Allstateの保険金請求の重大度の卒業プロジェクト予測
パート1.プロジェクトの説明
プロジェクトの概要
データ関連の分野で働く多くの人々は、データサイエンスコンテストをホストするプラットフォームであるKaggleを知っています。 現在、Kaggle には60万人を超えるデータサイエンティストと多くの有名企業が参加しています。 会社は問題を説明し、品質指標を設定し、問題解決に役立つデータセットを公開し、参加者は会社が提起した問題を解決する独自の方法を見つけます。
このKaggleコンペは、個人の生命保険および財産保険の分野で最大の米国公開企業であるAllstateによって提供されています。 Allstateは現在、保険金請求のコスト(重大度)を予測する自動方法を開発しており、Kaggleコミュニティにこの問題を解決するための新しいアイデアと新しいアプローチを示すよう呼びかけています。
同社は、保険金請求処理サービスの品質の向上を目指しており、保険金請求の費用を数値で推定した世帯(各世帯は匿名の記号のベクトルで表されます)で発生した事故に関する一連のデータを公開しています。 私たちの仕事は、新しい世帯の保険金請求の可能性を予測することでした。
Kaggleには、このタスクに関連する他のデータセットもいくつかあります。
• Allstate Insurance Prediction Competition-被保険車両の特性に基づいて保険料を予測するために設計された以前のAllstate競争。 この競争のデータセットは、保険分野に突入する機会を提供します。
• 火災損失評価競争 -保険契約を策定するために、予想される火災損失を予測するためにLiberty Mutual Groupが開催する競争。 これは、保険業界の予測問題を解決するアプローチの理解を深めるのに役立った保険業界のデータセットのもう1つの例です。
それとは別に、初期データセットは高度に匿名であることに注意してください(機能名と値の両方の点で)。 この側面は、特性の意味の理解を複雑にし、外部ソースからのデータセットを充実させることを困難にします。 競争の参加者は、ソースデータを充実させ解釈するためにさまざまな試みをしましたが、その試みの成功には議論の余地があります。 一方、このデータセットには、トレーニングデータに追加情報が残っている場合に発生するデータリークがないようです。 そのような情報は、ターゲット変数と強く相関し、不合理に正確な予測につながる可能性があります。 最近、かなりの数のKaggleコンテストがこのようなリークに苦しんでいます。
問題の声明
Allstateの顧客の保険金請求に関する記録を含むデータセットを自由に使用できます。 各エントリには、カテゴリ属性と連続属性の両方が含まれています。 ターゲット変数は、この保険金請求によって引き起こされる損失の数値推定です。 すべての標識は可能な限り匿名で作成されます。標識の実際の名前またはその本当の意味はわかりません。
私たちの目標は、与えられた属性値に基づいて将来の損失を正しく予測できるモデルを構築することです。 明らかに、これは回帰タスクです。ターゲット変数は数値です。 また、教師とのトレーニングのタスクでもあります。ターゲット変数はトレーニングデータセットで明確に定義されており、テストセットの各レコードの値を取得する必要があります。
Allstateはデータのクリーニングと前処理に優れた仕事をしました。提供されたデータセットは非常に高度にクリーニングされ、(少し追加処理を行った後)教師と一緒に多数のトレーニングアルゴリズムに転送できます。 データ調査専用のレポートの一部で見るように、Allstateのタスクでは、特に新しい機能を生成したり、既存の機能を前処理したりすることはできません。 一方、このデータセットは、さまざまな機械学習アルゴリズムとアンサンブルの使用とテストを促進します-ちょうど卒業プロジェクトに必要なものです。
Allstateプロジェクトに次のアプローチを適用しました。
1.データセットを調べ、データ、機能、およびターゲット変数の意味を理解し、データ内の単純な関係を見つけます。 この手順は、 Data Discovery Notebookファイルで実行されます。
2.必要なデータ前処理を実行し、いくつかの異なる機械学習アルゴリズム(XGBoostおよび多層パーセプトロン)をトレーニングします。 基本的な結果を取得します。 これらのタスクは、 XGBoostおよびMLPファイルで解決されます。
3.モデルを構成し、各モデルの結果に顕著な改善を達成します。 このステップは、XGBoostおよびMLPファイルにも実装されています。
4.基本予測子として以前のモデルを使用して、モデルを重ね合わせる(積み重ねる)手法を使用してアンサンブルを学習させます。 最終結果を取得します。これは以前の結果よりもはるかに優れています。 このステップは、 Stacking Notebookファイルに実装されています。
5.結果を簡単に話し合い、トーナメントの順位で最終的な位置を評価し、それを改善するための追加の方法を見つけます。 結果については、このレポートとStacking Notebookファイルの最後の部分で説明します。
指標
