
ルシアーノについて冗談を言わないようにほとんど拘束されていない)
たとえば、Caffeは人気のある深層学習ニューラルネットワーク開発プラットフォームです。 Berkley Vision and Learning Center(BVLC)で作成され、その開発に貢献する独立した開発者のコミュニティに好まれました。 プラットフォームは存続し、開発されています。これの証拠は、GitHubのプロジェクトページの統計です。 Caffeは「ディープラーニングのための高速でオープンなプラットフォーム」と呼ばれています。 このような「クイック」ツールセットを高速化することは可能ですか? この質問をして、CaffeをIntelアーキテクチャ向けに最適化することにしました。
今後、Caffeは、Intel Math Kernel Library 2017との統合と、 この記事で概説した計画に従って実行した一連の最適化のおかげで、ベースバージョンよりも10倍以上高速なIntelプロセッサで動作し始めたことに注意してください以下、BVLC Caffeと呼びます。 Intelアーキテクチャ向けに最適化されたバージョンは、簡潔にするためIntel Caffeと呼ばれます。 ソースコードは次のとおりです。
パフォーマンスの改善の主な分野(詳細は以下で説明します)は、コードのリファクタリング、Intel AVX2などのベクトル命令セットの使用に基づく最適化、コンパイルの微調整、およびOpenMPを使用したマルチスレッドコード実行の効率化です。 テストは、2つのIntel Xeonプロセッサを搭載したシステムで実施されました。 特に、CIFAR-10セットの画像を操作する際に、Caffeツールによって構築されたニューラルネットワークの速度を調査しました。 プログラムの実行結果は、Intel VTune Amplifier XE 2017および他のツールを使用して分析されました。
同様のアプローチを使用して、さまざまなプログラム(ニューラルネットワークの深層学習用の他のプラットフォームなど)のパフォーマンスを向上させることができます。
最適化の問題に進む前に、ディープラーニングアルゴリズムとそれらの助けを借りて解決されるタスクについて説明します。
深層学習アルゴリズムについて
ディープラーニングアルゴリズムは、より一般的なクラスの機械学習アルゴリズムの一部であり、近年、写真やビデオのパターン認識、音声認識、自然言語処理、および大量の情報を処理する必要がある他の分野で重要な結果を示していますデータ分析の問題を解決します。 ディープラーニングの成功は、大規模なデータセットを処理する能力におけるコンピューティングとアルゴリズムの最新の進歩に基づいています。 このようなアルゴリズムの動作原理は、データがネットワークレイヤーを通過し、そこで情報が変換され、さらに複雑な機能がそこから抽出されるということです。
ディープニューラルネットワークの各レベルをトレーニングして、さらに複雑な兆候を特定する方法の例を次に示します。 これは、グレースケール画像として視覚化された、深いネットワークによって認識される機能の小さなセットを示しています。 また、元のカラー画像も表示され、その処理によりこれらの標識が選択されます。 ここから撮影した画像。

畳み込みニューラルネットワーク
ディープラーニングアルゴリズムを教師と連携させるには、ラベル付きデータセットが必要です。 教師が教える3つの一般的なタイプのディープニューラルネットワークは、多層パーセプトロン(MLM)、畳み込みニューラルネットワーク(CNN)、およびリカレントニューラルネットワーク(RNN)です。 これらのネットワークでは、入力データは、ネットワークの各レイヤーを通過するときに、一連の線形および非線形変換を受けます。 その結果、ネットワーク出力データが生成されます。 ネットワーク応答が予想される結果と比較され、エラーが検出された後、出力層に対してエラー表面勾配ベクトルが計算され、活性化関数を考慮して、ニューロンのシナプス重みのネットワークへの寄与が考慮され、その後、同じ手順が他の層に対して実行されます以前に受信したデータ。 このトレーニング方法はエラー逆伝播アルゴリズムと呼ばれ、その適用の結果として、ネットワークニューロンの重み係数の段階的な変更が実行されます。
多層パーセプトロンでは、各レイヤーの入力データ(ベクトルで表される)に、そのレイヤーに固有の完全に満たされたウェイトマトリックスが最初に乗算されます。 リカレントネットワークでは、このようなマトリックスは各レイヤーで同じであり(レイヤーがリカレントであるため)、ネットワークのプロパティは入力信号に依存します。 畳み込みネットワークは多層パーセプトロンに似ていますが、畳み込みネットワークと呼ばれる隠れ層にスパース行列を使用します。 このようなネットワークでは、行列乗算は、重みの行列表現とレイヤーの入力データの行列表現の畳み込みによって表されます。 畳み込みネットワークは画像認識で一般的ですが、音声認識や自然言語の処理に応用できます。 ここでは、そのようなネットワークについて詳しく読むことができます。
