はじめに
ディープラーニングテクノロジーをすばやく理解できるように設計されたシリーズの3番目の(そして最後の)記事を紹介します。 MNIST(手書き数字の分類)とCIFAR-10(小さな画像の10クラスへの分類:飛行機、車、鳥、猫、鹿、犬、カエル)の適切なパフォーマンスを得るために、基本原則から重要な機能に移行します、馬、船、トラック)。

前回、 畳み込みニューラルネットワークモデルを見て、ドロップアウトと呼ばれる単純だが効果的な正則化方法を使用して、Keras深層学習ネットワークフレームワークを使用して78.6%の精度を迅速に達成できることを示しました。
これで、最も興味深いタスクにディープラーニングを適用するために必要な基本スキルが得られました(例外は非線形時系列を処理するタスクであり、この考慮事項はこのガイドの範囲を超えており、どのリカレントニューラルネットワーク (RNN)が通常望ましいソリューションです。このガイドの最後の部分には、非常に重要ですが、そのような記事では見落とされがちなのは、基本的なモデルよりも一般化するようにモデルを教えるためのモデルの微調整の秘andです あなたが始めました。
マニュアルのこの部分は、サイクルの最初と2番目の記事に精通していることを前提としています。
ハイパーパラメーターのセットアップとベースモデル
通常、ニューラルネットワークの開発プロセスは、このような問題を解決するために既に正常に使用されているアーキテクチャを直接使用するか、以前は良い結果をもたらしたハイパーパラメーターを使用して、単純なネットワークの開発から始まります。 最終的には、適切な開始点となるパフォーマンスレベルを達成し、その後、すべての固定パラメーターを変更し、ネットワークから最大のパフォーマンスを抽出できるようになることを願っています。 このプロセスは、トレーニングを開始する前にインストールする必要があるネットワークコンポーネントの変更を伴うため、一般にハイパーパラメーターのチューニングと呼ばれます。
ここで説明する方法は、グラフィックプロセッサがない場合にCIPAR-10をすばやくプロトタイピングするのが比較的難しいため、CIFAR-10でより具体的なメリットを提供する可能性がありますが、MNISTでのパフォーマンスの改善に焦点を当てます。 もちろん、リソースが許せば、CIFARでこれらのメソッドを試して、標準のCNNアプローチと比較してどれだけのメリットがあるかを自分で確かめることをお勧めします。
出発点は、以下に示す元のCNNです。 一部のコードフラグメントが理解できないと思われる場合は、このシリーズの前の2つのパートにすべての基本原則を説明することをお勧めします。
ベースモデルコード
from keras.datasets import mnist # subroutines for fetching the MNIST dataset from keras.models import Model # basic class for specifying and training a neural network from keras.layers import Input, Dense, Flatten, Convolution2D, MaxPooling2D, Dropout from keras.utils import np_utils # utilities for one-hot encoding of ground truth values batch_size = 128 # in each iteration, we consider 128 training examples at once num_epochs = 12 # we iterate twelve times over the entire training set kernel_size = 3 # we will use 3x3 kernels throughout pool_size = 2 # we will use 2x2 pooling throughout conv_depth = 32 # use 32 kernels in both convolutional layers drop_prob_1 = 0.25 # dropout after pooling with probability 0.25 drop_prob_2 = 0.5 # dropout in the FC layer with probability 0.5 hidden_size = 128 # there will be 128 neurons in both hidden layers num_train = 60000 # there are 60000 training examples in MNIST num_test = 10000 # there are 10000 test examples in MNIST height, width, depth = 28, 28, 1 # MNIST images are 28x28 and greyscale num_classes = 10 # there are 10 classes (1 per digit) (X_train, y_train), (X_test, y_test) = mnist.load_data() # fetch MNIST data X_train = X_train.reshape(X_train.shape[0], depth, height, width) X_test = X_test.reshape(X_test.shape[0], depth, height, width) X_train = X_train.astype('float32') X_test = X_test.astype('float32') X_train /= 255 # Normalise data to [0, 1] range X_test /= 255 # Normalise data to [0, 1] range Y_train = np_utils.to_categorical(y_train, num_classes) # One-hot encode the labels Y_test = np_utils.to_categorical(y_test, num_classes) # One-hot encode the labels inp = Input(shape=(depth, height, width)) # NB Keras expects channel dimension first # Conv [32] -> Conv [32] -> Pool (with dropout on the pooling layer) conv_1 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', activation='relu')(inp) conv_2 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', activation='relu')(conv_1) pool_1 = MaxPooling2D(pool_size=(pool_size, pool_size))(conv_2) drop_1 = Dropout(drop_prob_1)(pool_1) flat = Flatten()(drop_1) hidden = Dense(hidden_size, activation='relu')(flat) # Hidden ReLU layer drop = Dropout(drop_prob_2)(hidden) out = Dense(num_classes, activation='softmax')(drop) # Output softmax layer model = Model(input=inp, output=out) # To define a model, just specify its input and output layers model.compile(loss='categorical_crossentropy', # using the cross-entropy loss function optimizer='adam', # using the Adam optimiser metrics=['accuracy']) # reporting the accuracy model.fit(X_train, Y_train, # Train the model using the training set... batch_size=batch_size, nb_epoch=num_epochs, verbose=1, validation_split=0.1) # ...holding out 10% of the data for validation model.evaluate(X_test, Y_test, verbose=1) # Evaluate the trained model on the test set!