Kaggleプラットフォームでは、競合会社が競合他社が競合できる指標を明確に定義する必要があります。 Allstateは、このようなメトリックとしてMAEを選択しました。 MAE(平均絶対誤差)は、予測値と真の値を直接比較する非常にシンプルで明白なメトリックです。
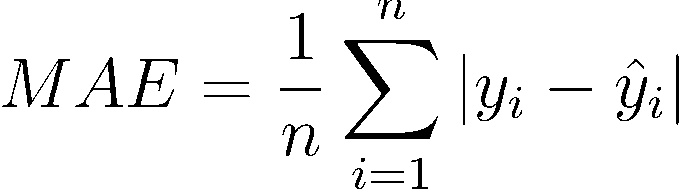
このメトリックは指定されているため、変更できません 競争条件の一部です。 それにもかかわらず、私はそれがこのタスクに適していると考えています。 まず、MAEは(MSEや標準誤差とは異なり)エミッションの不正確な推定に対して大きなペナルティを与えません(データセットには、異常に高い損失値を持つ複数のエミッションがあります)。 第二に、MAEは簡単に理解できます。エラー値は、ターゲット変数自体と同じ次元で表現されます。 一般的に、MAEはデータサイエンスの初心者にとって優れた指標です。 簡単に計算でき、理解しやすく、誤解しにくいです。
パート2.分析
データ探索
このステップの完全な概要については、 データ検出ファイルを参照できます。
トレーニングセット全体は、uid変数を使用してインデックス付けされた188318個の要素で構成されます。 データを操作するためのインデックスには、追加情報は含まれません。 これは、いくつかの欠損値を含む「1」で始まる単純な番号付けです。 予測のためのインデックスなしでテストセットを使用することはありません(結果をKaggleに送信する必要があります)が、テストデータセットがトレーニングと同じように編成されていることに注意してください。 明らかに、トレーニングとテストのサンプルは、sklearnパッケージのtrain_test_splitなど、分割手順によって同じデータセットから取得されました。
プロジェクトのこの部分の主な結果は次のとおりです。
•データセットには130の異なる属性が含まれます(idインデックスとターゲット損失変数を除く)。 データセットのサイズを考えると、これは非常に合理的な数の機能です。 ここで「次元の呪い」に出くわすことはほとんどなかったでしょう。
•116のカテゴリ記号、14の数値。 ほとんどの機械学習アルゴリズムはカテゴリ変数を正しく処理できないため、おそらくこれらの116の機能をコーディングする必要があります。 このようなコーディングの方法と、それらの違いについては後で説明します。
•データセット全体に単一の欠損値はありません。 この事実は、Allstateが高度な前処理でデータを提供し、アクセスしやすく使いやすくしたことを確認するだけです。
•ほとんどのカテゴリ属性(72または62%)はバイナリ(はい/いいえ、男性/女性)ですが、それらの意味は単に「A」および「B」と書かれているため、意味をまったく推測できません。 3つの標識には3つの異なる意味があり、12の標識には4つの異なる意味があります。
•数値記号は既に0から1の範囲でスケーリングされており、それらすべての標準偏差は0.2に近く、平均値は0.5のオーダーです。したがって、これらの記号については、その値について推測することはできません。
•どうやら、LabelEncoderまたは同様の手順を使用して数値に変換される前に、一部の数値属性がカテゴリ化されていたようです。
•さまざまな兆候のヒストグラムを作成することにより、それらのいずれも正規分布法則に従わないことを確認できます。 このデータの分布の非対称性を減らすことはできますが(scipy.stats.mstats.skew> 0.25の場合)、そのような変換の後でも、正常に近い分布は失敗します。
•ターゲット変数も正規分布ではありませんが、正規分布に近い単純な対数変換になります。
•ターゲット変数には、異常に高い値(非常に重大なインシデント)を持ついくつかの外れ値が含まれています。 理想的なケースでは、モデルがそのような外れ値を識別して正しく予測できるようにしたいと思います。 同時に、十分な注意を払わなければ、簡単に再トレーニングできます。 明らかに、ここで何らかの妥協が必要です。
•トレーニングサンプルとテストサンプルのデータ分布は類似しています。 これは、トレーニングサンプルとテストサンプルへの分割の理想的な特性です。これにより、交差検証が大幅に簡素化され、トレーニングデータセットの交差検証を使用してモデルの品質に関する情報に基づいた決定を行うことができます。 これにより、Kaggleコンテストへの参加が大幅に簡素化されましたが、卒業プロジェクトの実施には役立ちません。
•いくつかの連続的な特徴は強く相関しています(相関行列は下の図1に示されています)。 これにより、このデータセットにデータベースの多重共線性が生じ、線形回帰モデルの予測力が大幅に低下する可能性があります。 この問題の一部は、L1またはL2正則化を使用して解決できます。
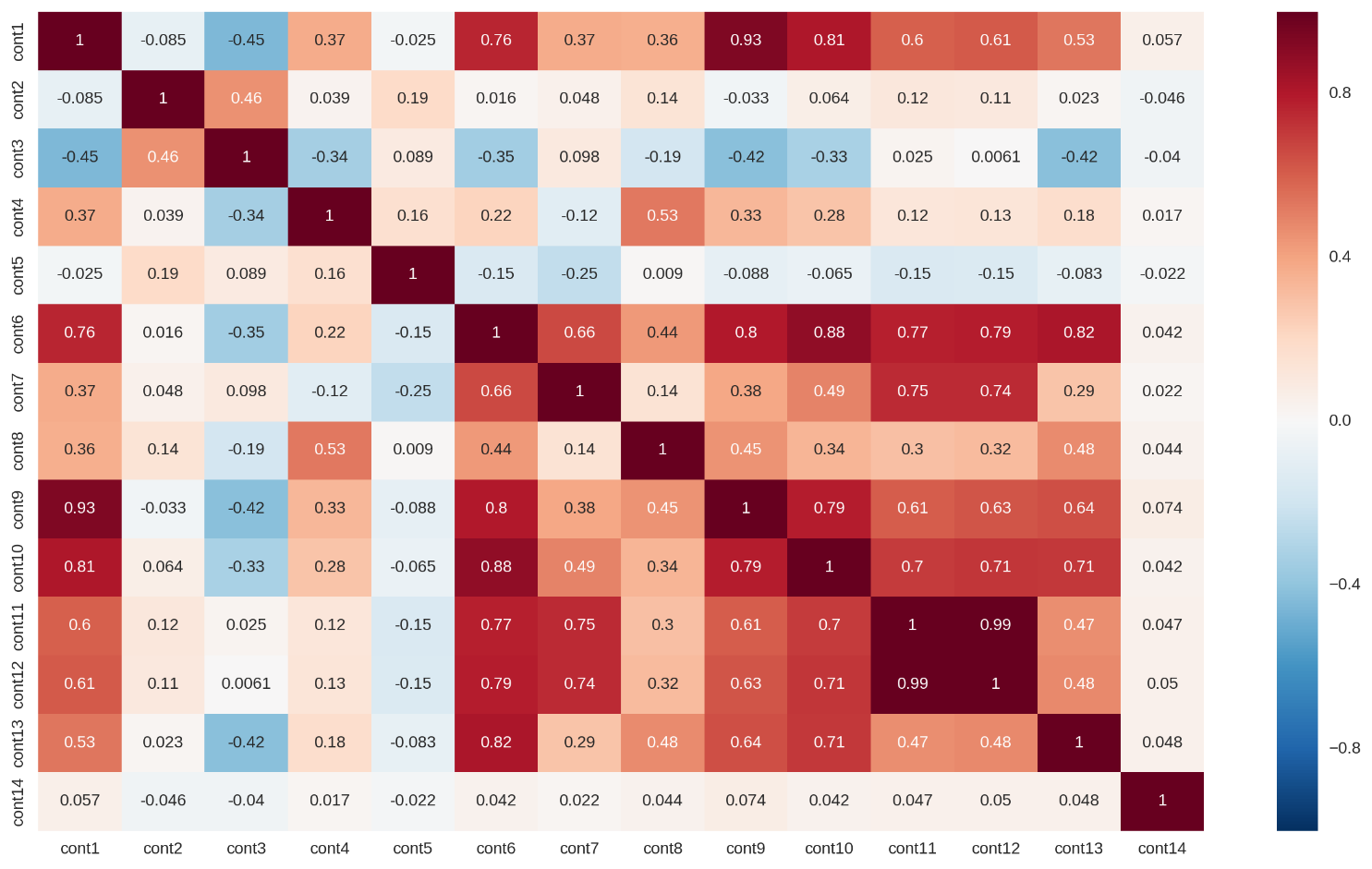
図1:連続フィーチャの相関行列
概要の視覚化
このデータセットの重要な機能-高度な匿名性、データ前処理-を示すために、1つの視覚化を示します。
以下は、cont#としてマークされた14の連続特性のヒストグラムです。 図からわかるように 1、データ分布には複数のピークがあり、分布密度関数はガウス分布に近くありません。 データの非対称係数を減らすことはできますが、正規化アルゴリズム( Box-Cox変換など)を使用しても、このデータセットにはほとんど効果がありません。
