 ロックフリーリストは、多くの興味深いデータ構造、ロックフリーリストが衝突リストとして使用される最も単純なハッシュマップ 、 分割順序リスト 、すべてがバケットを分割するための元のアルゴリズム、本質的にはマルチレベルスキップリスト 、リストの階層リスト。 前回の記事では、競合のないコンテナにこのような内部構造を与え、ロックフリーコンテナの動的な世界でスレッドセーフなイテレータをサポートできるようにしました。 わかったように、ロックフリーコンテナーが反復可能になるための主な条件は、内部構造の安定性です。ノードを物理的に削除(削除)してはなりません。 この場合、イテレータは、次の(インクリメント演算子)に移動する機能を持つノードへの単なる(おそらく複合)ポインタです。
ロックフリーリストは、多くの興味深いデータ構造、ロックフリーリストが衝突リストとして使用される最も単純なハッシュマップ 、 分割順序リスト 、すべてがバケットを分割するための元のアルゴリズム、本質的にはマルチレベルスキップリスト 、リストの階層リスト。 前回の記事では、競合のないコンテナにこのような内部構造を与え、ロックフリーコンテナの動的な世界でスレッドセーフなイテレータをサポートできるようにしました。 わかったように、ロックフリーコンテナーが反復可能になるための主な条件は、内部構造の安定性です。ノードを物理的に削除(削除)してはなりません。 この場合、イテレータは、次の(インクリメント演算子)に移動する機能を持つノードへの単なる(おそらく複合)ポインタです。
このアプローチをロックフリーリストに拡張できますか?..見てみましょう...
通常のロックフリーリストの構造は次のとおりです。
template <typename T> struct list_node { std::atomic<list_node*> next_; T data_; };
その中で、データはノードに直接組み込まれるため、キー(データ)を削除するとノード全体が削除されます。
ノードとデータを分離します-ノードが運ぶデータへのポインターを含むようにします:
template <typename T> struct node { std::atomic<node*> next_; std::atomic<T*> data_; };
次に、キーを削除するには、ノードの
data_
フィールドをリセットするだけで十分です。 その結果、リストは次の内部構造を取得します。
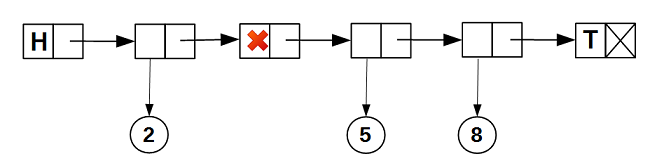
ノードは決して削除されないので、リストは反復可能です:イテレーターは実際にはノードへのポインターです:
template <typename T> struct iterator { guarded_ptr<T> gp_; node* node_; T* operator ->() { return gp_.ptr; } iterator& operator++() { // , node_, // } };
別のスレッドがイテレーターが配置されているデータを削除しないことを保証できないため、
guarded_ptr
(ハザードポインターで保護されたデータへのポインターを含む)の存在が必要です。 イテレータ
node_
nodeに
node_
するときのみ、データが含まれていることが保証されます。 保護されたポインターは、イテレーターが
node_
node上にある
node_
、そのデータが物理的に削除(削除)されないことを保証します。
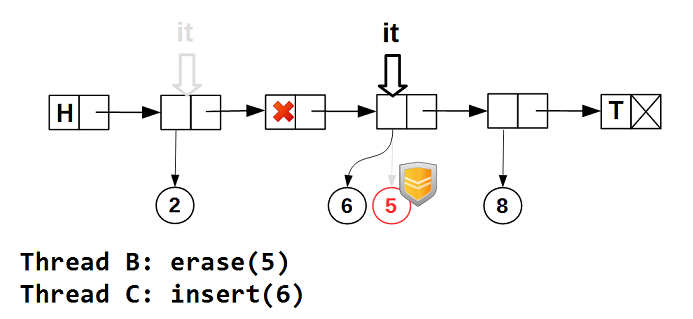
これがどのように機能するかを写真で見てみましょう。 リストの走査を開始します-イテレーターは、空でないデータを持つ最初のノードに配置されます。