Caffe、CIFAR-10および画像分類
既に述べたように、ここでは、ディープラーニングネットワークを作成および探索するための一般的なプラットフォームであるIntel BVLC Caffeのアーキテクチャを最適化します。 画像分類タスクでよく使用されるCIFAR-10データセットとCaffeで構築されたニューラルネットワークモデルを使用して、プラットフォームの初期バージョンと最適化バージョンをテストします。

CIFAR-10セットの画像例
CIFAR-10データセットは、サイズが32x32ピクセルの60,000色の画像で構成され、飛行機、車、鳥、猫、鹿、犬、カエル、馬、船、トラックの10クラスに分けられます。 クラスは交差しません。 たとえば、クラス「車」と「トラック」の間に重複はありません。 「車」には、たとえばセダンやSUVが含まれます。 「トラック」クラスには大型トラックのみが含まれ、たとえば、ピックアップトラックはどの画像グループにも含まれていません。
パフォーマンステスト中に使用されるネットワークには、さまざまなタイプのレイヤーが含まれます。 特に、これらはシグモイド活性化機能を持つ層(Caffeの用語では、シグモイド型の層)、畳み込み層(畳み込み型)、空間結合層、またはサブサンプル層(プール型)、バッチ正規化層( BatchNormタイプ)、完全に接続されたレイヤー(InnerProductタイプ)。 ネットワークの出力には、アクティベーション関数Softmax(タイプSoftmaxWithLoss)を持つレイヤーがあります。 このネットワークとそのレイヤーについては、以下で詳しく説明します。 それでは、Caffeのオリジナルバージョンの分析に取りかかりましょう。
初期性能分析
BVLC CaffeとIntel Caffeのパフォーマンスを評価する方法の1つは、 timeコマンドを使用することです。これは、信号がレイヤーを順方向および逆方向に移動するのにかかる時間を計算します。 このコマンドは、各レベルで計算に費やされた時間を測定し、異なるモデルの比較実行時間を取得するのに非常に便利です。
./build/tools/caffe time \ --model=examples/cifar10/cifar10_full_sigmoid_train_test_bn.prototxt \ -iterations 1000
この場合、「反復」( 反復パラメーターを設定する)は、画像パケットを1回前方および後方に通過することです。 上記のコマンドは、個々のレイヤーとネットワーク全体の両方について、1000回の反復の平均実行時間を表示します。 BVLC Caffeのこのチームの結果は次のとおりです。

BVLC Caffeの時間コマンド出力
テストでは、2つのソケットを持つシステムを使用しました。 それぞれに、18個の物理コアを持つIntel XeonプロセッサーE5-2699 v3(2.3 GHz)がインストールされました。 同時に、Intel Hyper-Threading Technologyは無効になりました。 したがって、システムには36個の物理プロセッサコアと、 OMP_NUM_THREADS環境変数を使用して設定された同数のOpenMPスレッドしかありませんでした。 特に明記しない限り、このような構成のみが実験で使用されました。 Intel CaffeがOpenMP環境変数を自分で設定するのではなく、自動的に設定できるようにすることをお勧めします。 システムには、64 GBのDDR4メモリも搭載されており、2.133 MHzの周波数で動作します。
ここでは、Intelエンジニアによるコードの最適化のおかげで達成されたパフォーマンステストの結果を見ることができます。 パフォーマンスを測定するために、次のツールを使用しました。
- ValgrindツールキットからのCallgrind。
- Intel VTune Amplifier XE 2017ベータ版。
Intel VTune Amplifier XEのツールは、次の情報を提供します。
- システムに最大の負荷をかける機能(ホットスポット)。
- システムコール(タスクスイッチングを含む)。
- CPUおよびキャッシュの使用。
- OpenMPストリーム間の負荷分散。
- スレッドロック。
- メモリ使用量。
パフォーマンス分析を使用して、システムに大きな負荷をかける関数や、完了するまでに比較的長い時間を要する関数の呼び出しなど、最適化の適切な候補を見つけることができます。
