
この記事では、商品の画像の類似性に基づいて簡単な推奨システムを構築するオプションを実際に検討したいと思います。 この資料は、シンプルで興味深く実用的なプロジェクトでディープラーニング、つまり畳み込みニューラルネットワークの使用を試みたいが、どこから始めればよいかわからない人を対象としています。
背景
オンラインストアでTシャツを選ぶ過程で、このプロトタイプを書くようになりました。 11,000個の製品のうち1000個をスクロールすると、少し疲れました。 既に選択した製品に類似した製品を検索できるようにしたかったのです。 組み込みの推奨システムは何の助けにもなりませんでした。 私のバージョンを提出し、実際のデータでどのように機能するかを確認することにしました。
画像の解析
手始めに、 このカテゴリのシンプルな画像パーサーが実装されました。 解像度が250x250のサムネイルは、ItemID.jpgタイプの名前を持つ1つのフォルダーに入れられました。 約11,000枚の写真が見つかりました。
特徴抽出
画像の類似性を判断するには、それらのベクトル表現を取得する必要があります。 これを行うには、画像の分類に使用される畳み込みニューラルネットワーク(VGG-16)を使用し、既に大きなデータセット(ImageNet)でトレーニング済みで、そこから最後のレイヤーを切り取ります。これにより、出力で1000個のImageNetクラスのそれぞれの確率が得られます。 その結果、各画像に対して4096次元のベクトルを取得します。
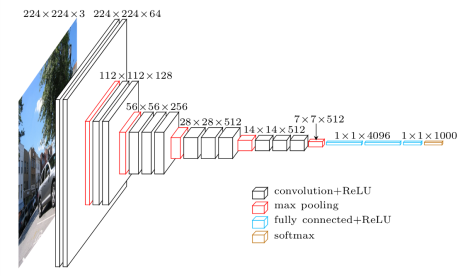
プロトタイプはipythonノートブックに実装するのが最も便利です。まだ試していない人にはお勧めです。
このコードは基礎として採用されました: gist.github.com/baraldilorenzo/07d7802847aaad0a35d3
ライブラリをロードします:
%matplotlib inline from keras.models import Sequential from keras.layers.core import Flatten, Dense, Dropout from keras.layers.convolutional import Convolution2D, MaxPooling2D, ZeroPadding2D from keras.optimizers import SGD import cv2, numpy as np import os import h5py from matplotlib import pyplot as plt import theano theano.config.openmp = True
事前トレーニング済みのImageGet VGG-16をダウンロードし、そこから最後のレイヤーを削除します。
def VGG_16(weights_path=None): model = Sequential() model.add(ZeroPadding2D((1,1),input_shape=(3,224,224))) model.add(Convolution2D(64, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(64, 3, 3, activation='relu')) model.add(MaxPooling2D((2,2), strides=(2,2))) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(128, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(128, 3, 3, activation='relu')) model.add(MaxPooling2D((2,2), strides=(2,2))) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(256, 3, 3, activation='relu')) model.add(MaxPooling2D((2,2), strides=(2,2))) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(MaxPooling2D((2,2), strides=(2,2))) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(ZeroPadding2D((1,1))) model.add(Convolution2D(512, 3, 3, activation='relu')) model.add(MaxPooling2D((2,2), strides=(2,2))) model.add(Flatten()) model.add(Dense(4096, activation='relu')) model.add(Dropout(0.5)) model.add(Dense(4096, activation='relu')) # model.add(Dropout(0.5)) # model.add(Dense(1000, activation='softmax')) assert os.path.exists(weights_path), 'Model weights not found (see "weights_path" variable in script).' f = h5py.File(weights_path) for k in range(f.attrs['nb_layers']): if k >= len(model.layers): # we don't look at the last (fully-connected) layers in the savefile break g = f['layer_{}'.format(k)] weights = [g['param_{}'.format(p)] for p in range(g.attrs['nb_params'])] model.layers[k].set_weights(weights) f.close() print('Model loaded.') return model model = VGG_16('../../keras/vgg16_weights.h5') sgd = SGD(lr=0.1, decay=1e-6, momentum=0.9, nesterov=True) model.compile(optimizer=sgd, loss='categorical_crossentropy')