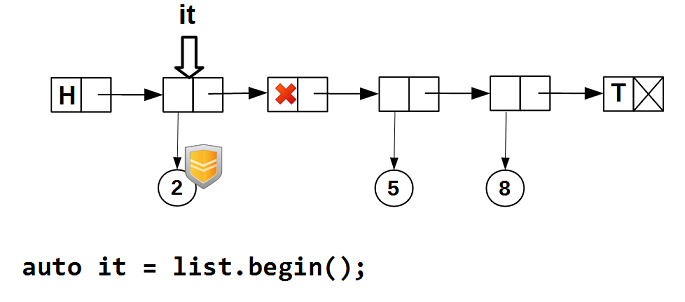
次に、イテレータをインクリメントします-空のデータを持つノードをスキップします:
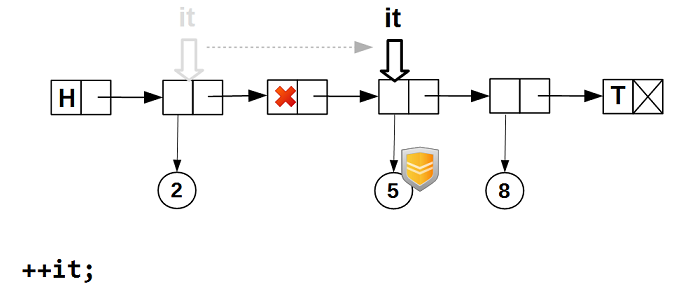
他のスレッドがイテレーターが配置されているノードのデータを削除しても、イテレーターの
guarded_ptr
は、イテレーターがノード上にある間、データが物理的に削除されないことを保証します。
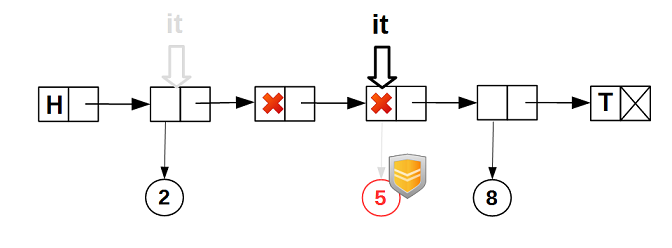
データがリストから削除され、他のデータが同じ
node_
nodeに割り当てられる
node_
ます。 この場合、イテレーターは
node_
ノードに配置されます。 この場合
operator ->()
イテレータの
operator ->()
異なるデータへのポインタを返すとしたら、奇妙です。
guarded_ptr
は、イテレータによって返されるデータの不変性を保証しますが、他のストリームによる変更を完全に防止するわけではありません。
ご覧のとおり、構築された反復可能リストはスレッドセーフイテレータをサポートし、非常に単純なキー(データ)削除操作を持ちます。これは、ノードの
data_
フィールドをゼロ化(CASプリミティブを使用)する
data_
です。 次の2つのケースが考えられるため、新しいデータを追加
insert()
操作はやや複雑です。
-空でないデータを含むリストの既存のノード間の新しいノードの挿入:
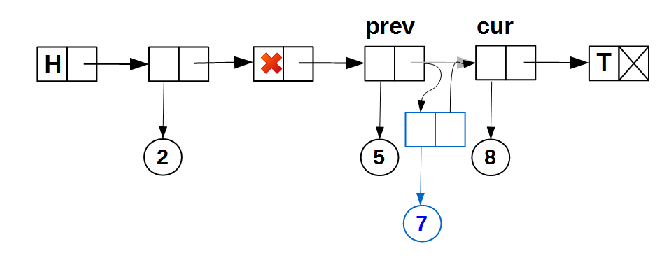
ノードを挿入するためのこのアルゴリズムは、以前の記事のいずれかですでによく知られています。
-空の
prev
ノードで
data_
フィールドを設定する:

2番目のケース(空の
data_
再利用する)が2、3の驚きを投げかけない場合、これで記事を終了できます。
最初の驚き
反復可能リストの挿入の最初の(単純な)バージョンは次のようになりました。

linear_search
関数はリスト内の通常の線形検索です(まあ、あまり一般的ではありません-競合リストがあるため、アトミック操作とハザードポインターを備えたスクワットが提供されます)、キーが見つかった場合は
true
返し、
true
ない場合は
false
返し
true
。 (
insert_pos
型の)
pos
関数のoutパラメーターは常に入力されます。 少なくとも目的の
data
キーが見つかるとすぐに検索が停止し
data
。 挿入については、検索の失敗に関心があります。この場合、
pos
には挿入位置が含まれます。
pos.cur
ノード
pos.cur
常に空で
pos.cur
ません(または、リストの最後(
tail
ノード)を
pos.prev
ます)が、
pos.prev
の前のノード)は空のノードを指している可能性があります。これは特に重要です。
prevData
構造体の
prevData
および
curData
フィールドは
cur
それぞれ
prev
および
cur
insert_pos
値です。 また、リストからノードが削除されることはないため、
prev
のポインターを保護し、ノードでハザードポインターを無効にする必要がないことにも注意してください。 ただし、データは削除できるため、保護します。
そのため、単純な実装では、前のノードが空の場合(
pos.prevData == nullptr
)、挿入されたデータへのリンクを書き込もうとしています。 競争力のあるリストがあるので(さらに、ロックフリーでも、すぐに修正します)、アトミックCASによって
prev.data_
ポインターを変更します。成功した場合、他のスレッドは私たちを
prev.data_