トレーニング一覧
Train on 54000 samples, validate on 6000 samples Epoch 1/12 54000/54000 [==============================] - 4s - loss: 0.3010 - acc: 0.9073 - val_loss: 0.0612 - val_acc: 0.9825 Epoch 2/12 54000/54000 [==============================] - 4s - loss: 0.1010 - acc: 0.9698 - val_loss: 0.0400 - val_acc: 0.9893 Epoch 3/12 54000/54000 [==============================] - 4s - loss: 0.0753 - acc: 0.9775 - val_loss: 0.0376 - val_acc: 0.9903 Epoch 4/12 54000/54000 [==============================] - 4s - loss: 0.0629 - acc: 0.9809 - val_loss: 0.0321 - val_acc: 0.9913 Epoch 5/12 54000/54000 [==============================] - 4s - loss: 0.0520 - acc: 0.9837 - val_loss: 0.0346 - val_acc: 0.9902 Epoch 6/12 54000/54000 [==============================] - 4s - loss: 0.0466 - acc: 0.9850 - val_loss: 0.0361 - val_acc: 0.9912 Epoch 7/12 54000/54000 [==============================] - 4s - loss: 0.0405 - acc: 0.9871 - val_loss: 0.0330 - val_acc: 0.9917 Epoch 8/12 54000/54000 [==============================] - 4s - loss: 0.0386 - acc: 0.9879 - val_loss: 0.0326 - val_acc: 0.9908 Epoch 9/12 54000/54000 [==============================] - 4s - loss: 0.0349 - acc: 0.9894 - val_loss: 0.0369 - val_acc: 0.9908 Epoch 10/12 54000/54000 [==============================] - 4s - loss: 0.0315 - acc: 0.9901 - val_loss: 0.0277 - val_acc: 0.9923 Epoch 11/12 54000/54000 [==============================] - 4s - loss: 0.0287 - acc: 0.9906 - val_loss: 0.0346 - val_acc: 0.9922 Epoch 12/12 54000/54000 [==============================] - 4s - loss: 0.0273 - acc: 0.9909 - val_loss: 0.0264 - val_acc: 0.9930 9888/10000 [============================>.] - ETA: 0s [0.026324689089493085, 0.99119999999999997]
ご覧のとおり、このモデルはテストセットで99.12%の精度を達成しています。 これは、前半で説明したMLPの結果よりわずかに優れていますが、まだ成長の余地があります!
このガイドでは、このような「基本的な」ニューラルネットワークを(CNNアーキテクチャから逸脱することなく)改善する方法を共有し、得られるパフォーマンスゲインを評価します。
 -正規化
-正規化
前の記事で、機械学習の主な問題の1つは、トレーニングコストの最小化を追求するモデルが一般化する能力を失った場合の過剰適合の問題であると述べました。

既に述べたように、再トレーニングをチェックし続ける簡単な方法、 ドロップアウトメソッドがあります。
しかし、私たちのネットワークに適用できる他のレギュライザーがあります。 おそらく最も人気のあるものは
適切なλを選択することが非常に重要であることに注意してください。 係数が小さすぎる場合、正則化の影響は無視でき、大きすぎる場合、モデルはすべての重みをリセットします。 ここでは、λ= 0.0001を使用します。 この正規化メソッドをモデルに追加するには、インポートがもう1つ必要です。その後、正規化を適用する各レイヤーに
W_regularizer
パラメーターを追加するだけで十分です。
from keras.regularizers import l2 # L2-regularisation # ... l2_lambda = 0.0001 # ... # This is how to add L2-regularisation to any Keras layer with weights (eg Convolution2D/Dense) conv_1 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', W_regularizer=l2(l2_lambda), activation='relu')(inp)
ネットワークの初期化