次の図は、100回の反復後に得られたIntel VTuneのBVLC Caffeのパフォーマンス分析の概要を示しています。 図の上部にある経過時間インジケータは37秒です。 これは、テストシステムでコードを実行するのにかかった時間です。 CPU時間インジケータ、プロセッサ時間は1306秒です。 これは、37秒に36コア(1332秒)を掛けた値よりわずかに小さいです。 このインジケーターは、計算で使用されるすべてのスレッド(または、インテルHTテクノロジーが無効になっているため、すべてのコア)でのコード実行の合計期間を表します。

Intel VTune Amplifier XE 2017ベータ版のCIFAR-10データセットでのBVLC Caffeパフォーマンス分析の一般的な結果
図の下部にあるプロセッサ使用率のヒストグラムは、テスト中に特定の数のスレッドが同時にアクティブ化される頻度を示しています。 この場合、37秒のうち、14が1つのスレッド(つまり、1つのコア)に落ちます。 残りの時間では、非常に非効率的なマルチスレッド処理が見られますが、基本的には20スレッド未満が作業に参加しています。
図の中央にある[上位のホットスポット]セクションには、最も多くの機能を占める機能が示されます。 関数呼び出しと、それぞれの合計プロセッサー時間に対するそれらの寄与がここにリストされています。 kmp_fork_barrier関数は、コードを実行するのに1130秒のプロセッサー時間を要する外部OpenMP関数です。 これは、プロセッサの作業時間の約87%が、このバリア機能で何も役に立たずにアイドリングするスレッドに費やされることを意味します。
BVLC Caffeのソースコードには、 #pragma omp parallelという行があります 。 ただし、コード自体はOpenMPライブラリを明示的に使用してマルチスレッドデータ処理を編成しません。 同時に、インテル®MKLの内部では、OpenMPストリームを使用して、いくつかの基本的な数学的計算の実行を並列化します。 この並列化を確認するために、Intel VTune XEの[ボトムアップ]タブを使用できます。CIFAR-10データセットでBVLC Caffeをテストした後、その内容を下図に示します。 ここでは、関数呼び出しのリストとそれらに関する追加情報を見つけることができます。 特に、使用率別の有効時間インジケーター(タブの上部)と、フローによる機能によって作成された負荷の分布のインジケーター(下部)に関心があります。

CIFAR-10データセットでBVLC Caffeを実行するときに、関数の実行の時間パラメーターとシステムに最も負荷をかける関数のリストの可視化
gemm_omp_driver_v2関数は、Intel MKLの行列乗算(GEMM)の汎用実装であるlibmkl_intel_thread.soライブラリの一部です。 この関数の内部メカニズムには、OpenMPマルチスレッドが関係しています。 インテル®MKLの行列乗算関数は、順方向および逆方向の伝播手順、つまりネットワーク応答を受信してトレーニングする操作で使用される主な関数です。 インテル®MKLはマルチスレッド実行を使用します。これにより、通常、GEMM計算の実行時間が短縮されます。 ただし、この特定のケースでは、32x32イメージのたたみ込み操作によってシステムに過度の負荷がかかることはなく、1つのGEMM操作で36コアの36 OpenMPフローすべてを効率的に使用することはできません。 したがって、以下に示すように、マルチスレッドとコード実行の並列化のさまざまなスキームを使用する必要があります。
多くのOpenMPストリームで作業する必要があるシステムへの追加の負荷を示すために、環境変数OMP_NUM_THREADS = 1で同じコードを実行し、実行時間を前の結果と比較しました。 私たちが持っているものを下の図に示します。 ここでは、前回のテストから37秒ではなく、31.1秒の経過時間の値が表示されます。 環境変数にユニットを書き込んだので、OpenMPに1つのストリームのみを作成させ、それを使用してコードを実行しました。 結果として生じるほぼ6秒の差は、OpenMPストリームの初期化と同期化によって引き起こされる、システムへの追加の負荷を示しています。

シングルストリームを使用したIntel VTune Amplifier XE 2017ベータのCIFAR-10データセットでのBVLC Caffeパフォーマンスの分析の一般的な結果
上の図の中央部分には、システムに最も重い負荷をかける機能のリストがあります。 その中で、最適化の3つの主要な候補が見つかりました。 つまり、これらは関数im2col_cpu 、 col2im_cpu 、およびPoolingLayer :: Forward_cpuです。
コードの最適化
