
それはすべて、ビットコインをよりよく知ることを決めたという事実から始まりました。 それらがどのように採掘されたかを理解したかった。 最近、ビットコインとブロックチェーンに関する記事が頻繁に見つかりましたが、技術的な詳細がすべて記載された記事はあまり多くありません。
すべての詳細を把握する最も簡単な方法は、オープンソースを調べることです。 FPGAマイナーの Verilogソースコードを調査することにしました。 これはそのようなプロジェクトだけではありません。githubにはさらにいくつかの例があり、それらはすべて異なる作者のものですが、ほぼ同じスキームに従って機能しているようです。 作者が最初にすべてを持っている可能性があります。異なるチップと異なるボードに同じコードを適応させる開発者が異なるだけです...少なくとも私には思えました...
Verilogのソースコードを研究した私は、5万個のロジック要素を備えたAltera MAX10 FPGAに基づいて、githubからMars rover3ボードにプロジェクトを適合させました。 私は鉱山労働者を立ち上げ、ビットコインの計算プロセスを開始することさえできましたが、無駄のため30分後にこのビジネスを終了しました。 現在のところ、FPGAマイナーは動作しています。 まあ、それをさせてください。
正直なところ、ビットコイン自体(これら、これらのお金の代用物)には興味がありませんでしたが、SHA256アルゴリズムの数学的な側面に興味がありました。 それが私が話したいことです。 SHA256アルゴリズムを使用していくつかの実験を実施しましたが、これらの実験の結果は興味深いものになるでしょう。
実験のために最初に必要なことは、Verilogで「クリーンな」SHA256実装を作成することでした。
実際、少なくとも同じopencores.org上、少なくともgithub.com上で、VerilogにSHA256アルゴリズムの実装が多数あります。 ただし、このような実装は実験には適していません。 既存のモジュールには、常にパイプライン構造、パイプラインがあります。 これは正しいようです。 パイプラインがある場合のみ、高速アルゴリズムを取得できます。 SHA256アルゴリズムは、64の処理ステップ、いわゆる「ラウンド」で構成されています。 FPGAのボリュームが許せば、64ラウンドすべてを単一の操作チェーンに展開できます。計算のすべての段階は、動作周波数の1クロックサイクルで並行して実行されます。 このようなもの:

アルゴリズムの入力で、SHA256マシンの8つの32ビット状態ワード。 これらはレジスタA、B、C、D、E、F、G、Hです。入力データ自体、512ビットはW係数に変換され、各ラウンドで混合されます。 新しい単語データは最初のラウンドのレジスタにロードされますが、2番目のラウンドは前のメジャーにロードされたデータの読み取りを続け、3番目のラウンドは前のメジャーにロードされたデータの読み取りを続けます。 結果のレイテンシ、つまり計算結果の遅延は正確に64サイクルになりますが、一般に、パイプラインを使用するとアルゴリズム全体を1サイクルで読み取ることができます。 FPGAのボリュームが小さく、ラウンドチェーン全体を拡張できない場合、半分になります。 そのため、プロジェクトを既存のFPGAに適合させることができますが、計算速度も当然半分になります。 さらに容量の少ないFPGAを使用してそこに合わせることができますが、パイプラインを短くする必要があり、生産性が再び低下します。 私が理解しているように、2回連続のSHA256変換を行うBitcoinマイナー全体では、アルテラ/ Intel FPGAに約8万のロジックエレメントが必要です。 しかし、私は気を取られました...
