
最終的に、Elasticsearchモニタリング機能をパブリックリリースに追加しました。 結果が私たちに合わず、ESクラスターでかき集めた問題が表示されなかったため、合計で3回再編集しました。
カットの下で、物語は私たちの生産クラスター、私たちの問題、そして新しいESモニタリングについてです。
エラスティックのスーパーショートコース
Elasticsearchは、Apache Luceneライブラリの上に構築された、分散型の自己拡張可能なRESTful全文検索サービスです。
ESの用語:
- ノード(ノード) -あるサーバーで実行されているJVMプロセス
- インデックス(インデックス) -検索するドキュメントのセット。インデックスには、いくつかの種類のドキュメントがあります。
- シャード -インデックスの一部。 インデックスは複数の部分に分割され、サーバー間でインデックスとそのリクエストを分散します
- レプリカはシャードのコピーです。 インデックスの各部分は、フォールトトレランスのために異なるサーバーの複数のコピーに格納されます。
内部では、各シャードはインデックスですが、すでにLuceneの用語では、セグメントに分割されています。
ESの使用方法
okmeter.ioのすべてのメトリックにはラベルがあります。つまり、システムのメトリック識別子はキー値辞書です。次に例を示します。
{name: net.interface.bytes.in, site: okmeter, source_hostname: es103, plugin: net, interface: eth1}
-
{name: process.cpu.user, site: okmeter, source_hostname: es103, plugin: process_info, process: /usr/bin/java, username: elasticsearch, container: ~host}
-
{name: elasticsearch.shards.count, site: okmeter, source_hostname: es103, plugin: elasticsearch, cluster: okmeter-ovh, index: monthly-metadata-2016-10, shard_state: active, shard_type: primary}