Intelアーキテクチャ向けに最適化されたCaffe環境でCIFAR-10 cデータセットを使用すると、Caffe BVLCを使用した場合よりも約13.5倍高速になります。 次の図は、1000回の反復後の平均結果を示しています。 左側はBVLC Caffeデータ、右側はIntel Caffeです。 最初のケースでは、合計実行時間は270ミリ秒でした。また、2番目のケースでは20ミリ秒でした。

BVLC CaffeとIntel Caffeのパフォーマンス比較
レイヤーの計算パラメーターの設定方法の詳細は、 こちらをご覧ください 。
次のセクションでは、さまざまなレイヤーで使用される計算のパフォーマンスを改善するために使用される最適化について説明します。 Intel Modern Codeプログラムのチュートリアルに従いました。 最適化の一部は、Intel MKL 2017の基本的な数学関数に基づいています。
スカラーおよびシーケンシャル最適化
▍ベクトル化コード
BVLC Caffeコードをプロファイリングし、最もCPU時間を消費する最もロードされた関数を特定した後、コードのベクトル化の作業を開始しました。 変更には次のものがあります。
- 基本的な線形代数サブプログラム(BLAS)ライブラリ、つまり、自動調整線形代数システム(ATLAS)からインテルMKLへの移行を改善します。
- コード構築プロセスの最適化(Xbyak JITアセンブラーを使用)。
- GNU Compiler Collection(GCC)およびOpenMPを使用したベクターコード。
BVLC Caffeでは、Intel MKL BLAS関数呼び出しまたは同じメカニズムの他の実装を使用できます。 たとえば、GEMM関数は、ベクトル化、マルチスレッド実行、およびキャッシュメモリの効率的な使用のために最適化されています。 ベクトル化を改善するために、x86(IA-32)およびx64(AMD64またはx86-64)アーキテクチャ用のJITアセンブラーであるXbyakも使用しました。 Xbyakは、MMX、Intel Streaming SIMD Extensions(Intel SSE)、Intel SSE2、Intel SSE3、Intel SSE4、浮動小数点モジュール、Intel AVX、Intel AVX2、Intel AVX-512のベクター命令セットをサポートしています。
Xbyakは、コード実行効率を改善するために特別に設計されたライブラリ、C ++用のx86 / x64アセンブラーです。 Xbyakはヘッダーファイルとして提供されます。 x86およびx64アーキテクチャ用のニーモニック命令を動的にコンパイルできます。 実行中のバイナリコードのJIT生成は、追加の最適化の機会を提供します。 たとえば、量子化の最適化、ある配列を別の配列で要素ごとに除算する操作、またはプログラム実行中に必要な関数を自動的に作成するための多項式計算の最適化です。 Intel AVXおよびIntel AVX2ベクトル命令セットのサポートにより、Xbyakを使用すると、Intelアーキテクチャ向けに最適化されたCaffeで最高レベルのコードベクトル化を実現できます。 Xbyakの最新バージョンは、Intel AVX-512ベクトル命令セットをサポートしています。 これにより、Intel Xeon Phi x200ファミリプロセッサのコンピューティングパフォーマンスが向上します。
ベクトル化のパフォーマンスを向上させると、SIMD命令の助けを借りてXbyakが同時により多くのデータを処理できるようになり、並列データ処理をより効率的に使用できるようになります。 Xbyakを使用してコードを最適化し、空間結合のレイヤーでの計算のパフォーマンスを大幅に改善しました。 空間結合のパラメーターがわかっている場合、特定のデータ処理ウィンドウまたはアルゴリズムを使用する特定の結合モデルのアセンブラーコードを生成できます。 結果は完全に正常なアセンブリであり、証明されているように、Xbyakを使用せずにコンパイルされたC ++コードよりも効率的に動作します。
▍一般的なコードの最適化
その他の連続した最適化には、次のものが含まれます。
- アルゴリズムの複雑さを軽減します。
- 計算量の減少。
- 展開サイクル。
結果が変わらないコードの繰り返し実行をなくすことは、適用したスカラー最適化手法の1つです。 これは、最大のネストの深さでループ内で計算されるものを事前に計算するために行われました。
たとえば、次のコードフラグメントを考えます。
for (int h_col = 0; h_col < height_col; ++h_col) { for (int w_col = 0; w_col < width_col; ++w_col) { int h_im = h_col * stride_h - pad_h + h_offset; int w_im = w_col * stride_w - pad_w + w_offset;