前の記事で見落とした点の1つは、モデルを構成するレイヤーの重みの初期値を選択する原理です。 明らかに、この質問は非常に重要です。すべての重みを0に設定することは、学習の重大な障害になります。最初はどの重みもアクティブにならないためです。 間隔±1の値に重みを割り当てることも、通常は最適なオプションではありません-実際、時には(タスクとモデルの複雑さに応じて)モデルの正しい初期化に依存する場合があり、最高のパフォーマンスを達成するか、まったく収束しません。 タスクにそのような極端なものが含まれていない場合でも、重みを初期化する適切な方法は、損失関数を考慮してモデルパラメーターを事前設定するため、モデルの学習能力に大きく影響します。
最も興味深い2つの方法を次に示します。
Xavier初期化メソッド(場合によってはGlorotのメソッド)。 この方法の主なアイデアは、 線形活性化関数のエラーの前方および後方伝搬中にレイヤーを通過する信号の通過を単純化することです(この方法は、シグモイド関数でも不飽和領域が線形特性を持つため、うまく機能します)。 重みを計算するとき、この方法は、分散が等しい確率分布(均一または正規)に依存します。
初期化メソッドGe(He)は、Zawierメソッドのバリエーションであり、 ReLUアクティベーション関数により適しています。この関数が定義の半分の領域でゼロを返すという事実を補正します。 つまり、この場合
Zawierの初期化に必要な分散を取得するために、重みと入力値が相関せず 、 期待値がゼロであると仮定して、線形ニューロンの出力値の分散(バイアス成分なし)がどうなるかを考えます 。
したがって、レイヤーを通過した後の入力データの分散を維持するには、分散が
これらの2つの方法は、出会うほとんどの例に適しています(ただし、 直交初期化方法も、特にリカレントネットワークに関しては研究に値します)。 レイヤーの初期化メソッドを指定することは難しくありません。以下で説明するように、
init
パラメーターを指定するだけです。 すべてのReLUレイヤーにGeの均一な初期化(
glorot_uniform
)を使用し、出力
glorot_uniform
にGevierの均一な初期化(
glorot_uniform
)を使用します(本質的に、ロジスティック関数を複数の類似データに一般化するためです)。
# Add He initialisation to a layer conv_1 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', init='he_uniform', W_regularizer=l2(l2_lambda), activation='relu')(inp) # Add Xavier initialisation to a layer out = Dense(num_classes, init='glorot_uniform', W_regularizer=l2(l2_lambda), activation='softmax')(drop)
バッチ正規化
バッチ正規化は、2015年初頭にIoffeとSzegedyによって提案されたディープラーニングの高速化方法で、arXivで既に560回引用されています! この方法は、ニューラルネットワークの効果的な学習を妨げる次の問題を解決します。信号がネットワークを伝播するとき、入力で信号を正規化し、内側の層を通過しても、平均と分散の両方によって大きく歪む可能性があります(この現象は内部共分散シフトと呼ばれます) )、異なるレベルの勾配間の深刻な不一致に満ちています。 したがって、より強力な正則化を使用する必要があり、それによって学習のペースが遅くなります。
バッチ正規化は、この問題に対する非常に簡単な解決策を提供します。期待値と単位分散がゼロになるように入力データを正規化します。 各レイヤーに入る前に正規化が実行されます。 つまり、トレーニング中は
batch_size
例を正規化し、テスト中は事前にテストデータを表示できないため、トレーニングセット全体に基づいて取得した統計を正規化します。 つまり、特定のバッチ(パッケージ)の期待値と分散を計算します
これらの統計的特性を使用して、バッチ全体でゼロの期待値と単位分散を持つようにアクティベーション関数を変換します。
ここで、ε> 0は、0で除算することを防ぐパラメーターです(バッチの標準偏差が非常に小さい場合、またはゼロに等しい場合でも)。 最後に、最終的なアクティベーション関数yを取得するために、正規化中に一般化する能力が失われないことを確認する必要があります。元のデータにスケーリングおよびシフト操作を適用したため、正規化された値の任意のスケーリングおよびシフトを許可して最終関数を取得できますアクティベーション:
ここで、βとγは、システムをトレーニングできるバッチ正規化のパラメーターです(トレーニングデータの勾配降下法によって最適化できます)。 この一般化は、パッチの正規化がニューラルネットワークの入力に直接適用するのに役立つことも意味します。
この方法は、深い畳み込みネットワークに適用されると、ほとんどの場合、目標を達成します-学習を高速化します。 さらに、優れたレギュラライザーである可能性があり 、トレーニングのペース、パワーを選択できます
そして最後に、メソッドの著者はニューロンの活性化機能の前に正規化を正常に適用することを推奨していますが、最近の研究では、それがより有用でない場合、少なくとも活性化後に使用することも有益であることが示されています。これはこのガイドの一部として行います。
BatchNormalization
、ネットワークにバッチ正規化を追加するのは非常に簡単です:
BatchNormalization
レイヤーがそれを担当し、いくつかのパラメータを渡します。最も重要なパラメータは
axis
(データのどの軸に沿って統計特性が計算されます)。 特に、畳み込み層で作業しているときは、個々のチャネルに沿って正規化する方が適切です。したがって、select
axis=1
です。
from keras.layers.normalization import BatchNormalization # batch normalisation # ... inp_norm = BatchNormalization(axis=1)(inp) # apply BN to the input (NB need to rename here) # conv_1 = Convolution2D(...)(inp_norm) conv_1 = BatchNormalization(axis=1)(conv_1) # apply BN to the first conv layer