このような各メトリック識別子ディクショナリは、ESのドキュメントです。 たとえば、このようなスケジュールを作成するには
ESでこの(非常に単純化された)クエリを検索します
site:okmeter AND name:elasticsearch.index.size
cassandraからメトリックの値を取得するメトリックのid
返します。
クラスターの状態
ES自体は 、クラスターが次の3つの状態になる可能性があると考えています。
- 緑-各インデックスの各シャードの必要なコピー数が利用可能です
- 黄色-シャードの一部のコピーは移行状態にあるか、ノードに接続されていません
- 赤-インデックスの一部がまったく利用できません
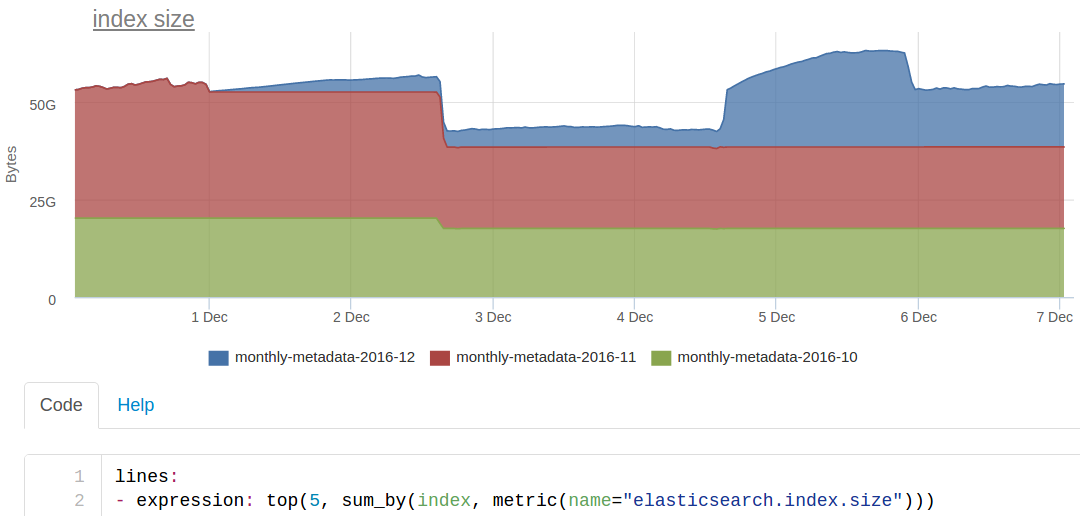
同じ条件に基づいて選択した標準ESダッシュボードのメインチャート:
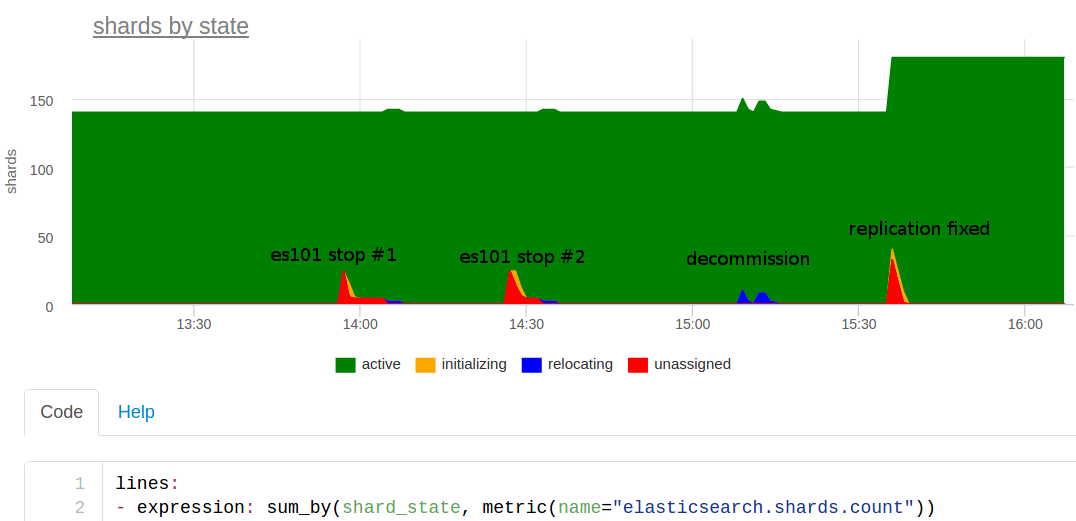
この日についてお話します。 前日、より強力なサーバーをクラスターに追加しましたが、2つの古いノードを削除する必要がありました。 午後2時ごろ、アイデアが浮かびましたが、演習を行う必要がありますか? 私たちは議論し、実験することが可能であると決定しました-1つのノードをオフにして、そのような弾性弾性がどのように機能するかを見てください。
彼らはそれをオフにし、すぐに監視が問題のメトリックコレクターを叫んだ。 なぜ?
彼らはノードを返し、少し待って、すべてがうまくいきました。 奇妙なことに、いくつかのエラスティックの1つがシャットダウンしたために横になることはありえません。 おそらく何か他のもの...
彼らは午後2時30分頃に再びノードをオフにしました-再びアラートを出しました。 うーん。 教えは、1つの弾性体の落下が私たちを傷つけることを示しました-これも結果ですが、私たちはそれを理解する必要があります。
彼らは一種の廃止措置を行いました。クラスターの1つにノードを注意深く表示しました。 15:10のグラフの青色は、破片が他のノードに移動したことです。 問題はありませんでした。