だから、私は完全にばかげたことをしたい-中間レジスタなしでSHA256アルゴリズムの「純粋な」関数をVerilogに書いて、パイプラインなしでそれを残す。 この奇妙なアクションの目標は単純です-SHA256アルゴリズムの計算に必要な実際のロジック量を決定することです。 512ビットのデータ(まあ、256ビットの初期状態)を供給する単純な組み合わせ回路が必要で、256ビットの結果を生成します。
私はこのVerilogモジュールを書きました。自分で何かを書いたどこかで、他のオープンソースから何かを借りました。 私のプロジェクトはsha256-testです。
これは、単一の中間レジスタではなく、純粋なラマンSHA256です。
module e0 (x, y); input [31:0] x; output [31:0] y; assign y = {x[1:0],x[31:2]} ^ {x[12:0],x[31:13]} ^ {x[21:0],x[31:22]}; endmodule module e1 (x, y); input [31:0] x; output [31:0] y; assign y = {x[5:0],x[31:6]} ^ {x[10:0],x[31:11]} ^ {x[24:0],x[31:25]}; endmodule module ch (x, y, z, o); input [31:0] x, y, z; output [31:0] o; assign o = z ^ (x & (y ^ z)); endmodule module maj (x, y, z, o); input [31:0] x, y, z; output [31:0] o; assign o = (x & y) | (z & (x | y)); endmodule module s0 (x, y); input [31:0] x; output [31:0] y; assign y[31:29] = x[6:4] ^ x[17:15]; assign y[28:0] = {x[3:0], x[31:7]} ^ {x[14:0],x[31:18]} ^ x[31:3]; endmodule module s1 (x, y); input [31:0] x; output [31:0] y; assign y[31:22] = x[16:7] ^ x[18:9]; assign y[21:0] = {x[6:0],x[31:17]} ^ {x[8:0],x[31:19]} ^ x[31:10]; endmodule module round (idx, in, k, w, out); input [7:0]idx; input [255:0]in; input [ 31:0]k; input [ 31:0]w; output [255:0]out; always @(w) $display("i=%dk=%8x w=%8x",idx,k,w); wire [31:0]a; assign a = in[ 31: 0]; wire [31:0]b; assign b = in[ 63: 32]; wire [31:0]c; assign c = in[ 95: 64]; wire [31:0]d; assign d = in[127: 96]; wire [31:0]e; assign e = in[159:128]; wire [31:0]f; assign f = in[191:160]; wire [31:0]g; assign g = in[223:192]; wire [31:0]h; assign h = in[255:224]; wire [31:0]e0_w; e0 e0_(a,e0_w); wire [31:0]e1_w; e1 e1_(e,e1_w); wire [31:0]ch_w; ch ch_(e,f,g,ch_w); wire [31:0]mj_w; maj maj_(a,b,c,mj_w); wire [31:0]t1; assign t1 = h+w+k+ch_w+e1_w; wire [31:0]t2; assign