トレーニングセットの拡張(データ拡張)
上記の方法は主にモデル自体の微調整に関するものですが、特に画像認識タスクに関しては、 データ調整オプションを検討するのに役立ちます。
ほぼ同じサイズで、きれいに配置された手書きの数字を認識するようにニューラルネットワークをトレーニングしたと想像してください。 ここで、誰かがこのネットワークに異なるサイズと傾斜のわずかにシフトした数のテストを与えるとどうなるかを想像してみましょう。適切なクラスに対する自信が急激に低下します。 理想的には、そのような歪みに耐えられるようにネットワークをトレーニングできると便利ですが、モデルはトレーニングセットの何らかの統計分析を実行して推定する一方で、提供したサンプルに基づいてのみトレーニングできます。
幸いなことに、この問題の解決策は単純ですが、特に画像認識タスクでは効果的です。トレーニング中に歪んだバージョンでトレーニングデータを人工的に拡張します。 これは次のことを意味します。モデルの入力の例を設定する前に、必要と思われるすべての変換を適用し、ネットワークがデータに与える影響を直接観察し、これらに対して「うまく動作する」ように教えます例。 たとえば、MNISTセットからシフト、スケーリング、ワープ、チルトされた数字の例を次に示します。





Kerasは、学習セットを拡張するための素晴らしいインターフェースである
ImageDataGenerator
クラスを提供します。 クラスを初期化して、画像にどのような変換を適用するかを伝えてから、ジェネレーターを介してトレーニングデータを実行し、
fit
メソッドを呼び出し、次に
flow
メソッドを呼び出して、補充するバッチの継続的に展開するイテレーターを取得します。 このイテレータを使用してモデルをトレーニングする特別な
model.fit_generator
メソッドもあり、コードが大幅に簡素化されます。 小さな欠点があります:これは
validation_split
パラメーターを失う方法です。つまり、データの検証サブセットを自分で分離する必要がありますが、これには4行のコードしか必要ありません。
ここでは、ランダムな水平および垂直シフトを使用します。
ImageDataGenerator
は、ランダムな回転、スケーリング、ワーピング、ミラーリングを実行する機能も提供します。 実際には、このように拡大された手書きの数字に出会う可能性は低いため、これらの変換はすべて、おそらく鏡像を除いて、試してみる価値があります。
from keras.preprocessing.image import ImageDataGenerator # data augmentation # ... after model.compile(...) # Explicitly split the training and validation sets X_val = X_train[54000:] Y_val = Y_train[54000:] X_train = X_train[:54000] Y_train = Y_train[:54000] datagen = ImageDataGenerator( width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1) # randomly shift images vertically (fraction of total height) datagen.fit(X_train) # fit the model on the batches generated by datagen.flow()---most parameters similar to model.fit model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), samples_per_epoch=X_train.shape[0], nb_epoch=num_epochs, validation_data=(X_val, Y_val), verbose=1)
アンサンブル
ニューラルネットワークを使用してデータを3つ以上のクラスに分散するときに見られる興味深い機能の1つは、異なる初期学習条件の下で、1つのクラスにより簡単に割り当てられる一方で、他のクラスが混乱することです。 MNISTを例として使用すると、単一のニューラルネットワークでトリプルと5を完全に区別できることがわかりますが、7からユニットを正しく分離する方法は学習しませんが、逆は別のネットワークから分割する場合です。
この不一致は、統計アンサンブルの方法を使用して処理できます。1つのネットワークを配置し、異なる初期値でそのコピーを複数構築し、同じ入力データで平均結果を計算します。 ここでは、3つの個別のモデルを構築します。 それらの違いは、Kerasに組み込まれた図形式で簡単に表すことができます。
コアネットワーク
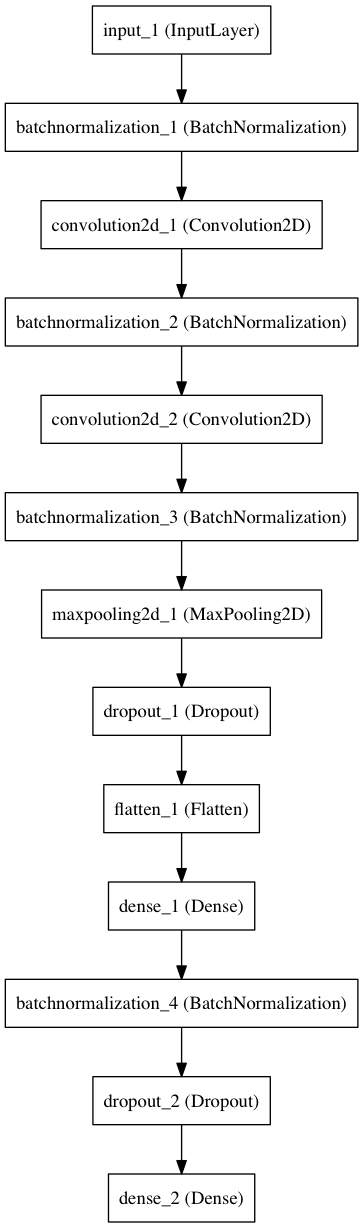
アンサンブル
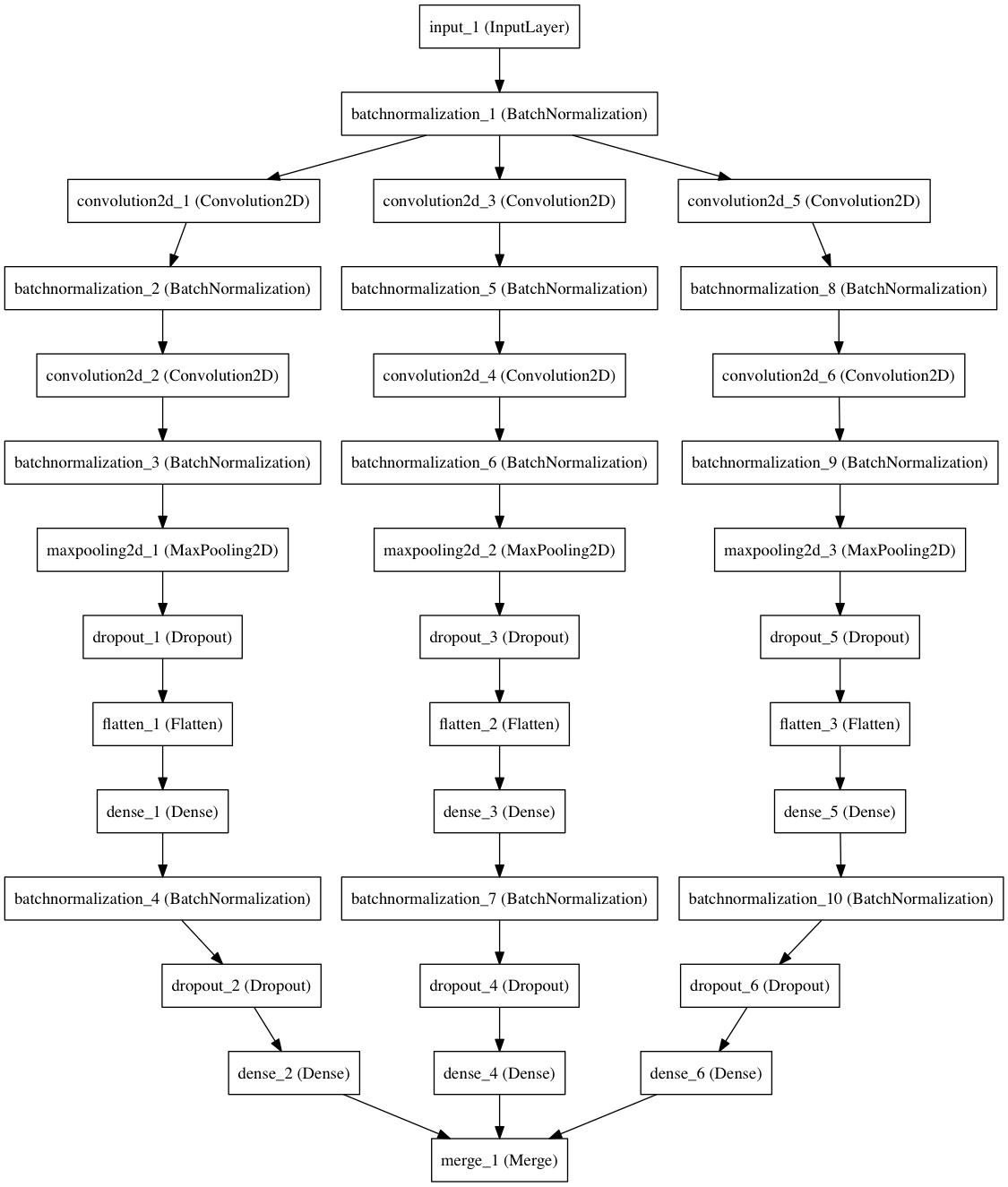
繰り返しになりますが、Kerasでは、最小限のコードを追加するだけで計画を実装できます。最後の
merge
レイヤーで結果を組み合わせて、モデルのコンポーネントをループで構築する方法をまとめます。