シャードの数を見てみると:140-奇妙なことに、20個のnumber_of_shards 、2個のnumber_of_replicas 、および別のマスターコピー、つまり インデックスごとに60個のシャードが必要です。 インデックス3-毎月独自のもの。つまり、シャードは180個だけです。 12月のインデックスはnumber_of_replicas -0で作成されたことがわかりました 。 レプリカがないため、ノードをオフにすると、このインデックスでの作業が完全に中断されます。
制御された実験でレプリカがないことがわかったのは良いことです。 これに気付かなかった場合、将来大きな問題が発生する可能性があります。メインストレージのデータを使用して完全なインデックスの再作成を行う必要があります。
将来この問題を確認するために、インデックスにレプリカが0個あるかどうかを通知する自動トリガーを作成しました。 このトリガーは一度にすべてのクライアントの自動トリガーとしてリリースされました。私たちは監視サービスです:)
スプリットブレイン
エラスティックで最も恐ろしくよく知られている問題は、ネットワーク上のノードの接続性の問題のため、またはノードが長時間応答しなかった場合(たとえば、GCでスタックしているため)、クラスタに2番目のマスターノードが表示される場合があるスプリットブレインです。
この場合、2つのバージョンのインデックスがあり、一部のドキュメントはクラスターの一部でインデックス付けされ、他のドキュメントは他の部分でインデックス付けされます。 検索中に矛盾が表示されます-同じリクエストに対して異なる結果が返されます。 この場合、インデックスを復元するのは難しい作業であり、ほとんどの場合、完全なインデックスの再作成、またはバックアップからの回復と、その後の現在の瞬間の変更のトッピングが必要になります。
ESにはスプリットブレイン保護メカニズムがあり、最も重要な設定はminimum_master_nodesですが、デフォルトではdiscovery.zen.minimum_master_nodes:1 、つまり 保護はありません。