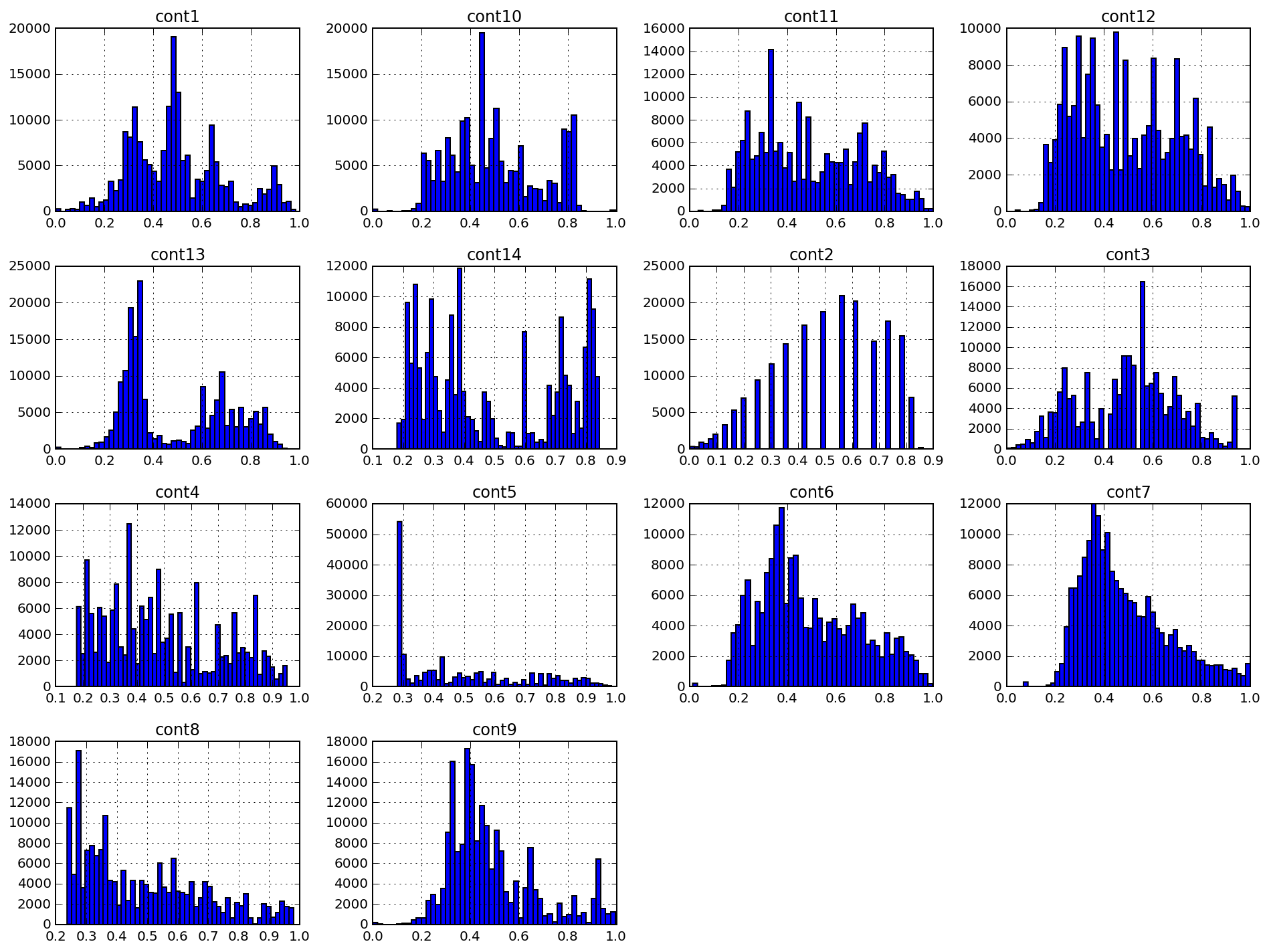
図2:連続フィーチャの棒グラフ
cont2の兆候は特に興味深いものです。 この症状はカテゴリーに由来する可能性が高く、年齢または年齢カテゴリーを反映している可能性があります。 残念ながら、私はこの症状の調査には参加しませんでした。私のプロジェクトには影響がありませんでした。
データ分析のアルゴリズムと方法
このセクションは、 XGBoostノートブックとMLPノート ブックの 2つのドキュメントでさらに詳しく説明されています。
XGBoost。 私がプロジェクトに興味を持っている理由の1つは、木、特にXGBoostをブーストする方法を試す機会です。 事実、このアルゴリズムは、そのスケーラビリティ、柔軟性、印象的な予測力により、多くのKaggle競技会の一種の標準的なスイスナイフになりました。
XGBoostは、現在の教師(よく定義されたトレーニングデータセットとターゲット変数)と同様の教師によるタスクの指導に適しています。 以下に、XGBoostアルゴリズムの原理を説明します。
XGBoostは、本質的にブースティングのバリエーションです。教師トレーニングのバイアスと分散を減らすために使用される機械学習のアンサンブルメタアルゴリズムと、弱いモデルをより強力なモデルに変える一連の機械学習アルゴリズムです。 出典: ウィキペディア 当初、ブースティングのアイデアは、PAC(おそらくほぼ正しい)モデルでのランダムな推測よりもわずかに良い結果を与える「弱い」学習アルゴリズムを、任意の「強い」学習アルゴリズムに「強化」できるかどうかについて、KearnsとValiantによって提起された質問に根ざしています精度。 出典: ブースティングの簡単な紹介 (Yoav FreundとRobert E. Schapire)。 この質問に対する肯定的な回答は、多くのブースティングアルゴリズムの開発につながったRESchapireの記事The Power of Weak Learningで与えられました。
ご覧のとおり、ブースティングの基本原則は、弱学習アルゴリズムの一貫した使用です。 後続の各弱いアルゴリズムは、モデル全体のバイアスを減らし、弱いアルゴリズムを強力なアンサンブルモデルに結合しようとします。 AdaBoost(弱学習アルゴリズムに適応する適応型ブースティング)、LPBoost、勾配ブースティングなど、ブースティングアルゴリズムと方法にはさまざまな例があります。
特に、XGBoostは、勾配ブースティングスキームを実装するライブラリです。 勾配ブースティングモデルは、他のブースティング方法を使用する場合と同様に、段階的に構築されます。 このブースティング方法は、弱学習アルゴリズムを一般化して、任意の微分可能な損失関数(計算可能な勾配を持つ損失関数)の最適化を可能にします。
XGBoostは、一種のブースティングとして、スパースデータの操作に適した、オリジナルの決定木ベースの機械学習アルゴリズムが含まれています。 理論に基づいた手順により、木のトレーニングでさまざまな要素の重みを操作できます。 出典: XGBoost:スケーラブルなツリーブースティングシステム (Tianqi Chen、Carlos Guestrin)
XGBoostアルゴリズムには多くの利点があります。
•正則化。 多層パーセプトロンモデルに特化したセクションで示されるように、他のアルゴリズムを使用すると、再トレーニングされたモデルを簡単に取得できます。 XGBoostは、このプロセスを構成するための一連のオプションとともに、信頼性が高く、すぐに使用できる正規化ツールを提供します。 これらのパラメーターのリストには、ガンマ(さらなるツリー分割に必要な損失関数の最小削減)、アルファ(L1正則化の重み)、ラムダ(L2正則化の重み)、max_depth(最大ツリー深度)、min_child_weight(すべての重みの最小合計)が含まれます子供に必要な観察)。
•並列および分散コンピューティングの実装。 他の多くのブースティングアルゴリズムとは異なり、ここでのトレーニングは並行して実行できるため、トレーニング時間が短縮されます。 XGBoostは非常に高速です。 前述の記事の著者によると、 「システムは1台のコンピューターで既存の一般的なソリューションよりも10倍以上高速で実行され、分散環境またはメモリ制限環境で数百万のコピーに拡張できます。」
•組み込みの相互検証。 クロス検証は、結果として得られるモデルの品質を評価するための前提条件であり、XGBoostの場合、それと連携するプロセスは非常にシンプルで理解しやすいものです。
MLP 私たちが構築している2番目のモデルは、完全に接続された直接分布ニューラルネットワークまたは多層パーセプトロンです。 最終目標は、基本的なリグレッサのアンサンブル(スタッキング)を構築することなので(そして、最初のリグレッサのタイプ-XGBoostを決定しました)、そうでなければデータセットを調べる一般化アルゴリズムの別の「タイプ」を見つける必要があります。
これは、一般化されたゼロレベルアルゴリズムが「スペースをカバーする」べきだと言うときです。 Wolpert、一般化オーバーレイ。
