この記事では、このツールのビジョンと開発経験を共有します。
関連性マップはインターネット上で何と言っていますか?
このツールについてはほとんど書かれていません。最も完全な定義の1つは、Texterra代理店のWebサイトで見つけることができます。
「関連性マップは、プロモーション部門のスペシャリストがプロモーション作業を開始する前に作成する.excel形式のファイルです。 実際、関連性マップは、サイト構造全体に広がるセマンティックコアです。 さらに、関連マップには以下に関する情報が含まれています。
再リンク、つまり ドナーページからアクセプターページへの内部リンク(既に存在し、将来の作業中にのみ添付されるリンクが反映されます)
H1、タイトル、説明などの要素の関連性。」(Texterra)
それらは次のようになります。

なぜ関連性マップが必要なのですか?
同じソースで私たちは読みました:
「当社のseoオプティマイザーとコピーライターは、作業中にこのドキュメントを常に参照しています。 そのおかげで、混乱や偶発的なエラーは発生せず、まったく別のページに存在するはずの1つまたは別のキーに関連するセクションは表示されません。 たとえば、関連するページはまだありませんが、プランにすでに表示されており、別のページでは、既存のページではなく、別のページによって「予約」されたキーのテキスト関連性を「押し上げる」ことはできません。 (Tekterra)
言われていることはすべて真実ですが、スクリーンショットでマップの例を見ており、このツールを体系的に使用する方法をまったく理解していません。
- 複数の従業員を使用するには? これがExcelの場合、変更を同期するには、別の「シンクロナイザー」の位置を入力する必要があります。
- 並べ替えとフィルタリングの方法は? ドキュメント自体の構造にはフィルタリングは含まれませんが、データの配列を操作する場合は非常に重要です。
- どのセマンティクスがサイトのどのセクションに属しているかを理解する方法は?
- 仕事の優先ページを強調表示する方法は?
一般的に、答えよりも質問の方が多いです。 この記事はおそらく時代遅れであるか、簡略化されたバージョンが例として使用されています。
関連性マップオプション
まず、このドキュメントで必要なものを決定します。
1.共同編集。 複数の従業員を編集できる必要があります。
2.フィルタリング。 マップにはさまざまなデータが含まれているため、どこでもフィルタリングや並べ替えを行う必要はありません。
3.サイトの全体構造の可視性。 これは、マップ内で、どのリクエストがサイトのどのセクションおよびサブセクションを参照しているかが明確であることを意味します。
4.セマンティクスに関する完全な情報。 頻度、サイトのページ、メタタグ、サイトのセクションに応じた場所-これらすべてを1か所で見ると便利です。
最初の要件は、Google SpreadSheetを使用して簡単に解決できます。 共同編集のための魔法のツールは、Excelとほぼ同じだけでなく、オンラインでも機能します。
残りのアイテムを一致させることはより困難です。 これを行うには、リレーショナルデータベースの理論に目を向ける必要があります。
フィルタリングを使用する
フィルタリングを便利に使用するには(繰り返しますが、これがないとテーブルを使用する意味がありません。ノートに書いてください-違いを感じることはありません)、正規化された形式のテーブルが必要です。
「テーブルの最初の標準形式(1NF)であるのは、どの行にもフィールドに複数の値が含まれておらず、キーフィールドが空ではない場合のみです。」
簡単に言えば、テーブルには複合フィールドや空の重要なフィールドを含めるべきではありません。 テーブルのどの行でも、そこに反映されているデータが何を指しているのかを理解する必要があります。
これは簡単で、次のようになります。

この場合、標準のフィルタリングとソートを使用できます。 各行には、その識別に必要なすべてのデータが個別に含まれています。 強調表示された行では、クエリ「bktp」が「BKTP」グループを参照しており、これが「Equipment」セクションを参照していることが明らかです。 要求の頻度は255です。
サイトの全体構造の可視性
これを行うには、ソースデータのピボットテーブルを作成します。 以下はその一部です。

代理店では、カードを常に使用しているため、このオプションはオプションではないことにすぐに気付きました。 理由は次のとおりです。
1つのドキュメントに多くの異なるデータを保存する必要がありますが、それらはすべて2つの異なるエンティティを参照します。 たとえば、頻度は各リクエストを個別に参照しますが、ページURLはリクエストのグループを参照します。 そして、テーブル内のすべてが正しいように、1つのページに関連するすべてのリクエストで同じURLを指定する必要があります。 コピーライターとプロジェクトマネージャーにとって、サイトのページのコンテキスト内のマップは重要であり、キーワードはSEOオプティマイザーにとってより重要です。 要するに、ミスマッチ。