ElasticSearchテストクラスターでこれを再現し、結果に基づいて2つの自動トリガーを作成しました:クラスター内に複数のマスターノードが見つかった場合は 1つが動作し、 discovery.zen.minimum_master_nodesが推奨クォーラム(N / 2 + 1)現在のクラスターサイズから。 ノードの追加を決定し、 minimum_master_nodesの修正を忘れることがあるため、これを監視する必要があります。
エラスティックでリクエストを監視する
クラスターの状態を把握した後、クラスターが処理するリクエストの数とそれらが処理する速度を理解する必要があります。
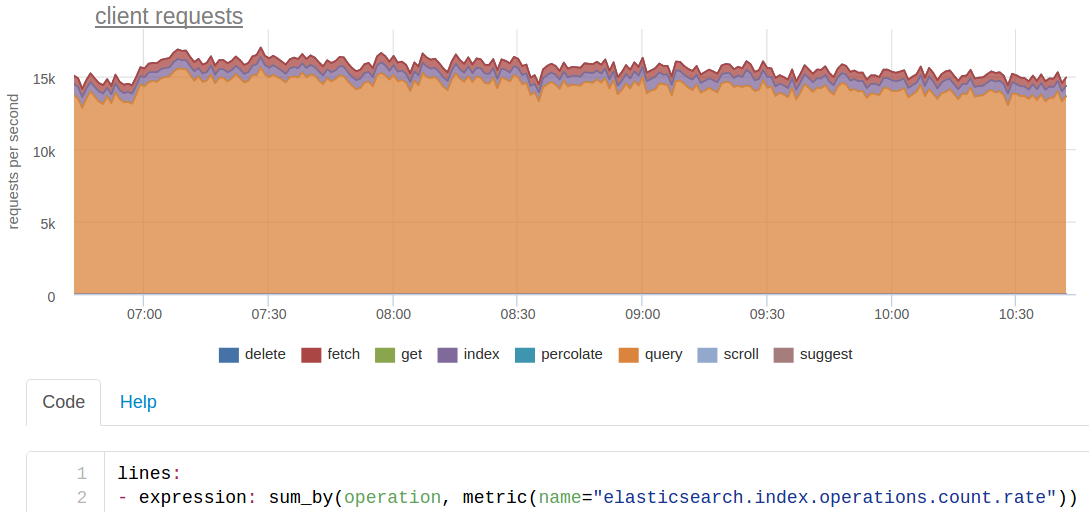
ESの検索は、それぞれが20個のシャードに分割されている3つのインデックスによって一度に行われます。 このため、ESのコードからの最初の〜250の検索クエリは毎秒〜15,000になります。
実際には約200のインデックス作成要求がありますが、各シャードは3つのコピー(メイン+ 2つのレプリカ)に格納されているため、ESは約600 rpsを認識します。
クエリ時間についてESはわずかな統計を提供します。処理されたリクエストのカウンターがあり、タイプごとのクエリ時間の累積合計があります。 したがって、各タイプのリクエストの平均応答時間のみを計算でき、このタイプのグラフを取得します(グラフを描画するときに直接応答時間の合計も興味深いメトリックなので、直接平均を計算します):
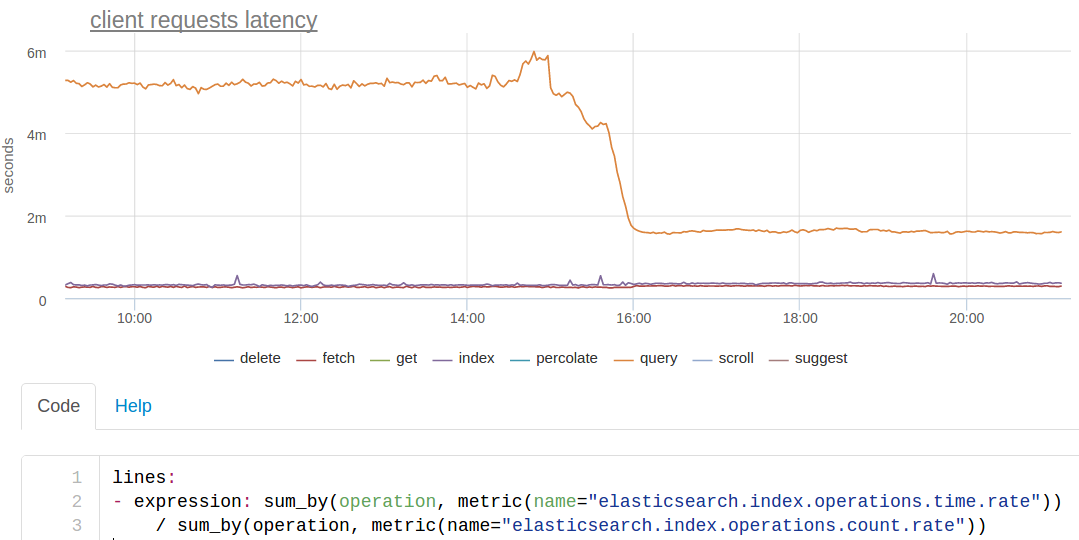
オレンジ色の線は検索です。 ある時点で約3倍加速したことがわかります。
セグメントを強制的にマージしました 。 インデックスは毎月カットされます。 現在の月に常に(ほぼ)インデックスが作成され、3か月間検索されます。 前の月のインデックスからの読み取りのみであるため、負荷がかかった状態でインデックスを強制的にマージすることができます。
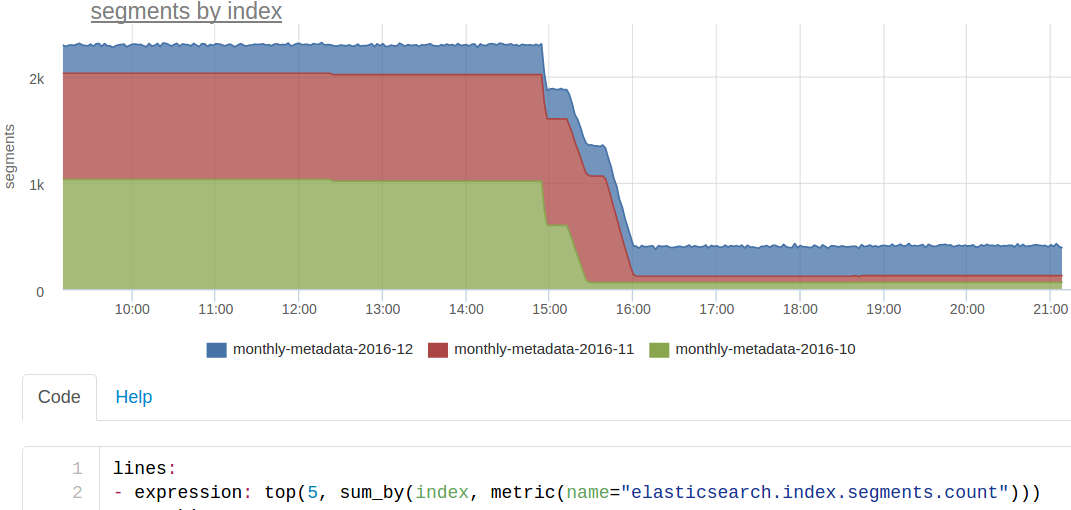
その結果、各シャードにはセグメントが1つしか残っていなかったため、これらのインデックスの検索は著しく高速になりました。 おそらく、私たちはクラウンを作るべきです。これは、先月のフォースマージインデックスを実行します。
バックグラウンドopsグラフィック