このフラグメントの3行目では、変数h_imの計算に内部ループw_colのインデックスを使用していません。 ただし、これにもかかわらず、この変数の計算は、ネストされたループの各反復で実行されます。 または、この行を内側のループの外側に移動して、コードを次の形式にできます。
for (int h_col = 0; h_col < height_col; ++h_col) { int h_im = h_col * stride_h - pad_h + h_offset; for (int w_col = 0; w_col < width_col; ++w_col) { int w_im = w_col * stride_w - pad_w + w_offset;
プロセッサ、システム固有の最適化、およびその他の一般的なコード改善アプローチ
適用されるいくつかの追加の一般的なコード最適化を次に示します。
- im2col_cpuおよびcol2im_cpu関数の改善。
- バッチ正規化操作の複雑さを軽減します。
- プロセッサとシステムに固有の最適化。
- 計算ストリームごとに1つのコアを使用します。
- コンピューティングコア間のフローの移動の排除。
Intel VTune Amplifier XEは、 im2col_cpuが最も負荷の高いシステムの1つであることを発見しました。 これは、彼女がパフォーマンスの最適化に適していることを意味します。 im2col_cpu関数は、直接畳み込み演算の標準ステップの実装です。 各ローカルフラグメントは個別のベクトルに展開され、画像全体がより大きなマトリックスに変換され(メモリの処理の強度が増します)、その行はフィルターが適用された多くの場所に対応します。
im2col_cpuの最適化手法の1つは、データにアクセスするために必要な操作の数を減らすことです。 BVLC Caffeコードには、画像のピクセルを反復処理する3つのネストされたループがあります。
for (int c_col = 0; c_col < channels_col; ++c_col) for (int h_col = 0; h_col < height_col; ++h_col) for (int w_col = 0; w_col < width_col; ++w_col) data_col[(c_col*height_col+h_col)*width_col+w_col] = // ...
このコードスニペットでは、BVLC Caffeは最初にdata_col要素の配列の対応するインデックスを計算しましたが、この配列のインデックスは単純に順番に処理されます。 したがって、4つの算術演算(2つの加算と2つの乗算)を1つのインデックスインクリメント演算に置き換えることができます。 さらに、次の条件に基づいて、条件の確認の複雑さを軽減できます。
/* int unsigned , a , , b. b – unsigned, , , , 0x800…, , , 0x800… . */ inline bool is_a_ge_zero_and_a_lt_b(int a, int b) { return static_cast<unsigned>(a) < static_cast<unsigned>(b); }
BVLC Caffeコードでは、 if(x> = 0 && x <N)の形式の条件をチェックしました。xとNは符号付き整数で、 Nは常に正の数です。 これらの整数を符号なし整数に変換すると、比較間隔を変更できます。 型変換後に、論理ANDの比較と計算の2つの操作を実行する代わりに、1つの比較で十分です。
if (((unsigned) x) < ((unsigned) N))
オペレーティングシステムによるコンピューティングコア間のスレッドの移動を回避するために、OpenMP環境変数を使用しました: KMP_AFFINITY = compact、granularity = fine 。 隣接するスレッドをコンパクトに配置すると、同じ最終レベルキャッシュ(LLC)と連携して動作するスレッドが以前にキャッシュラインに書き込まれたデータを再利用できるため、GEMM操作のパフォーマンスが向上します。
キャッシュのブロックに関連する最適化、最適なデータ構成とベクトル化の機能に関する詳細を見つけることができる資料を以下に示します。
OpenMPを使用したコード並列化
▍ニューラルネットワーク層
OpenMP並列化の適用中に、次のニューラルネットワークメカニズムが最適化されました。
- 畳み込み層
- 逆畳み込み(デコンボリューション)のレイヤー。