t2 = mj_w+e0_w; wire [31:0]a_; assign a_ = t1+t2; wire [31:0]d_; assign d_ = d+t1; assign out = { g,f,e,d_,c,b,a,a_ }; endmodule module sha256_transform( input wire [255:0]state_in, input wire [511:0]data_in, output wire [255:0]state_out ); localparam Ks = { 32'h428a2f98, 32'h71374491, 32'hb5c0fbcf, 32'he9b5dba5, 32'h3956c25b, 32'h59f111f1, 32'h923f82a4, 32'hab1c5ed5, 32'hd807aa98, 32'h12835b01, 32'h243185be, 32'h550c7dc3, 32'h72be5d74, 32'h80deb1fe, 32'h9bdc06a7, 32'hc19bf174, 32'he49b69c1, 32'hefbe4786, 32'h0fc19dc6, 32'h240ca1cc, 32'h2de92c6f, 32'h4a7484aa, 32'h5cb0a9dc, 32'h76f988da, 32'h983e5152, 32'ha831c66d, 32'hb00327c8, 32'hbf597fc7, 32'hc6e00bf3, 32'hd5a79147, 32'h06ca6351, 32'h14292967, 32'h27b70a85, 32'h2e1b2138, 32'h4d2c6dfc, 32'h53380d13, 32'h650a7354, 32'h766a0abb, 32'h81c2c92e, 32'h92722c85, 32'ha2bfe8a1, 32'ha81a664b, 32'hc24b8b70, 32'hc76c51a3, 32'hd192e819, 32'hd6990624, 32'hf40e3585, 32'h106aa070, 32'h19a4c116, 32'h1e376c08, 32'h2748774c, 32'h34b0bcb5, 32'h391c0cb3, 32'h4ed8aa4a, 32'h5b9cca4f, 32'h682e6ff3, 32'h748f82ee, 32'h78a5636f, 32'h84c87814, 32'h8cc70208, 32'h90befffa, 32'ha4506ceb, 32'hbef9a3f7, 32'hc67178f2}; genvar i; generate for(i=0; i<64; i=i+1) begin : RND wire [255:0] state; wire [31:0]W; if(i<16) begin assign W = data_in[i*32+31:i*32]; end else begin wire [31:0]s0_w; s0 so_(RND[i-15].W,s0_w); wire [31:0]s1_w; s1 s1_(RND[i-2].W,s1_w); assign W = s1_w + RND[i - 7].W + s0_w + RND[i - 16].W; end if(i == 0) round R ( .idx(i[7:0]), .in(state_in), .k( Ks[32*(63-i)+31:32*(63-i)] ), .w(W), .out(state) ); else round R ( .idx(i[7:0]), .in(RND[i-1].state), .k( Ks[32*(63-i)+31:32*(63-i)] ), .w(W), .out(state) ); end endgenerate wire [31:0]a; assign a = state_in[ 31: 0]; wire [31:0]b; assign b = state_in[ 63: 32]; wire [31:0]c; assign