さらに、「バックグラウンド」操作を個別に導出しました-これは、エラスティックがバックグラウンド自体で、または強制マージのように要求に応じて行うことです。 これとは別に、「ユーザー」リクエストを「システム」とは別に表示する方が論理的であるため、ミリ秒ではなく秒という非常に異なるタイミングがあるため、1つのチャートを見るのは不便です。 また、このような操作の数は非常に少なく、すべてのユーザー要求の背景に対して失われる可能性があります。
このグラフは、私たちにとって検索応答時間を短縮したまさにマージを示していますが、今回はES応答時間の合計を見る方が便利です(クラスターのコンピューティングリソースが一般的に費やされたものを見るようなものです)。
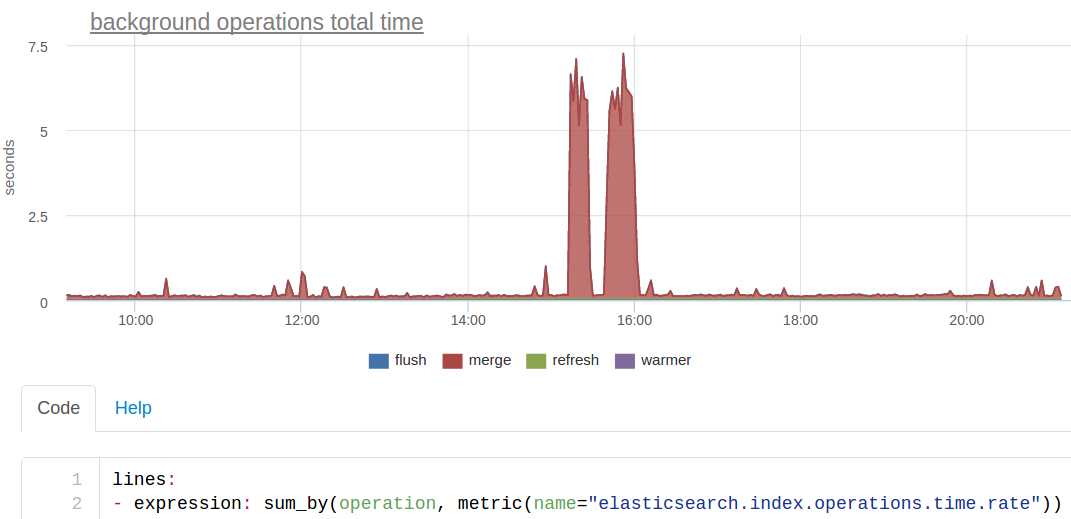
Linuxシステムメトリックの観点では、このマージはESプロセスによるディスクへのアクティブな書き込みのように見えました。

キャッシュ
エラスティックでクエリの実行速度を確保するために、キャッシュがあります:
- query_cache (以前はfilter_cacheと呼ばれていました )-要求内の特定のフィルターに一致するビットセットを文書化します
- fielddata_cache-集約に使用
- request_cache-シャードはリクエストに対するレスポンス全体をキャッシュします
キャッシュされるもの、キャッシュされる場合、無効化される場合、調整方法の詳細については、ドキュメントを読むことをお勧めします。
監視エージェントは、サイズ、ヒット、ミッション、エビクション(エクステント)の各キャッシュを削除します。
ここでは、たとえば、ケースがありました-私たちのエラスティックはOutOfMemoryによって落ちました。 ログを把握することは困難ですが、それらが既にそれを上げていたとき、グラフでフィールドデータキャッシュのメモリ使用量の急激な増加に気付きました。

実際、elasticsearch集計は使用せず、通常は最も基本的な機能のみを使用します。 スコアリングせずに、指定されたフィールドに値が指定されているすべてのドキュメントを見つける必要があります。 フィールドデータキャッシュの使用がこれほど大きくなったのはなぜですか?