- ローカル正規化の層(ローカル応答正規化、LRN)。
- 半線形活性化機能を備えたレイヤー(整流線形ユニット、ReLU)
- Softmaxアクティベーション機能を備えたレイヤー。
- 連結レイヤー
- vPowx操作-y [i] = x [i]β、操作caffe_set 、 caffe_copy 、 caffe_rng_bernoulliなどのOpenBLAS最適化のためのユーティリティ。
- 空間結合、またはサブサンプリング(プール)のレイヤー。
- 再トレーニング(ドロップアウト)の影響を防ぐために、ネットワークを「薄層化」します。
- バッチ正規化レイヤー。
- データ層
- 要素単位の操作を実行するレイヤー(Eltwise)。
▍レイヤー畳み込み
その名前と非常に一致している畳み込み層は、トレーニングネットワークまたはフィルターによって変更された重みのセットを使用して入力データを畳み込みます。それぞれを使用すると、出力画像に1つの特徴マップを取得できます。 この最適化により、単一セットの入力フィーチャカードのハードウェアリソースが十分に活用されなくなります。
template <typename Dtype> void ConvolutionLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& \ bottom, const vector<Blob<Dtype>*>& top) { const Dtype* weight = this->blobs_[0]->cpu_data(); // , , // ( , 36 // ). // MKL. for (int i = 0; i < bottom.size(); ++i) { const Dtype* bottom_data = bottom[i]->cpu_data(); Dtype* top_data = top[i]->mutable_cpu_data(); #ifdef _OPENMP #pragma omp parallel for num_threads(this->num_of_threads_) #endif for (int n = 0; n < this->num_; ++n) { this->forward_cpu_gemm(bottom_data + n*this->bottom_dim_, weight, top_data + n*this->top_dim_); if (this->bias_term_) { const Dtype* bias = this->blobs_[1]->cpu_data(); this->forward_cpu_bias(top_data + n * this->top_dim_, bias); } } } }
input_featureマップセットの k = min(num_threads、batch_size)セットを処理します 。 たとえば、 k個の im2col操作が並行して発生し、インテルMKLへのk回の呼び出しが実行されます。 インテル®MKLは自動的にシングルスレッド実行モードに切り替わり、インテル®MKLが1つのパケットを処理したときよりも全体的なパフォーマンスが向上します。 この動作は、src / caffe / layers / base_conv_layer.cppソースファイルで指定されています。 これは、src / caffe / layers / conv_layer.cppソースファイルからOpenMPを使用して最適化されたマルチスレッド処理の実装です。
▍レイヤーのサブサンプリング
最大プーリング、平均プーリング、および確率的プーリング(まだ実装されていない)は異なるダウンサンプリング手法であり、最大プーリングが最も一般的な手法です。 サブサンプリングレイヤーは、前のレイヤーから取得した結果を、通常は重なり合わない長方形の断片のセットに分割します。 そのようなフラグメントごとに、レイヤーは、各フラグメントの活性化関数から形成された多項分布から得られた最大値(最大プーリング)、算術平均(平均プーリング)、または(将来)確率値(確率プーリング)を表示します。
サブサンプリングレイヤーは、主に次の3つの理由で畳み込みネットワークで役立ちます。
- サブサンプリングにより、タスクの次元と上層の計算負荷が軽減されます。
- 基礎となる層のサブサンプルにより、上の層の畳み込みカーネルが入力データの広い領域をカバーできるため、より複雑な属性を学習できます。 たとえば、通常、下のレイヤーのコアは画像の小さな要素を認識することを学習できますが、上のレイヤーのコアは森林やビーチの画像など、より複雑な構造を認識することを学習できます。
- 最大プーリング方式は、イメージシフトに対するネットワークの復元力を高めます。 2x2 ( ) , . 3x3 .