ず、挿入しましたリストに新しいデータ。
ここで最初の驚きがあります。 スレッドAが特定のキーをリストに追加するとします:
linear_search()
実行され、挿入位置によってinsert_pos構造体が初期化され、スレッドは
link()
を呼び出す準備ができましたが、時間が経過するとオペレーティングシステムによって
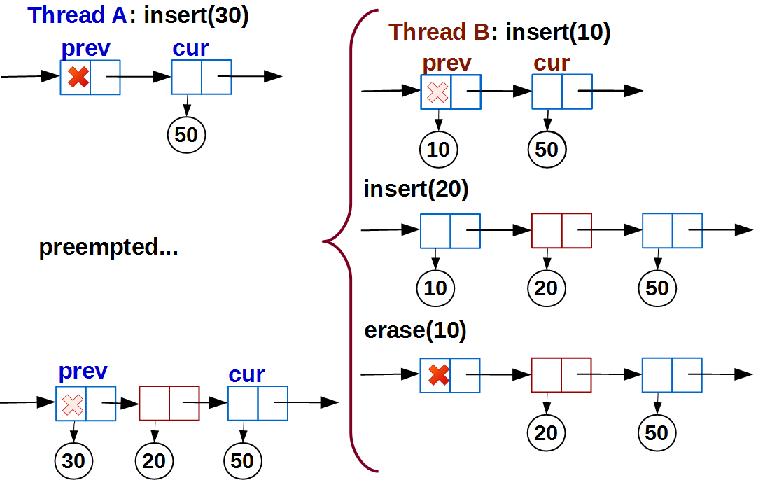
スレッドAの再開時に、リストは認識できないほど変更されましたが、ストリームAで見つかった位置
pos
観点からは何も変わりませんでした。
prev
は空だったため、空のままでした。 したがって、ストリームAはキー30でデータを書き込み、挿入を成功させ、正常に挿入を完了します。これにより、リストの順序が崩れます。
prev->data_
が
NULL
であるため、これはハザードポインターを使用しても解決できないABAの問題の一種です。 検索後にリンク
prev
>
cur
が変更されていない場合にのみ、新しいデータを空のノードにリンクする権利があります。 さらに、これらのノードのデータは変更されていません。 この問題を解決するために、 マークポインター手法を使用します。ノードデータへのポインターの最下位ビットを「新しいノードが挿入されています」という記号として使用します。 さらに、
prev
と
cur
両方のノードをマークする必要があります。そうしないと、他のスレッドが
cur
からデータを削除し、リストの順序が再び違反されます(
cur
ノードが常に空でないことを忘れないでください)。 その結果、ノードの構造が変更され、データを追加するための
link()
関数は次の形式になります。
template <typename T> struct node { std::atomic< node * > next_; std::atomic< marked_ptr< T, 1 >> data_; }; bool link( insert_pos& pos, T& data ) { // prev cur if ( !pos.cur->data_.CAS( marked_ptr(pos.curData, 0), marked_ptr(pos.curData, 1))) { // — - return false; } if ( !pos.prev->data_.CAS( marked_ptr(pos.prevData, 0), marked_ptr(pos.prevData, 1))) { // — // pos.cur->data_.store( marked_ptr(pos.curData, 0)); return false; } // , prev -> cur if ( pos.prev->next_.load() != pos.cur ) { // - - prev cur pos.prev->data_.store( marked_ptr(pos.prevData, 0)); pos.cur->data_.store( marked_ptr( pos.curData, 0)); return false; } // , if ( pos.prevData == nullptr ) { // // , store bool ok = pos.prev->data_.CAS( marked_ptr( nullptr, 1 ), marked_ptr( &data, 0 )); // cur pos.cur->data_.store( marked_ptr( pos.curData, 0)); return ok; } else { // — Harris/Michael // // } }