これも制御された実験であることが判明しました:-) curlで重い集約リクエストを手動でプルし、すべてがそれから来ました。 理論的には、これはfielddataのメモリ制限を正しく設定することで保護できます。 しかし、それらが機能しなかったか、エラスティックのバグのいずれかでした(その後、古いバージョン1.7に座っていました)。
システム指標
エラスティックの内部メトリックに加えて、オペレーティングシステムのプロセスとして、上からそれを見る価値があります。 CPU時間、メモリ、ディスクに負荷をかける量を消費します。
バージョン1.7.5からESの更新を開始したとき、すぐに2.4(最後の5つ、恐れている間)にアップグレードすることにしました。 標準的な手順に従って、なんらかの大きな弾力的な更新を行うことができます。通常、2番目のクラスターを上げて、コードを介して同期コピーを作成します。
新しいクラスターをインデックスに含めると、新しいESはディスクに約350回/秒書き込み、古いクラスターは約25回書き込みます:
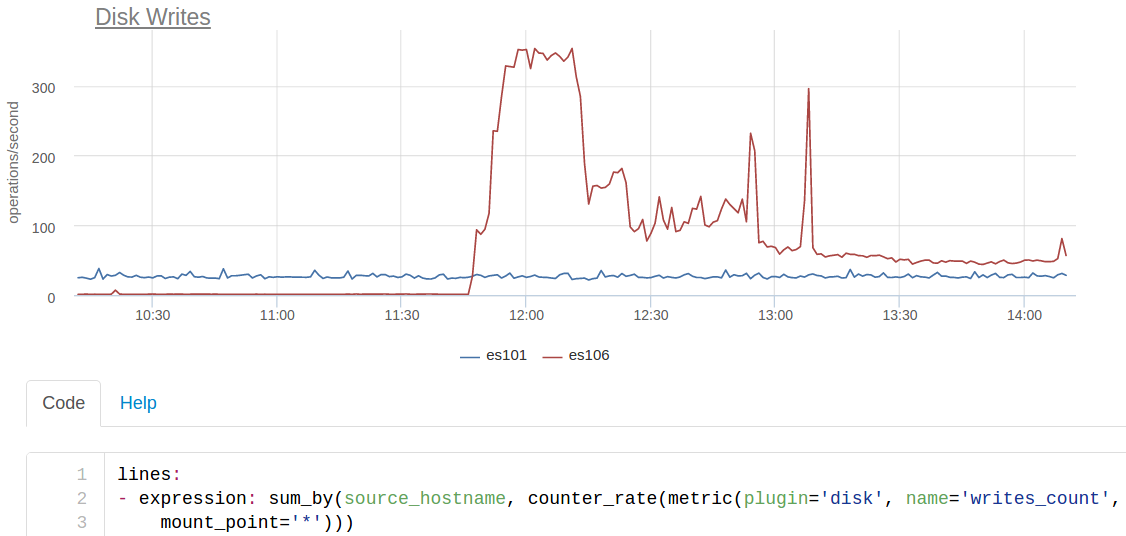
es101は古いクラスターのノードで、es106は新しいクラスターのノードです。 さらに、SSDを新しいノードに配置しなかったため(すべてがメモリに収まると考えていたため)、このioはパフォーマンスを大幅に低下させました。
エラスティックのバージョン2のすべてのニュースを読み直し、index.translog.durabilityを見つけました 。 デフォルトではrequestになり、この値では各インデックスリクエストの後にtranslogがディスクにクラッシュします。 5秒で標準のsync_intervalを使用して非同期に変更され、ほぼ以前のようになりました。
ESのシステムメトリックに加えて、gc、メモリプールなどのJVMメトリックを確認すると便利です。 エージェントはjmxを介してすべてを自動的に取得し、グラフも自動的に表示されます。
ES自動検出
少し前までは、クライアントのサーバー上のすべてのサービスが構成なしで自動的に監視に含まれるようにすることに多大な努力を費やしていると既に述べました。 このアプローチにより、何かを監視することを忘れずに実装を大幅に加速できます。
ESの自動検出は次のようなものです。
- プロセスのリストから、ESに似たプロセスを見つける:jvmスタートアップクラスorg.elasticsearch.bootstrap
- 起動ラインでES設定を見つけようとします
- 設定を読み、リッスンIPとポートを理解する
さらに、技術的な問題-標準APIを使用して定期的にメトリックを削除し、クラウドに送信します。
結論の代わりに
私たちは常に実際のユースケースから進めようとします。 サービスの監視を切り詰めるには、サービスに徹底的に対処し、何がどのように破壊されるかを理解する必要があります。 したがって、まず第一に、私たちはよく調理する方法を知っており、自分で使用するサービスをサポートしました。
さらに、問題について話す顧客は非常に役立ちます。 ダッシュボード/自動トリガーを絶えず変更し、最終的にいくつかのグラフではなく、すぐに問題の原因を表示します。
監視されるのを待っているESがある場合は、2週間の無料トライアルが必要です。サイトへのリンクはすぐ下にあります:)