レイヤーと各レイヤー内の要素を追加することにより、ニューラルネットワークはデータ内の非常に複雑な非線形関係をキャプチャできます。 普遍近似定理は、直接伝播ニューラルネットワークがユークリッド空間の任意の連続関数を近似できると述べています。 したがって、多層パーセプトロンは非常に強力なモデリングアルゴリズムです。 多層パーセプトロンは簡単に再トレーニングの対象となりますが、この要因の影響を減らすために必要なすべてのツールを自由に使用できます:ニューロン活性化のランダムシャットダウン(ドロップアウト)、L1-L2正則化、パケット正規化(バッチ正規化)など また、いくつかの同様のニューラルネットワークをトレーニングして、それらの予測を平均化することもできます。
ディープラーニングコミュニティは、人工ニューラルネットワークに基づいてモデルをトレーニングおよび評価するための高品質なソフトウェアを開発しました。 私のモデルは、Googleが開発したテンソルコンピューティングライブラリであるTensorFlowに基づいています。 モデルの構築を簡素化するため、TensorFlowとTheanoの高レベル外部インターフェイスであるKerasを使用することにしました。これは、ニューラルネットワークの構築とトレーニングに必要なほとんどの標準操作を引き受けます。
GridSearchおよびHyperopt。 これらのメソッドは、モデルの選択とハイパーパラメーターの構成に使用されます。 GridSearchはパラメーターのすべての可能な組み合わせを徹底的に検索しますが、Hyperoptはパラメーター空間から特定の分布で特定の数の候補を選択するか、ベイジアン最適化の形式を使用します。 これらの両方の選択方法とともに、相互検証手法を使用してモデルのパフォーマンスを評価します。 モデルの計算の複雑さに応じて、3つまたは5つの部分でk分割交差検証を使用します。
オーバーレイモデル(スタッキング)。 2つのモデル(XGBoostおよび多層パーセプトロン)の予測を組み合わせて、メタリグレッサーを使用して最終予測を作成します。 この方法はスタッキングと呼ばれ、Kaggleで頻繁に使用されます(多くの場合、過度に)。 スタッキングのアイデアは、トレーニングセットをk個の部分に分割し、各ベースリグレッサをk-1個の部分でトレーニングし、残りの部分で予測を行うことです。 その結果、ターゲット変数の実際の値を保持しながら、リグレッサーの予測(フォールド外)を含むトレーニングサンプルを取得します。 次に、各リグレッサーの予測をメタモデルのサインとして使用し、真の値をターゲットサインとして使用して、このデータでメタモデルをトレーニングします。
トレーニングされたメタモデルの場合、テストサンプルのリグレッサの予測変数を入力し、トレーニングされたモデルが各リグレッサの特性誤差を考慮に入れる最終予測を取得します。 このステップの実装については、 Stacking Notebookファイルで詳しく説明されています。
結果を評価するための基準
最初の結果はAllstateによって設定されました。ランダムフォレストのアンサンブルモデルをトレーニングし、MAE = 1217.52141の結果を得ました。 この結果は、単純なXGBoostモデルでも簡単に超えることができ、ほとんどの参加者が成功しました。
また、モデルを教えたときに自分自身にいくつかの基準を設定しました。 一番下の行は、このクラスの単純なモデルのパフォーマンスでした。 XGBoostの場合、この結果はMAE = 1219.57に設定されており、最適化またはハイパーパラメーター設定なしで50本の木の単純なモデルによって達成されています。 標準のハイパーパラメーター値( Analytics Vidhyaの記事で推奨 )を取得し、少数のツリーを残して、この初期結果を得ました。
多層パーセプトロンの場合、ReLUアクティベーション機能、標準ウェイトの初期化、およびAdam GDオプティマイザー:MAE = 1190.73を使用して、隠れ層(128)に少数の要素を含む2層モデルのパフォーマンスが基本結果として選択されました。
この卒業プロジェクトでは、すべての結果が再現可能であるべきだと理解しているため、複雑なベースラインモデルを避けました。 私もこのKaggleコンペティションに参加していますが、コンペティションで使用されているすべてのモデル(ほとんどが組み合わせであり、多数のアルゴリズムを使用)をトレーニングするには、間違いなく読者からの時間がかかりすぎます。 Kaggleコンテストでは、MAE = 1100の結果を上回ることを望んでいます。
パート3.方法論
データの前処理
このデータセットはすでに十分に準備され、前処理されていることを既に述べました。たとえば、連続記号は間隔[0,1]にスケーリングされ、カテゴリ記号は名前が変更され、値は数値に変換されました。 実際、前処理の観点では、実行できる余地はあまりありません。 ただし、正しいモデルをトレーニングできるように、まだいくつかの作業を行う必要があります。
ターゲット変数の前処理
ターゲット特性には、回帰モデルの品質を低下させる可能性のある指数分布があります。 ご存知のように、回帰モデルは、ターゲット変数が正規分布している場合に最適に機能します。