c = state_in[ 95: 64]; wire [31:0]d; assign d = state_in[127: 96]; wire [31:0]e; assign e = state_in[159:128]; wire [31:0]f; assign f = state_in[191:160]; wire [31:0]g; assign g = state_in[223:192]; wire [31:0]h; assign h = state_in[255:224]; wire [31:0]a1; assign a1 = RND[63].state[ 31: 0]; wire [31:0]b1; assign b1 = RND[63].state[ 63: 32]; wire [31:0]c1; assign c1 = RND[63].state[ 95: 64]; wire [31:0]d1; assign d1 = RND[63].state[127: 96]; wire [31:0]e1; assign e1 = RND[63].state[159:128]; wire [31:0]f1; assign f1 = RND[63].state[191:160]; wire [31:0]g1; assign g1 = RND[63].state[223:192]; wire [31:0]h1; assign h1 = RND[63].state[255:224]; wire [31:0]a2; assign a2 = a+a1; wire [31:0]b2; assign b2 = b+b1; wire [31:0]c2; assign c2 = c+c1; wire [31:0]d2; assign d2 = d+d1; wire [31:0]e2; assign e2 = e+e1; wire [31:0]f2; assign f2 = f+f1; wire [31:0]g2; assign g2 = g+g1; wire [31:0]h2; assign h2 = h+h1; assign state_out = {h2,g2,f2,e2,d2,c2,b2,a2}; endmodule
当然、モジュールが機能していることを確認する必要があります。 これを行うには、いくつかのデータブロックを入力に送信して結果を確認する簡単なテストベンチが必要です。
これがテストベンチVerilogです
`timescale 1ns/1ps module tb; initial begin $dumpfile("tb.vcd"); $dumpvars(0, tb); #100; $finish; end wire [511:0]data; assign data = 512'h66656463626139383736353433323130666564636261393837363534333231306665646362613938373635343332313066656463626139383736353433323130; wire [255:0]result; sha256_transform s( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in(data), .state_out(result) ); endmodule
Cで記述されたsha256_transform関数によって与えられた答えと比較します(Cでコードを提供できませんか?C / C ++でのこれらの実装は完全に完了しています)。 主な結果:
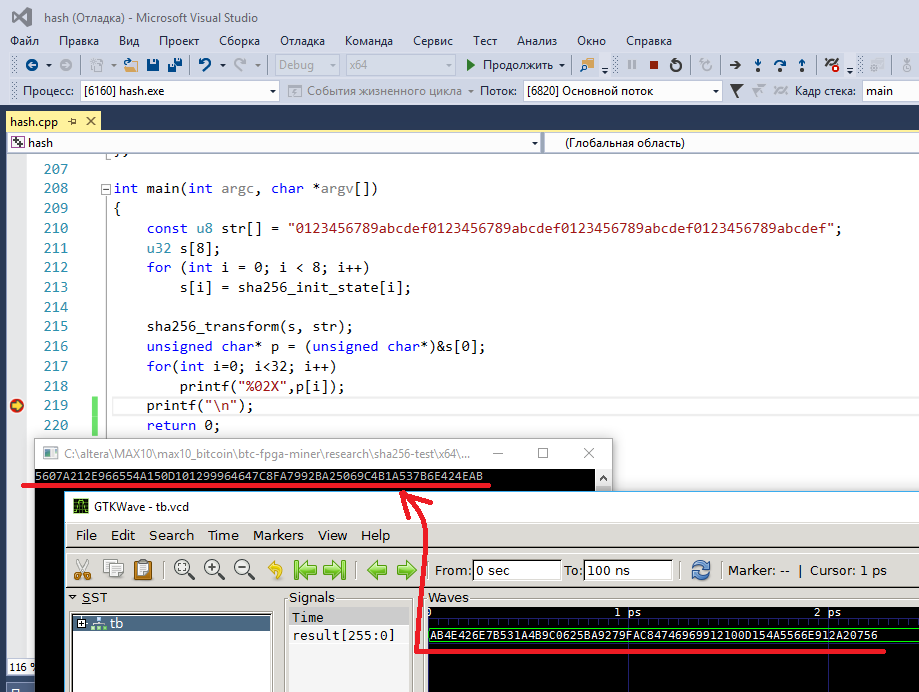
Visual Studio環境でC / C ++でプログラムし、icarus verilogとgtkwaveでVerilogプログラムをテストします。 私は答えが一致すると確信したので、先に進むことができます。
これで、モジュールをFPGAに挿入し、そのような関数が占有できる論理要素の数を確認できます。
FPGAのようなプロジェクトを作成します。