それはそのような地獄です。
「1行-1要求」または「1行-1ページ」のデータの表示の間で引き裂かれて、私たちの意見では単純に驚くべき解決策を見つけました。 1つのテーブルの2つの抽象化レベルをスクリプトと組み合わせることで、いわば、関連性マップを両面に作成しました。 マップを表示するには2つのオプションがあります。それぞれを詳細に説明するので、これがどのように行われ、なぜ行われるかが明確になります。
最初のビューは「One line-one request」です。 クエリレベルで作業する場合、マップは次のようになります。
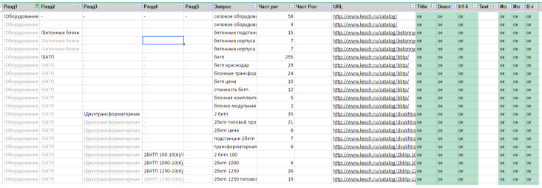
これは「1行1要求」ビューです。 すべての情報は、特定の要求ごとに示されます。 フィルタを並べ替えて、何でもできます。
非常に便利なチップがいくつかあります。
- 最大5レベルのセクション/サブセクションを表示します(必要に応じて、さらに多くのことができます)。
- 次のスクリーンショットでは、最初の行でセクション名が視覚的に強調表示され、後続の同様の名前が暗くなっています。 このような選択は、通常の条件付き書式設定を使用して自動的に行われ、サイト構造の認識を大幅に簡素化します。
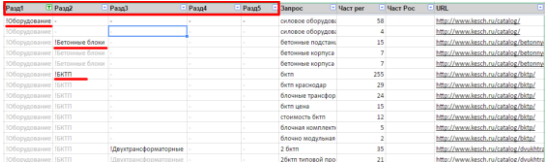
- 1つのセクションまたはサブセクションのみからの要求が表示されるようにフィルターできます。
- 要求を頻度でソートすることができます。
- 関心のあるリクエストのリストを簡単にコピーでき、バラバラで接続されていない一連の行をドラッグする必要はありません。 たとえば、他のサービスで追加の統計を収集すると便利です。
- クエリがどのページに関連するかを確認でき、1ページのみまたはページのグループに関連するクエリを除外できます。
一般的に、私たちはあらゆるものをフィルタリングします。 頻度、タイトル、説明など、リクエストの新しい特徴を追加します。一般に、リクエストのコンテキストで知る必要があるすべてのものを追加します。
プレゼンテーション「1行-1ページ」
繰り返しますが、前のビューはクエリの操作に最適ですが、ページに関連するデータを追加する必要があるとすぐに迷惑になります。 そして、ここでプレゼンテーション「1行-1ページ」の助けになります。 小さなスクリプトを作成し、Googleテーブルメニューの[グループ]項目を選択します。
スクリプトは、テーブル内の行を反復処理し、各URLのすべてのデータをグループ化します。 次の形式になります。
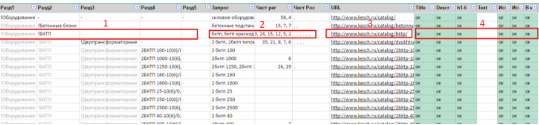
このフォームでは、データは各URL、つまりページごとに示されます。
ここに:
パーティションデータ(番号1)-グループ化
クエリデータ(番号2)-コンマで区切られた単一のフィールドに結合されます
ページURL(番号3)-グループ化
ページデータ(番号4)-グループ化
ページのコンテキストでマップビューに必要なものは次のとおりです。
- リスト付きのページをコピーできます(たとえば、一意性チェックサービスでページをチェックするため)。
- ページに関連するすべての作業が完了したことに注意してください。 ここでは、「一意性の確認」、「テキスト最適化の確認」、「インデックス作成ページの確認」など、好きなものを追加できます。 Zipf法に従ってテキストを確認しますか、それともGlavredサービスを通過しますか? 新しいフィールドを追加して、実行の事実を記録します。
- コピーライターは、コンテンツがまだ書き込まれていない必須ページを確認します。

したがって、1つのファイルで、プロセスのすべての参加者が何が行われ、計画されているかがわかります。
「1行-1つのクエリ」ビューに戻る必要があるが、「グループ解除」をクリックして前のビューに戻る場合:
その結果、何が得られましたか?
次のような複数レベルの関連性マップがあります。
- 「クラウド」に保存され、追加の同期は不要です。
- 便利に連携できます。
- サイトの構造全体を視覚的に確認できます。
- リクエストのコンテキストで情報を保存し、同時にページのコンテキストで作業することができます。
- スクリプトを使用すると、各プロジェクト参加者のニーズに応じてデータの表示を変更できます。
- スクリプトを使用して、ページに関連するデータを1回だけ指定すると、このページのリクエストごとにデータが自動的に複製されます。
- コピーライターとの対話を簡素化します。 実際、マップはサイトの各ページの既製のタスクです。
- プロセスのすべての参加者に、プロジェクトの全体像のビジョンを提供します。
セマンティクスをどのように使用しますか? 誰もが独自の方法を持っています-共有しましょう。