この問題を解決するには、ターゲット変数損失に対数変換np.log(train ['loss'])を適用するだけです。
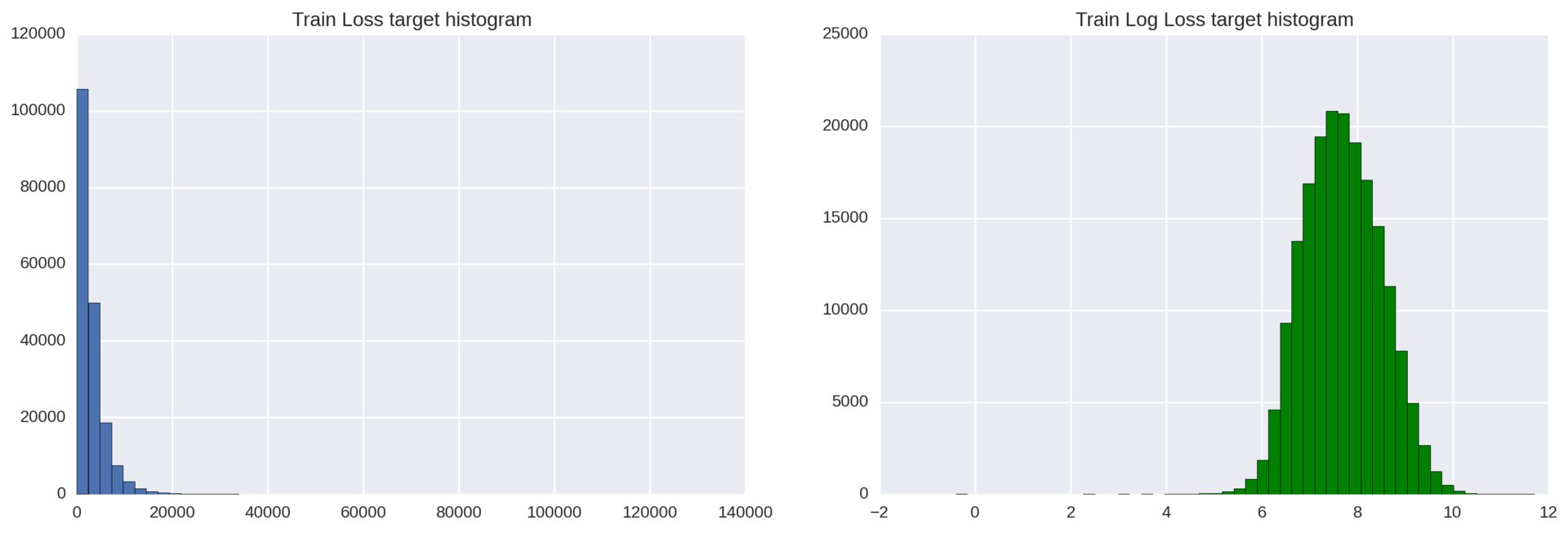
図3:対数変換前後のターゲット変数の分布のヒストグラム
結果を改善することができます。いくつかの逸脱した観測値は、メインの分布ベルの左側にあります。 これらの外れ値を取り除くために、損失変数のすべての値を右に200ポイント(損失+ 200)シフトし、それらから対数を取ることができます。
カテゴリー変数のコーディング
ほとんどの機械学習アルゴリズムは、カテゴリー変数を直接使用できません。 XGBoostも例外ではないため、カテゴリ変数を数値に変換する必要があります。 ここでは、ラベルエンコーディングまたはワンホットエンコーディングの2つの標準戦略のいずれかを選択できます。 使用する戦略は重要なポイントですが、ここではいくつかの要因を考慮する必要があります。
直接コーディング(ワンホットエンコーディング)は、カテゴリ属性を操作する基本的な方法です。 スパースマトリックスを生成します。新しい列はそれぞれ、1つの属性の1つの可能な値を表します。 116個のカテゴリ変数があり、cat116は326個の値をとるため、膨大な数のゼロを持つスパース行列を取得できます。 これにより、トレーニング時間が長くなり、メモリコストが増加し、結果が低下することさえあります。 直接コーディングの別の欠点は、カテゴリの順序が重要な場合の情報の損失です。
一方、 ラベルエンコーディングは 、0からクラス1の数までの値のみが含まれるように、入力列を単純に正規化します 。 多くの回帰アルゴリズムでは、これは良い戦略ではありませんが、XGBoost はそのような変換を非常にうまく処理できます。
XGBoostの場合、LabelEncoderを使用して入力を正規化します。 多層パーセプトロンの場合、ダミー変数を作成する必要があるため、ここでの選択はワンホットエンコーディングです。
モデルの実装と改善
前述のように、機械学習を実装するための方法論は2つのセクションに分けられます。
•基本モデル(ゼロレベルモデル)のトレーニング、調整、および交差検証:XGBoostと、これらの2つのモデルでは少し異なる予備データ準備を既に実行したという仮定の下での多層パーセプトロン。 違いは、属性のエンコード(直接エンコードまたはラベルエンコード)と(残念ながら)多層パーセプトロンモデルのターゲット変数の対数変換がない場合です。 このパートの結果は2つの調整されたモデルになり、その結果は確立された基準を満たします。
•レベル1モデル、つまりオーバーレイモデルのトレーニングと検証。このセクションの結果は、以前にトレーニングした基本的なゼロレベルモデルのそれぞれよりも優れた結果を提供する新しいメタモデルになります。
次に、各セクションの詳細な概要を説明します。
セクション1.ゼロレベルモデル:トレーニング、チューニング、クロス検証
XGBoostモデルトレーニング方法(Analytics VidhyaのXGBoostチューニングガイドの適合バージョン):
1.パラメーターnum_boost_round = 50、max_depth = 5で浅くシンプルなモデルをトレーニングしましょう。 MAE = 1219.57。そのような結果を下限として設定し、モデルを調整することでそれを改善します。
2。ハイパーパラメーターの最適化を促進するために、XGBoost上に構築された独自のクラスXGBoostRegressorを実装します。このクラスは、概して、モデルが機能するために必要ではありませんが、scikit-learnで実装されたGridSearchCVグリッド検索を使用する場合、多くの利点を提供します(独自の損失関数を使用し、最大化する代わりにこの関数を最小化できます)。
3.学習速度と、グリッド上での以降の各検索に含まれるツリーの数を決定して修正します。私たちのタスクは最短時間で良い結果を得ることであるため、少数のツリーと高い学習速度を配置します:eta = 0.1、num_boost_round = 50。
4。パラメーターmax_depthおよびmin_child_weightを設定します。これらのハイパーパラメーターを一緒に構成することをお勧めします。 max_depthの増加は、モデルの複雑さを増加させます(そして再訓練の可能性を増加させます)。同時に、min_child_weightは正則化パラメーターとして機能します。次の最適なパラメーターを取得します:max_depth = 8、min_child_weight = 6。これにより、MAE = 1219.57からMAE = 1186.5に結果が改善されます。
5.ガンマ、正則化パラメーターを構成します。
6.各ツリー(colsample_bytree、subsample)で使用されるトレーニングの兆候と要素の数の比率を構成します。次の最適な構成を取得します:subsample = 0.9、colsample_bytree = 0.6、結果をMAE = 1183.7に改善します。
7。 , ( num_boost_round) eta. . 200 , eta=0.07 MAE=1145.9.