module sha256_test( input wire clk, input wire data, output wire [255:0]result ); reg [511:0]d; always @(posedge clk) d <= { d[510:0],data }; sha256_transform s0( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in( d ), .state_out(result) ); endmodule
ここでは、入力データが512ビットの1つの長いレジスタにプッシュされ、「クリーンな」SHA256_transformへの入力として供給されると想定しています。 256個の出力ビットはすべて、FPGAの出力ピンに出力されます。
FPGA Cyclone IV用にコンパイルしていますが、この処理には30.103の論理要素が必要になることがわかります。
この番号を覚えておいてください: 30103 ...
2番目の実験を行いましょう。 プロジェクトは「sha256-eliminated」です。
module sha256_test( input wire clk, input wire data, output wire [255:0]result ); sha256_transform s0( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in( 512'h66656463626139383736353433323130666564636261393837363534333231306665646362613938373635343332313066656463626139383736353433323130 ), .state_out(result) ); endmodule
ここでは、外部から入力データをFPGAに送信するのではなく、sha256_transformモジュールの定数、一定の入力信号で単純に設定します。
FPGAでコンパイルします。 この場合、 ZEROに関係する論理要素の数がわかります。
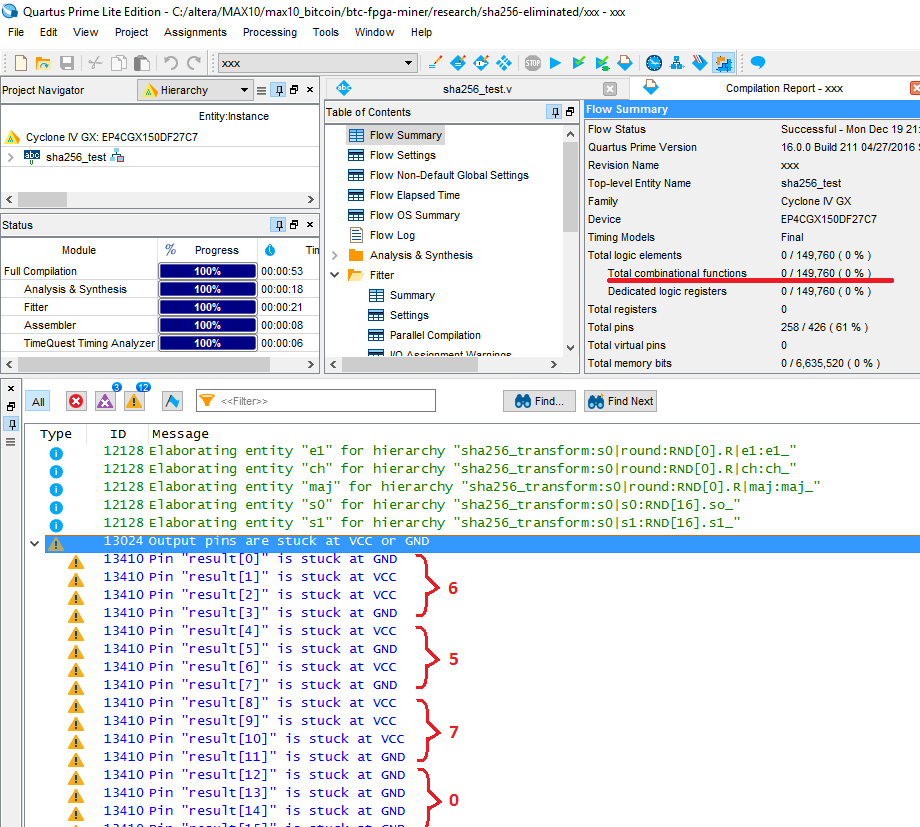
アルテラ(またはIntelですか?正しいと呼ぶべきですか?)Quartus Primeはデバイスのロジック全体を最適化し、レジスタがなく、結果が依存する入力信号がないため、SHA256モジュールの入力パラメーターから組み合わせ関数全体が縮退し、答えが計算されますコンパイル。 FPGAピンで出力信号を確認できます。 コンパイラはすぐに、一部の信号がグランドに、一部がVCCに供給電圧に結合されることを書き込みます。 したがって、コンパイラーによって計算された出力は、出力に表示されます:0x56、0x70、...最初のテストケースとまったく同じです。
したがって、そのような考えが生じます。 コンパイラーは非常に賢く、ロジックを非常にうまく最適化できるため、sha256からの出力ビットを1つだけ考慮しないのはなぜですか? 結果のビットを1つだけカウントするには、どのくらいのロジックが必要ですか?
実際に。 ビットコインは次のように考慮されます:データブロックがあります。 データブロックには変更可能な可変フィールドがあります。これは32ビットのナンスフィールドです。 ブロック内の残りのデータは修正されています。 sha256の結果が「特別」になるように、つまり、sha256変換結果の上位ビットがゼロになるように、ノンスフィールドを反復処理する必要があります。
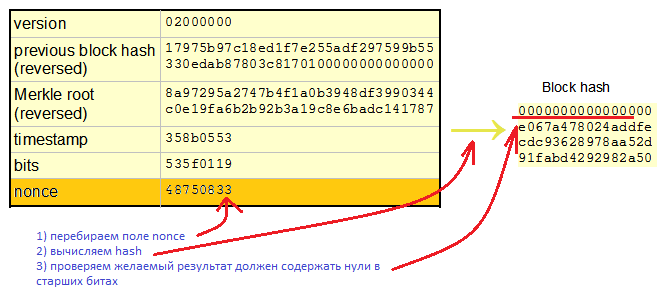
ここでは、sha256を1回考慮し、ノンスを1つ増やします。再びハッシュを取得し、何度も繰り返します。 何百、何千回も同じデータブロックですが、わずかに異なるノンスフィールド。 この場合、sha256の結果のすべてのビットが計算されます。つまり、すべての出力ビットは256ビットです。 それはエネルギー的に有益ですか? これは、関与する論理要素の数の点で有益ですか?