, Xbyak , , . , OpenMP.
, OpenMP-. , :
#ifdef _OPENMP #pragma omp parallel for collapse(2) #endif for (int image = 0; image < num_batches; ++image) for (int channel = 0; channel < num_channels; ++channel) generator_func(bottom_data, top_data, top_count, image, image+1, mask, channel, channel+1, this, use_top_mask); }
collapse(2), OpenMP #pragma omp parallel for , , , .
▍ Softmax
– . , . , , , , , . softmax ( – SoftmaxWithLoss).
, , , , . , ( ), – K , j - x :
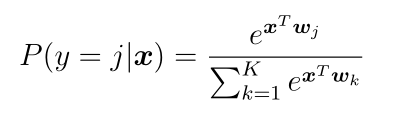
. , , . , .
, :
// #ifdef _OPENMP #pragma omp parallel for #endif for (int j = 0; j < channels; j++) { caffe_div(inner_num_, top_data + j*inner_num_, scale_data, top_data + j*inner_num_); }
▍ReLU
ReLU – , . – , (blob Caffe), , . ( – , Caffe. , Caffe ).
ReLU x x , , negative_slope :
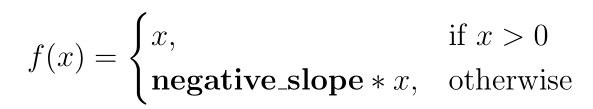
negative_slope , ReLU, : max(x, 0) . - , :
template <typename Dtype> void ReLULayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) { const Dtype* bottom_data = bottom[0]->cpu_data(); Dtype* top_data = top[0]->mutable_cpu_data(); const int count = bottom[0]->count(); Dtype negative_slope=this->layer_param_.relu_param().negative_slope(); #ifdef _OPENMP #pragma omp parallel for #endif for (int i = 0; i < count; ++i) { top_data[i] = std::max(bottom_data[i], Dtype(0)) + negative_slope * std::min(bottom_data[i], Dtype(0)); } }
:
template <typename Dtype> void ReLULayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top, const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) { if (propagate_down[0]) { const Dtype* bottom_data = bottom[0]->cpu_data(); const Dtype* top_diff = top[0]->cpu_diff(); Dtype* bottom_diff = bottom[0]->mutable_cpu_diff(); const int count = bottom[0]->count(); Dtype negative_slope=this->layer_param_.relu_param().negative_slope(); #ifdef _OPENMP #pragma omp parallel for #endif for (int i = 0; i < count; ++i) { bottom_diff[i] = top_diff[i] * ((bottom_data[i] > 0) + negative_slope * (bottom_data[i] <= 0)); } } }
S(x) = 1 / (1 + exp(-x)):
#ifdef _OPENMP #pragma omp parallel for #endif for (int i = 0; i < count; ++i) { top_data[i] = sigmoid(bottom_data[i]); }
MKL ReLU-, , , ReLU- ( Xbyak). , , Intel Xeon. - . C++ .
結論
, , , , OpenMP Intel MKL. , , , .