Grid Search 4 ( ):
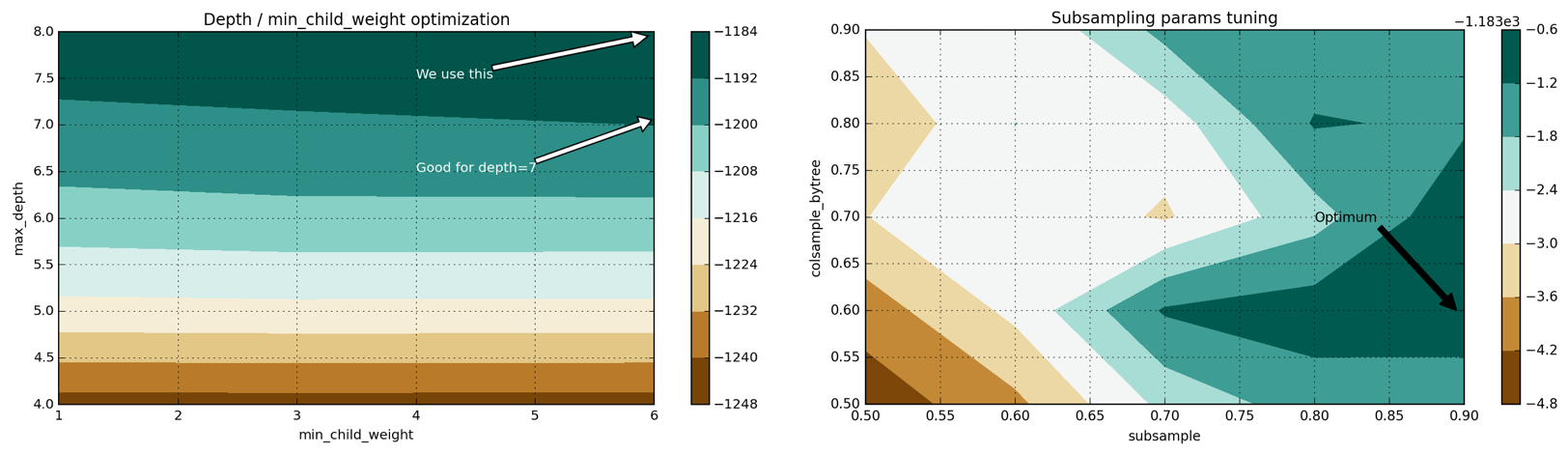
4: max_depth–min_child_weight colsample-subsampling
:
1.簡単なものから始めて、単一の隠れ層(2層)、ReLUアクティベーション関数、および勾配降下法を実装するAdamオプティマイザーで基本モデルを構築しましょう。このような浅いモデルは再トレーニングが困難で、すぐに学習して適切な初期結果が得られます。変位と分散の間の妥協点に関して、それらは変位モデルですが、それらは安定しており、そのような単純なモデルに対してまともな結果MAE = 1190.73を与えます。
2. k-fold cross-validationを使用して、より深いモデルのパフォーマンスを測定し、再トレーニングを視覚化します。 3層モデルをトレーニングし、簡単に再トレーニングする傾向があることを示します。
3。3層モデルに正則化を追加します:ニューロンのシャットダウン(ドロップアウト)と早期停止(早期停止)。後続の手動テスト用にいくつかの可能な構成を定義します。これらの構成は、非表示要素の数とニューロンをオフにする確率が異なります。これらのモデルをトレーニングし、相互検証によって得られた結果を検討および比較し、最適なものを選択します。実際、このアプローチでは、改善は得られません。2層モデルと比較した結果は悪化するだけです。このような結果は、多層パーセプトロンの正則化に対する手動の(そしてそれにより不正確な)アプローチによって引き起こされる可能性があります。レイヤーの妥当な蒸着強度を決定するだけですが、選択した強度が最適であるという保証はありません。
4。Hyperoptを導入して、自動化されたよりインテリジェントな方法でハイパーパラメーターのスペースを検索します(評価Parzenアルゴリズムのツリーであるtpe.suggestを使用します)。さまざまなニューロンの損失、層の構成、隠れた要素の数を含むハイパーパラメーターの多数の構成で、Hyperoptのいくつかの反復を実行します。最後に、adadeltaオプティマイザー、パケット正規化(バッチ正規化)、およびニューロンの損失を伴う4層アーキテクチャー(3つの隠れ層)を使用するのが最適であることがわかります。
多層パーセプトロンの

最終アーキテクチャ :図5:多層パーセプトロン
の最終アーキテクチャ交差検証に関するこのモデルの結果は次のとおりです。MAE= 1150.009。
セクション2.第1レベルモデルのトレーニング
これまでに、ゼロレベルモデル(XGBoostと多層パーセプトロン)のトレーニングと調整を行ってきました。このセクションでは、(真の値がわかっている)ゼロレベルモデルのクロス検証で作成された予測からのデータセットと、メタモデルの品質の最終評価に使用されるゼロレベルモデルの予測のテストサンプルをコンパイルします。
モデルのアンサンブルを構築するプロセスを完全に理解するには、このファイルを参照してください。
私が使用したアンサンブル構築方法論を以下に説明します。
• ステップ1.遅延データセットの新しいトレーニングと生成。結果をKaggleに送信せず、「リーダーボードを破る」こともしないため、トレーニングサンプルをトレーニングとテストの2つの部分に分ける必要があります。トレーニングサブサンプルは、k分割パーティションを使用した交差検証のゼロレベルモデルの予測を生成するために使用されますが、遅延データセットは、2つのゼロレベルモデルとメタモデルのパフォーマンスの最終評価にのみ使用されます。
• ステップ2:パーティション分割。トレーニングセットをk個の部分に分割します。これは、ゼロレベルモデルのトレーニングに使用されます。
• ステップ3:相互検証の予測。K-1パーツで各ゼロレベルモデルをトレーニングし、残りのパーツの予測を作成します。すべてのKパーツに対してこのプロセスを繰り返します。最後に、テストサンプル全体(タグもあります)の予測を取得します。
• ステップ4:サンプル全体のトレーニング。トレーニングデータセット全体で各ゼロレベルモデルをトレーニングし、テストセットの予測を取得します。得られた予測から新しいデータセットを作成します。各符号は、ゼロレベルモデルの1つの予測です。
• ステップ5:第1レベルモデルのトレーニング。レベル1モデルのマークとしてトレーニングセットの対応するマークを使用して、クロス検証中に取得した予測の第1レベルモデルをトレーニングします。その後、ゼロレベルモデルの予測のデータの組み合わせセットを使用して、第1レベルモデルの最終予測を取得します。
最初のレベルのモデルとして、線形回帰を選択します。メタモデルは簡単に再トレーニングされます(そして、率直に言って、競争では、メタモデルとしての単純な線形回帰よりもうまく機能しませんでした)。このオーバーレイは非常にうまく機能し、結果が大幅に改善されました。非表示のデータセットでゼロレベルモデルと最終的なアンサンブルモデルを相互検証した後、次の結果が得られました。
MAE XGBoost: 1149.19888471 MAE : 1145.49726607 MAE : 1136.21813333
モデルの重複MAE = 1136.21の結果は、アンサンブルの最高のモデルの結果よりも顕著に優れています。 もちろん、この結果はさらに改善できますが、このプロジェクトでは、モデルの予測能力を高めることとトレーニング時間を短縮することの間で妥協します。
説明:この結果セットは、相互検証ではなく、遅延選択で計算されました。 したがって、クロスバリデーションで得られた結果を遅延データセットの結果と直接比較する権利はありません。 ただし、保留中のデータセットには、予想どおり、データセット全体の分布に近い分布があります。 これが、オーバーレイがパフォーマンスを本当に改善したと主張できる理由です。
補足として、ゼロレベルモデルがオーバーレイにどのような重みを付けたのかを知ることは興味深いでしょう。 線形回帰では、最終予測は単純に重みと初期予測の線形結合です。
PREDICTION = 0.59 * XGB_PREDICTION + 0.41 * MLP_PREDICTION
パート4.結果
モデルの評価と検証
結果を評価するために、データセットのさまざまなサブセットで最終モデル(個々およびアンサンブル)をトレーニングおよび検証します。 したがって、モデルの安定性、および初期トレーニングサンプルに関係なく安定した結果を得ることができるかどうかを確認できます。 これらの目標を達成するために、 Stacking Notebookドキュメントからmodules / stacker.pyクラスへのモデルのオーバーラップを一般化します。これにより、異なるsidでモデルの評価手順をすばやく呼び出すことができます(モデルが互いにわずかに異なるように)。
5つの異なるsidを使用して、ゼロおよび最初のレベルのモデルをトレーニングし、結果を表に書き込みます。 次に、pd.describeメソッドを使用して、各モデルの集計パフォーマンス統計を取得します。 ここで最も特徴的なメトリックは、平均(平均)と標準偏差(std)です。

ご覧のとおり、モデルは非常に安定しており(標準偏差が低い)、アンサンブルは常に他のどのモデルよりも優れています。 その最低の結果は、最良の個々のモデルの最高の結果よりも優れています(MAE = 1132.165対MAE = 1136.59)。
もう1つの説明:モデルを慎重にトレーニングして検証しようとしましたが、まだ気付かないまま情報漏えいの余地があるかもしれません。 すべてのモデルは、1つのそのようなリークによって引き起こされる可能性のある結果の改善を示しています(ただし、5つのモデルのみをトレーニングしました。パラメーターseed = 0は、単に悪い結果を与える可能性があります)。 それでも、最終的な結論は引き続き有効です。 さまざまなSIDでトレーニングされた複数のオーバーレイを平均すると、最終結果が向上します。
正当化
基本的な結果は次のとおりです。MAE= 1217.52(Allstateのランダムフォレストモデル)およびMAE = 1190.73(MAE単純多層パーセプトロン)。 最終モデルでは、最初の結果が7.2% 、 5.1%改善されました(2番目)。
これらの結果の重要性を測定するために、各基本結果を前のセクションで取得した結果の表に追加し、基本結果が異常と呼ばれるかどうかを調べます。 そのため、ベースラインの結果を排出量とみなすことができる場合、最終結果とベースラインの結果の差は大きくなります。
このテストを実行するために、異常と異常値の検出に使用されるIQR(四分位範囲)を計算できます。 次に、3番目のデータ変位値(Q3)を計算し、式Q3 + 1.5 * IQRを使用して、結果の上限を設定します。 この制限を超える値は外れ値と見なされます。 このテストを実施すると、両方の基本的な結果が外れ値であることがわかります。 したがって、オーバーレイモデルはベースコントロールポイントをはるかに超えていると言えます。
for baseline in [1217.52, 1190.73]: stacker_scores = list(scores.stacker) stacker_scores.append(baseline) max_margin = np.percentile(stacker_scores, 75) + 1.5*iqr(stacker_scores) if baseline - max_margin > 0: print 'MAE =', baseline, ' .' else: print 'MAE = ', baseline, ' .'