しかし、結果の最上位ビットの1つだけを数えるとどうなるでしょう。 彼は、ゼロまたは1のいずれかである可能性が等しいと考えています。 1であることが判明した場合、残りのビットをカウントする必要はありません。 貴重なエネルギーを無駄遣いするのはなぜですか?
この仮定を行ったので、何らかの理由で、1つのハッシュビットのみを計算するための論理要素の数は、結果のすべてのビットを計算する場合の256倍にすべきだとすぐに思いました。 しかし、私は間違っていました。
この仮説をテストするために、次のような最上位モジュールを使用して、四分位のプロジェクトを作成することにしました。
module sha256_test( input wire clk, input wire data, output wire result ); reg [511:0]d; always @(posedge clk) d <= { d[510:0],data }; wire [255:0]r; sha256_transform s0( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in( d ), .state_out(r) ); assign result = r[187]; // , endmodule
sta256_transformはハッシュ全体を計算し、答えは信号線[255:0] rにあるように見えますが、Verilogモジュールの出力は1ビットのみであり、結果= r [187]が割り当てられます。 これにより、コンパイラは目的のビットを計算するために必要なロジックのみを効果的に残すことができます。 残りは最適化され、プロジェクトから削除されます。
実験を行うには、最後から2番目の行を修正し、プロジェクトを256回再コンパイルするだけです。 この作業を容易にするために、quartusのスクリプトを作成します。
#!/usr/bin/tclsh proc read_rpt { i frpt } { set fp [open "output_files/xxx.map.summary" r] set file_data [read $fp] close $fp set data [split $file_data "\n"] foreach line $data { set half [split $line ":"] set a [lindex $half 0] set b [lindex $half 1] if { $a == " Total combinational functions " } { puts [format "%d %s" $i $b] puts $frpt [format "%d %s" $i $b] } } } proc gen_sha256_src { i } { set fo [open "sha256_test.v" "w"] puts $fo "module sha256_test(" puts $fo " input wire clk," puts $fo " input wire data," puts $fo " output wire result" puts $fo ");" puts $fo "" puts $fo "reg \[511:0]d;" puts $fo "always @(posedge clk)" puts $fo " d <= { d\[510:0],data };" puts $fo "" puts $fo "wire \[255:0]r;" puts $fo "sha256_transform s0(" puts $fo " .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 )," puts $fo " .data_in( d )," puts $fo " .state_out(r)" puts $fo " );" puts $fo "" puts $fo "assign result = r\[$i];" puts $fo "" puts $fo "endmodule" close $fo } set frpt [open "rpt.txt" "w"] for {set i 0} {$i < 256} {incr i} { gen_sha256_src $i exec x.bat read_rpt $i $frpt } close $frpt exit
このスクリプトは、ループ内でsha256_test.vモジュールを再作成し、sha256の結果の次のビットをFPGA出力ピンに出力するたびに再作成します。
スクリプトを数時間実行すると、出来上がりです。 値の表があります。 これで、SHA256のどのビットが最も計算しやすいかが確実にわかりました。 計算されたSHA256ビットのシリアル番号に対するロジックエレメントの必要数のグラフは次のとおりです。

これから、ビット番号224を計算するのが最も簡単であることが明らかになります。27,204個の論理要素が必要です 。 これは実際には、256個の出力ビットすべてを計算する場合よりもほぼ10%少なくなります。
鋸の形のグラフは、SHA256アルゴリズムには多くの加算器があるという事実によって説明されます。 加算器では、次の各上位ビットは、前の下位ビットよりも計算が困難です。 これは、加算器が多くの全加算器ブロックで構成されるため、転送スキームが原因です。
幽霊のようなエネルギー節約はすでに現れています。 私はすべての論理機能がエネルギーを食べると信じています。 FPGAプロジェクトに含まれるLEゲートの数が少ないほど、エネルギー消費が少なくなります。 提案されるアルゴリズムは次のとおりです。1つの最も単純なビットを検討し、ゼロの場合は次を検討します。 1つであれば、同じハッシュの残りのビットにエネルギーと時間とエネルギーを無駄にしません。
ロジックを最適化するコンパイラの機能に関連する別の考え。
ノンスフィールドを列挙するとき、ブロックのメインデータは同じままであるため、サイクルごとに、一部の計算が単純に繰り返され、同じことを考慮することは論理的で明白です。 質問:繰り返し計算で失われるエネルギー量を推定する方法は?
