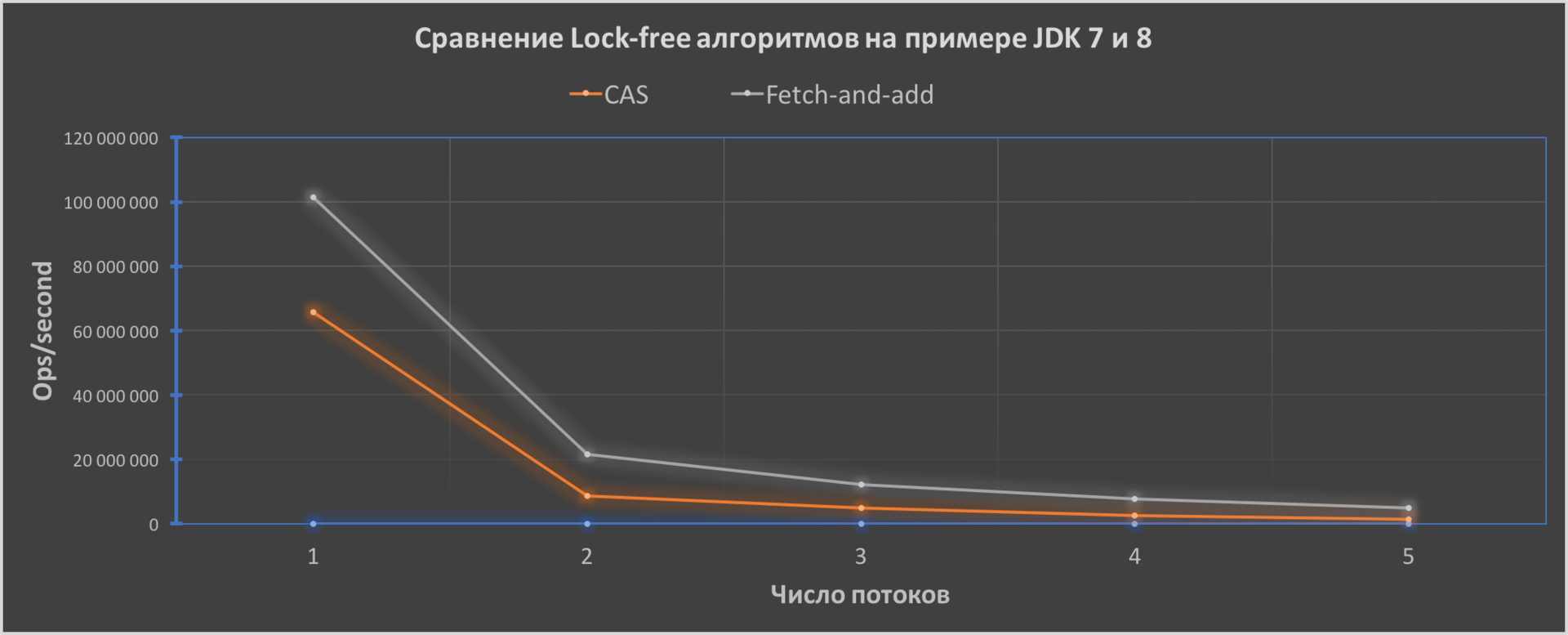
ご覧のように、FAAのコードパフォーマンスは向上し、スレッド数が1.6倍から約3.4倍になると効率が向上します。

テスト用のJavaバージョン:Oracle JDK7u80およびJDK8u111-64ビットサーバーVM。 CPU-Intel Core i5-5250U世代Broadwell、OS-macOS Sierra 10.12.2、RAM-8-Gb
興味深いことに、テストコードへのリンクはテストのソースコードです 。
コメント、改善などを待っています。