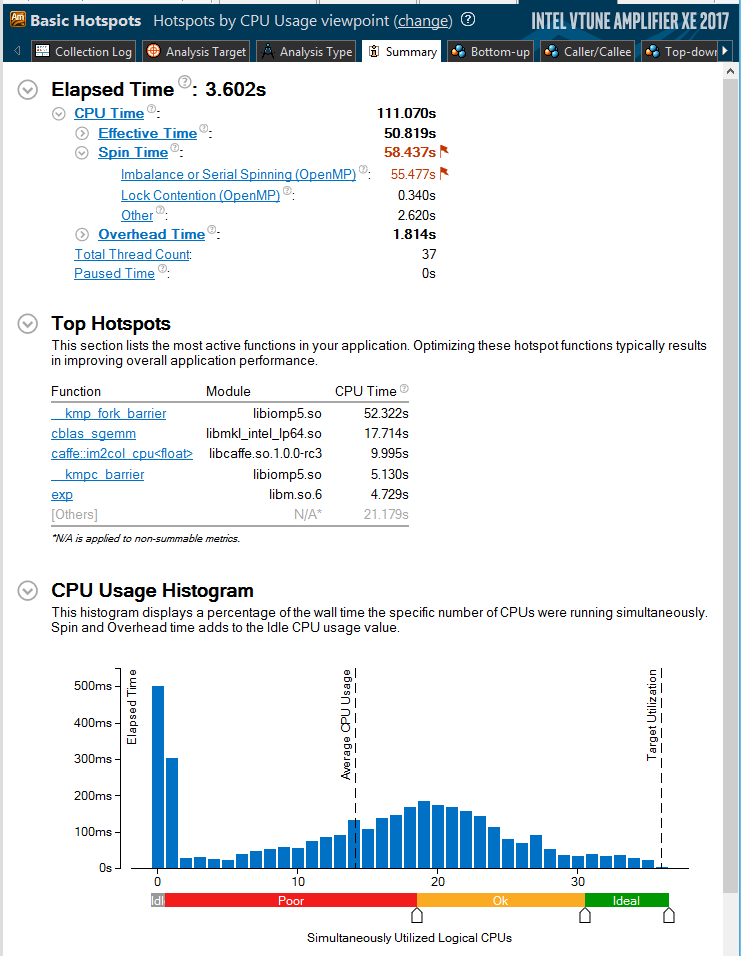
Caffe, Intel, CIFAR-10 Intel VTune Amplifier XE 2017 beta
Caffe, Intel, . 37 BVLC Caffe, 3.6 . 10 .
Elapsed Time, , Spin Time, , , . ( ). , , , OpenMP. OpenMP OpenMP, . , , , .
, , Caffe Intel.
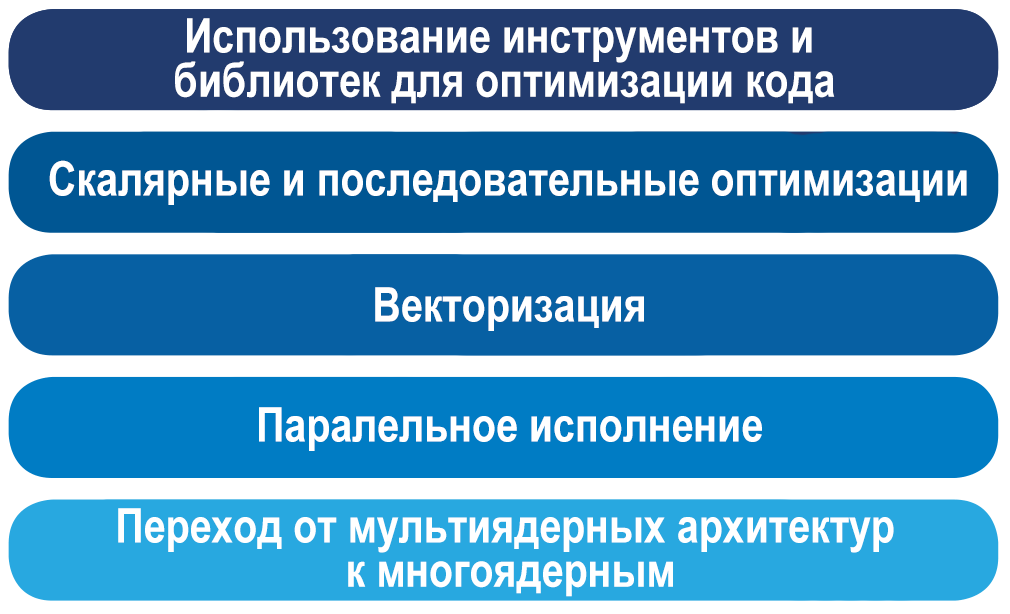
Intel Modern Code
Intel VTune Amplifier XE 2017 beta , , . , , . , . , , GCC. JIT- Xbyak SIMD-.
, OpenMP, , . Intel Modern Code , , , . , , . , , -, . . Intel Xeon Phi x200 MCDRAM NUMA.
Caffe Intel , . Caffe, Intel, .
, , , , , , .
Intel OpenMP- Caffe, Intel.
Intel Modern Code .