実験は簡単です。 たとえば、2つのsha256_transformモジュールを並べて配置し、1ビットを除き、同じ入力を適切に供給します。 これらの2つのモジュールは、隣接するノンスが1ビット異なることを考慮していると考えています。
module sha256_test( input wire clk, input wire data, output wire [1:0]result ); reg [511:0]d; always @(posedge clk) d <= { d[510:0],data }; wire [255:0]r0; sha256_transform s0( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in( { 1'b0, d[510:0] } ), .state_out(r0) ); wire [255:0]r1; sha256_transform s1( .state_in( 256'h5be0cd191f83d9ab9b05688c510e527fa54ff53a3c6ef372bb67ae856a09e667 ), .data_in( { 1'b1, d[510:0] } ), .state_out(r1) ); assign result = { r0[224], r1[224] }; endmodule
モジュールs0とs1のそれぞれは、同じ入力からのハッシュを考慮し、1つのnonceだけが異なります。 それぞれから、結果の「最も軽い」ビット、ビット番号224のみを取得します。
このロジックはFPGAでどのくらい時間がかかりますか? 47,805個の論理要素。 2つのモジュールがあるので、47805/2 = 23902が必要です。2つのハッシュを一度に読み始める方が、一般的な計算があるため、順番にカウントするよりもはるかに有益です。
そして、すぐに4つのハッシュをカウントし始め、ナンスフィールドで2ビットだけ異なる場合はどうでしょうか? 89009LE / 4 = 22252 LE / SHA256
そして、あなたが8つのハッシュを数えたら? 171418LE / 8 = 21427 LE / SHA256と判明
ここでは、完全なSHA256_transformあたりの30103個の論理要素の初期数を結果の256ビットの出力と比較し、SHA256_transfromの21427個の論理要素を結果の1ビットの出力と比較できます(これはさらなる計算の実行可能性を予測するために使用できます)。 そのような方法は、鉱夫のエネルギー消費を約3分の1削減できるように思えます。 まあ、四分の一...私はこれがどれほど重要であるかわかりませんが、これは重要であるようです。
もう一つ考えがあります。 計算用ブロックのメインデータは固定されたままであり、ハッシュの計算中にナンスフィールドのみが変更されます。 FPGA向けに迅速にコンパイルできる場合は、コンパイル段階で事前計算の大部分を実行できます。 結局のところ、コンパイラーが事前に計算できるすべてを計算する効率性を上記で示しました。 事前計算を使用して最適化されたロジックは、フルコンピューターに必要なボリュームよりもはるかに小さいか、はるかに小さいため、エネルギー消費が少なくなります。
まあ、そのようなもの。 実際、私自身は自分の研究を完全に確信しているわけではありません。 何かを考慮していないか、理解していないのかもしれません。 もちろん、提案された方法はグローバルなブレークスルーをもたらすものではありませんが、何かを保存することができます。 これまでのところ、これらはすべて理論的な考慮事項です。 実際の実装では、「クリーンな」SHA256は適切ではありません-動作周波数が低すぎます。 パイプラインを導入する必要があります。
もう1つ要因があります。 実際には、2つの連続したSHA256_transformがビットコインと見なされます。 この場合、論理要素の数と消費されるエネルギーの私の推定ゲインはそれほど重要ではないかもしれません。
アルテラのMAX10、50K LE FPGAを搭載したMars rover3ボードのbitconマイナープロジェクトのソースはこちらです。 ここで、Researchフォルダには、SHA256アルゴリズムを使用した私の実験のすべてのソースがあります。
マイナーFPGAプロジェクトの説明はこちら