from keras.layers import merge # for merging predictions in an ensemble # ... ens_models = 3 # we will train three separate models on the data # ... inp_norm = BatchNormalization(axis=1)(inp) # Apply BN to the input (NB need to rename here) outs = [] # the list of ensemble outputs for i in range(ens_models): # conv_1 = Convolution2D(...)(inp_norm) # ... outs.append(Dense(num_classes, init='glorot_uniform', W_regularizer=l2(l2_lambda), activation='softmax')(drop)) # Output softmax layer out = merge(outs, mode='ave') # average the predictions to obtain the final output
早期停止
ここで、ハイパーパラメータの最適化のより広い分野への導入として、別の方法を説明します。 これまで、トレーニングの進捗状況を監視するためだけに検証済みのデータセットを使用しましたが、これは間違いなく合理的ではありません(このデータは建設的な目的には使用されないため)。 実際、検証セットは、ネットワークハイパーパラメーター(深さ、ニューロン/核の数、正則化パラメーターなど)を評価するための基礎として使用できます。 ネットワークがハイパーパラメーターのさまざまな組み合わせで駆動され、検証セットでのパフォーマンスに基づいて決定が行われることを想像してください。 最終的にハイパーパラメータを決定する前に、テストセットについて何も知る必要がないことに注意してください。 そうしないと、テストセットの兆候が学習プロセスに無意識に流れ込んでしまいます。 この原則は、機械学習の黄金律とも呼ばれ、多くの初期のアプローチで違反されています。
おそらく、検証セットを使用する最も簡単な方法は、 早期停止と呼ばれる手順を使用して「 時代 」(サイクル)の数を設定することです。特定の時代(パラメータの忍耐)で損失が減少し始めない場合は、学習プロセスを停止します。 データセットは比較的小さく、すぐに飽和するため、忍耐力を5エポックに設定し、エポックの最大数を50に増やします(この数に達することはほとんどありません)。
早期停止メカニズムは、 コールバック関数のEarlyStoppingクラスを通じてKerasに実装されています。 コールバック関数は、
fit
または
fit_generator
渡される
callbacks
パラメーターを使用して、各トレーニングエポック後に
fit_generator
。 いつものように、すべてが非常にコンパクトです。プログラムは1行のコードで成長します。
from keras.callbacks import EarlyStopping # ... num_epochs = 50 # we iterate at most fifty times over the entire training set # ... # fit the model on the batches generated by datagen.flow()---most parameters similar to model.fit model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), samples_per_epoch=X_train.shape[0], nb_epoch=num_epochs, validation_data=(X_val, Y_val), verbose=1, callbacks=[EarlyStopping(monitor='val_loss', patience=5)]) # adding early stopping
コードを見せてください
上記の6つの最適化手法を適用すると、ニューラルネットワークのコードは次のようになります。
コード
from keras.datasets import mnist # subroutines for fetching the MNIST dataset from keras.models import Model # basic class for specifying and training a neural network from keras.layers import Input, Dense, Flatten, Convolution2D, MaxPooling2D, Dropout, merge from keras.utils import np_utils # utilities for one-hot encoding of ground truth values from keras.regularizers import l2 # L2-regularisation from keras.layers.normalization import BatchNormalization # batch normalisation from keras.preprocessing.image import ImageDataGenerator # data augmentation from keras.callbacks import EarlyStopping # early stopping batch_size = 128 # in each iteration, we consider 128 training examples at once num_epochs = 50 # we iterate at most fifty times over the entire training set kernel_size = 3 # we will use 3x3 kernels throughout pool_size = 2 # we will use 2x2 pooling throughout conv_depth = 32 # use 32 kernels in both convolutional layers drop_prob_1 = 0.25 # dropout after pooling with