出力では次のようになります。
MAE = 1217.52 . MAE = 1190.73 .
パート5.結論
自由形式の視覚化
詳細から抽象化し、プロジェクト全体を見てみましょう。 XGBoostと多層パーセプトロンの2つの主要モデルをトレーニングおよび最適化しました。 最も単純なモデルから、調整された、より安定した複雑なモデルまで、多くのステップを踏んでいます。 その後、レベル1モデルの線形回帰予測、線形回帰を作成し、スタッキング手法を使用してゼロレベルモデルの予測を結合しました。 最後に、スタッキングのパフォーマンスを検証し、5つのバリエーションをトレーニングしました。 これら5つのモデルの結果を平均すると、最終結果はMAE = 1129.91になりました。
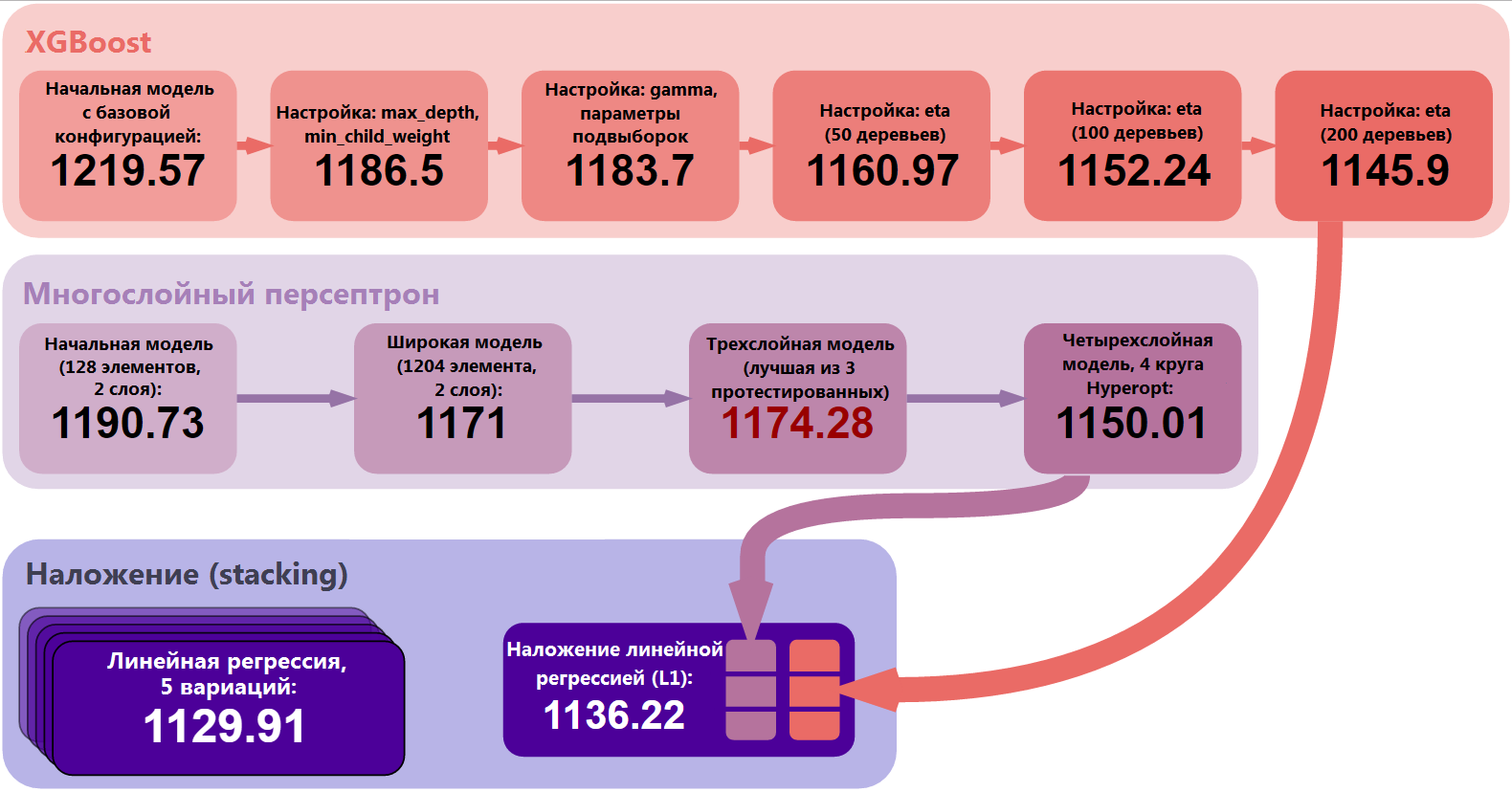
図6:結果を改善するための重要なステップ
もちろん、ゼロレベルにもっと多くのモデルを含めることも、それらのアンサンブルをより複雑にすることもできます。 可能な方法の1つは、いくつかの完全に異なるアンサンブルをトレーニングし、それらの予測を(たとえば、線形結合として)新しいレベルのレベル2で結合することです。
完了した作業の分析
問題の完全な解決策
このプロジェクトのアイデアは、新しい特性の作成を必要としないデータセットを使用することでした。 そのようなデータセットを持つことは非常に素晴らしいです、なぜなら これにより、データの前処理やアルゴリズムの変更ではなく、アルゴリズムとその最適化に集中できます。 もちろん、XGBoostとニューラルネットワークの動作をテストしたかったので、選択したデータセットは、他のKaggle参加者の結果と比較して、モデルの品質の優れた基本的な評価を与えることができました。
プロジェクトで提示された脆弱なモデルを使用しても、基本結果がかなり過剰になり、 7.2%増加しました 。 基本結果を最終結果と比較し、最終結果が実際に大幅な改善であることを確認しました。
難しさ
このプロジェクトは簡単ではありませんでした。 新しい属性の作成、次元の削減、データの強化など、データセットに対する特別なまたは創造的なアプローチは示しませんでしたが、Kaggleに必要なモデルの計算の複雑さは予想よりも高くなりました。
Allstate Claims Severityの主な問題は、コンピューティングの再現性でした。 それを保証するために、多くの予備的な要件を満たす必要がありました:結果を得るプロセスは明確であり、計算-決定論的(または少なくとも限られた変動で)であり、現代の機器で合理的な時間に再現可能でなければなりませんでした。 その結果、既存のモデルの複雑さを大幅に削減し、いくつかの手法を完全に排除しました(たとえば、XGBoostおよび多層パーセプトロンのバギング手法を除外しましたが、これらのモデルをバギングした後、著しく良い結果が得られました)。
このプロジェクトは、主にAmazon Web Servicesインフラストラクチャで行われました。マルチレイヤーパーセプトロン(NVIDIA Tesla K80 GPU、12 GB GPUメモリ)のGPUコンピューティングを使用したp2.xlargeインスタンスと、XGBoost(36 vCPU、 60 GBのメモリ)。 私のプロジェクトには、重い計算を必要とするいくつかのセクションがあります。
•グリッドで検索。 XGBoostセクション内のすべてのグリッドを反復処理するには、多くの時間がかかります。 通常のコンピューターでは、XGBoostに必要なすべての計算に1〜2時間かかる場合があります。
•多層パーセプトロンモデルの相互検証。 残念ながら、多層パーセプトロンのトレーニングで交差検証を加速する魔法の方法はありません。 交差検証は、モデルの品質を評価するための信頼できる方法です。それを避けるべきではありませんが、十分な時間を確保する必要があります。
•ハイパーパラメーターの最適化。 これは間違いなくすべての計算の中で最も難しい部分です。 Hyperoptのさまざまな組み合わせを検索し、Hyperoptを使用して適切な組み合わせを見つけるには何時間もかかります。
•多層パーセプトロンとXGBoostの相互検証予測の生成。
結果を再現する最良の方法は、事前にトレーニングされたモデルを最初に実行し、次に最も簡単なモデルのいくつかを再集計することです。
機能強化
プロジェクトには、将来の改善のための十分な余地が残されています。 以下では、他にどのような改善方法を使用できるかを考えます。
データの前処理