マークされたポインターの導入は、データ削除機能にも影響します(思い出すように、これは単純に
data_
フィールドの無効化に
data_
ます):タグなしのデータのみをゼロにする必要がありますが、これは削除手順に複雑さを追加しません。 リスト検索では、マーカーは完全に無視されます。
その結果、反復可能リストはロックフリーではなくなりました:スレッドが少なくとも1つのノードをマークしてから削除された(
link()
関数に例外の場所がない
link()
場合、ノードは永久に、最後にマークされたままになるため、ロックフリー条件に違反しますいつの日か、ラベル付け解除のための無限のアクティブな待機につながります。 一方、仕事中に小川を殺すのは
第二の驚き
残念ながら、テストではこれが完全なソリューションではないことが示されています。 デバッグビルドであっても、単純な反復可能なリストがデータの並べ替えの違反を頻繁に示した場合、マークポインターの導入後、テストはリリースビルドでのみまれに違反を示し始めました。 これは、非常に不快な問題があることを示す信号であり、実際には妥当な時間内に再現することはできず、分析的にしか解決できません。
分析が示したように、問題は実際には最初の問題と直交しています。
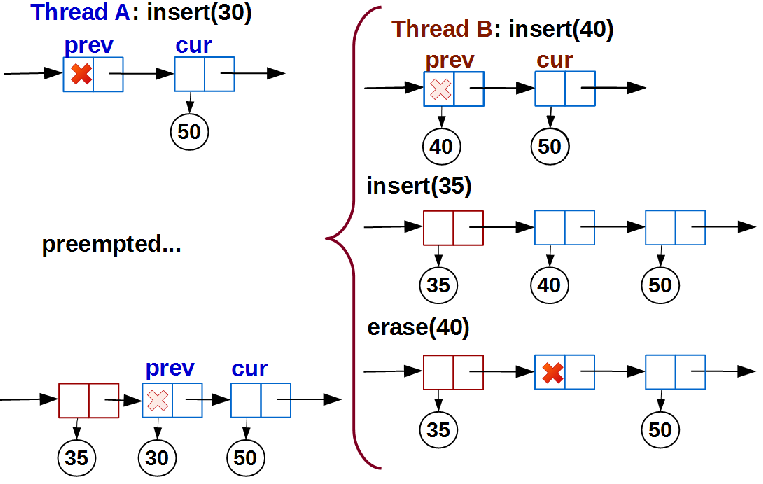
最初の場合と同様に、スレッドAは
link()
に入る前に強制的に削除されます。 Aが再び計画されるまで待機する間、他のスレッドは、スレッドAの
link()
関数の前提条件に違反しないが、並べ替えられたリストの違反につながるシーケンスを追加/削除するために、リストで
解決策は、
link()
別の条件を追加することです:
prev
および
cur
ノードをマークした後、新しいノードを挿入する(または空の
prev
)後、 挿入位置が変更されていないことを確認する必要があります。 これを確認する方法は1つしかありません。新しいデータに続くノードを見つけて、それが
cur
あることを確認してください。
bool link( insert_pos& pos, T& data ) { // prev cur // ... // , prev -> cur // ... // , if ( find_next( data ) != pos.cur ) { // oops! … pos.prev->data_.store( marked_ptr(pos.prevData, 0)); pos.cur->data_.store( marked_ptr( pos.curData, 0)); return false; } // , // ... }
ここで、ヘルパー関数
find_next()
は、上記の
data
最も近いノードを探します。

おわりに
したがって、反復可能な競合リストを作成できます。 その中の検索はロックフリーですが、挿入とその結果の削除はまだロックフリーではありません。 なぜ彼はそんなに必要なのですか?..
まず、いくつかのタスクではスレッドセーフなイテレータが重要です。 第二に、このリストは、その中のキーを削除する操作が挿入よりもはるかに簡単であるという点で興味深いです-ノードのデータへのポインタをリセットするだけです。 削除は通常、はるかに困難です。従来のロックフリーリストからの2段階の削除を参照してください。 最後に、このタスクは個人的には特定の課題でした。それ以前は、競合コンテナでは原則としてイテレータの概念を実現できないと考えていたためです。
このアルゴリズムが役に立つことを願っています。libcdsを参照してください。MichaelSet / MapおよびSplitListSet / MapとIterableListに基づいて実装用のスレッドセーフイテレータをサポートしています。
ロックフリーのデータ構造