probability 0.25 drop_prob_2 = 0.5 # dropout in the FC layer with probability 0.5 hidden_size = 128 # there will be 128 neurons in both hidden layers l2_lambda = 0.0001 # use 0.0001 as a L2-regularisation factor ens_models = 3 # we will train three separate models on the data num_train = 60000 # there are 60000 training examples in MNIST num_test = 10000 # there are 10000 test examples in MNIST height, width, depth = 28, 28, 1 # MNIST images are 28x28 and greyscale num_classes = 10 # there are 10 classes (1 per digit) (X_train, y_train), (X_test, y_test) = mnist.load_data() # fetch MNIST data X_train = X_train.reshape(X_train.shape[0], depth, height, width) X_test = X_test.reshape(X_test.shape[0], depth, height, width) X_train = X_train.astype('float32') X_test = X_test.astype('float32') Y_train = np_utils.to_categorical(y_train, num_classes) # One-hot encode the labels Y_test = np_utils.to_categorical(y_test, num_classes) # One-hot encode the labels # Explicitly split the training and validation sets X_val = X_train[54000:] Y_val = Y_train[54000:] X_train = X_train[:54000] Y_train = Y_train[:54000] inp = Input(shape=(depth, height, width)) # NB Keras expects channel dimension first inp_norm = BatchNormalization(axis=1)(inp) # Apply BN to the input (NB need to rename here) outs = [] # the list of ensemble outputs for i in range(ens_models): # Conv [32] -> Conv [32] -> Pool (with dropout on the pooling layer), applying BN in between conv_1 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', init='he_uniform', W_regularizer=l2(l2_lambda), activation='relu')(inp_norm) conv_1 = BatchNormalization(axis=1)(conv_1) conv_2 = Convolution2D(conv_depth, kernel_size, kernel_size, border_mode='same', init='he_uniform', W_regularizer=l2(l2_lambda), activation='relu')(conv_1) conv_2 = BatchNormalization(axis=1)(conv_2) pool_1 = MaxPooling2D(pool_size=(pool_size, pool_size))(conv_2) drop_1 = Dropout(drop_prob_1)(pool_1) flat = Flatten()(drop_1) hidden = Dense(hidden_size, init='he_uniform', W_regularizer=l2(l2_lambda), activation='relu')(flat) # Hidden ReLU layer hidden = BatchNormalization(axis=1)(hidden) drop = Dropout(drop_prob_2)(hidden) outs.append(Dense(num_classes, init='glorot_uniform', W_regularizer=l2(l2_lambda), activation='softmax')(drop)) # Output softmax layer out = merge(outs, mode='ave') # average the predictions to obtain the final output model = Model(input=inp, output=out) # To define a model, just specify its input and output layers model.compile(loss='categorical_crossentropy', # using the cross-entropy loss function optimizer='adam', # using the Adam optimiser metrics=['accuracy']) # reporting the accuracy datagen = ImageDataGenerator( width_shift_range=0.1, # randomly shift images horizontally (fraction of total width) height_shift_range=0.1) # randomly shift images vertically (fraction of total height) datagen.fit(X_train) # fit the model on the batches generated by datagen.flow()---most parameters similar to model.fit model.fit_generator(datagen.flow(X_train, Y_train, batch_size=batch_size), samples_per_epoch=X_train.shape[0], nb_epoch=num_epochs, validation_data=(X_val, Y_val), verbose=1, callbacks=[EarlyStopping(monitor='val_loss', patience=5)]) # adding early stopping model.evaluate(X_test, Y_test, verbose=1) # Evaluate the trained model on the test set!
Epoch 1/50 54000/54000 [==============================] - 30s - loss: 0.3487 - acc: 0.9031 - val_loss: 0.0579 - val_acc: 0.9863 Epoch 2/50 54000/54000 [==============================] - 30s - loss: 0.1441 - acc: 0.9634 - val_loss: 0.0424 - val_acc: 0.9890 Epoch 3/50 54000/54000 [==============================] - 30s - loss: 0.1126 - acc: 0.9716 - val_loss: 0.0405 - val_acc: 0.9887 Epoch 4/50 54000/54000 [==============================] - 30s - loss: 0.0929 - acc: 0.9757 - val_loss: 0.0390 - val_acc: 0.9890 Epoch 5/50 54000/54000 [==============================] - 30s - loss: 0.0829 - acc: 0.9788 - val_loss: 0.0329 - val_acc: 0.9920 Epoch 6/50 54000/54000 [==============================] - 30s - loss: 0.0760 - acc: 0.9807 - val_loss: 0.0315 - val_acc: 0.9917 Epoch 7/50 54000/54000 [==============================] - 30s - loss: 0.0740 - acc: 0.9824 - val_loss: 0.0310 - val_acc: 0.9917 Epoch 8/50 54000/54000 [==============================] - 30s - loss: 0.0679 - acc: 0.9826 - val_loss: 0.0297 - val_acc: 0.9927 Epoch 9/50 54000/54000 [==============================] - 30s - loss: 0.0663 - acc: 0.9834 - val_loss: 0.0300 - val_acc: 0.9908 Epoch 10/50 54000/54000 [==============================] - 30s - loss: 0.0658 - acc: 0.9833 - val_loss: 0.0281 - val_acc: 0.9923 Epoch 11/50 54000/54000 [==============================] - 30s - loss: 0.0600 - acc: 0.9844 - val_loss: 0.0272 - val_acc: 0.9930 Epoch 12/50 54000/54000 [==============================] - 30s - loss: 0.0563 - acc: 0.9857 - val_loss: 0.0250 - val_acc: 0.9923 Epoch 13/50 54000/54000 [==============================] - 30s - loss: 0.0530 - acc: 0.9862 - val_loss: 0.0266 - val_acc: 0.9925 Epoch 14/50 54000/54000 [==============================] - 31s - loss: 0.0517 - acc: 0.9865 - val_loss: 0.0263 - val_acc: 0.9923 Epoch 15/50 54000/54000 [==============================] - 30s - loss: 0.0510 - acc: 0.9867 - val_loss: 0.0261 - val_acc: 0.9940 Epoch 16/50 54000/54000 [==============================] - 30s - loss: 0.0501 - acc: 0.9871 - val_loss: 0.0238 - val_acc: 0.9937 Epoch 17/50 54000/54000 [==============================] - 30s - loss: 0.0495 - acc: 0.9870 - val_loss: 0.0246 - val_acc: 0.9923 Epoch 18/50 54000/54000 [==============================] - 31s - loss: 0.0463 - acc: 0.9877 - val_loss: 0.0271 - val_acc: 0.9933 Epoch 19/50 54000/54000 [==============================] - 30s - loss: 0.0472 - acc: 0.9877 - val_loss: 0.0239 - val_acc: 0.9935 Epoch 20/50 54000/54000 [==============================] - 30s - loss: 0.0446 - acc: 0.9885 - val_loss: 0.0226 - val_acc: 0.9942 Epoch 21/50 54000/54000 [==============================] - 30s - loss: 0.0435 - acc: 0.9890 - val_loss: 0.0218 - val_acc: 0.9947 Epoch 22/50 54000/54000 [==============================] - 30s - loss: 0.0432 - acc: 0.9889 - val_loss: 0.0244 - val_acc: 0.9928 Epoch 23/50 54000/54000 [==============================] - 30s - loss: 0.0419 - acc: 0.9893 - val_loss: 0.0245 - val_acc: 0.9943 Epoch 24/50 54000/54000 [==============================] - 30s - loss: 0.0423 - acc: 0.9890 - val_loss: 0.0231 - val_acc: 0.9933 Epoch 25/50 54000/54000 [==============================] - 30s - loss: 0.0400 - acc: 0.9894 - val_loss: 0.0213 - val_acc: 0.9938 Epoch 26/50 54000/54000 [==============================] - 30s - loss: 0.0384 - acc: 0.9899 - val_loss: 0.0226 - val_acc: 0.9943 Epoch 27/50 54000/54000 [==============================] - 30s - loss: 0.0398 - acc: 0.9899 - val_loss: 0.0217 - val_acc: 0.9945 Epoch 28/50 54000/54000 [==============================] - 30s - loss: 0.0383 - acc: 0.9902 - val_loss: 0.0223 - val_acc: 0.9940 Epoch 29/50 54000/54000 [==============================] - 31s - loss: 0.0382 - acc: 0.9898 - val_loss: 0.0229 - val_acc: 0.9942 Epoch 30/50 54000/54000 [==============================] - 31s - loss: 0.0379 - acc: 0.9900 - val_loss: 0.0225 - val_acc: 0.9950 Epoch 31/50 54000/54000 [==============================] - 30s - loss: 0.0359 - acc: 0.9906 - val_loss: 0.0228 - val_acc: 0.9943 10000/10000 [==============================] - 2s [0.017431972888592554, 0.99470000000000003]
99.47% , 99.12%. , , MNIST, . CIFAR-10, , .
: , , , , , , , ( 99.79% MNIST).
おわりに
:この記事では、我々は以前の記事で説明したニューラルネットワークの微調整のための6つのレセプションを見
初期化
バッチ正規化
トレーニングセットの拡張
Ensembleメソッド
アーリーストップ
Kerasディープコンボリューションネットワークに正常に適用され、MNISTの精度が大幅に向上し、90行未満のコードで済みました。
これがシリーズの最後の記事でした。ここと前の2つの部分を読むことができます。
あなたの知識が、必要なリソースと組み合わせることで、ディープラーニングネットワークで最もクールなエンジニアになるためのインセンティブになることを願っています。
よろしくお願いします!
ああ、仕事に来てくれませんか? :)wunderfund.ioは、 高頻度アルゴリズム取引を扱う若い財団です。 高頻度取引は、世界中の最高のプログラマーと数学者による継続的な競争です。 私たちに参加することで、あなたはこの魅力的な戦いの一部になります。
熱心な研究者やプログラマー向けに、興味深く複雑なデータ分析と低遅延の開発タスクを提供しています。 柔軟なスケジュールと官僚主義がないため、意思決定が迅速に行われ、実施されます。
チームに参加: wunderfund.io