1.最初に多層パーセプトロンのモデルで作業を開始し、その後初めてターゲット変数の対数を使用する手法を発見しました。 その結果、私の多層パーセプトロンは対数変換なしで訓練されました。 もちろん、ターゲット変数を対数化し、すべての多層パーセプトロンモデルを再トレーニングできます。
2.ターゲット変数を変換する有望な方法は、200ポイント右にシフトすることです(すべての値に200を追加します)。 このようなシフトを行ってから対数を取ると、ターゲット変数の分布密度関数の左側にある外れ値が取り除かれます。 したがって、分布を正規に近づけます。
XGBoost
1.ツリーを追加し、同時にetaパラメーターを減らして、より洗練されたXGBoostモデルをトレーニングします。 私の作業モデルでは、28000本の木とeta = 0.003を使用します。これは、グリッド検索手順を使用して決定されました。
2. num_boost_roundの代わりにearly_stopping_roundsを使用して、学習を停止し、モデルの過剰適合を回避します。 この場合、etaを小さな数に設定し、num_boost_roundを非常に大きく設定します(最大10万)。 この場合、検証サンプルを準備する必要があることを理解する必要があります。 その結果、モデルのトレーニング用データが少なくなり、パフォーマンスが低下する可能性があります。
3.ハイパーパラメーターの他の値でグリッド検索を開始します。 0と0.5の間のcolsample_bytreeの値をテストできるとしましょう。多くの場合、良い結果が得られます。 ここでの考え方は、ハイパーパラメーターの空間にいくつかの局所的な最適値があり、それらのいくつかを見つける必要があるということです。
4.異なるハイパーパラメーターでトレーニングされた複数のXGBoostモデルを組み合わせます。 これを行うには、モデルの結果を平均化し、ブレンドおよびスタックします。
多層パーセプトロン
1.バギング手法を使用して、同じモデルの複数の多層パーセプトロンを平均化します。 モデルは確率論的であるため(たとえば、ニューロンの損失=ドロップアウトを使用するため)、バギングにより作業がスムーズになり、予測能力が向上します。
2.より深いネットワークアーキテクチャ、他の要素構成、およびハイパーパラメーター値を試してください。 勾配降下法に従って動作する他のオプティマイザーをテストし、レイヤーの数、各レイヤーの要素の数を変更できます-Hyperoptのすべての力は私たちの手にあります。
3.既知の手法を使用して、いくつかの異なる多層パーセプトロンを組み合わせます (たとえば、2層、3層、および4層のニューラルネットワークをトレーニングします)。 これらのモデルは、さまざまな方法でデータ空間をカバーし、ベースラインの結果よりも改善されます。
相互検証
3つの部分に分割する単純な相互検証を使用する代わりに(5つの部分に分割を使用することもあります)、10の部分に相互検証することができます。 このような相互検証は、Kaggle競技に適していますが、ほぼ確実に結果が向上します(トレーニングデータが増えます)。
スタッキング
1.ゼロレベルモデルをさらにアンサンブルに追加できます。 まず、より多くの多層パーセプトロンとXGBoostモデルを単純にトレーニングできますが、それらは互いに異なる必要があります。 たとえば、これらのモデルをさまざまなデータのサブセットでトレーニングできます。一部のモデルでは、さまざまな方法でデータを前処理(損失)できます。 次に、完全に異なるモデルを導入できます。LightGBM、k個の最近傍アルゴリズム、因数分解マシン(FM)などです。
2.別のアイデアは、新しいオーバーレイレイヤーとして2番目のレイヤーを追加することです。 その結果、2レベルのスタッキングが得られます。ゼロレベルのリグレッサー(L0)があり、フォールド外予測ではいくつかの異なる第1レベルのメタモデル(L1)をトレーニングします。 次に、メタモデル予測(L2)の線形結合を取得し、最終グレードを取得します。
3. PCA-データマイニングについてラップトップで考慮された主要コンポーネントの方法を使用してみてください。 ここにいくつかのアイデアがあります。 まず、取得したコンポーネントをフォールドアウト予測と混合することができます。この予測では、メタモデルに追加情報を追加するために線形回帰(L1)がトレーニングされます。 第二に、すべての標識から重量の大きいもののみを選択でき、残りはノイズとして破棄されます。 これは、結果のモデルの品質を向上させるのにも役立ちます。
プロジェクト全体が実行された構成の説明、 ここ