画像をダウンロードして、ニューラルネットワークに適した形式に変換します。
path = "../../keras/tshirts/out/" ims = [] files = [] for f in os.listdir(path): if (f.endswith(".jpg")) and (os.stat(path+f) > 10000): try: files.append(f) im = cv2.resize(cv2.imread(path+f), (224, 224)).astype(np.float32) # plt.imshow(im) # plt.show() im[:,:,0] -= 103.939 im[:,:,1] -= 116.779 im[:,:,2] -= 123.68 im = im.transpose((2,0,1)) im = np.expand_dims(im, axis=0) ims.append(im) except: print f images = np.vstack(ims)
外部IDを外部IDに、またはその逆に変換するための辞書を作成します。
r1 =[] r2= [] for i,x in enumerate(files): r1.append((int(x[:-4]),i)) r2.append((i,int(x[:-4]))) extid_to_intid_dict = dict(r1) intid_to_extid_dict = dict(r2)
写真からベクトル表現を抽出します。
out = model.predict(images) print out print out.shape
11 556個の写真のそれぞれについて、4096次元のベクトルになります。
[[ 0.00000000e+00 5.96046448e-08 4.35693979e+00 ..., 2.01165676e-07 -2.30967999e-07 5.48017263e+00] [ -2.98023224e-08 -1.78813934e-07 5.60834265e+00 ..., 2.01165676e-07 7.45058060e-09 9.42541122e+00] [ 8.94069672e-08 0.00000000e+00 8.79157162e+00 ..., 2.01165676e-07 -2.30967999e-07 8.50830841e+00] ..., [ 5.17337513e+00 -5.96046448e-08 6.89156103e+00 ..., 2.01165676e-07 7.45058060e-09 1.49011612e-08] [ 3.18071890e+00 -1.78813934e-07 -5.96046448e-08 ..., 2.01165676e-07 -2.30967999e-07 1.49011612e-08] [ 8.19161701e+00 5.96046448e-08 9.62305927e+00 ..., -3.72529030e-08 -2.30967999e-07 7.47453260e+00]] (11556, 4096)
類似画像の検索
コサイン画像がどれだけ近いかを調べます。
from sklearn.metrics.pairwise import pairwise_distances extid = 875317 i = extid_to_intid_dict[extid] print i plt.imshow(cv2.imread(path+files[i])) plt.show() dist = pairwise_distances(out[i],out, metric='cosine', n_jobs=1) top = np.argsort(dist[0])[0:7] for t in top: print t,dist[0][t] plt.imshow(cv2.imread(path+files[t])) plt.show()

テスト用のWebインターフェイス
これらすべてをipythonでテストするのはあまり便利ではないため、DjangoでWebインターフェースを作成することにしました。
Webインターフェースで使用するために必要なデータを保存します。
import joblib joblib.dump((extid_to_intid_dict,intid_to_extid_dict,out),"../../keras/tshirts/models/wo_1_layer.pkl")
次に、起動時にデータをメモリに格納し、リクエストごとに5つの最近傍を見つけます
これが結果です。 パラメータなしでプロンプトが表示されたら、ランダム画像を選択します。 さまざまな距離メトリックに「コサイン」、「ユークリッド」、「マンハッタン」の5つの最も近い画像を提供します
私の意見では、それは十分悪くないことが判明しました。
ImageNetで画像を分類するように訓練されたニューラルネットワークが、Tシャツに描かれているものを「理解」し、意味が似ている画像を選択できることは興味深いことです。
以下に例を示します。
ねこ
くま
人
フルーツ
同様のスタイル
同様のテクスチャ