
このツリーから、「mother」と「soaps」という単語、および「soaps」と「frame」が接続されており、「mother」と「frame」という単語は直接関連していないことが明らかです。
この記事は、パーサーを必要とする人には役立ちますが、どこから始めるべきかは明確ではありません。
私は数ヶ月前にこのトピックに対処しましたが、その時点で既製の、できれば無料のアナライザーを入手する場所についての情報はあまり見つかりませんでした。
Habréには、 MaltParserの経験に関する優れた記事があります。 しかし、それ以降、アセンブリに使用される一部のパッケージは他のリポジトリに移動し、必要なバージョンのライブラリを使用してプロジェクトをアセンブルするために一生懸命働く必要があります。
SyntaxNetを含む他のオプションがあります。 Habrでは、SyntaxNetについて何も見つけられなかったため、ギャップを埋めます。
SyntaxNetとは何ですか?
基本的に、 SyntaxNetは、ニューラルネットワークを使用するTensorFlowベースの構文リンケージライブラリです。 現在、ロシア語を含む40の言語がサポートされています。
SyntaxNetをインストールする
インストールプロセス全体は、公式ドキュメントに記載されています。 ここで指示を複製しても意味がありません。1つだけ注意してください。 組み立てには、Bazelが使用されます。 4つのプロセッサと8 GBのRAMが割り当てられたUbuntu 16.04 x64 Serverを使用する仮想マシンでプロジェクトをビルドしようとしましたが、これは失敗しました。すべてのメモリが消費され、スワップが使用されます。 数時間後、インストールプロセスを中断し、すべてを繰り返し、既に12 GBのRAMを割り当てました。 この場合、すべてがスムーズに進み、ピーク時には20 MBのスワップのみが関係していました。
おそらく、RAMの少ない環境にシステムを配置できる設定がいくつかあります。 おそらく、アセンブリは複数の並列プロセスで実行され、仮想マシンに1つのプロセッサのみを割り当てる価値がありました。 知っている場合は、コメントを書いてください。
インストールが完了した後、この仮想マシン用に1GBのメモリを残しましたが、これはテキストを正常に解析するためのマージンで十分です。
私はマーク付きのケースとしてRussian-SynTagRusを選択しました。ロシア語と比較してよりボリュームがあり、精度が高いはずです。
SyntaxNetの使用
文を解析するには、
tensorflow/models/syntaxnet
して実行します(モデルへのパスは絶対です):
echo " " | syntaxnet/models/parsey_universal/parse.sh /home/tensor/tensorflow/Russian-SynTagRus > result.txt
result.txtファイルでは、次のようになります。6番目の列のデータを「_」に置き換えて、行がここで折り返されないようにします。そうしないと、読むのが不便になります。
cat result.txt 1 _ NOUN _ _ 2 nsubj __ 2 _ VERB _ _ 0 ROOT _ _ 3 _ NOUN _ _ 2 dobj __
データはCoNLL-U形式で表示されます。 ここで最も興味深いのは次の列です。
1.文中の単語のシリアル番号、
2.単語(または句読文字)、
4.品詞、 ここでは品詞の説明を見ることができ、
7.親語の番号(またはルートの場合は0)。
つまり、列番号7に「0」が含まれる行にあるため、「soap」という語がルートであるツリーがあります。 「soap」という単語にはシリアル番号2があります。列番号7に「2」が含まれるすべての行を探します。これらは「soap」という単語の子です。 合計:

ところで、さらに詳しく見ると、ツリーはすべての依存関係を常に正常に表しているとは限りません。 たとえば、 ABBYY Comprenoでは、 追加のリンクがツリーに追加され、ツリーのさまざまなブランチにある要素の接続を示します。 私たちの場合、そのような関係はありません。
インターフェース
テキスト解析の速度が重要な場合は、 TensorFlow Servingを扱うことができます。これにより、モデルを一度メモリに読み込んでから、はるかに高速に回答を得ることができます。 残念ながら、TensorFlow Servingを介した作業のセットアップは、当初のように簡単ではありませんでした。 しかし、全体的には可能です。 これが韓国語でどのように行われたかの例です。 ロシア語でこれを行う方法の例がある場合は、コメントに書いてください。
私の場合、解析速度はそれほど重要ではなかったので、TensorFlow Servingでトピックを終了せず、SyntaxNet を操作するための簡単なAPIを作成して、SyntaxNetを別のサーバーに保持してHTTP経由でアクセスできるようにしました。
このリポジトリには、デバッグがオファーの解析方法を確認するために使用するのに便利なWebインターフェイスもあります。

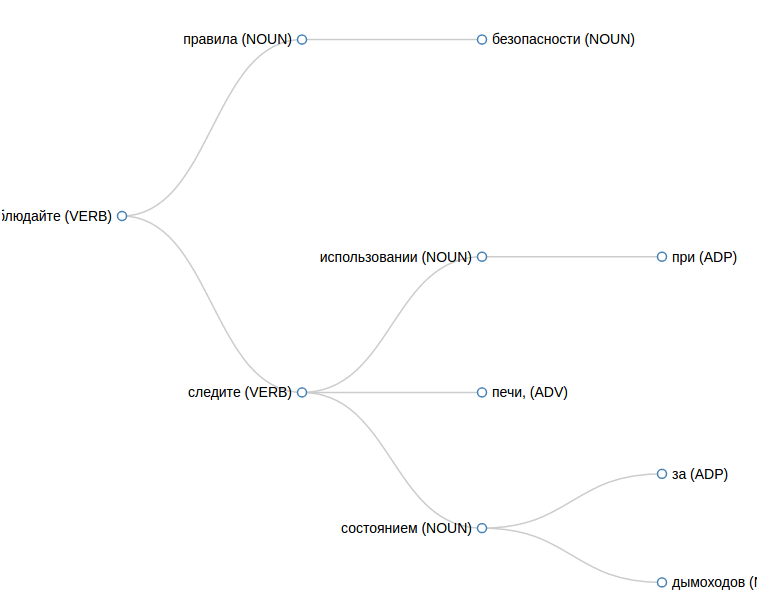
JSONで結果を取得するには、次のリクエストを行います。
curl -d text=" ." -d format="JSON" http://<host where syntax-tree installed>
次の答えが得られます。
[{ number: "2", text: "", pos: "VERB", children: [ { number: "1", text: "", pos: "NOUN", children: [ ] }, { number: "3", text: "", pos: "NOUN", children: [ ] } ] }]
1つのポイントを明確にします。 Bazelは興味深い方法でパッケージをインストールするため、一部のバイナリは
~/.cache/bazel
保存されます。 PHPから実行にアクセスするために、ローカルマシン上のWebサーバーのユーザーにこのディレクトリへの権限を追加しました。 おそらく同じ目標をより文化的な方法で達成することができますが、実験にはこれで十分です。
他に何
また、冒頭で述べたMaltParserもあります。 後で、 マークアップされたSynTagRusケースをここからダウンロードして、最新バージョンのMaltParserをトレーニングすることもできることを発見しましたが、解析結果を得るためにジョブを完了してMaltParser全体を組み立てる時間はありませんでした。 このシステムはわずかに異なる方法でツリーを構築します。私のタスクでは、SyntaxNetとMaltParserを使用して得られた結果を比較することは興味深いです。 おそらく次回はそれについて書くことができるでしょう。
ロシア語のテキストを解析するためのツールをすでに正常に使用している場合は、使用するコメントを書いてください。私や他の読者にとって興味深いことです。
UPD
以下のコメントの buriyからの非常に有用な説明:
モルフォロジーモデルにエラーがなければ、そこでの解析ははるかにうまく機能します。これは、辞書に基づいていないが、ニューラルネットワークでもあります。
入力形式では、句読点は個別のトークンです。
したがって、エントリの提案は、句読点が両側でスペースで区切られるように提出する必要があります。
まあ、文の最後の別のポイントは時々何かを変える
最終ポイントの前にもスペースが必要であるため、入力形式が配置され、モデルはそのような例でトレーニングされました